今天问关于老师分布式的概念和高并发的理解,之前由于自己的粗心马虎,一直将这两个概念没搞清楚,刚好今早看到一篇互联网分层架构的本质,觉得讲的十分好,让自己清晰了很多抽象概念。转载分享以待以后学习。
互联网分层架构的本质
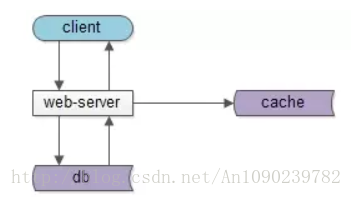
上图是一个典型的互联网分层架构:
- **客户端层:**典型调用方是browser或者APP
- 站点应用层:实现核心业务逻辑,从下游获取数据,对上游返回html或者json
- **数据-缓存层:**加速访问存储
- 数据-数据库层:固化数据存储
如果实施了服务化,这个分层架构图可能是这样:
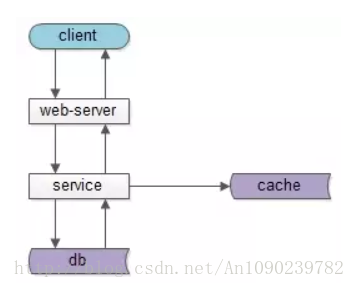
中间多了一个服务层。
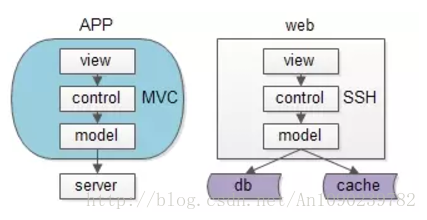
同一个层次的内部,例如端上的APP,以及web-server,也都有进行MVC分层:
- view层:展现
- control层:逻辑
- model层:数据
可以看到,每个工程师骨子里,都潜移默化的实施着分层架构。
那么,互联网分层架构的本质究竟是什么呢?
如果我们仔细思考会发现,不管是跨进程的分层架构,还是进程内的MVC分层,都是一个“数据移动”,然后“被处理”和“被呈现”的过程,归根结底一句话:互联网分层架构,是一个数据移动,处理,呈现的过程,其中数据移动是整个过程的核心。
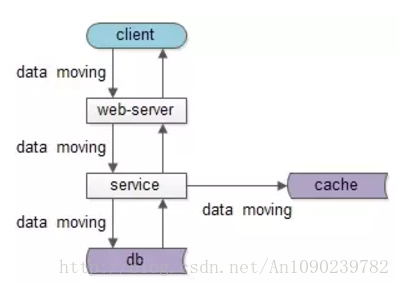
如上图所示:
数据处理和呈现要CPU计算,CPU是固定不动的:
- db/service/web-server都部署在固定的集群上
- 端上,不管是browser还是APP,也有固定的CPU处理
数据是移动的:
- 跨进程移动:数据从数据库和缓存里,转移到service层,到web-server层,到client层
- 同进程移动:数据从model层,转移到control层,转移到view层
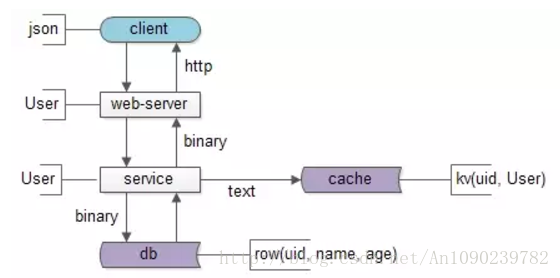
数据要移动,所以有两个东西很重要:
- 数据传输的格式
- 数据在各层次的形态
先看数据传输的格式,即协议很重要:
- service与db/cache之间,二进制协议/文本协议是数据传输的载体
- web-server与service之间,RPC的二进制协议是数据传输的载体
- client和web-server之间,http协议是数据传输的载体
再看数据在各层次的形态,以用户数据为例:
- db层,数据是以**“行”为单位**存在的row(uid, name, age)
- cache层,数据是以kv的形式存在的kv(uid -> User)
- service层,会把row或者kv转化为对程序友好的User对象
- web-server层,会把对程序友好的User对象转化为对http友好的json对象
- client层:最终端上拿到的是json对象
结论:互联网分层架构的本质,是数据的移动。
为什么要说这个,这将会引出“分层架构演进”的核心原则与方法:
- 让上游更高效的获取与处理数据,复用
- 让下游能屏蔽数据的获取细节,封装
总结
- 互联网分层架构的本质,是数据的移动
- 互联网分层架构中,数据的传输格式(协议)与数据在各层次的形态很重要
- 互联网分层架构演进的核心原则与方法:封装与复用
分布式架构的演进
什么是分布式架构
分布式系统(distributed system) 是建立在网络之上的软件系统。
内聚性:是指每一个数据库分布节点高度自治,有本地的数据库管理系统。
透明性:是指每一个数据库分布节点对用户的应用来说都是透明的,看不出是本地还是远程。
在一个分布式系统中,一组独立的计算机展现给用户的是一个统一的整体,就好像是一个系统似的。
分布式系统作为一个整体对用户提供服务,而整个系统的内部的协作对用户来说是透明的,用户就像是指使用一个mysql 一样。
如:分布式mysql中间件 mycat ,来处理大并发大数据量的构架。
分布式架构的应用
分布式文件系统
例如:出名的有 Hadoop 的 HDFS, 还有 google的 GFS , 淘宝的 TFS 等;
分布式缓存系统
例如:memcache , hbase, mongdb 等;
分布式数据库
例如:mysql, mariadb, postgreSql 等;