add by zhj:同时也看看国外牛逼公司是怎么做的吧
Stream-Framework Python实现的feed
Twitter 2013 Redis based, database fallback, very similar to Fashiolista's old approach.
Etsy feed scaling (Gearman, separate scoring and aggregation steps, rollups - aggregation part two)
Django project with good naming conventions
Quora scaling a social network feed
原文:http://blog.renren.com/share/117462957/15084000902
最近见几个朋友都在说人人网新鲜事排序的问题,恰巧对这方面也较感兴趣,于是打算顺便把手头收集到的资料梳理学习一下。由于本人也只是新手,很多内容仅仅是参阅资料后的个人猜测与纸上谈兵故难免存有错误与纰漏,感谢大家指正。
一、 什么是feed
“Feed,本意是“饲料、饲养、(新闻的)广播等”,RSS订阅的过程中会用到的“Feed”,便是在这个意义上进行引申,表示这是用来接收该信息来源更新的接口。”----摘自百度百科。
要说严格的feed定义与解释又得吧啦吧啦说一大堆无趣的话,通俗点说feed系统就是当你登陆进对应网站后:阅读器收到的一篇篇新文章、人人网上看到的一件件新鲜事、新浪微博上推到你面前的一条条新围脖、QQ空间中好友的一桩桩新动态等等。
二、 怎样得到feed
feed的获取方式主要有两种:push(推)以及pull(拉),简单说来正如他们字面意思一样。
push就是当一条feed产生后交到分发器,它再去查找用户关系明确出谁应该看到这条feed,再push到这些用户的feed列表中(新鲜事、好友动 态),用手机短信来比喻的话就是收件箱里存收到的feed,发件箱里存发出的feed,产生一条feed就是把它“推”到所有粉丝或好友的收件箱中,而查 看的话直接访问自己的收件箱就OK,我们可以明显地看到这种情况下通过前置计算(或者叫offline computation)提前准备好用户的feed信息,在取数据时无需多余的计算开销;但相反在分发的过程中会产生大量的计算,尤其是类似于姚晨这种的 明星级人物(1400多万的粉丝真的不是开玩笑)发送一条围脖会产生巨大的数据分发量(新浪微薄的具体解决方案貌似是异步发送,具体方案超出本文范围,感 兴趣的同学可以去看TimYang的博客看看)。总体来说push的特征是取轻、发重。使用push方式发送的例图如下所示:

图2-1 push发feed例图
pull则相反,当一个用户登录到网站后,业务逻辑系统会到feed列表里去查找用户应该看到的feed,用户的feed渲染系统再把它们pull出来。 还是手机短信的例子,pull中发表feed就是把它存入自己的发件箱,用户查看feed的时候就去读取所有关注对象的发件箱把内容“拉”进自己的收件 箱。“拉”方案的优点是随需计算(或者叫 online computation)节约存储空间,但相对的缺点也很明显过大的计算量影响feed数据的读取速度,尤其是峰值时段(新浪的号称1亿多用户可不是开玩 笑的),相对于push来说pull的特征是取重、发轻。使用pull方式取的例图如下所示:

图2-2 pull模式取feed例图
针对push和pull的优缺点,实际项目中一般采用混合模式。发布的时候push给热点用户,再把feed存入热点cache当没收到push的用户登 陆后可以到cache里快速pull出相关feed;用户可以先收到push的新feed消息,当想看以前的消息时再去pull出相关的feed。
三、 如何表示feed
每个平台有各式各样的feed消息,考虑到feed消息最终会展示到平台自身、扩展应用以及客户端上,所以对feed格式统一成某种规范而不是发布者随意输出最终展示的文字。同时对图片、视频以及连接等都统一定义。Facebook的实现方式是这样的:
- feed是自描述的,即它不是由生产者决定最终格式,也不是前端决定。而是通过template机制来进行。
- template在平台中可以由开发者注册,注册时需要定义字段及最终展示样式,如
“{*actor*} 在***游戏中升到 {*credit*} 级”
- 发布的feed内容仅包含字段数据,也就是变量的值,json格式。
“{"credit": "80"}”
- 前端需要显示feed时候调用feed模板,再替换字段得到feed内容
“Tim 在***游戏中升到 80 级”
- 模板需要定义两个,模板标题及模板内容(展示feed详细内容),前端根据需要决定只显示标题还是全部都显示。
- “target”, “actor”是系统保留字段,代表目标对象和当前用户,{*actor*}必须放在模板标题开始位置。
- “images”, “flash”, “mp3″, “video” 是系统保留字段,无需在模板中定义。但这些内容只会在详细feed界面输出。即只要feed内容里面有这个字段值,界面就会自动显示。
- facebook文档中没有规定feed长度限制。
- 每个开发者最多只能注册100个模板。
四、 有效组织feed信息
现在的网络是信息大爆炸的展示场,为了避免让用户淹没在杂乱的feed海洋中,如何有效组织这些feed信息就是各大平台技术较量的一大战场,当平台在后 台为用户准备好了属于他的原始feed信息后,当然各家平台针对自己业务的特点会有不同的方案,但大致都要经过以下几个步骤才能变成最终展示给用户的形 态:
1、 聚合:
根据feed信息的访问频率可能会存在不同的服务器存储区域中。借用淘宝网核心系统专家余峰对各存储区与读书的比喻加以修改就是:
“CPU访问L0就像是你读手边的一本书,访问L1就像从书桌拿一本书,L2是从书架拿一本书,L3是从客厅桌子上拿一本书,访问主存就像骑车去社区图书馆拿一本书。”
以下图新浪微博cache设计图为例:
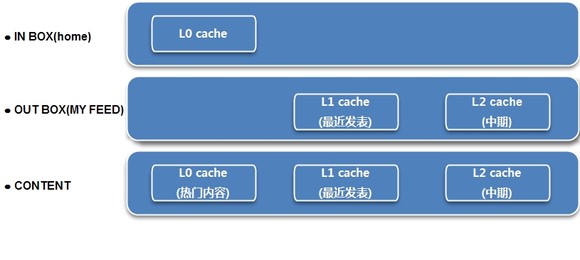
图4-1、新浪微博cache结构图
feed信息依据自身特性分布于各级存储中,必须要把他们汇聚到一起。汇聚并不单纯只是不同级别存储位置的汇聚,还有牵扯到业务数据的汇聚,比如来自不同feed信息源的汇聚如:来自平台本身,开放应用,第三方外部网站等业务流的汇聚。
2、 去重
很多时候有些feed信息是有重复性的,比如A发表了一篇日志,他的好友B和C看后很喜欢选择分享。当这条feed如果出现在B与C的共同好友里就会出现 重复feed信息。面对这个问题不同的社交平台针对自己的业务类型选择了不同的处理方式,即使是同一个平台也在对这种行为采取了不同的应对策略。经过简单 测试后猜测结果:
表4-1 不同平台feed去重说明
|
平台名称 |
说明 |
|
|
新浪微博 |
基于微薄轻传播媒体理论,不覆盖重复的分享feed记录下分享传输的轨迹 |
|
|
人人网 |
早期 |
不处理重复分享,单纯按时间排序feed,时间早的自然在feed列表中淘汰 |
|
曾经 |
消除重复feed信息,只显示最新一条,但在feed信息的下方显示拥有相似分享的连接,点这里可以看到其他的相似分享以及消重的个数 |
|
|
现在 |
有选择的处理重复分享,按现有高级排序方法对feed排序 |
|
|
QQ空间 |
旧版 |
不处理重复分享,根据旧版汇聚在一个大的用户最新动态之中 |
|
新版 |
不处理重复分享,根据新版方式排序在feed列表里 |
|
经过测试发现:
对于新浪微博来说由于他的定位是一种媒体工具,所以关注的点是信息的传输,故而并未太注重去重的分析。他只是单纯的记录信息传输过程新产生的信息,可以说针对同一条信息每一次不同人的转发都是在完善这条媒体信息。
人人网由于是这里面最纯粹的社交网络,馈赠型经济驱动下的社交网络更关注的是如何产生分享这一行为,如何激励用户的互动是他首要关注的目标。因而我们可 以看出人人网对于去重的技术关注较其他平台更深,其自身去重的方法也在不断修改,一开始确实是没有关注到相关问题,在用户数量增加后,对于一些热点分享就 会出现很严重的重复feed,当用户登陆网站会发现排在feed列表前的都是重复的热点信息。针对这点人人推出了消除重复feed的功能,将许多相似分享 合并到一个feed中只显示最新的分享条目。但这样一来有些用户发现自己分享的东西,只能在好友feed中生存一小段时间,一旦有共同好友也分享这条信息 就会覆盖掉自己的分享。这样一来用户的分享不能被其他人完全看到,抑制了馈赠型经济的产生条件。好在之后随着推荐引擎的技术发展解决了这个问题,人人网 feed排序方式的改进,完全可以避免热点信息重复出现在feed列表的前面,而且可以有针对性的将你的分享自动投递到你期望的读者面前,具体的排序方案 在下一节会详细分析。
QQ空间作为腾讯QQ IM的一个扩展并不算一个纯粹的社交分享型网络,他只是完善QQ IM不能触及的一些方面,使用户更加全面的了解IM交流的对象。他更像是一个用户的展示平台,所以重复分享现象在QQ空间中并不严重。QQ空间最主要的展 示内容都是围绕着该用户的一些信息故不太会经常产生过度重复的分享内容。
从趋势上看随着排序算法更加智能化的发展,重复的热点消息问题会得到更有的解决。
3、 排序
feed排序算法可以说是SNS发展最重要的技术之一,也是各家平台的核心技术。由于看过的相关资料较少,以下的一些分析仅仅是个人纸上谈兵的一点浅析,欢迎大家指正。
不同平台有着不同的排序方案(经测试和个人使用总结):
表4-2 不同平台排序说明
|
平台名称 |
说明 |
|
|
新浪微博 |
单纯按照feed发生时间排序 |
|
|
人人网 |
早期 |
按feed发布时间顺序排序 |
|
曾经 |
有段时间相册是按最后评论时间排序 |
|
|
现在 |
综合的推荐引擎方式排序 |
|
|
QQ空间 |
旧版 |
将用户最近feed信息框入一个大的feed中,按用户最新动态时间对这个大feed整体排序 |
|
新版 |
类似于新浪微薄的单纯按照feed发生时间排序 |
|
如前所述由于新浪微薄的定位是媒体功能,所以它的时效性要求较高。再加上原来140个字的限制都表明他轻量级的信息定位应该更专心于时效性,故新浪采取 产生时间排序无可厚非,微博的原理是假设有价值的微博会不断被转发从而反复出现在用户的feed列表中,但这种方法也产生了微博的“15分钟定理”——如 果一条微博在最初的15分钟内没有被大量关注与转发则它会被汪洋“博”海所淹没,最终传播不了多远。根据长尾理论可能存在一些小型的细分用户群体话题存 在,于是一些有价值的微博由于初期没有被发现,或是作者的粉丝过少,都有可能导致作品无法传播开去。个人预测新浪也可能会引入推荐引擎系统,通过对用户兴 趣和微博数据库的深度数据挖掘进行微博推荐,在时间单维排序的基础上加入兴趣维度。
单看国内SNS人人网现在的排序系统貌似是最复杂的(facebook的算法智能与变态程度就不考虑了)。根据人人网张铁安在《程序员》与CSDN举办 的TUP第二期上的演讲以及个人使用情况来看,首先人人网会对用户的资料和行为进行挖掘然后按兴趣分类生成兴趣向量,再根据用户与好友的互动行为挖掘生成 社会关系向量。当一条feed由好友产生了会挖掘这条消息的兴趣分类向量,该分类向量与你的兴趣分类向量计算距离得到兴趣权值,再通过作者与你的社交向量 做计算得出关系权值。最终一条feed的排序权值会来自于最少以下几个方面【生成时间、消息热度(最近活跃程度)、兴趣权值、关系权值、商业权值】。其中 商业权值应该是针对一些商业推广活动类feed,比如说你参加了在人人网做广告的某些活动,系统会将这条feed发送给你的好友面前,可能根据广告主付钱 多少采取不同的权值会在好友的feed列表前面排列很久。
QQ空间在前面已经分析过是针对QQ IM的一个拓展,他的核心是展示用户信息平台,所以他较老版本的排序是以某一用户的最新动态排序,然后将该用户最近的动态打包合并到一个大的feed中向 用户展示。他的核心是针对于一个用户的信息产生的。在新版QQ空间中可能是为了和面向媒体的腾讯微博以及面向社交的朋友网进行整合,修改成面对单一每条 feed的排序。
总体来说SNS由于业务类型的不同,各个平台针对产生feed的这一行为的关注点各有不同,进而导致了排序行为的不同。新浪微博这种媒体平台关注的是 feed本身的内容以及由转发与评论引出的新内容;人人网这种纯粹社交网络关注的是由feed内容引发的用户间的互动行为;而QQ空间这种应为是辅助与其 他产品的工具,所以他关注的是被辅助的产品自身所需求的特点。
4、 渲染
渲染阶段比较易于理解,通过第三部分的描述我们了解到feed最初是由变量名与变量值组成的,渲染就是通过将feed套入对应模版并依据之前几个步骤经过聚合、去重、排序后的结果最终生成为用户所看到的feed列表。
五、 架构简介
这部分只是简单给大家展示下新浪和人人网的系统架构,具体技术和原理个人还正在学习中(就不说出来丢人了)
新浪微博的功能性架构图如下所示:

图5-1 新浪微博功能架构
这个是新浪微博的第三代架构图了,首先在最底层是实现一些存储同步等基础性需求。再上面是平台面向业务的服务与提供应用的服务,最上层是作为第三方开发的API提供给app开发者。
其系统架构如下图:
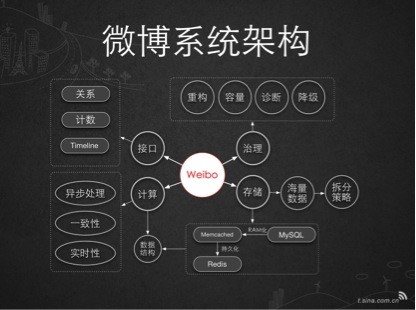
图5-2 微博系统架构
具体技术方案我自己也在学习中,这里就不再多说了(就不出来丢人了…),有兴趣大家一起探讨学习吧。
人人网系统架构图:

图5-3 人人网feed系统架构图
简单说一下这图,笑脸表示某个用户很开心写了篇日志,是先交给分发器(Dispatcher),经过一些处理后发往三个不同的地方,第一个是 newsfeed这是完整的一个feed信息与索引;第二个是minifeed这是一个feed的短摘要信息,你在人人网上看到的某个用户写了篇日志的新 鲜事,在它的标题下面会有一小段摘要,这个短摘要就是minifeed;第三是要把新鲜事本身cache起来,会把feed发到集群里面最后进行存储持久 化。
六、 总结
好久没写这么长篇的东西了,终于写完了。由于个人水平有限系统架构部分写的有点略显薄弱,欢迎大家一起讨论,争取以后有机会把这部分单独完善重写一篇。