原文:http://caduke.blog.51cto.com/3365689/1544229
当单个服务器性能 不能满足日益增多访问流量时,服务器的扩展策略:
Scale Up :向上扩展,提升单个物理主机的性能,比如增加CPU、内存等。
Scale Out:向外扩展,将相互依赖的服务器(LAMP等)做层次上的划分,然后将各个层次的服务器分别安装在不同的层次的物理主机上。当哪个层次的服务器无法承受压力时只要增加其层次的主机即可。
划分层次的过程也叫做解耦的过程,也就是将此程序之间的耦合度。不同层次的服务器之间叫做甬道。

而每个层次上就需要使用负载均衡器将请求分发到多个后端真实服务器。而为了避免负载均衡器的单点故障,就需要将负载均衡器做成高可用集群。
负载均衡器的工作层次:
TCP/UDP:工作在内核空间,请求由内核判断后直接转发,所以速度快,性能好。软件有LVS。
应用层负载均衡:工作在用户空间,需要将请求从内核空间复制到用户空间然后再复制到内核空间,所以性能上会比TCP/UDP层低。但是由于应用层更懂得应用程序更高层次、更细化的分发,所以当用户请求量没有超过应用程序的负载量时,直接使用应用层会更好。软件有nginx、haproxy、Apache、lighttpd、varnish、squid。
硬件负载均衡:BigIP的F5,可以达到单台600-800W的并发。
Citrix的Netscaler,A10
集群的分类:
LB:Load Balancing Cluster,负载均衡集群。
HA:High Availiablity,高可用集群
HP:High Perfomance,高性能集群。比如Apache官方维护的Hadoop(至少有40台)
LVS作者:章文嵩
LVS工作模型是前端负载均衡器Load Balancer(也可以叫做dispatcher分发器、director调度器)+后端真实服务器(RealServer),也就是请求达到director,然后director将请求根据不同的算法分发到不同的真实RealServer上。
类似于iptables/netfilter,LVS是ipvsadm/ipvs。由于iptables的过滤、追踪功能会极大的降低LVS的性能,所以ipvs一般不会和这些表一起使用。不过,在LVS的某些模型中会使用到iptables的mangle表prerouting链的规则。
ipvs工作在input链上,当请求内容符合input链中的rule时,input链就会将请求直接强行扭转到postrouting链,然后发送给后端的真实主机。
LVS调度方法:
起点公平的静态调度算法:(也就是不考虑后端RealServer的连接数)
rr:Round-Robin,轮询、轮叫、轮调,从服务器列表的第一个开始,然后依次循环。
当每台服务器主机的性能不一样时,性能差的主机会扛不住,这时这个算法就不靠谱了。
wrr:Weight Round-Robin,加权轮叫。按照权重倍数进行分发,也就是性能好的主机会得到较多的请求。但也只是起点公平。
sh:Source Hashing源地址hash,实现lvs的连接持久性。
一般情况下,服务器为了保持与客户端的http的连接持久性,会向客户端发送一个cookie标签,用于标明客户端的动作,比如向购物车添加的物品等。但是当下次链接被director分配到其他RealServer上时,那么cookie就没用了,也无法保持http的持久性了。但是RealServer之间可以通过广播和组播同步session。但是这样非常占用网络资源;如果使用memcached保持会话,那么memcached宕机,那么所有的会话就没用了。但是如果开始就在Director上面使用sh算法,那么就会建立一个使用键值方式的session表,客户端IP是键,内部RS是值。这样就能保证所有的会话一直发往一个主机。但是问题依然存在:一个RS损坏,那么相当一部分用户依然会受到损害。
dh: Destination Hashing,目标地址hash。
sh与dh的应用:使用sh/dh的Director后面是多个防火墙(兼具路由器),使得数据包只走同一个只允许established通过的防火墙。
结果公平的动态算法:(计算后端RealServer的连接数,动态分发)
lc:Least Connection,最少连接。
算法:Overhead=Active*256+Inactive
这个值谁小,谁就是下一个接受请求的RS。
缺点:一开始都是0,可能依然从性能最差的开始。
wlc:Weight lc,加权最少连接,默认算法。
算法:Overhead=(Active*256+Inactive)/Weight
缺点:性能差的依然可能是第一个接受请求的。
sed: Shortest Expect Delay最少期望延迟,对wlc的该进
算法Overhead=(Active+1)*256/Weight
缺点:这里不再计算非活动链接数了,但是当有当量连接时,依然需要考虑非活动连接数。而且只有当性能好的服务器有一大堆请求时,性能差的依然没有接受请求。
nq: Never Queue永不排队,一开始就各自分配一个
lblc: (dh+lc) Lo
cality-based Least Connection本地最少连接
lblcr: Replicated and Locality-based Least Connection
带复制的本地最少连接
英文简称:
Director:调度器,
VIP:virtual IP,调度器上浮动的虚拟ip
RIP:后端提供服务器的真实主机的IP
DIP:调度器与RIP相互通信的IP
CIP:client IP,发来请求的客户端IP
LVS的工作类型:
NAT、DR、TUN、FNAT
NAT类型:
1、RS应该使用私有IP;
2、RS网关应该指向DIP;
3、RIP和DIP应该在同一个网段内;
4、进出报文都得经过Director,高负载情况下,Director会成为性能瓶颈。
5、支持端口映射;
6、RS可以使用任意OS;
7、由于智能带动10台内的RS,所以生产环境下几乎不用。
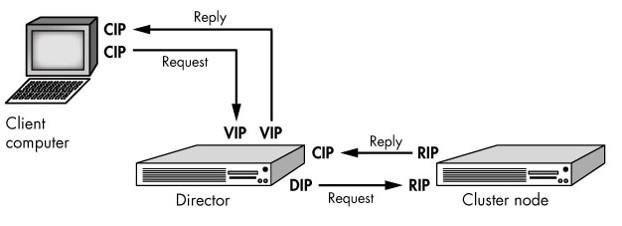
DR类型:
1、RS可以使用私有IP,亦可以使用公网IP;
2、RealServer的网关不能指向DIP;
3、DIP和RIP要在同一个网段,所以RS和Director要在同一个物理网络内,也就是同一个机房,这样就不具备防灾功能了;
4、入站报文经过Director,出站报文则直接由RS响应给Client;
5、不能做端口映射;
6、RS可以为大多数OS;
7、每个RS都可以哟RIP和VIP;
8、由于RS有VIP,且最后到达RS数据传输都是以数据帧方式进行的,所以需要开启RS的arptables,或者其他参数以拒绝交换机对VIP的广播请求。
9、当VIP、DIP、RIP在同一个网段时,他们都可以使用总的网关。
但当VIP、DIP和RIP不在一个网段时,RS就需要加一个单独的路由,然后由这个单独路由再去找Director的网关。
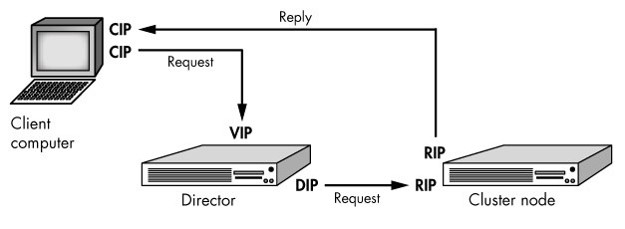
如上图,集群节点由于要自己将回复报文返回给客户端,所以集群节点自己也需要一个VIP,否则客户端不会接受其他主机无缘无故发送来的数据包。但是这样一来,集群节点就需要处理内部网络内的arp广播问题,否则集群的路由器在广播谁是VIP时,有一堆设备应答就坏了。处理arp广播的方法有:
1,在集群的路由器上直接绑定VIP为Director,但是IDC机房一般不允许被操作。
2,在RS上使用arptables,拒绝arp的广播请求。
3,使用linux内核2.6.4版本以后引入的2个参数,以设定对arp的通告和响应方式。
解释:对于linux系统而言,IP地址是数据主机的,而不是单个网卡的。
当某个arp请求到达linux主机时,默认情况下,本机只要有那个IP地址,
主机都会应答,而不管arp请求通过哪个网卡进来的。
这时,就需要禁止RS响应任意网卡进来的arp请求。
比如eth0网卡的IP位172.16.100.100,但是从eth0网卡进来一个请求192.168.100.101的arp广播,默认只要linux有这个IP,都会响应出去。
再次,当linux主机接入一个网络后,默认情况下,会向所有网络通告自己所有的IP地址和对应MAC地址。
这时,就需要禁止RS向任意网络通告自己的VIP和对应MAC。
内核参数设定方法:
arp_announce定义arp通告限制级别,默认为0,应设定为2.
0,默认值,linux主机会向所有接口的网络通告自己所有接口的IP+MAC。
1,尽可能的不在一个接口上通告其他接口的IP+MAC,但还可能会通告。
2,绝对禁止在一个接口上通告其他接口的IP+MAC,RS的实际设定值
echo 2 > /proc/sys/net/ipv4/conf/lo/arp_announce
echo 2 > /proc/sys/net/ipv4/conf/all/arp_announce
arp_ignore定义arp响应级别,默认为0,应设定为1.
0,默认值,任意接口进来的请求,linux都会给。
1,arp请求的IP必须是进来的接口的IP,否则不予响应。
比如eth0接口为192.168.100.101,如果从eth1进来的请求,则不会响应。
echo 1 > /proc/sys/net/ipv4/conf/lo/arp_ignore
echo 1 > /proc/sys/net/ipv4/conf/all/arp_ignore
数据包在集群内部网络的传递问题:
在数据包进入Director时,会被拆掉源MAC+目标MAC,但是进入INPUT链时,被ipvs规则强行扭转到POSTROUTING链,由于集群主机间都要接入交换机,而交换机只是识别MAC,所以数据包只是在Director上改变了源MAC+目标MAC,其他层次并未改变。
当数据包到达RS内部时,看到是自己的MAC,且自己有VIP,那么就开始构建响应报文。
当RS向外发送报文时,默认情况下,linux默认数据包从哪个网卡向外发送数据,就那个那个网卡的IP作为源IP,这时就需要制定一个强制的路由策略,要求源地址必须是VIP,而不管从哪个网卡出去,比如使用route add -host $VIP dev lo:0。
TUN隧道模型:
1、RIP、DIP不能是私有IP;
2、RS的网关不能指向DIP;
3、入站报文经过Director,出站则由RS直接响应Client;
4、不支持端口映射;
5、支持IP tunnelin的OS才能用于RS。
IP隧道指的是数据在IP层上又加上了一层源IP+目标IP,这样在到达最外层的IP地址设备后,那个设备拆开报文后发现不是给自己的,于是接着转发。
过程:
当客户端数据包到达具有2个公网IP的Director的VIP后,将数据包进行二次封装,将原数据包的IP层网上保持不动,再添加一层IP(DIP+RIP)+MAC,然后经过路由设备的转发,到达具有公网IP的RS的RIP,RS发现自己有VIP,开始构建响应。
IPVS用户空间工具ipvsadm的使用:
# grep -i ipvs -C 20 /boot/config-2.6.32-358.el6.x86_64
查看内核支不支持ipvs及更多的被支持的算法等。
# yum install ipvsadm -y这样就成为了一个Director调度器了。
添加/编辑集群服务:
ipvsadm -A|E -t|u|f service-address [-s scheduler] [-p [timeout]] [-O] [-M netmask]
-A:添加集群服务
-E:编辑集群服务
-t: tcp
-u: udp
-f: firewall mark用于构建RS的持久连接,使用iptables将多个端口打同一个标记
service-address: VIP:Port
-s: 指定调度方法
-p:表示persistent持久性,指定持久连接的超时时间
添加一个VIP为172.16.100.10的httpd服务
ipvsadm -A -t 172.16.100.10:80 -s wrr
删除集群服务:
ipvsadm -D -t|u|f service-address
-D:删除一个集群服务
添加/编辑RS:
ipvsadm -a|e -t|u|f service-address -r server-address [-g|i|m] [-w weight] [-x upper] [-y lower]
-a:向指定集群服务中添加RS
-e:修改集群服务中的RS
-r IP[:port]: 指定RS的地址
指定lvs类型:
-g: dr模型,默认,gateway网关
-i: tun模型,internet,表示在ip隧道中
-m: nat模型
-w weight:指定权重,当使用带有权重的算法时才会生效。
向172.16.100.10:80的集群中添加2个RS,并使用DR模型:
ipvsadm -a -t 172.16.100.10:80 -r 192.168.100.1 -g
ipvsadm -a -t 172.16.100.10:80 -r 192.168.100.2 -g
删除集群服务中的RS:
ipvsadm -d -t|u|f service-address -r server-address
-d:删除RS
保存ipvs配置:
service ipvsadm save
保存到:/etc/sysconfig/ipvsadm
ipvsadm -S > /path/to/ipvsadm.rules
ipvsadm -R < /path/to/ipvsadm.rules
查看ipvsadm的连接:
ipvsadm -L|l [-n] [-c] [--stats] [--rate] [--timeout]
-n:以数字方式显示
-c:统计信息
--stats:显示状态
--rate:显示速率
--timeout:显示超时
重置ipvsadm的计数器:
ipvsadm -Z
清空ipvsadm的所有规则:
ipvsadm -C
LVS的持久连接:
持久连接的称呼是不准确的,因为sh、dh不是TCP的持久连接机制。
keepalive指的是tcp的三次握手后,会建立一个通道,在此后的一段时间内时间都可以通过这个通道进出。
sh调度方法只是在一段时间内将同一个CIP的请求发送到同一个RS,而且只能解决单个集群服务的持久。而这个时间取决于TCP会话的持久连接时间,而这个时间又是TCP会话自己设定的。
当我们希望一个客户端的httpd和ssh请求都发送到同一个RS上面时,那么就需要使用 端口殷亲(port affinity) 来解决:将2个或多个集群服务当做一个服务来对待,也就是将多个端口绑定在一起,打上一个标记。只要让ipvsadm认识这个标记即可。
LVS persistent template
持久连接模板,是保存在内存中的哈希表,也就是键值表。键是CIP,值是RS。
对于非常繁忙的调度器,这个表需要占用很大的空间,所以系统默认对其做了限制。
所以某些场景下需要修改这个限制值。
模板的持久时间也是有限制的,在CentOScar6.4上默认是360秒,可以使用-p修改。
pcc: Persistent Client Connection
持久客户端连接
对同一客户端发的所有服务请求都生效,都发送到一个服务器上。
演示:
ipvsadm -C清除所有规则
ipvsadm -A -t 192.168.1.10:0 -s rr -p
ipvsadm -a -t 192.168.1.10:0 -r 192.168.1.210
ipvsadm -a -t 192.168.1.10:0 -r 192.168.1.212
上面是将所有的服务都定向到同一个服务器上。(0表示所有端口)
ppc:Persistent Port Connection
持久端口连接
只对一个服务有效。
可以在使用-t service:port的这个port可以写0表示所有
pfm:持久防火墙标记连接
在数据包刚刚到达Director的PREROUTING链上时,就打上一个标记。比如对VIP的80和443端口都标记位10,然后使用-f将这个标记定义为一个集群服务,这里只是给报文打标记,并没有改变报文。而且打标记是在mangle表上的PREROUTING链上实现的,所以需要借助iptables规则。这个标记是界于0到99之间的数值。
iptables打标方法:
iptables -t mangle -A PREROUTING -d $VIP -p tcp --dport 80 -j MARK --set-mark 10
iptables -t mangle -A PREROUTING -d $VIP -p tcp --dport 443 -j MARK --set-mark 10
ipvsadm集群定义方法:
ipvsadm -A -f 10 -s rr -p
ipvadm -a -f 10 -r 192.168.1.210 -g
LVS的高可用:
LVS的Director能够使用脚本对后端RS做健康状态监测后,可以及时将宕掉的RS删除,但是这种状态是不具有冗余的,因为用户数据会丢失。
具体LVS的实验请看下节详解