从操作系统的角度详解Linux文件系统层次、文件系统分类、文件系统的存储结构、不同存储介质的区别(RAM、ROM、Flash)、存储节点inode。本文参考:
http://blog.chinaunix.net/uid-8698570-id-1763151.html
http://www.iteye.com/topic/816268
http://soft.chinabyte.com/os/142/12315142.shtml
http://www.ibm.com/developerworks/cn/linux/l-cn-hardandsymb-links/
http://blog.csdn.net/kension/article/details/3796603
http://www.360doc.com/content/11/0915/17/3200886_148505332.shtml
在LINUX系统中有一个重要的概念:一切都是文件。 其实这是UNIX哲学的一个体现,而Linux是重写UNIX而来,所以这个概念也就传承了下来。在UNIX系统中,把一切资源都看作是文件,包括硬件设备。UNIX系统把每个硬件都看成是一个文件,通常称为设备文件,这样用户就可以用读写文件的方式实现对硬件的访问。这样带来优势也是显而易见的:
UNIX 权限模型也是围绕文件的概念来建立的,所以对设备也就可以同样处理了。
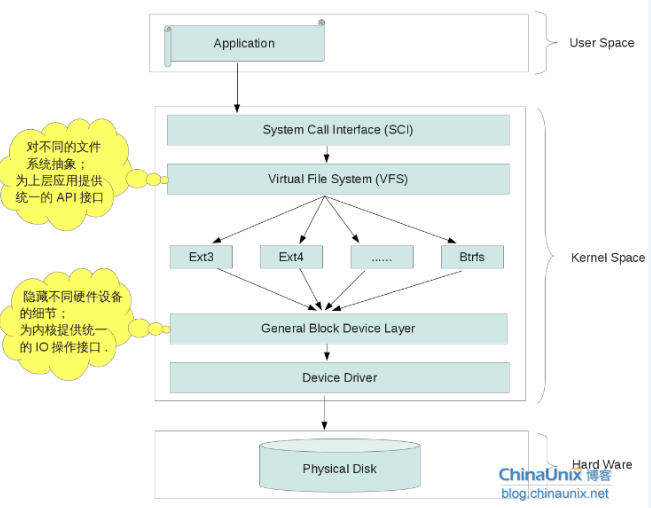
1. 硬盘驱动
常见的硬盘类型有PATA, SATA和AHCI等,在Linux系统中,对不同硬盘所提供的驱动模块一般都存放在内核目录树drivers/ata中,而对于一般通用的硬盘驱动,也许会直接被编译到内核中,而不会以模块的方式出现,可以通过查看/boot/config-xxx.xxx文件来确认:
CONFIG_SATA_AHCI=y
2. General Block Device Layer
这一层的作用,正是解答了上面提出的第一个问题,不同的硬盘驱动,会提供不同的IO接口,内核认为这种杂乱的接口,不利于管理,需要把这些接口抽象一下,形成一个统一的对外接口,这样,不管你是什么硬盘,什么驱动,对外而言,它们所提供的IO接口没什么区别,都一视同仁的被看作块设备来处理。
所以,如果在一层做的任何修改,将会直接影响到所有文件系统,不管是ext3,ext4还是其它文件系统,只要在这一层次做了某种修改,对它们都会产生影响。
3. 文件系统
文件系统这一层相信大家都再熟悉不过了,目前大多Linux发行版本默认使用的文件系统一般是ext4,另外,新一代的btrfs也呼之欲出,不管什么样的文件系统,都是由一系列的mkfs.xxx命令来创建,如:
mkfs.ext4 /dev/sda
mkfs.btrfs /dev/sdb
内核所支持的文件系统类型,可以通过内核目录树 fs 目录中的内容来查看。
4. 虚拟文件系统(VFS)
Virtual File System这一层,正是用来解决上面提出的第二个问题,试想,当我们通过mkfs.xxx系列命令创建了很多不同的文件系统,但这些文件系统都有各自的API接口,而用户想要的是,不管你是什么API,他们只关心mount/umount,或open/close等操作。
所以,VFS就把这些不同的文件系统做一个抽象,提供统一的API访问接口,这样,用户空间就不用关心不同文件系统中不一样的API了。VFS所提供的这些统一的API,再经过System Call包装一下,用户空间就可以经过SCI的系统调用来操作不同的文件系统。
VFS所提供的常用API有:
mount(), umount() …
open(),close() …
mkdir() …
和文件系统关系最密切的就是存储介质,存储介质大致有RAM,ROM,磁盘磁带,闪存等。
闪存(Flash Memory)是一种长寿命的非易失性(在断电情况下仍能保持所存储的数据信息)的存储器,数据删除不是以单个的字节为单位而是以固定的区块为单位(注意:NOR Flash 为字节存储。),区块大小一般为256KB到20MB。闪存是电子可擦除只读存储器(EEPROM)的变种,EEPROM与闪存不同的是,它能在字节水平上进行删除和重写而不是整个芯片擦写,这样闪存就比EEPROM的更新速度快。由于其断电时仍能保存数据,闪存通常被用来保存设置信息,如在电脑的BIOS(基本输入输出程序)、PDA(个人数字助理)、数码相机中保存资料等。外存通常是磁性介质或光盘,像硬盘,软盘,磁带,CD等,能长期保存信息,并且不依赖于电来保存信息,但是由机械部件带动,速度与CPU相比就显得慢的多。内存指的就是主板上的存储部件,是CPU直接与之沟通,并用其存储数据的部件,存放当前正在使用的(即执行中)的数据和程序,它的物理实质就是一组或多组具备数据输入输出和数据存储功能的集成电路,内存只用于暂时存放程序和数据,一旦关闭电源或发生断电,其中的程序和数据就会丢失。
RAM又分为动态的和静态。。静态被用作cache,动态的常用作内存。。网上说闪存不能代替DRAM是因为闪存不像RAM(随机存取存储器)一样以字节为单位改写数据,因此不能取代RAM。这个以后可以了解下硬件的知识再来辨别.
Linux下的文件系统结构如下:

Linux启动时,第一个必须挂载的是根文件系统;若系统不能从指定设备上挂载根文件系统,则系统会出错而退出启动。之后可以自动或手动挂载其他的文件系统。因此,一个系统中可以同时存在不同的文件系统。
不同的文件系统类型有不同的特点,因而根据存储设备的硬件特性、系统需求等有不同的应用场合。在嵌入式Linux应用中,主要的存储设备为RAM(DRAM, SDRAM)和ROM(常采用FLASH存储器),常用的基于存储设备的文件系统类型包括:jffs2, yaffs, cramfs, romfs, ramdisk, ramfs/tmpfs等。
1. 基于FLASH的文件系统
Flash(闪存)作为嵌入式系统的主要存储媒介,有其自身的特性。Flash的写入操作只能把对应位置的1修改为0,而不能把0修改为1(擦除Flash就是把对应存储块的内容恢复为1),因此,一般情况下,向Flash写入内容时,需要先擦除对应的存储区间,这种擦除是以块(block)为单位进行的。
闪存主要有NOR和NAND两种技术。Flash存储器的擦写次数是有限的,NAND闪存还有特殊的硬件接口和读写时序。因此,必须针对Flash的硬件特性设计符合应用要求的文件系统;传统的文件系统如ext2等,用作Flash的文件系统会有诸多弊端。
在嵌入式Linux下,MTD(Memory Technology Device,存储技术设备)为底层硬件(闪存)和上层(文件系统)之间提供一个统一的抽象接口,即Flash的文件系统都是基于MTD驱动层的(参见上面的Linux下的文件系统结构图)。使用MTD驱动程序的主要优点在于,它是专门针对各种非易失性存储器(以闪存为主)而设计的,因而它对Flash有更好的支持、管理和基于扇区的擦除、读/写操作接口。
顺便一提,一块Flash芯片可以被划分为多个分区,各分区可以采用不同的文件系统;两块Flash芯片也可以合并为一个分区使用,采用一个文件系统。即文件系统是针对于存储器分区而言的,而非存储芯片。
(1) jffs2
JFFS文件系统最早是由瑞典Axis Communications公司基于Linux2.0的内核为嵌入式系统开发的文件系统。JFFS2是RedHat公司基于JFFS开发的闪存文件系统,最初是针对RedHat公司的嵌入式产品eCos开发的嵌入式文件系统,所以JFFS2也可以用在Linux, uCLinux中。
Jffs2: 日志闪存文件系统版本2 (Journalling Flash FileSystem v2)
主要用于NOR型闪存,基于MTD驱动层,特点是:可读写的、支持数据压缩的、基于哈希表的日志型文件系统,并提供了崩溃/掉电安全保护,提供“写平衡”支持等。缺点主要是当文件系统已满或接近满时,因为垃圾收集的关系而使jffs2的运行速度大大放慢。
目前jffs3正在开发中。关于jffs系列文件系统的使用详细文档,可参考MTD补丁包中mtd-jffs-HOWTO.txt。
jffsx不适合用于NAND闪存主要是因为NAND闪存的容量一般较大,这样导致jffs为维护日志节点所占用的内存空间迅速增大,另外,jffsx文件系统在挂载时需要扫描整个FLASH的内容,以找出所有的日志节点,建立文件结构,对于大容量的NAND闪存会耗费大量时间。
(2) yaffs:Yet Another Flash File System
yaffs/yaffs2是专为嵌入式系统使用NAND型闪存而设计的一种日志型文件系统。与jffs2相比,它减少了一些功能(例如不支持数据压缩),所以速度更快,挂载时间很短,对内存的占用较小。另外,它还是跨平台的文件系统,除了Linux和eCos,还支持WinCE, pSOS和ThreadX等。
yaffs/yaffs2自带NAND芯片的驱动,并且为嵌入式系统提供了直接访问文件系统的API,用户可以不使用Linux中的MTD与VFS,直接对文件系统操作。当然,yaffs也可与MTD驱动程序配合使用。
yaffs与yaffs2的主要区别在于,前者仅支持小页(512 Bytes) NAND闪存,后者则可支持大页(2KB) NAND闪存。同时,yaffs2在内存空间占用、垃圾回收速度、读/写速度等方面均有大幅提升。
(3) Cramfs:Compressed ROM File System
Cramfs是Linux的创始人 Linus Torvalds参与开发的一种只读的压缩文件系统。它也基于MTD驱动程序。
在cramfs文件系统中,每一页(4KB)被单独压缩,可以随机页访问,其压缩比高达2:1,为嵌入式系统节省大量的Flash存储空间,使系统可通过更低容量的FLASH存储相同的文件,从而降低系统成本。
Cramfs文件系统以压缩方式存储,在运行时解压缩,所以不支持应用程序以XIP方式运行,所有的应用程序要求被拷到RAM里去运行,但这并不代表比Ramfs需求的RAM空间要大一点,因为Cramfs是采用分页压缩的方式存放档案,在读取档案时,不会一下子就耗用过多的内存空间,只针对目前实际读取的部分分配内存,尚没有读取的部分不分配内存空间,当我们读取的档案不在内存时,Cramfs文件系统自动计算压缩后的资料所存的位置,再即时解压缩到RAM中。
另外,它的速度快,效率高,其只读的特点有利于保护文件系统免受破坏,提高了系统的可靠性。
由于以上特性,Cramfs在嵌入式系统中应用广泛。
但是它的只读属性同时又是它的一大缺陷,使得用户无法对其内容对进扩充。?
Cramfs映像通常是放在Flash中,但是也能放在别的文件系统里,使用loopback 设备可以把它安装别的文件系统里。
(4) Romfs
传统型的Romfs文件系统是一种简单的、紧凑的、只读的文件系统,不支持动态擦写保存,按顺序存放数据,因而支持应用程序以XIP(eXecute In Place,片内运行)方式运行,在系统运行时,节省RAM空间。uClinux系统通常采用Romfs文件系统。
其他文件系统:fat/fat32也可用于实际嵌入式系统的扩展存储器(例如PDA, Smartphone, 数码相机等的SD卡),这主要是为了更好的与最流行的Windows桌面操作系统相兼容。ext2也可以作为嵌入式Linux的文件系统,不过将它用于FLASH闪存会有诸多弊端。
2. 基于RAM的文件系统
(1) Ramdisk
Ramdisk是将一部分固定大小的内存当作分区来使用。它并非一个实际的文件系统,而是一种将实际的文件系统装入内存的机制,并且可以作为根文件系统。将一些经常被访问而又不会更改的文件(如只读的根文件系统)通过Ramdisk放在内存中,可以明显地提高系统的性能。
在Linux的启动阶段,initrd提供了一套机制,可以将内核映像和根文件系统一起载入内存。
(2)ramfs/tmpfs
Ramfs是Linus Torvalds开发的一种基于内存的文件系统,工作于虚拟文件系统(VFS)层,不能格式化,可以创建多个,在创建时可以指定其最大能使用的内存大小。(实际上,VFS本质上可看成一种内存文件系统,它统一了文件在内核中的表示方式,并对磁盘文件系统进行缓冲。)
Ramfs/tmpfs文件系统把所有的文件都放在RAM中,所以读/写操作发生在RAM中,可以用ramfs/tmpfs来存储一些临时性或经常要修改的数据,例如/tmp和/var目录,这样既避免了对Flash存储器的读写损耗,也提高了数据读写速度。
Ramfs/tmpfs相对于传统的Ramdisk的不同之处主要在于:不能格式化,文件系统大小可随所含文件内容大小变化。
Tmpfs的一个缺点是当系统重新引导时会丢失所有数据。
3. 网络文件系统NFS (Network File System)
NFS是由Sun开发并发展起来的一项在不同机器、不同操作系统之间通过网络共享文件的技术。在嵌入式Linux系统的开发调试阶段,可以利用该技术在主机上建立基于NFS的根文件系统,挂载到嵌入式设备,可以很方便地修改根文件系统的内容。
以上讨论的都是基于存储设备的文件系统(memory-based file system),它们都可用作Linux的根文件系统。实际上,Linux还支持逻辑的或伪文件系统(logical or pseudo file system),例如procfs(proc文件系统),用于获取系统信息,以及devfs(设备文件系统)和sysfs,用于维护设备文件。
附录:NOR闪存与NAND闪存比较
NOR FLASH
接口时序同SRAM,易使用
读取速度较快
擦除速度慢,以64-128KB的块为单位
写入速度慢(因为一般要先擦除)
随机存取速度较快,支持XIP(eXecute In Place,芯片内执行),适用于代码存储。在嵌入式系统中,常用于存放引导程序、根文件系统等。
单片容量较小,1-32MB
最大擦写次数10万次
NAND FLASH
地址/数据线复用,数据位较窄
读取速度较慢
擦除速度快,以8-32KB的块为单位
写入速度快
顺序读取速度较快,随机存取速度慢,适用于数据存储(如大容量的多媒体应用)。在嵌入式系统中,常用于存放用户文件系统等。
单片容量较大,8-128MB,提高了单元密度
三、文件存储结构
介绍文件存储结构前先来看看文件系统如何划分磁盘,创建一个文件、目录、链接的过程。
1.物理磁盘到文件系统
我们知道文件最终是保存在硬盘上的。硬盘最基本的组成部分是由坚硬金属材料制成的涂以磁性介质的盘片,不同容量硬盘的盘片数不等。每个盘片有两面,都可记录信息。盘片被分成许多扇形的区域,每个区域叫一个扇区,每个扇区可存储128×2的N次方(N=0.1.2.3)字节信息。在DOS中每扇区是128×2的2次方=512字节,盘片表面上以盘片中心为圆心,不同半径的同心圆称为磁道。硬盘中,不同盘片相同半径的磁道所组成的圆柱称为柱面。磁道与柱面都是表示不同半径的圆,在许多场合,磁道和柱面可以互换使用,我们知道,每个磁盘有两个面,每个面都有一个磁头,习惯用磁头号来区分。扇区,磁道(或柱面)和磁头数构成了硬盘结构的基本参数,帮这些参数可以得到硬盘的容量,基计算公式为:
存储容量=磁头数×磁道(柱面)数×每道扇区数×每扇区字节数
要点:
(1)硬盘有数个盘片,每盘片两个面,每个面一个磁头
(2)盘片被划分为多个扇形区域即扇区
(3)同一盘片不同半径的同心圆为磁道
(4)不同盘片相同半径构成的圆柱面即柱面
(5)公式: 存储容量=磁头数×磁道(柱面)数×每道扇区数×每扇区字节数
(6)信息记录可表示为:××磁道(柱面),××磁头,××扇区
那么这些空间又是怎么管理起来的呢?unix/linux使用了一个简单的方法。
它将磁盘块分为以下三个部分:
1) 超级块,文件系统中第一个块被称为超级块。这个块存放文件系统本身的结构信息。比如,超级块记录了每个区域的大小,超级块也存放未被使用的磁盘块的信息。
2) I-切点表。超级块的下一个部分就是i-节点表。每个i-节点就是一个对应一个文件/目录的结构,这个结构它包含了一个文件的长度、创建及修改时间、权限、所属关系、磁盘中的位置等信息。一个文件系统维护了一个索引节点的数组,每个文件或目录都与索引节点数组中的唯一一个元素对应。系统给每个索引节点分配了一个号码,也就是该节点在数组中的索引号,称为索引节点号
3) 数据区。文件系统的第3个部分是数据区。文件的内容保存在这个区域。磁盘上所有块的大小都一样。如果文件包含了超过一个块的内容,则文件内容会存放在多个磁盘块中。一个较大的文件很容易分布上千个独产的磁盘块中。
我们知道文件最终是保存在硬盘上的。硬盘最基本的组成部分是由坚硬金属材料制成的涂以磁性介质的盘片,不同容量硬盘的盘片数不等。每个盘片有两面,都可记录信息。盘片被分成许多扇形的区域,每个区域叫一个扇区,每个扇区可存储128×2的N次方(N=0.1.2.3)字节信息。在DOS中每扇区是128×2的2次方=512字节,盘片表面上以盘片中心为圆心,不同半径的同心圆称为磁道。硬盘中,不同盘片相同半径的磁道所组成的圆柱称为柱面。磁道与柱面都是表示不同半径的圆,在许多场合,磁道和柱面可以互换使用,我们知道,每个磁盘有两个面,每个面都有一个磁头,习惯用磁头号来区分。扇区,磁道(或柱面)和磁头数构成了硬盘结构的基本参数,帮这些参数可以得到硬盘的容量,基计算公式为:
存储容量=磁头数×磁道(柱面)数×每道扇区数×每扇区字节数
要点:
(1)硬盘有数个盘片,每盘片两个面,每个面一个磁头
(2)盘片被划分为多个扇形区域即扇区
(3)同一盘片不同半径的同心圆为磁道
(4)不同盘片相同半径构成的圆柱面即柱面
(5)公式: 存储容量=磁头数×磁道(柱面)数×每道扇区数×每扇区字节数
(6)信息记录可表示为:××磁道(柱面),××磁头,××扇区
那么这些空间又是怎么管理起来的呢?unix/linux使用了一个简单的方法。
它将磁盘块分为以下三个部分:
1) 超级块,文件系统中第一个块被称为超级块。这个块存放文件系统本身的结构信息。比如,超级块记录了每个区域的大小,超级块也存放未被使用的磁盘块的信息。
2) I-切点表。超级块的下一个部分就是i-节点表。每个i-节点就是一个对应一个文件/目录的结构,这个结构它包含了一个文件的长度、创建及修改时间、权限、所属关系、磁盘中的位置等信息。一个文件系统维护了一个索引节点的数组,每个文件或目录都与索引节点数组中的唯一一个元素对应。系统给每个索引节点分配了一个号码,也就是该节点在数组中的索引号,称为索引节点号
3) 数据区。文件系统的第3个部分是数据区。文件的内容保存在这个区域。磁盘上所有块的大小都一样。如果文件包含了超过一个块的内容,则文件内容会存放在多个磁盘块中。一个较大的文件很容易分布上千个独产的磁盘块中。
Linux正统的文件系统(如ext2、ext3)一个文件由目录项、inode和数据块组成。
目录项:包括文件名和inode节点号。
Inode:又称文件索引节点,是文件基本信息的存放地和数据块指针存放地。
数据块:文件的具体内容存放地。
Linux正统的文件系统(如ext2、3等)将硬盘分区时会划分出目录块、inode Table区块和data block数据区域。一个文件由一个目录项、inode和数据区域块组成。Inode包含文件的属性(如读写属性、owner等,以及指向数据块的指针),数据区域块则是文件内容。当查看某个文件时,会先从inode table中查出文件属性及数据存放点,再从数据块中读取数据。
文件存储结构大概如下:
.png)
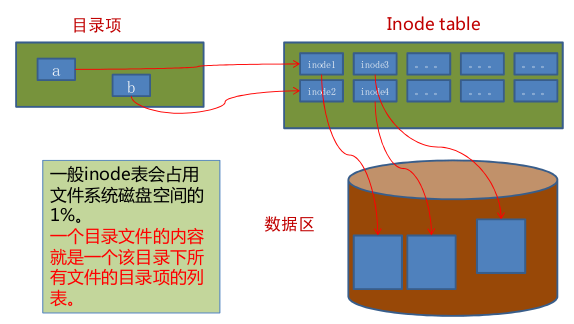
其中目录项的结构如下(每个文件的目录项存储在改文件所属目录的文件内容里):
.png)
图4:目录项结构

其中文件的inode结构如下(inode里所包含的文件信息可以通过stat filename查看得到):

.png)
以上只反映大体的结构,linux文件系统本身在不断发展。但是以上概念基本是不变的。且如ext2、ext3、ext4文件系统也存在很大差别,如果要了解可以查看专门的文件系统介绍。
目录项:包括文件名和inode节点号。
Inode:又称文件索引节点,是文件基本信息的存放地和数据块指针存放地。
数据块:文件的具体内容存放地。
Linux正统的文件系统(如ext2、3等)将硬盘分区时会划分出目录块、inode Table区块和data block数据区域。一个文件由一个目录项、inode和数据区域块组成。Inode包含文件的属性(如读写属性、owner等,以及指向数据块的指针),数据区域块则是文件内容。当查看某个文件时,会先从inode table中查出文件属性及数据存放点,再从数据块中读取数据。
文件存储结构大概如下:
其中目录项的结构如下(每个文件的目录项存储在改文件所属目录的文件内容里):
图4:目录项结构
其中文件的inode结构如下(inode里所包含的文件信息可以通过stat filename查看得到):
以上只反映大体的结构,linux文件系统本身在不断发展。但是以上概念基本是不变的。且如ext2、ext3、ext4文件系统也存在很大差别,如果要了解可以查看专门的文件系统介绍。
2. 创建一个文件的过程
我们从前面可以知道文件的内容和属性是分开存放的,那么又是如何管理它们的呢?现在我们以创建一个文件为例来讲解。
在命令行输入命令:
$ who > userlist
当完成这个命令时。文件系统中增加了一个存放命令who输出内容的新文件userlist,那么这整个过程到底是怎么回事呢?
文件主要有属性、内容以及文件名三项。内核将文件内容存放在数据区,文件属性存放在i-节点,文件名存放在目录中。
创建成功一个文件主要有以下四个步骤:
1) 存储属性 也就是文件属性的存储,内核先找到一块空的i-节点。例如,内核找到i-节点号921130。内核把文件的信息记录其中。如文件的大小、文件所有者、和创建时间等。
2) 存储数据 即文件内容的存储,由于该文件需要3个数据块。因此内核从自由块的列表中找到3个自由块。如600、200、992,内核缓冲区的第一块数据复制到块600,第二和第三分别复制到922和600.
3) 记录分配情况,数据保存到了三个数据块中。所以必须要记录起来,以后再找到正确的数据。分配情况记录在文件的i-节点中的磁盘序号列表里。这3个编号分别放在最开始的3个位置。
4) 添加文件名到目录,新文件的名字是userlist 内核将文件的入口(47,userlist)添加到目录文件里。文件名和i-节点号之间的对应关系将文件名和文件和文件的内容属性连接起来,找到文件名就找到文件的i-节点号,通过i-节点号就能找到文件的属性和内容。
代码具体实现过程参考:
我们从前面可以知道文件的内容和属性是分开存放的,那么又是如何管理它们的呢?现在我们以创建一个文件为例来讲解。
在命令行输入命令:
$ who > userlist
当完成这个命令时。文件系统中增加了一个存放命令who输出内容的新文件userlist,那么这整个过程到底是怎么回事呢?
文件主要有属性、内容以及文件名三项。内核将文件内容存放在数据区,文件属性存放在i-节点,文件名存放在目录中。
创建成功一个文件主要有以下四个步骤:
1) 存储属性 也就是文件属性的存储,内核先找到一块空的i-节点。例如,内核找到i-节点号921130。内核把文件的信息记录其中。如文件的大小、文件所有者、和创建时间等。
2) 存储数据 即文件内容的存储,由于该文件需要3个数据块。因此内核从自由块的列表中找到3个自由块。如600、200、992,内核缓冲区的第一块数据复制到块600,第二和第三分别复制到922和600.
3) 记录分配情况,数据保存到了三个数据块中。所以必须要记录起来,以后再找到正确的数据。分配情况记录在文件的i-节点中的磁盘序号列表里。这3个编号分别放在最开始的3个位置。
4) 添加文件名到目录,新文件的名字是userlist 内核将文件的入口(47,userlist)添加到目录文件里。文件名和i-节点号之间的对应关系将文件名和文件和文件的内容属性连接起来,找到文件名就找到文件的i-节点号,通过i-节点号就能找到文件的属性和内容。
代码具体实现过程参考:
3.创建一个目录的过程
前面说了创建一个文件的大概过程,也了解文件内容、属性以及入口的保存方式,那么创建一个目录时又是怎么回事呢?
我现在test目录使用命令mkdir 新增一个子目录child:
从用户的角度看,目录child是目录test的一个子目录,那么在系统中这层关系是怎么实现的呢?实际上test目录包含一个指向子目录child的i-节点的链接,原理跟普通文件一样,因为目录也是文件。
目录其实也是文件,只是它的内容比较特殊。所以它的创建过程和文件创建过程一样,只是第二步写的内容不同。
1) 系统找到空闲的i-节点号887220,写入目录的属性
2) 找到空闲的数据块1002来存储目录的内容,只是目录的内容比较特殊,包含文件名字列表,列表一般包含两个部分:i-节点号和文件名,这个列表其实也就是文件的入口,新建的目录至少包含三个目录”.”和”..”其中”.”指向自己,”..”指向上级目录,我们可以通过比较对应的i-节点号来验证,887270 对应着上级目录中的child对应的i-节点号
3) 记录分配情况。这个和创建文件完全一样
4) 添加目录的入口到父目录,即在父目录中的child入口。
一般都说文件存放在某个目录中,其实目录中存入的只是文件在i-节点表的入口,而文件的内容则存储在数据区。我们一般会说“文件userlist在目录test中”,其实这意味着目录test中有一个指向i-节点921130的链接,这个链接所附加的文件名为userlist,这也可以这样理解:目录包含的是文件的引用,每个引用被称为链接。文件的内容存储在数据块。文件的属性被记录在一个被称为i-节点的结构中。I-节点的编号和文件名关联起来存在目录中。
注意:其中“.”表示是当前目录。而“..”是当前目录的父目录。但也有特殊情况:如我们查看根目录/的情况:
发现“.”和“..”都指向i-节点2。实际上当我们用mkfs创建一个文件系统时,mkfs都会将根目录的父目录指向自己。所以根目录下.和..指向同一个i-节点也不奇怪了。
代码具体实现参考:
前面说了创建一个文件的大概过程,也了解文件内容、属性以及入口的保存方式,那么创建一个目录时又是怎么回事呢?
我现在test目录使用命令mkdir 新增一个子目录child:
从用户的角度看,目录child是目录test的一个子目录,那么在系统中这层关系是怎么实现的呢?实际上test目录包含一个指向子目录child的i-节点的链接,原理跟普通文件一样,因为目录也是文件。
目录其实也是文件,只是它的内容比较特殊。所以它的创建过程和文件创建过程一样,只是第二步写的内容不同。
1) 系统找到空闲的i-节点号887220,写入目录的属性
2) 找到空闲的数据块1002来存储目录的内容,只是目录的内容比较特殊,包含文件名字列表,列表一般包含两个部分:i-节点号和文件名,这个列表其实也就是文件的入口,新建的目录至少包含三个目录”.”和”..”其中”.”指向自己,”..”指向上级目录,我们可以通过比较对应的i-节点号来验证,887270 对应着上级目录中的child对应的i-节点号
3) 记录分配情况。这个和创建文件完全一样
4) 添加目录的入口到父目录,即在父目录中的child入口。
一般都说文件存放在某个目录中,其实目录中存入的只是文件在i-节点表的入口,而文件的内容则存储在数据区。我们一般会说“文件userlist在目录test中”,其实这意味着目录test中有一个指向i-节点921130的链接,这个链接所附加的文件名为userlist,这也可以这样理解:目录包含的是文件的引用,每个引用被称为链接。文件的内容存储在数据块。文件的属性被记录在一个被称为i-节点的结构中。I-节点的编号和文件名关联起来存在目录中。
注意:其中“.”表示是当前目录。而“..”是当前目录的父目录。但也有特殊情况:如我们查看根目录/的情况:
发现“.”和“..”都指向i-节点2。实际上当我们用mkfs创建一个文件系统时,mkfs都会将根目录的父目录指向自己。所以根目录下.和..指向同一个i-节点也不奇怪了。
代码具体实现参考:
4. 理解链接
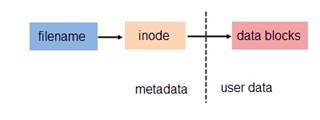
我们知道文件都有文件名与数据,这在 Linux 上被分成两个部分:用户数据 (user data) 与元数据 (metadata)。用户数据,即文件数据块 (data block),数据块是记录文件真实内容的地方;而元数据则是文件的附加属性,如文件大小、创建时间、所有者等信息。在 Linux 中,元数据中的 inode 号(inode 是文件元数据的一部分但其并不包含文件名,inode 号即索引节点号)才是文件的唯一标识而非文件名。文件名仅是为了方便人们的记忆和使用,系统或程序通过 inode 号寻找正确的文件数据块。图 1.展示了程序通过文件名获取文件内容的过程。
图 1. 通过文件名打开文件
.png)
图 1. 通过文件名打开文件
清单 3. 移动或重命名文件

# stat /home/harris/source/glibc-2.16.0.tar.xz
File: `/home/harris/source/glibc-2.16.0.tar.xz'
Size: 9990512 Blocks: 19520 IO Block: 4096 regular file
Device: 807h/2055d Inode: 2485677 Links: 1
Access: (0600/-rw-------) Uid: ( 1000/ harris) Gid: ( 1000/ harris)
...
...
# mv /home/harris/source/glibc-2.16.0.tar.xz /home/harris/Desktop/glibc.tar.xz
# ls -i -F /home/harris/Desktop/glibc.tar.xz
2485677 /home/harris/Desktop/glibc.tar.xz
在 Linux 系统中查看 inode 号可使用命令 stat 或 ls -i(若是 AIX 系统,则使用命令 istat)。清单
3.中使用命令 mv 移动并重命名文件 glibc-2.16.0.tar.xz,其结果不影响文件的用户数据及 inode 号,文件移动前后
inode 号均为:2485677。
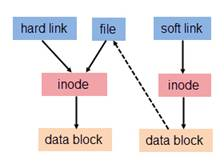
为解决文件的共享使用,Linux 系统引入了两种链接:硬链接 (hard link) 与软链接(又称符号链接,即 soft link 或 symbolic link)。
具体关系可以看下图:
为 Linux
系统解决了文件的共享使用,还带来了隐藏文件路径、增加权限安全及节省存储等好处。若一个 inode
号对应多个文件名,则称这些文件为硬链接。换言之,硬链接就是同一个文件使用了多个别名(见 图 2.hard link 就是 file
的一个别名,他们有共同的 inode)。硬链接可由命令 link 或 ln 创建。如下是对文件 oldfile 创建硬链接。
link oldfile newfile
ln oldfile newfile
由于硬链接是有着相同 inode 号仅文件名不同的文件,因此硬链接存在以下几点特性:
文件有相同的 inode 及 data block;
只能对已存在的文件进行创建;
不能交叉文件系统进行硬链接的创建;
不能对目录进行创建,只可对文件创建;
删除一个硬链接文件并不影响其他有相同 inode 号的文件。
创建一个链接的步骤大概如下:
1) 通过原文件的文件名找到文件的i-节点号
2) 添加文件名关联到目录,新文件的名字是mylink 内核将文件的入口(921130,mylink)添加到目录文件里。
和创建文件的过程比较发现,链接少了写文件内容的步骤,完全相同的是把文件名关联到目录这一步
现在.i- 节点号921130对应了两个文件名。链接数也会变成2个,文件的内容并不会发生任何变化。前面我们已经讲了:目录包含的是文件的引用,每个引用被称为链接。所以链接文件和原始文件本质上是一样的,因为它们都是指向同一个i-节点。由于此原因也就可以理解链接的下列特性:你改变其中任何一个文件的内容,别的链接文件也一样是变化;另外如果你删除某一个文件,系统只会在所指向的i-节点上把链接数减1,只有当链接数减为零时才会真正释放i-节点。
硬链接有两个特点:
1)不能跨文件系统
2)不能对目录
link oldfile newfile
ln oldfile newfile
由于硬链接是有着相同 inode 号仅文件名不同的文件,因此硬链接存在以下几点特性:
文件有相同的 inode 及 data block;
只能对已存在的文件进行创建;
不能交叉文件系统进行硬链接的创建;
不能对目录进行创建,只可对文件创建;
删除一个硬链接文件并不影响其他有相同 inode 号的文件。
1) 通过原文件的文件名找到文件的i-节点号
2) 添加文件名关联到目录,新文件的名字是mylink 内核将文件的入口(921130,mylink)添加到目录文件里。
和创建文件的过程比较发现,链接少了写文件内容的步骤,完全相同的是把文件名关联到目录这一步
现在.i- 节点号921130对应了两个文件名。链接数也会变成2个,文件的内容并不会发生任何变化。前面我们已经讲了:目录包含的是文件的引用,每个引用被称为链接。所以链接文件和原始文件本质上是一样的,因为它们都是指向同一个i-节点。由于此原因也就可以理解链接的下列特性:你改变其中任何一个文件的内容,别的链接文件也一样是变化;另外如果你删除某一个文件,系统只会在所指向的i-节点上把链接数减1,只有当链接数减为零时才会真正释放i-节点。
硬链接有两个特点:
1)不能跨文件系统
2)不能对目录
清单 4. 硬链接特性展示
# ls -li
total 0
// 只能对已存在的文件创建硬连接
# link old.file hard.link
link: cannot create link `hard.link' to `old.file': No such file or directory
# echo "This is an original file" > old.file
# cat old.file
This is an original file
# stat old.file
File: `old.file'
Size: 25 Blocks: 8 IO Block: 4096 regular file
Device: 807h/2055d Inode: 660650 Links: 2
Access: (0644/-rw-r--r--) Uid: ( 0/ root) Gid: ( 0/ root)
...
// 文件有相同的 inode 号以及 data block
# link old.file hard.link | ls -li
total 8
660650 -rw-r--r-- 2 root root 25 Sep 1 17:44 hard.link
660650 -rw-r--r-- 2 root root 25 Sep 1 17:44 old.file
// 不能交叉文件系统
# ln /dev/input/event5 /root/bfile.txt
ln: failed to create hard link `/root/bfile.txt' => `/dev/input/event5':
Invalid cross-device link
// 不能对目录进行创建硬连接
# mkdir -p old.dir/test
# ln old.dir/ hardlink.dir
ln: `old.dir/': hard link not allowed for directory
# ls -iF
660650 hard.link 657948 old.dir/ 660650 old.file
软链接与硬链接不同,若文件用户数据块中存放的内容是另一文件的路径名的指向,则该文件就是软连接。软链接就是一个普通文件,只是数据块内容有点特殊。软链接有着自己的 inode 号以及用户数据块(见 图 2.)。因此软链接的创建与使用没有类似硬链接的诸多限制:
软链接有自己的文件属性及权限等;
可对不存在的文件或目录创建软链接;
软链接可交叉文件系统;
软链接可对文件或目录创建;
创建软链接时,链接计数 i_nlink 不会增加;
删除软链接并不影响被指向的文件,但若被指向的原文件被删除,则相关软连接被称为死链接(即 dangling link,若被指向路径文件被重新创建,死链接可恢复为正常的软链接)。
软链接有自己的文件属性及权限等;
可对不存在的文件或目录创建软链接;
软链接可交叉文件系统;
软链接可对文件或目录创建;
创建软链接时,链接计数 i_nlink 不会增加;
删除软链接并不影响被指向的文件,但若被指向的原文件被删除,则相关软连接被称为死链接(即 dangling link,若被指向路径文件被重新创建,死链接可恢复为正常的软链接)。
图 2. 软链接的访问
.png)
软链接
实际上只是一段文字,里面包含着它所指向的文件的名字,系统看到软链接后自动跳到对应的文件位置处进行处理;相反,硬链接为文件开设一个新的目录项,硬链接与文件原有的名字是平权的,在Linux看来它们是等价的。由于这个原因,硬链接不能连接两个不同文件系统上的文件。
软连接与windows下的快捷方式类似
至于硬连接,举个例子说吧,你把dir1/file1硬连接到dir2/file2, 就是在dir2下建立一个dir1/file1的镜像文件file2,它与file1是占用一样大的空间的,并且改动两者中的一个,另一个也会发生同样的改动.
软连接和硬连接可以这样理解:
硬连接就像一个文件有多个文件名,
软连接就是产生一个新文件(这个文件内容,实际上就是记当要链接原文件路径的信息),这个文件指向另一个文件的位置,
硬连接必须在同一文件系统中,而软连接可以跨文件系统
硬连接 :源文件名和链接文件名都指向相同的物理地址,目录不能够有硬连接,文件在磁盘中只有一个复制,可以节省硬盘空间,由于删除文件要在同一个索引节点属于唯一的连接时才能成功,因此可以防止不必要的误删除软连接(符号连接)用ln -s命令创建文件的符号连接,符号连接是linux特殊文件的一种,作为一个文件,它的资料是它所连接的文件的路径名,类似于硬件方式,******可以删除原始文件 而连接文件仍然存在。********
软连接与windows下的快捷方式类似
至于硬连接,举个例子说吧,你把dir1/file1硬连接到dir2/file2, 就是在dir2下建立一个dir1/file1的镜像文件file2,它与file1是占用一样大的空间的,并且改动两者中的一个,另一个也会发生同样的改动.
软连接和硬连接可以这样理解:
硬连接就像一个文件有多个文件名,
软连接就是产生一个新文件(这个文件内容,实际上就是记当要链接原文件路径的信息),这个文件指向另一个文件的位置,
硬连接必须在同一文件系统中,而软连接可以跨文件系统
硬连接 :源文件名和链接文件名都指向相同的物理地址,目录不能够有硬连接,文件在磁盘中只有一个复制,可以节省硬盘空间,由于删除文件要在同一个索引节点属于唯一的连接时才能成功,因此可以防止不必要的误删除软连接(符号连接)用ln -s命令创建文件的符号连接,符号连接是linux特殊文件的一种,作为一个文件,它的资料是它所连接的文件的路径名,类似于硬件方式,******可以删除原始文件 而连接文件仍然存在。********
清单 5. 软链接特性展示
# ls -li
total 0
// 可对不存在的文件创建软链接
# ln -s old.file soft.link
# ls -liF
total 0
789467 lrwxrwxrwx 1 root root 8 Sep 1 18:00 soft.link -> old.file
// 由于被指向的文件不存在,此时的软链接 soft.link 就是死链接
# cat soft.link
cat: soft.link: No such file or directory
// 创建被指向的文件 old.file,soft.link 恢复成正常的软链接
# echo "This is an original file_A" >> old.file
# cat soft.link
This is an original file_A
// 对不存在的目录创建软链接
# ln -s old.dir soft.link.dir
# mkdir -p old.dir/test
# tree . -F --inodes
.
├── [ 789497] old.dir/
│ └── [ 789498] test/
├── [ 789495] old.file
├── [ 789495] soft.link -> old.file
└── [ 789497] soft.link.dir -> old.dir/
四、文件节点inode
可以看到inode节点好比是文件的大脑,下面就详细介绍一下inode。
1.inode是什么

.png)

理解inode,要从文件储存说起。
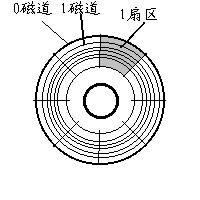
扇区(sector):硬件(磁盘)上的最小的操作单位,是操作系统和块设备(硬件、磁盘)之间传送数据的单位。
block由一个或多个sector组成,文件系统中最小的操作单位;OS的虚拟文件系统从硬件设备上读取一个block,实际为从硬件设备读取一个或多个sector。对于文件管理来说,每个文件对应的多个block可能是不连续的;
block最终要映射到sector上,所以block的大小一般是sector的整数倍。不同的文件系统block可使用不同的大小,操作系统会在内存中开辟内存,存放block到所谓的block buffer中。在Ext2中,物理块的大小是可变化的,这取决于在创建文件系统时的选择,之所以不限制大小,也正体现了Ext2的灵活性和可扩充性。通常,Ext2的物理块占一个或几个连续的扇区,显然,物理块的数目是由磁盘容量等硬件因素决定的。具体文件系统所操作的基本单位是逻辑块,只在需要进行I/O操作时才进行逻辑块到物理块的映射,这显然避免了大量的I/O操作,因而文件系统能够变得高效。逻辑块作为一个抽象的概念,它必然要映射到具体的物理块上去,因此,逻辑块的大小必须是物理块大小的整数倍,一般说来,两者是一样大的。
通常,一个文件占用的多个物理块在磁盘上是不连续存储的,因为如果连续存储,则经过频繁的删除、建立、移动文件等操作,最后磁盘上将形成大量的空洞,很快磁盘上将无空间可供使用。因此,必须提供一种方法将一个文件占用的多个逻辑块映射到对应的非连续存储的物理块上去,Ext2等类文件系统是用索引节点解决这个问题的。
block由一个或多个sector组成,文件系统中最小的操作单位;OS的虚拟文件系统从硬件设备上读取一个block,实际为从硬件设备读取一个或多个sector。对于文件管理来说,每个文件对应的多个block可能是不连续的;
block最终要映射到sector上,所以block的大小一般是sector的整数倍。不同的文件系统block可使用不同的大小,操作系统会在内存中开辟内存,存放block到所谓的block buffer中。在Ext2中,物理块的大小是可变化的,这取决于在创建文件系统时的选择,之所以不限制大小,也正体现了Ext2的灵活性和可扩充性。通常,Ext2的物理块占一个或几个连续的扇区,显然,物理块的数目是由磁盘容量等硬件因素决定的。具体文件系统所操作的基本单位是逻辑块,只在需要进行I/O操作时才进行逻辑块到物理块的映射,这显然避免了大量的I/O操作,因而文件系统能够变得高效。逻辑块作为一个抽象的概念,它必然要映射到具体的物理块上去,因此,逻辑块的大小必须是物理块大小的整数倍,一般说来,两者是一样大的。
通常,一个文件占用的多个物理块在磁盘上是不连续存储的,因为如果连续存储,则经过频繁的删除、建立、移动文件等操作,最后磁盘上将形成大量的空洞,很快磁盘上将无空间可供使用。因此,必须提供一种方法将一个文件占用的多个逻辑块映射到对应的非连续存储的物理块上去,Ext2等类文件系统是用索引节点解决这个问题的。
文件数据都储存在"块"中,那么很显然,我们还必须找到一个地方储存文件的元信息,比如文件的创建者、文件的创建日期、文件的大小等等。这种储存文件元信息的区域就叫做inode,中文译名为"索引节点"。
在Unix/Linux上,一个文件由一个inode 表示。inode在系统管理员看来是每一个文件的唯一标识,在系统里面,inode是一个结构,存储了关于这个文件的大部分信息。
2.inode内容
inode包含文件的元信息,具体来说有以下内容:
*文件的字节数
*文件拥有者的UserID*文件的GroupID
*文件的读、写、执行权限
*文件的时间戳,共有三个:ctime指inode上一次变动的时间,mtime指文件内容上一次变动的时间,atime指文件上一次打开的时间。
*链接数,即有多少文件名指向这个inode*文件数据block的位置可以用stat命令,查看某个文件的inode信息:statexample.txt
总之,除了文件名以外的所有文件信息,都存在inode之中。至于为什么没有文件名,下文会有详细解释。
inode中存储了一个文件的以下信息:inode包含文件的元信息,具体来说有以下内容:
*文件的字节数
*文件拥有者的UserID*文件的GroupID
*文件的读、写、执行权限
*文件的时间戳,共有三个:ctime指inode上一次变动的时间,mtime指文件内容上一次变动的时间,atime指文件上一次打开的时间。
*链接数,即有多少文件名指向这个inode*文件数据block的位置可以用stat命令,查看某个文件的inode信息:statexample.txt
总之,除了文件名以外的所有文件信息,都存在inode之中。至于为什么没有文件名,下文会有详细解释。
3.inode结构
struct inode {
struct hlist_node i_hash; /* 哈希表 */
struct list_head i_list; /* 索引节点链表 */
struct list_head i_dentry; /* 目录项链表 */
unsigned long i_ino; /* 节点号 */
atomic_t i_count; /* 引用记数 */
umode_t i_mode; /* 访问权限控制 */
unsigned int i_nlink; /* 硬链接数 */
uid_t i_uid; /* 使用者id */
gid_t i_gid; /* 使用者id组 */
kdev_t i_rdev; /* 实设备标识符 */
loff_t i_size; /* 以字节为单位的文件大小 */
struct timespec i_atime; /* 最后访问时间 */
struct timespec i_mtime; /* 最后修改(modify)时间 */
struct timespec i_ctime; /* 最后改变(change)时间 */
unsigned int i_blkbits; /* 以位为单位的块大小 */
unsigned long i_blksize; /* 以字节为单位的块大小 */
unsigned long i_version; /* 版本号 */
unsigned long i_blocks; /* 文件的块数 */
unsigned short i_bytes; /* 使用的字节数 */
spinlock_t i_lock; /* 自旋锁 */
struct rw_semaphore i_alloc_sem; /* 索引节点信号量 */
struct inode_operations *i_op; /* 索引节点操作表 */
struct file_operations *i_fop; /* 默认的索引节点操作 */
struct super_block *i_sb; /* 相关的超级块 */
struct file_lock *i_flock; /* 文件锁链表 */
struct address_space *i_mapping; /* 相关的地址映射 */
struct address_space i_data; /* 设备地址映射 */
struct dquot *i_dquot[MAXQUOTAS]; /* 节点的磁盘限额 */
struct list_head i_devices; /* 块设备链表 */
struct pipe_inode_info *i_pipe; /* 管道信息 */
struct block_device *i_bdev; /* 块设备驱动 */
unsigned long i_dnotify_mask; /* 目录通知掩码 */
struct dnotify_struct *i_dnotify; /* 目录通知 */
unsigned long i_state; /* 状态标志 */
unsigned long dirtied_when; /* 首次修改时间 */
unsigned int i_flags; /* 文件系统标志 */
unsigned char i_sock; /* 可能是个套接字吧 */
atomic_t i_writecount; /* 写者记数 */
void *i_security; /* 安全模块 */
__u32 i_generation; /* 索引节点版本号 */
union {
void *generic_ip; /* 文件特殊信息 */
} u;
};
inode就是一个文件的一部分描述,不是全部,在内核中,inode对应了这样一个实际存在的结构。
纵观整个inode的C语言描述,没有发现关于文件名的东西,也就是说文件名不由inode保存,实际上系统是不关心文件名的,对于系统中任何的操作,大部分情况下你都是通过文件名来做的,但系统最终都要通过找到文件对应的inode来操作文件,由inode结构中 *i_op指向的接口来操作。
文件系统如何存取文件的:
1)、根据文件名,通过Directory里的对应关系,找到文件对应的Inodenumber
文件系统如何存取文件的:
1)、根据文件名,通过Directory里的对应关系,找到文件对应的Inodenumber
2)、再根据Inodenumber读取到文件的Inodetable
3)、再根据Inodetable中的Pointer读取到相应的Blocks
这里有一个重要的内容,就是Directory,他不是我们通常说的目录,而是一个列表,记录了一个文件/目录名称对应的Inodenumber。
3)、再根据Inodetable中的Pointer读取到相应的Blocks
这里有一个重要的内容,就是Directory,他不是我们通常说的目录,而是一个列表,记录了一个文件/目录名称对应的Inodenumber。