摘要:
本章所讨论的问题是在一个由n个不同数值构成的集合中选择第i个顺序统计量问题。主要讲的内容是如何在线性时间内O(n)时间内在集合S中选择第i小的元素,最基本的是选择集合的最大值和最小值。一般情况下选择的元素是随机的,最大值和最小值是特殊情况,书中重点介绍了如何采用分治算法来实现选择第i小的元素,并借助中位数进行优化处理,保证最坏保证运行时间是线性的O(n)。
1、基本概念
顺序统计量:在一个由n个元素组成的集合中,第i个顺序统计量是值该集合中第i小的元素。例如最小值是第1个顺序统计量,最大值是第n个顺序统计量。
中位数:一般来说,中位数是指它所在集合的“中间元素”,当n为奇数时,中位数是唯一的,出现位置为n/2;当n为偶数时候,存在两个中位数,位置分别为n/2(上中位数)和n/2+1(下中位数)。
2、选择问题描述
输入:一个包含n个(不同的)数的集合A和一个数i,1≤i≤n。
输出:元素x∈A,它恰大于A中其他的i-1个元素。
最直接的办法就是采用一种排序算法先对集合A进行排序,然后输出第i个元素即可。可以采用前面讲到的归并排序、堆排序和快速排序,运行时间为O(nlgn)。接下来书中由浅入深的讲如何在线性时间内解决这个问题。
3、最大值和最小值
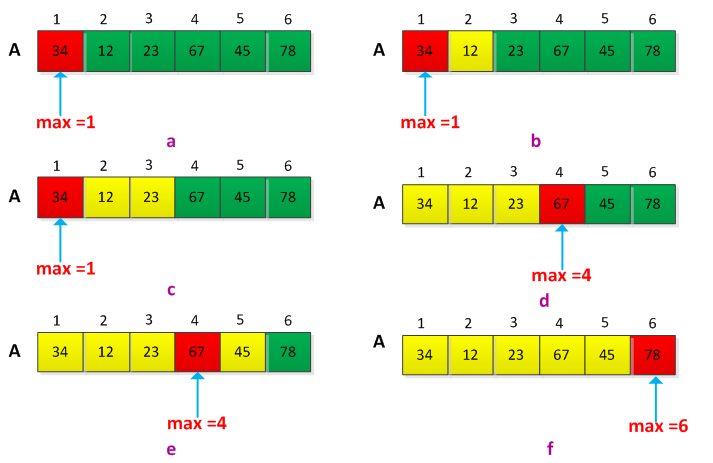
要在集合中选择最大值和最小值,可以通过两两元素比较,并记录最大值和最小值,n元素的集合需要比较n-1次,这样运行时间为O(n)。举个例子来说明,现在要求和集合A={32,12,23,67,45,78}的最大值,开始假设第一个元素最大,即max=1,然后从第二个元素开始向后比较,记录最大值的位置。执行过程如下图所示:
书中给出的求最小值的伪代码如下:
1 MINMUN(A) 2 min = A[1] 3 for i=1 to length(A) 4 do if min > A[i] 5 then min >= A[i] 6 return min
C++代码:
#include<iostream>using namespace std;int Minimum(int arr[],int n){ int i; int min=arr[0]; for(i=1;i<n;i++) if(arr[i]<min) min=arr[i]; return min;}int main(){ int arr[10]={14,38,46,7,30,5,87,9,3,56}; cout<<Minimum(arr,10)<<endl;}问题:
(1)同时找出集合的最大值和最小值
方法1:按照上面讲到的方法,分别独立的找出集合的最大值和最小值,各用n-1次比较,共有2n-2次比较。
#include<iostream>using namespace std;void FindMaxMin(int arr[],int n){ int i; int max,min; max=min=arr[0]; for(i=1;i<n;i++) { if(arr[i]<min) min=arr[i]; else if(arr[i]>max) max=arr[i]; } cout<<"minimum: "<<min<<" maximum: "<<max<<endl;}int main(){ int arr[10]={14,38,46,7,30,5,87,9,3,56}; FindMaxMin(arr,10);}方法2:可否将最大值和最小值结合在一起寻找呢?答案是可以的,在两两比较过程中同时记录最大值和最小值,这样最大需要3n/2次比较。现在的做法不是将每一个 输入元素与当前的最大值和最小值进行比较,而是成对的处理元素,先将一对输入元素进行比较,然后把较大者与当前最大值比较,较小者与当前最小者比较,因此每两个元素需要3次比较。初始设置最大值和最小值方法:如何n为奇数,就将最大值和最小值都设置为第一个元素的值,然后成对的处理后续的元素。如果n为偶数,那么先比较前面两个元素的值,较大的设置为最大值,较小的设置为最小值,然后成对处理后续的元素。这样做的目的保证能够成对的处理后续的元素。举个例子说明这个过程,假设现在要找出集合A={32,23,12,67,45,78,10,39,9,58}最大值和最小值,执行过程如下: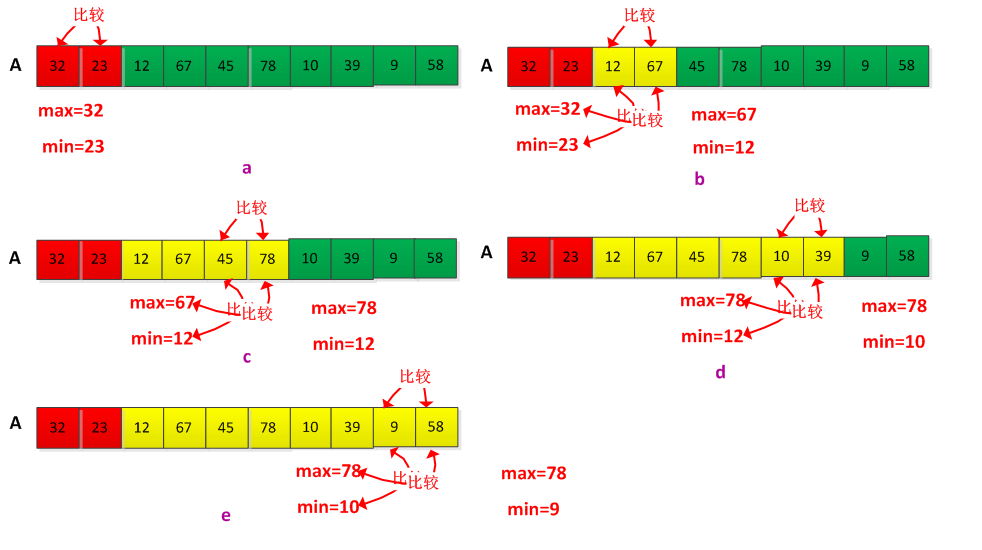
从图中可以看出方法2要比方法一要好,减少了元素之间的比较次数。现在用C语言实现方法2,程序如下:
#include<iostream>using namespace std;void MinMax(int arr[],int n){ int min,max; int i; min=max=arr[0]; for(i=0;i<n;i+=2) { if(i+1<n&&arr[i]<arr[i+1]) { if(arr[i]<min) min=arr[i]; if(arr[i+1]>max) max=arr[i+1]; } else if(i+1<n&&arr[i]>arr[i+1]) { if(arr[i+1]<min) min=arr[i+1]; if(arr[i]>max) max=arr[i]; } else if(i+1>=n) { if(arr[i]>max) max=arr[i]; if(arr[i]<min) min=arr[i]; } } cout<<"Minimum: "<<min<<" Maximum: "<<max<<endl;}int main(){ int arr[11]={14,38,46,7,30,5,87,9,3,56,778}; MinMax(arr,11);}(2)如何找出找出n个元素中的第2小元素。
解答:类似与上面的同时找出最大值和最小值的方法2,变成同时找最小值和第2小元素值。先初始化最小值和第2小的值,然后成对比较后续的元素,找出较小的元素与当前最小值和第二小值进行比较,在三者中找出最小值和第二小值。
4、以期望线性时间做选择
一般的选择问题似乎要比选择最大值和最小值要难,但是这两种问题的运行时间是相同的,都是θ(n)。书中介绍了采用分治算法解决一般的选择问题,其过程与快速排序过程中划分类似。每次划分集合可以确定一个元素的最终位置,根据这个位置可以判断是否是我们要求的第i小的元素。如果不是,那么我们只关心划分产出两个子部分中的其中一个,根据i的值来判断是前一个还是后一个,然后接着对子数组进行划分,重复此过程,直到找到第i个小的元素。划分可以采用随机划分,这样能够保证期望时间是θ(n)(假设所有元素是不同的)。
给个例子说明此过程,假设现有集合A={32,23,12,67,45,78,10,39,9,58},要求其第5小的元素,假设在划分过程中以总是以最后一个元素为主元素进行划分。执行过程如下图所示:
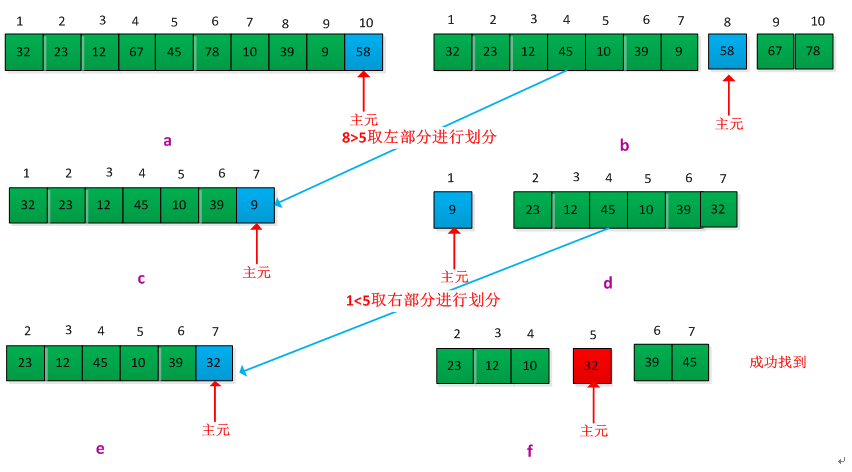
书中给出了返回A[p...r]中的第i小元素的伪代码:
1 RANDOMIZED_SELECT(A,p,r,i) 2 if p==r 3 then return A[p] 4 q = RANDOMIZED_PARTITION(A,p,r) 5 k = q-p+1; 6 if i==k 7 then return A[q] 8 else if i<k 9 then return RANDOMIZED_SELECT(A,p,q-1,i) 10 else 11 return RANDOMIZED_SELECT(A,p,q-1,i-k)
RANDOMIZED_SELECT通过对输入数组的递归划分来找出所求元素,该算法要保证对数组的划分是个好划分才更加高效。RANDOMIZED_SELECT的最坏情况运行时间为θ(n^2),即使是选择最小元素也是如此。因为在每次划分过程中,导致划分后两边不对称,总好是按照剩下元素中最大的划分进行。
#include<iostream>#include<cstdlib>#include<time.h>using namespace std;void swap(int *a,int *b){ int temp=*a; *a=*b; *b=temp;}int randomized_partition(int arr[],int p,int r){ int len,i,j,index; len = r-p+1; //随机获取一个主元 srand(time(NULL)); index = p + rand()%len; //将主元交换到末尾 swap(arr+index,arr+r); //从第一个元素开始向后查找主元的位置 i=p,j=r-1; int key=arr[r]; while(i<=j) { while(i<=j&&arr[i]<=key) i++; while(i<=j&&arr[j]>key) j--; if(i<j) swap(&arr[i++],&arr[j--]); } swap(&arr[i],&arr[r]); return i;}/*int randomized_partition(int* datas,int beg,int last){ int len,i,j,index; len = last-beg+1; //随机获取一个主元 srand(time(NULL)); index = beg + rand()%len; //将主元交换到末尾 swap(datas+index,datas+last); //从第一个元素开始向后查找主元的位置 i=beg; for(j=beg;j<last;j++) { if(datas[j] < datas[last]) { swap(datas+i,datas+j); i++; } } //最终确定主元的位置 swap(datas+i,datas+last); return i;}*/int RandomizedSelect(int arr[],int p,int r,int i){ int k,q; if(p==r) return arr[p]; //q为主元的下标 q=randomized_partition(arr,p,r); //k为主元为第k小的元素 k=q-p+1; if(k==i) return arr[q]; else if(i<k) return RandomizedSelect(arr,p,q-1,i); else return RandomizedSelect(arr,q+1,r,i-k);}int main(){ int arr[11]={14,38,46,7,30,5,87,9,3,56,778}; cout<<RandomizedSelect(arr,0,10,5)<<endl;}5、最坏情况线性时间的选择
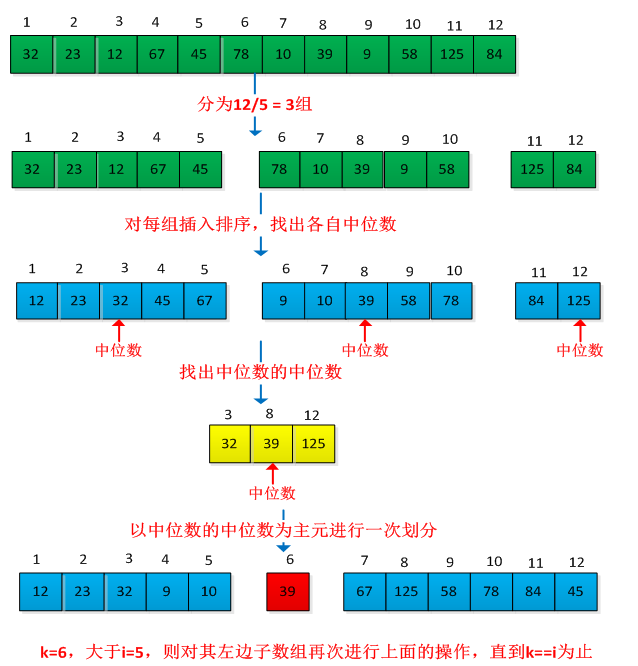
SELECT算法的思想是要保证对数组的划分是个好的划分,对PARTITION过程进行了修改。现在通过SELECT算法来确定n个元素的输入数组中的第i小的元素,具体操作步骤如下:
(1)将输入数组的n个元素划分为n/5(上取整)组,每组5个元素,且至多只有一个组有剩下的n%5个元素组成。(为何是5,而不是其他数,有点不明白。)
(2)寻找每个组织中中位数。首先对每组中的元素(至多为5个)进行插入排序,然后从排序后的序列中选择出中位数。
(3)对第2步中找出的n/5(上取整)个中位数,递归调用SELECT以找出其中位数x。(如果是偶数去下中位数)
(4)调用PARTITION过程,按照中位数x对输入数组进行划分。确定中位数x的位置k。
(5)如果i=k,则返回x。否则,如果i<k,则在地区间递归调用SELECT以找出第i小的元素,若干i>k,则在高区找第(i-k)个最小元素。
SELECT算法通过中位数进行划分,可以保证每次划分是对称的,这样就能保证最坏情况下运行时间为θ(n)。举个例子说明此过程,求集合A={32,23,12,67,45,78,10,39,9,58,125,84}的第5小的元素,操作过程如下图所示:
#include <stdio.h>#include <stdlib.h>int partition(int* datas,int beg,int last,int mid);int select(int* datas,int length,int i);void swap(int* a,int *b);int main(){ int datas[12]={32,23,12,67,45,78,10,39,9,58,125,84}; int i,ret; printf("The array is:
"); for(i=0;i<12;++i) printf("%d ",datas[i]); printf("
"); for(i=1;i<=12;++i) { ret=select(datas,12,i); printf("The %dth least number is: %d
",i,datas[i-1]); } exit(0);}int partition(int* datas,int beg,int last,int mid){ int i,j; swap(datas+mid,datas+last); i=beg; for(j=beg;j<last;j++) { if(datas[j] < datas[last]) { swap(datas+i,datas+j); i++; } } swap(datas+i,datas+last); return i;}int select(int* datas,int length,int i){ int groups,pivot; int j,k,t,q,beg,glen; int mid; int temp,index; int *pmid; if(length == 1) return datas[length-1]; if(length % 5 == 0) groups = length/5; else groups = length/5 +1; pmid = (int*)malloc(sizeof(int)*groups); index = 0; for(j=0;j<groups;j++) { beg = j*5; glen = beg+5; for(t=beg+1;t<glen && t<length;t++) { temp = datas[t]; for(q=t-1;q>=beg && datas[q] > datas[q+1];q--) swap(datas+q,datas+q+1); swap(datas+q+1,&temp); } glen = glen < length ? glen : length; pmid[index++] = beg+(glen-beg)/2; } for(t=1;t<groups;t++) { temp = pmid[t]; for(q=t-1;q>=0 && datas[pmid[q]] > datas[pmid[q+1]];q--) swap(pmid+q,pmid+q+1); swap(pmid+q+1,&temp); } //printf("mid indx = %d,mid value=%d
",pmid[groups/2],datas[pmid[groups/2]]); mid = pmid[groups/2]; pivot = partition(datas,0,length-1,mid); //printf("pivot=%d,value=%d
",pivot,datas[pivot]); k = pivot+1; if(k == i) return datas[pivot]; else if(k < i) return select(datas+k,length-k,i-k); else return select(datas,pivot,i);}void swap(int* a,int *b){ int temp = *a; *a = *b; *b = temp;}总结
本章中的选择算法之所以具有线性运行时间,是因为这些算法没有进行排序,线性时间的行为并不是因为对输入做假设所得到的结果。