kmalloc kzalloc vmalloc malloc 和get_free_page()的区别
一、简述
二、先看看linux内存分布图:

图1:linux内存分布图
对于提供了MMU(存储管理器,辅助操作系统进行内存管理,提供虚实地址转换等硬件支持)的处理器而言,Linux提供了复杂的存储管理系统,使得进程所能访问的内存达到4GB。
进程的4GB内存空间被人为的分为两个部分--用户空间与内核空间。用户空间地址分布从0到3GB(PAGE_OFFSET,在0x86中它等于0xC0000000),3GB到4GB为内核空间。
内核空间中,从3G到vmalloc_start这段地址是物理内存映射区域(该区域中包含了内核镜像、物理页框表mem_map等等),比如我们使用 的 VMware虚拟系统内存是160M,那么3G~3G+160M这片内存就应该映射物理内存。在物理内存映射区之后,就是vmalloc区域。对于 160M的系统而言,vmalloc_start位置应在3G+160M附近(在物理内存映射区与vmalloc_start期间还存在一个8M的gap 来防止跃界),vmalloc_end的位置接近4G(最后位置系统会保留一片128k大小的区域用于专用页面映射)
1、kmalloc
kmalloc申请的是较小的连续的物理内存,内存物理地址上连续,虚拟地址上也是连续的,使用的是内存分配器slab的一小片。申请的内存位于物理内存的映射区域。其真正的物理地址只相差一个固定的偏移。可以用两个宏来简单转换__pa(address) { virt_to_phys()} 和__va(address) {phys_to_virt()}
get_free_page()申请的内存是一整页,一页的大小一般是128K。
从本质上讲,kmalloc和get_free_page最终调用实现是相同的,只不过在调用最终函数时所传的flag不同而已。
kmalloc和get_free_page申请的内存位于物理内存映射区域,而且在物理上也是连续的,它们与真实的物理地址只有一个固定的偏移,因此存在较简单的转换关系,virt_to_phys()可以实现内核虚拟地址转化为物理地址:
#define __pa(x) ((unsigned long)(x)-PAGE_OFFSET)
extern inline unsigned long virt_to_phys(volatile void * address)
{
return __pa(address);
}
上面转换过程是将虚拟地址减去3G(PAGE_OFFSET=0XC000000)。
与之对应的函数为phys_to_virt(),将内核物理地址转化为虚拟地址:
#define __va(x) ((void *)((unsigned long)(x)+PAGE_OFFSET))
extern inline void * phys_to_virt(unsigned long address)
{
return __va(address);
}
virt_to_phys()和phys_to_virt()都定义在include/asm-i386/io.h中。
1. kmalloc的用法
kmalloc与malloc 相似,该函数返回速度快快(除非它阻塞)并对其分配的内存不进行 初始化(清零),分配的区仍然持有它原来的内容, 分配的区也是在物理内存中连 续
记住 kmalloc 原型是:
#include <linux/slab。h>
void *kmalloc(size_t size, int flags);
给 kmalloc 的第一个参数是要分配的块的大小。 第 2 个参数, 分配标志, 用于控制 kmalloc的行为。
1.1. flags 参数
GFP_ATOMIC
用来从中断处理和进程上下文之外的其他代码中分配内存。 从不睡眠。
GFP_KERNEL
内核内存的正常分配。 可能睡眠。
GFP_USER
用来为用户空间页来分配内存; 它可能睡眠。
GFP_HIGHUSER
如同 GFP_USER, 但是从高端内存分配, 如果有。 高端内存在下一个子节描述。
GFP_NOIO
GFP_NOFS
这个标志功能如同 GFP_KERNEL, 但是它们增加限制到内核能做的来满足请求。 一个 GFP_NOFS 分配不允许进行任何文件系统调用, 而
GFP_NOIO 根本不允许任何 I/O 初始化。 它们主要地用在文件系统和虚拟内存代码, 那里允许一个分配睡眠,
但是递归的文件系统调用会是一个坏注意。
上面列出的这些分配标志可以是下列标志的相或来作为参数, 这些标志改变这些分配如何进行:
__GFP_DMA
这个标志要求分配在能够 DMA 的内存区。 确切的含义是平台依赖的并且在下面章节来解释。
__GFP_HIGHMEM
这个标志指示分配的内存可以位于高端内存。
__GFP_COLD
正常地, 内存分配器尽力返回"缓冲热"的页 -- 可能在处理器缓冲中找到的页。 相反, 这个标志请求一个"冷"页, 它在一段时间没被使用。
它对分配页作 DMA 读是有用的, 此时在处理器缓冲中出现是无用的。 一个完整的对如何分配 DMA 缓存的讨论看"直接内存存取"一节在第 1
章。
__GFP_NOWARN
这个很少用到的标志阻止内核来发出警告(使用 printk ), 当一个分配无法满足。
__GFP_HIGH
这个标志标识了一个高优先级请求, 它被允许来消耗甚至被内核保留给紧急状况的最后的内存页。
__GFP_REPEAT
__GFP_NOFAIL
__GFP_NORETRY
这些标志修改分配器如何动作, 当它有困难满足一个分配。 __GFP_REPEAT 意思是" 更尽力些尝试" 通过重复尝试 --
但是分配可能仍然失败。 __GFP_NOFAIL 标志告诉分配器不要失败; 它尽最大努力来满足要求。 使用 __GFP_NOFAIL
是强烈不推荐的; 可能从不会有有效的理由在一个设备驱动中使用它。 最后, __GFP_NORETRY 告知分配器立即放弃如果得不到请求的内存。
1.2. size 参数
内核管理系统的物理内存,
这些物理内存只是以页大小的块来使用。 结果是, kmalloc 看来非常不同于一个典型的用户空间 malloc 实现。 一个简单的, 面向堆的分
配技术可能很快有麻烦; 它可能在解决页边界时有困难。 因而, 内核使用一个特殊的面向 页的分配技术来最好地利用系统RAM。
Linux 处理内存分配通过创建一套固定大小的内存对象池。 分配请求被这样来处理,进 入一个持有足够大的对象的池子并且将整个内存块递交给请求者。 内存管理方案是非常复 杂, 并且细节通常不是全部设备驱动编写者都感兴趣的。
然而, 驱动开发者应当记住的一件事情是, 内核只能分配某些预定义的, 固定大小的字 节数组。
如果你请求一个任意数量内存,你可能得到稍微多于你请求的, 至多是 2 倍数量。 同样, 程序员应当记住 kmalloc 能够处理的最小分配是
32 或者 64 字节,依赖系统的体 系所使用的页大小。
kmalloc 能够分配的内存块的大小有一个上限。 这个限制随着体系和内核配置选项而 变化。 如果你的代码是要完全可移植,它不能指望可以分配任何大于 128 KB。
2、kzalloc
用kzalloc申请内存的时候, 效果等同于先是用 kmalloc() 申请空间 , 然后用 memset() 来初始化 ,所有申请的元素都被初始化为 0.
- /**
- * kzalloc - allocate memory. The memory is set to zero.
- * @size: how many bytes of memory are required.
- * @flags: the type of memory to allocate (see kmalloc).
- */
- static inline void *kzalloc(size_t size, gfp_t flags)
- {
- return kmalloc(size, flags | __GFP_ZERO);
- }
kzalloc 函数是带参数调用kmalloc函数,添加的参数是或了标志位__GFP_ZERO,
- void *__kmalloc(size_t size, gfp_t flags)
- {
- struct kmem_cache *s;
- void *ret;
- if (unlikely(size > SLUB_MAX_SIZE))
- return kmalloc_large(size, flags);
- s = get_slab(size, flags);
- if (unlikely(ZERO_OR_NULL_PTR(s)))
- return s;
- ret = slab_alloc(s, flags, -1, _RET_IP_);
- trace_kmalloc(_RET_IP_, ret, size, s->size, flags);
- return ret;
- }
这个函数调用trace_kmalloc,flags参数不变,继续往里面可以看到
- static __always_inline void *slab_alloc(struct kmem_cache *s,
- gfp_t gfpflags, int node, unsigned long addr)
- {
- void **object;
- struct kmem_cache_cpu *c;
- unsigned long flags;
- unsigned int objsize;
- gfpflags &= gfp_allowed_mask;
- lockdep_trace_alloc(gfpflags);
- might_sleep_if(gfpflags & __GFP_WAIT);
- if (should_failslab(s->objsize, gfpflags))
- return NULL;
- local_irq_save(flags);
- c = get_cpu_slab(s, smp_processor_id());
- objsize = c->objsize;
- if (unlikely(!c->freelist || !node_match(c, node)))
- object = __slab_alloc(s, gfpflags, node, addr, c);
- else {
- object = c->freelist;
- c->freelist = object[c->offset];
- stat(c, ALLOC_FASTPATH);
- }
- local_irq_restore(flags);
- if (unlikely((gfpflags & __GFP_ZERO) && object))
- memset(object, 0, objsize);
- kmemcheck_slab_alloc(s, gfpflags, object, c->objsize);
- kmemleak_alloc_recursive(object, objsize, 1, s->flags, gfpflags);
- return object;
- }
这里主要判断两个标志,WAIT和ZERO,和本文有关的关键代码就是
if (unlikely((gfpflags & __GFP_ZERO) && object))
memset(object, 0, objsize);
3、vmalloc
vmalloc用于申请较大的内存空间,虚拟内存是连续。申请的内存的则位于vmalloc_start~vmalloc_end之间,与物理地址没有简单的转换关系,虽然在逻辑上它们也是连续的,但是在物理上它们不要求连续。
以字节为单位进行分配,在<linux/vmalloc.h>
void *vmalloc(unsigned long size) 分配的内存虚拟地址上连续,物理地址不连续。
一般情况下,只有硬件设备才需要物理地址连续的内存,因为硬件设备往往存在于MMU之外,根本不了解虚拟地址;但为了性能上的考虑,内核中一般使用kmalloc(),而只有在需要获得大块内存时才使用vmalloc,例如当模块被动态加载到内核当中时,就把模块装载到由vmalloc()分配的内存上。
4、kmalloc、get_free_page和vmalloc的区别:
#include <linux/module.h>
#include <linux/slab.h>
#include <linux/vmalloc.h>
MODULE_LICENSE("GPL");
unsigned char *pagemem;
unsigned char *kmallocmem;
unsigned char *vmallocmem;
int __init mem_module_init(void)
{
//最好每次内存申请都检查申请是否成功
//下面这段仅仅作为演示的代码没有检查
pagemem = (unsigned char*)get_free_page(0);
printk("<1>pagemem addr=%x", pagemem);
kmallocmem = (unsigned char*)kmalloc(100, 0);
printk("<1>kmallocmem addr=%x", kmallocmem);
vmallocmem = (unsigned char*)vmalloc(1000000);
printk("<1>vmallocmem addr=%x", vmallocmem);
return 0;
}
void __exit mem_module_exit(void)
{
free_page(pagemem);
kfree(kmallocmem);
vfree(vmallocmem);
}
module_init(mem_module_init);
module_exit(mem_module_exit);
我们的系统上有160MB的内存空间,运行一次上述程序,发现pagemem的地址在0xc7997000(约3G+121M)、kmallocmem 地址在0xc9bc1380(约3G+155M)、vmallocmem的地址在0xcabeb000(约3G+171M)处,符合前文所述的内存布局。
5、malloc
linux内存管理之malloc、vmalloc、kmalloc的区别
1、kmalloc和vmalloc是分配的是内核的内存,malloc分配的是用户的内存
2、kmalloc保证分配的内存在物理上是连续的,内存只有在要被DMA访问的时候才需要物理上连续,malloc和vmalloc保证的是在虚拟地址空间上的连续
3、kmalloc能分配的大小有限,vmalloc和malloc能分配的大小相对较大
4、vmalloc比kmalloc要慢。尽管在某些情况下才需要物理上连续的内存块,但是很多内核代码都用kmalloc来获得内存,而不是vmalloc。这主要是出于性能的考虑。vmalloc函数为了把物理内存上不连续的页转换为虚拟地址空间上连续的页,必须专门建立页表项。糟糕的是,通过vmalloc获得的页必须一个个地进行映射,因为它们物理上是不连续的,这就会导致比直接内存映射大得多的TLB抖动,vmalloc仅在不得已时才会用--典型的就是为了获得大块内存时。
malloc的实现原理
malloc函数的实质体现在,它有一个将可用的内存块连接为一个长长的列表的所谓空闲链表(全局变量,一个内存块的链表指针)。调用malloc函数时,它沿连接表寻找一个大到足以满足用户请求所需要的内存块。然后,将该内存块一分为二(一块的大小与用户请求的大小相等,另一块的大小就是剩下的字节)。接下来,将分配给用户的那块内存传给用户,并将剩下的那块(如果有的话)返回到连接表上。调用free函数时,它将用户释放的内存块连接到空闲链上。到最后,空闲链会被切成很多的小内存片段,如果这时用户申请一个大的内存片段,那么空闲链上可能没有可以满足用户要求的片段了。于是,malloc函数请求延时,并开始在空闲链上翻箱倒柜地检查各内存片段,对它们进行整理,将相邻的小空闲块合并成较大的内存块。 malloc()在操作系统中的实现 在 C 程序中,多次使用malloc () 和 free()。不过,您可能没有用一些时间去思考它们在您的操作系统中是如何实现的。本节将向您展示 malloc 和 free 的一个最简化实现的代码,来帮助说明管理内存时都涉及到了哪些事情。 在大部分操作系统中,内存分配由以下两个简单的函数来处理: void *malloc (long numbytes):该函数负责分配 numbytes 大小的内存,并返回指向第一个字节的指针。 void free(void *firstbyte):如果给定一个由先前的 malloc 返回的指针,那么该函数会将分配的空间归还给进程的“空闲空间”。
malloc_init 将是初始化内存分配程序的函数。它要完成以下三件事:将分配程序标识为已经初始化,找到系统中最后一个有效内存地址,然后建立起指向我们管理的内存的指针。这三个变量都是全局变量:
如前所述,被映射的内存的边界(最后一个有效地址)常被称为系统中断点或者当前中断点。在很多 UNIX?
系统中,为了指出当前系统中断点,必须使用sbrk(0) 函数。 sbrk
根据参数中给出的字节数移动当前系统中断点,然后返回新的系统中断点。使用参数 0 只是返回当前中断点。这里是我们的 malloc
初始化代码,它将找到当前中断点并初始化我们的变量
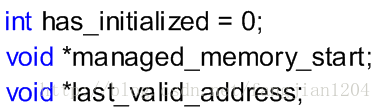

现在,为了完全地管理内存,我们需要能够追踪要分配和回收哪些内存。在对内存块进行了
free 调用之后,我们需要做的是诸如将它们标记为未被使用的等事情, 并且, 在调用 malloc 时, 我们要能够定位未被使用的内存块。
因此, malloc返回的每块内存的起始处首先要有这个结构:

现在,
您可能会认为当程序调用 malloc 时这会引发问题 ——
它们如何知道这个结构?答案是它们不必知道;在返回指针之前,我们会将其移动到这个结构之后, 把它隐藏起来。
这使得返回的指针指向没有用于任何其他用途的内存。 那样,从调用程序的角度来看,它们所得到的全部是空闲的、开放的内存。然后,当通过 free()
将该指针传递回来时,我们只需要倒退几个内存字节就可以再次找到这个结构。在讨论分配内存之前,我们将先讨论释放,因为它更简单。为了释放内存,我们必须要做的惟一一件事情就是,获得我们给出的指针,回退
sizeof(structmem_control_block) 个字节,并将其标记为可用的。这里是对应的代码:

如您所见,在这个分配程序中,内存的释放使用了一个非常简单的机制,在固定时间内完成内存释放。分配内存稍微困难一些。我们主要使用连接的指针遍历内存来寻找开放的内存块。这里是代码:






这就是我们的内存管理器。现在,我们只需要构建它,并在程序中使用它即可.多次调用 malloc()后空闲内存被切成很多的小内存片段,这就使得用户在申请内存使用时,由于找不到足够大的内存空间,malloc()需要进行内存整理,使得函数的性能越来越低。聪明的程序员通过总是分配大小为 2 的幂的内存块,而最大限度地降低潜在的 malloc 性能丧失。也就是说,所分配的内存块大小为4 字节、8 字节、16 字节、18446744073709551616 字节,等等。这样做最大限度地减少了进入空闲链的怪异片段(各种尺寸的小片段都有)的数量。尽管看起来这好像浪费了空间,但也容易看出浪费的空间永远不会超过 50%。