参考:http://www.admin10000.com/document/13593.html
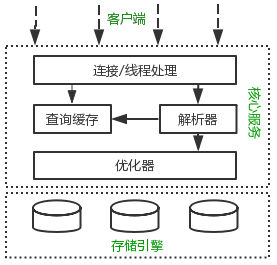
MySQL整体逻辑架构分为3层。
客户端层:连接处理,授权认证,安全等功能在这一层。
核心服务层:包括查询解析,分析,优化,缓存。所有跨存储引擎的功能也在这一层实现:存储构成,触发器,视图等。
存储引擎:负责mysql的数据存储和提取。中间的服务层通过API与存储引擎通信,这些API接口屏蔽了不同存储引擎间的差距。
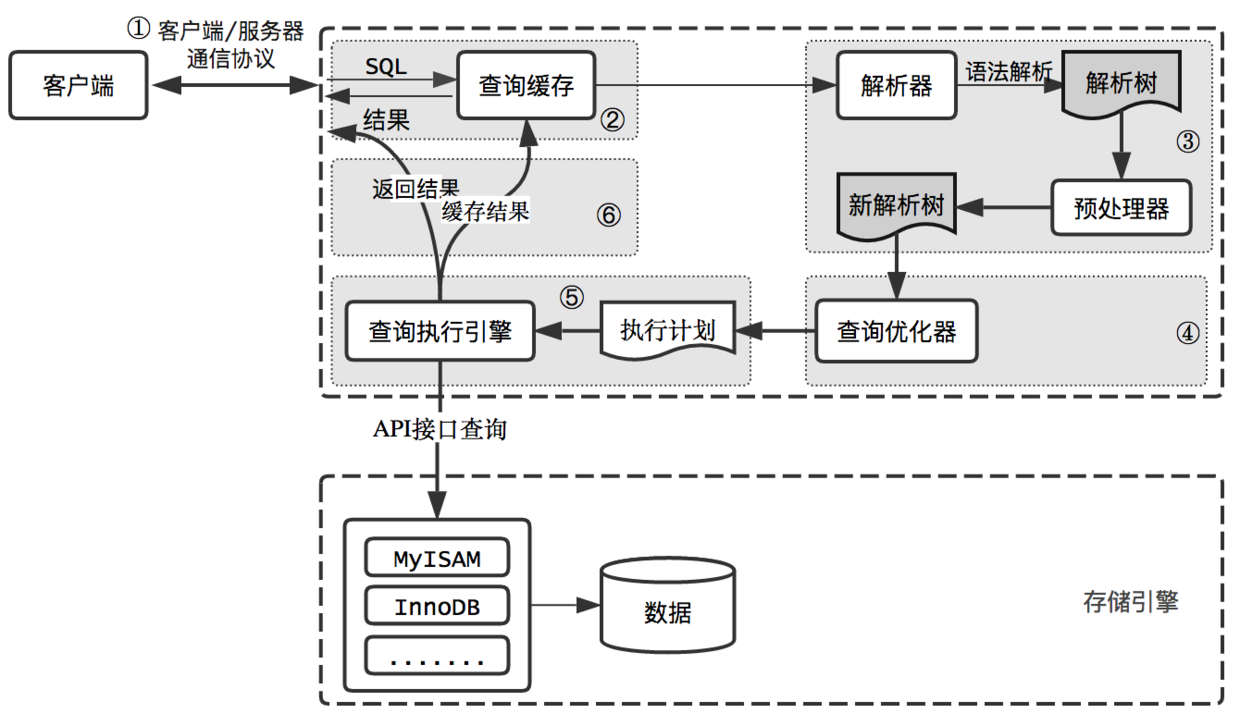
mysql查询过程:
客户端/服务端通信协议:
mysql客户端/服务器端通信协议是“半双工”的,在任意时刻,要么服务器向客服端发送数据,要么相反。这两个动作不能同时发生。
客户端用一个单独的数据包将查询请求发送给服务器,所以当查询语句很长的时候,需要设置max_allowed_packet参数。注意,如果查询实在太大,服务端会拒绝接收更多的数据并抛出异常。
由于服务端相应用户的数据通常很多,而客户端必须完整的接收整个返回结果。因此在实际开发过程中,尽量保持返回简单并且必须的数据。这也是查询中尽量避免使用SELECT *以及加上LIMIT限制的原因。
随着数据大小增加,索引本身大小也随之增加。索引以索引文件的形式存储在磁盘上。每次读取索引时多会产生I/O消耗(没读取一个节点,就要进行一次I/O消耗),相比于内存消耗,I/O消耗要高几个数量级。为了降低I/O消耗,一种办法就是降低树的深度。将二叉树变成m叉树。B+Tree树就是一种多路搜索树。理解B+Tree注意两个方面:1)所有数据(关键字)存储在叶子节点,非叶子节点不存储真正的数据。2)所有叶子节点由指针相连。如图为高度为2的简化的B+Tree。
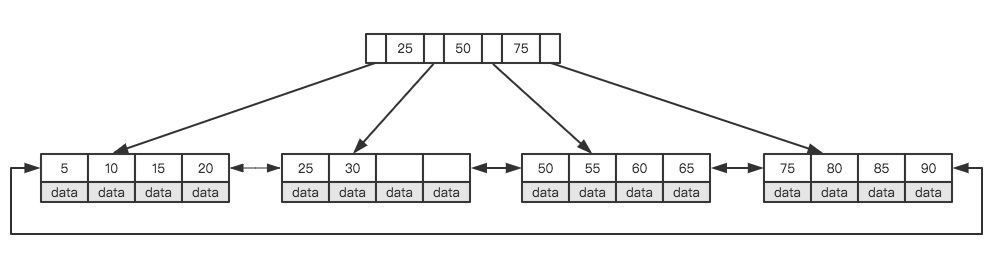
mysql为何将节点大小设置为页的整数倍?
根据磁盘存储原理,为了减少磁盘I/O,磁盘往往不是严格按需读取,而是每次都会预读。预读长度一般为页的整数倍。
页是计算机管理存储器的逻辑块。硬件和OS往往将主存和磁盘存储分割为连续大小相等的块,每个存储称为一页。主存和磁盘以页为单位交换数据。当计算机要读取的数据不在主存时,会触发一个缺页异常。此时系统会向磁盘发出读盘信号,磁盘会找到数据的起始位置并向后连续读取一页或几页载入内存中,然后返回异常,程序继续执行。
mysql利用这个预读原理,将一个节点的大小设为一个页。这样每个加点只需要一次I/O就可以完全载入。
虽然索引可以大大提高查询效率,但维护仍要耗费很大代价,因此要合理创建索引。