1 JVM内存模型

2 GC策略之算法
根搜索算法
- 标记复制
- 标记清除 缺点1: 效率比较低(递归与全堆对象遍历 GC的时候 停止程序) 缺点2: 内存碎片化
- 标记整理
标记: 遍历GCRoots 可达性分析
清除: 清除所有未标记
效率 复制 > 整理 > 清除
内存整齐度 复制 = 整理 > 清除
内存利用率 整理 = 清除 > 复制
GCRoots对象
1、虚拟机栈中的引用的对象。
2、方法区中的类静态属性引用的对象。
3、方法区中的常量引用的对象。
4、本地方法栈中JNI的引用的对象
普通GC(minor GC):只针对新生代区域的GC。****全局GC(major GC or Full GC):针对年老代的GC
-
对象晋升
-
年龄阈值
VM为每个对象定义了一个对象年龄(Age)计数器, 对象在Eden出生如果经第一次Minor GC后仍然存活, 且能被Survivor容纳的话, 将被移动到Survivor空间中, 并将年龄设为1. 以后对象在Survivor区中每熬过一次Minor GC年龄就+1. 当增加到一定程度(-XX:MaxTenuringThreshold, 默认15), 将会晋升到老年代.
-
提前晋升: 动态年龄判定
然而VM并不总是要求对象的年龄必须达到MaxTenuringThreshold才能晋升老年代: 如果在Survivor空间中相同年龄所有对象大小的总和大于Survivor空间的一半, 年龄大于或等于该年龄的对象就可以直接进入老年代, 而无须等到晋升年龄.
-
3 垃圾收集器
G1收集器
- 空间整合
- 可预测停顿
java堆内存分为大小相等独立的Region
- 初始标记,标记GCRoots能直接关联到的对象,时间很短。
- 并发标记,进行GCRoots Tracing(可达性分析)过程,时间很长。
- 最终标记,修正并发标记期间因用户程序继续运作而导致标记产生变动的那一部分对象的标记记录,时间较长。
- 筛选回收,排序各个Region的回收价值和成本,然后根据用户期望的GC停顿时间来制定回收计划
G1结构
一共四种region:
- 自由分区 free reigon
- 年轻代分区Young reigon 还是会存在eden 和 survivor
- 老年代分区Old reigon
- 大对象分区Humongous reigon
G1回收过程
- 初始标记:标记GC ROOT能关联到的对象,需要STW
- 并发标记:从GCRoots的直接关联对象开始遍历整个对象图的过程,扫描完成后还会重新处理并发标记过程中产生变动的对象
- 最终标记:短暂暂停用户线程,再处理一次,需要STW
- 筛选回收:更新Region的统计数据,对每个Region的回收价值和成本排序,根据用户设置的停顿时间制定回收计划。再把需要回收的Region中存活对象复制到空的Region,同时清理旧的Region。需要STW。
G1优势
回收器是为了减少STW时间 CMS的停顿时间不可预估 G1可以
-XX:MaxGCPauseMillis来设置允许的停顿时间(默认200ms) G1会收集每个Region的回收之后的空间大小、回收需要的时间,根据评估得到的价值,在后台维护一个优先级列表,然后基于我们设置的停顿时间优先回收价值收益最大的Region
那么,这个可预测的停顿时间模型怎么计算和建立的?主要是基于衰减平均值的理论基础,衰减平均是一种数学方法,用来计算一个数列的平均值,给近期的数据更高的权重,强调近期数据对结果的影响
空间分配和扩展
新生代 G1NewSizePercent 默认5% 最大60%
年轻代GC 年轻代reigon超过设置触发GC
Mixed GC 类似full gc 触发规则根据参数-XX:InitiatingHeapOccupancyPercent(默认45%)值
CMS收集器
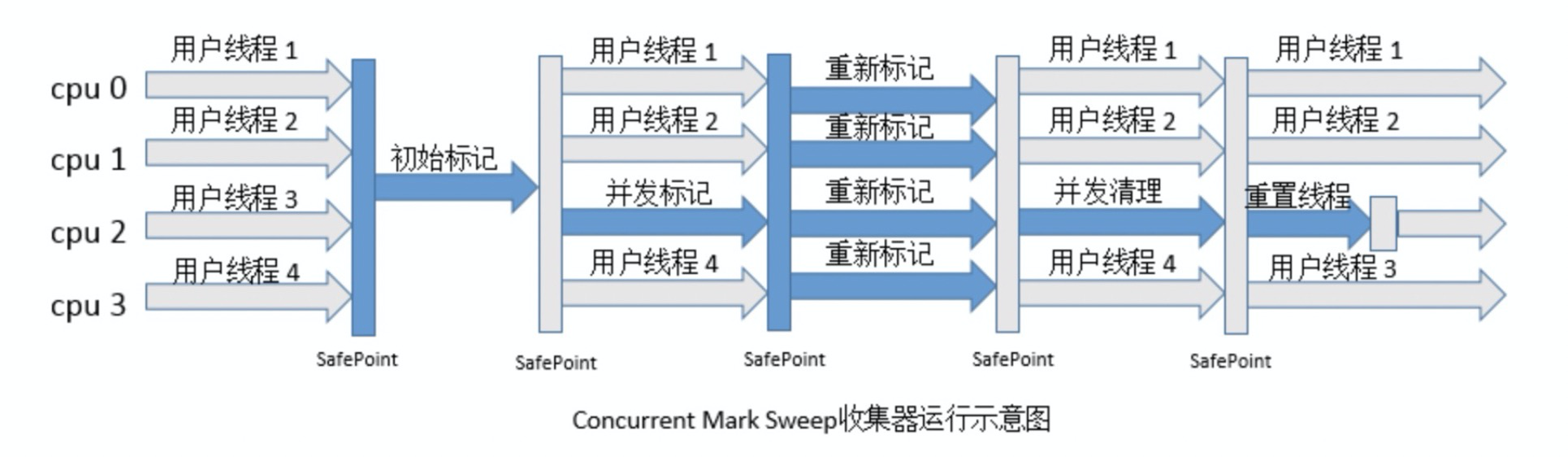
CMS(Conrrurent Mark Sweep)收集器是以获取最短回收停顿时间为目标的收集器。使用标记 - 清除算法,收集过程分为如下四步:
- 初始标记,标记GCRoots能直接关联到的对象,时间很短 STW(stop the world)。
- 并发标记,进行GCRoots Tracing(可达性分析)过程,时间很长。
- 重新标记,修正并发标记期间因用户程序继续运作而导致标记产生变动的那一部分对象的标记记录,时间较长。
- 并发清除,回收内存空间,时间很长。
其中,并发标记与并发清除两个阶段耗时最长,但是可以与用户线程并发执行。
CMS缺点
-
cms回收算法 标记清除,所以不会整理空间浪费问题
解决办法 CMS回收器不再采用简单的指针指向一块可用堆空 间来为下次对象分配使用。而是把一些未分配的空间汇总成一个列表,当JVM分配对象空间的时候,会搜索这个列表找到足够大的空间来hold住这个对象
-
需要更多的CPU资源 CMS和用户线程并发执行;重新标记阶段 为了减少STW时间也需要更多的CPU资源
-
需要更大的堆空间 因为标记和用户线程同时运行 需要预留堆空间给用户线程分配 ,也就是说CMS不会在老年代满的时候收集,会提前很多 默认老年代使用68% ,CMS就会开始收集 – XX:CMSInitiatingOccupancyFraction =n 设置
总的来说 CMS降低了回收的停顿事件 但是降低了堆空间的利用率
啥时候用CMS
- 用户对 停顿敏感
- 可以提供更大的CPU和内存
4 JVM命令
4.1 jps -v

4.2 jinfo
4.3 jstat -gc 2609 500 10 0.5输出一次 一共10次

4.4 jmap
4.5 jstack 查看线程运行状态
- Top + jstak 分析CPU过高 top -Hp 2609 查看2609进程最耗性能的线程 shift+p cpu排序 shiftp+m 内存排序
- Printf '%x' 2609 转16进制
关注线程状态
- 死锁,Deadlock(重点关注)
- 执行中,Runnable
- 等待资源,Waiting on condition(重点关注)
- 等待获取监视器,Waiting on monitor entry(重点关注)
- 暂停,Suspended
- 对象等待中,Object.wait() 或 TIMED_WAITING
- 阻塞,Blocked(重点关注)
- 停止,Parked
4.6 vmstat可以查看线程切换消耗
root@ubuntu:~# vmstat 2
procs -----------memory---------- ---swap-- -----io---- -system-- ----cpu----
r b swpd free buff cache si so bi bo in cs us sy id wa
1 0 0 3499840 315836 3819660 0 0 0 1 2 0 0 0 100 0
0 0 0 3499584 315836 3819660 0 0 0 0 88 158 0 0 100 0
0 0 0 3499708 315836 3819660 0 0 0 2 86 162 0 0 100 0
0 0 0 3499708 315836 3819660 0 0 0 10 81 151 0 0 100 0
1 0 0 3499732 315836 3819660 0 0 0 2 83 154 0 0 100 0
- r 运行队列 表示多个进程真实分到CPU
- b 阻塞队列
- swap已使用虚拟内存 >0表示物理内存不足
- free空闲物理内存
- buff系统权限等缓存
- cache缓存打开的文件,给文件做缓存
- si每秒从磁盘读入虚拟内存 >0表示物理内存不够或泄露
- so每秒虚拟内存写入磁盘 >0 同上
- bi块设备每秒接收块数量 块大小默认1024b
- bo块设备每秒发送块数量
- in每秒cpu中断次数
- cs上下文切换次数
- us用户cpu时间
- sy系统cpu时间 过长表示系统占用时间过长 如IO操作
- id空闲cpu时间 id+us+sy=100
- wt等待IO cpu时间
https://www.cnblogs.com/cuizhiquan/articles/10936986.html
uptime,vmstat,iostat,top
uptime用于查看系统负载,vmstat用于查看虚拟内存状态,iostat用于统计CPU和设备IO信息,top工具动态显示进程状态,还包括系统负载,虚拟内存状态,cpu和内存使用率
https://www.jianshu.com/p/ed372c5c0325