HDFS简介

HDFS的运用非常广泛,基本上很多大数据平台大部分都会选用HDFS(或者类似HDFS)这样的分布式文件系统、来作为海量数据存储的一个解决方案。
优缺点

- 优势
1. 高容错性,HDFS提供了非常好的“副本冗余机制”,简单来说就是一份数据在HDFS当中存放,包含它自身在内至少会有(默认)三个副本类似随机的存放在集群不同的服务器上,并且当其中一台服务器宕机、当前这台服务器上数据丢失,但HDFS会自动再将缺失的副本再通过copy的方式、保证数据的副本不会低于三个。
2. 可构建在廉价的商业服务器上,基于第一条高容错性的优势,HDFS可以搭建在低成本的廉价服务器上,而没有必要选择非常昂贵的服务器上,因为即使廉价服务器稳定性相对较差,但是集群规模成百上千台宕机一台、两台对于整个HDFS集群来说,基本上没有任何的影响。
3. 适合海量数据存储,分布式架构设计、HDFS可支持几万台服务器的集群规模,乘以每台服务器磁盘容量、整个HDFS文件系统容量非常之大,并且他所支持存放的单个数据文件GB、TB、PB级别都没有任何问题。
4. 适合批处理,它是通过“移动计算而非移动数据”来进行设计,会把数据存放位置暴露给计算框架,从而在海量数据计算过程中,数据在何处便在何处计算,避免了数据跨网络、结点移动拷贝的工作,很大限度的提升计算速度。
5. 流式数据访问,一次写入、多次读取。文件一旦写入完成、不能修改,仅仅只支持追加。保证了数据的一致性。
- 适用场景:
1. 适合大文件存储、海量数据存储
2. 适合批量数据访问
- 不擅长的一些场景:
1. 低延时数据访问,这里的“低延时”指的是例如毫秒级别要将数据写入HDFS、或毫秒级别读取HDFS内数据,这个它是做不到的。它的优势是在“高吞吐率”的场景,也就是在某一时间内大量写入、读取数据,但是毫秒级这种低延时它是支持不了的。
2. 并发写入、随机修改,HDFS当中文件只能有一个写、不支持多个线程同时写入一个文件。写好的文件只支持追加功能,并不支持文件的随机写入。
3. 小文件存储,小文件问题是大家在大数据领域需要格外注意的问题。首先撇开HDFS来说,假如10GB数据容量,10个1GB的数据集、1w个1M的数据集,占用存储空间相同,让你在这两种数据集中找到其中一个数据文件,明显第二种场景非常耗时,也就是说小文件存储之后,在寻址的时间开销会非常之高、以至于会高于读取时间。此外,回到HDFS当中来考虑,HDFS当中每一个数据文件都会对应有一份元数据信息需要存放,大家可以把元数据信息先简单理解为就是文件的一些基本信息(如文件名称、大小、权限等),一个文件对应一条元数据信息,当你存储的都是一些小文件、文件个数会急速增长,对应元数据也就需要更多的空间来存储,并且元数据是在内存介质中存储,这样一来会非常浪费内存资源、显然是不适用的。所以,在使用HDFS过程当中一定要注意“小文件”的这个问题。
HDFS原理
系统架构图
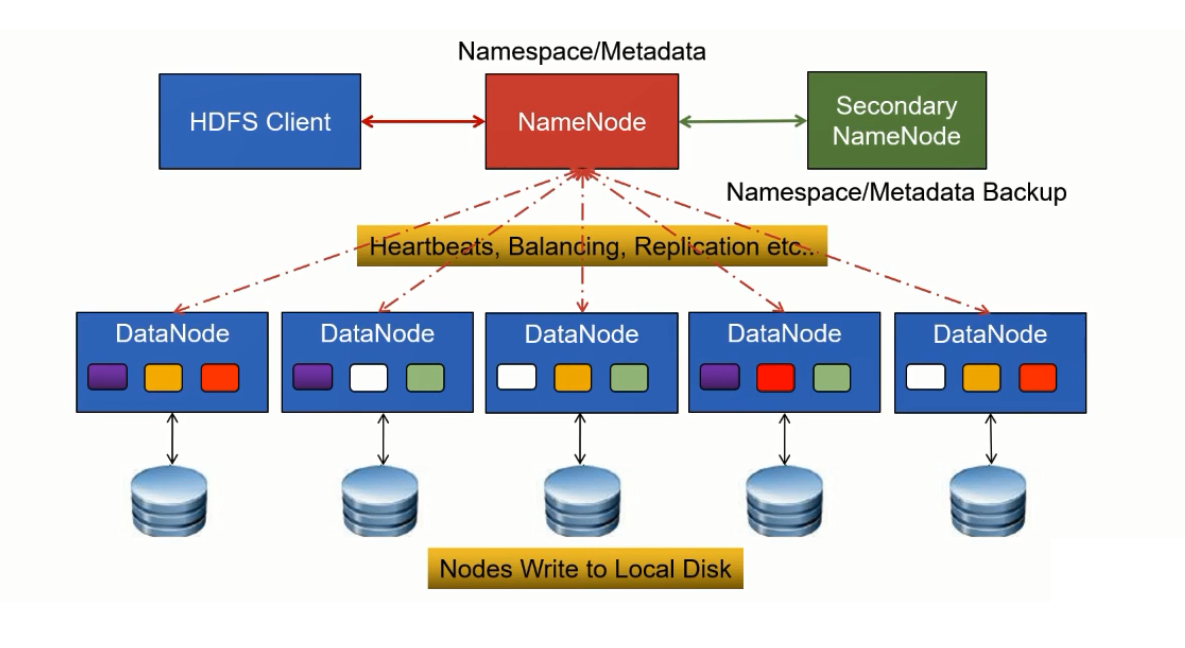
其中NameNode是主节点,DataNode是从节点,HDFS Client是客户端、HDFS提供了比较丰富的客户端像cli、api、gui等等支持,SecondaryNameNode相当于辅助NameNode工作的一个节点、但并不是NameNode的备份结点(这个一定要注意区分)。
NameNode,他作为主从架构当中的主节点,其实主要负责接受客户端提交过来的读写请求、以及一些类似管理的工作,比如说,数据存到HDFS当中每个文件都会对应一份元数据信息,这些元数据信息都是存放在NameNode的内存区域内、由NameNode来进行维护。
DataNode,他作为一个从节点出现,主要负责数据的存放。数据文件写入到HDFS当中会切分为小的数据块block(也就是图中DataNode方框中紫色、橙色、红色等小的方块),这些数据块会存放在DataNode节点上。在一个HDFS集群当中DataNode结点可以有任意多台,当然要根据你文件系统的数据量来确定,并且后期如果容量不足的情况下,也支持DataNode结点动态添加、扩容。
NameNode与DataNode之间的连线,DataNode在运行过程当中一直会和NameNode结点保持通信。一方面,在DataNode启动时,会给NameNode上报自己服务器上有哪些数据块、也就是block的位置存放信息,NameNode接收到这些block位置信息会维护好一份完整的元数据信息,从而找到具体数据存放在哪些DataNode上;另一方面,运行过程当中,DataNode会每隔3秒定时和NameNode做一次心跳,从而NameNode可以知道DataNode的运行状况。

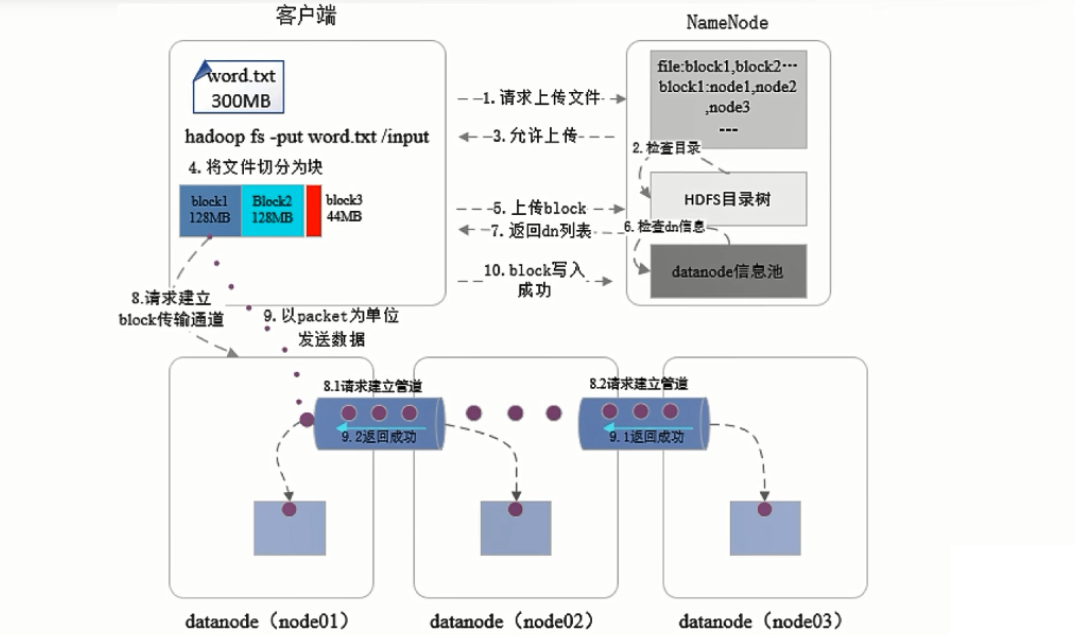
一个10G的文件上传到HDFS中,首先,会在客户端处进行切分,切分成一个个Block块,默认情况下Block块的大小是128M。
这些切分后的Block块,会以多副本的形式均匀放置到DataNode中。
数据存放在DataNode中后,主节点NameNode需要知道这份文件具体切分了多少Block块和每个Block块具体存放的位置。所以NameNode节点保存有一份元数据来记录这些信息。


fsimage可以理解为快照, 但数据块在DateNode的位置信息不会存, 不会持久化

存储机制

-
Block文件在DataNode本地磁盘中的目录结构。其中:
-
BP-random integer-NameNode-IP address-creation time:BP代表BlockPool,就是Namenode的VERSION中的集群唯一blockpoolID
-
finalized/rbw:其中finalized目录用于实际存储Block文件,finalized用于存 放Block文件以及Block元数据文件;rbw是“replica being written”的意思,该目录用于存储用户当前正在写入的数据
-
VERSION:VERSION文件是java属性文件,保存了HDFS的基本信息
-
blk_前缀文件:HDFS中的文件块本身,存储的是原始文件内容
-
in_use.lock:防止一台机器同时启动多个Datanode进程导致目录数据不一致


-
为什么有了fsimage内存快照、还需要有edits(日志)文件呢?
因为如果每次对于文件系统有操作,元数据信息就有可能发生变化,那么每次变化都去更新一下fsimage文件,显然成本非常之高而且性能也不好,所以fsimage并不会实时去发生变化,那么后边这些操作则通过edits文件做一个记录。

-
元数据持久化文件在DataNode本地磁盘中的目录结构:
-
fsimage_前缀文件:即fsimage文件,之所以有多个是因为他定时要做合并,所以会保留有多份fsimage文件
-
edits_前缀文件:即edits文件。
-
VERSION:VERSION文件是java属性文件,保存了HDFS的基本信息
-
seen_txid:是存放transactionId的文件,format之后是0,它代表的是namenode里面的edits_*文件的尾数,namenode重启的时候,会按照seen_txid的数字,循序从头跑edits_0000001~到seen_txid的数字。
看一下他们的名称命名规则,fsimage名称中一大串数字是合并时的一个id标识,edits文件名当中通过下划线分割前后分别代表合并前、后的id标识。

左右分别为NameNode以及SecondaryNameNode。整个合并流程为,NameNode在磁盘中有fsimage,集群在运行过程当中,客户端各项操作记录会写入到edits文件内,当触发合并时,SecondaryNameNode会主动从NameNode中通过HttpGet方式将edits和fsimage文件拷贝并存放在本地磁盘中,然后开始合并,合并过程其实就是将该fsimage加载到内存当中,然后逐条执行edits日志中的各项操作、来更新内存里的元数据信息,全部日志执行完成后,此时内存当中的元数据信息便是触发合并那个时间点一份完整的元数据信息,再往后,SecondaryNameNode将内存当中元数据持久化(做快照)产生一个新的fsimage文件,再通过Http Post方式将这个新的fsimage文件发送给NameNode,NameNode接收到新的fsimage文件启用新的fsimage文件。并且在触发合并的时候,NameNode除会把fsimage、edits交给SecondaryNameNode去合并,与此同时还会生成一个空的edits文件,SecondaryNameNode在做合并的整个过程中,所有客户端的操作都会记录在这个新的空edits文件中,直到SecondaryNameNode把新的fsimage文件推给NameNode,NameNode会同时将新的fsimage、以及新的edits文件启用整个合并过程完成结束。
SecondaryNameNode只是做了局部备份, 没有完整备份。
这边是HDFS元数据合并的机制,在运行过程中HDFS会定期触发整个合并流程,从而会保证fsimage文件越来越大、但edits文件会在比较的一个范围内,这样一个效果。
读写操作
写操作

读操作


安全模式

- 核心的配置项:dfs.namenode.safemode.threshold-pct: 副本数达到最小要求的block占系统总block数的百分比,当实际比例超过该配置后,才能离开安全模式(但是还需要其他条件也满足)。默认为0.999f,也就是说符合最小副本数要求的block占比超过99.9%时,并且其他条件也满足才能离开安全模式。如果为小于等于0,则不会等待任何副本达到要求即可离开。如果大于1,则永远处于安全模式。其他配置项一般默认不启用,先不做讨论。

高可用



高可用的本质是在主节点宕机之后,从热备节点可以立马代替宕机的主节点接管集群,保证服务是不中断的。那对于NameNode来说,如果要立马接管集群并且保证服务不中断,那就需要元数据保持一致。
在QJM这种高可用方案中,Journal集群可以实现edits共享,实现Master主备节点的元数据同步。
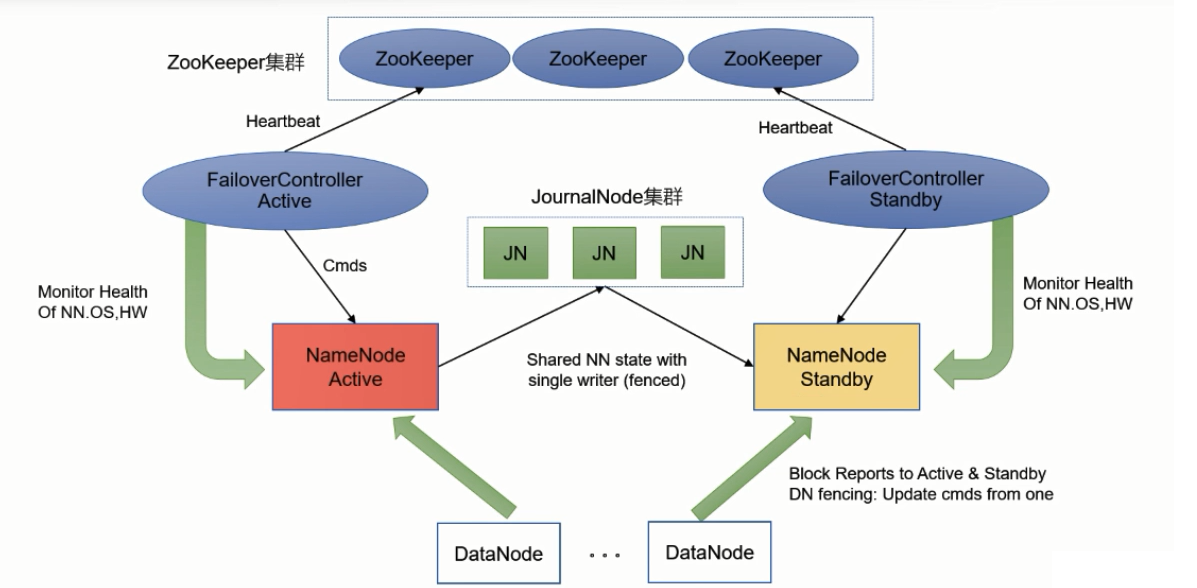
-
此时集群一共有两台NameNode、分别处于Active、Standby状态,Active状态的NameNode相当于处于工作状况、对集群负责管理并且接受客户端请求,另外一台Standby状态的NameNode处于一个等待状况如果Active的出现问题由它来负责接管集群。
-
JournalNode集群,它负责管理NameNode日志edits文件的管理,也就是ActiveNameNode写日志是直接写入到JournalNode集群上。
-
ZKFC – ZookeeperFailoverController,每台NameNode服务器上都会运行一个ZKFC进程,主要负责两个任务:监控当前NameNode运行状况信息、与Zookeeper集群保持心跳并将这些信息汇报给Zookeeper集群;控制NameNode Active、Standby状态的切换管理。
-
Zookeeper集群,实际中也是部署2N+1台,核心也是通过Paxos算法,在HDFS集群中主要负责接收到ZKFC汇报的NameNode健康信息做“选举”,“选举”哪一台NameNode应该是Active状态。
-
最下边是DataNode集群,负责数据的存储,但是区别于1.x的设计、在2.x集群中DataNode上报block信息会同时上报给两台NameNode。
HDFS运行过程中,如果Active的NameNode运行出现故障,此时当前NameNode上的ZKFC会将异常的健康信息汇报给Zookeeper集群,或者NameNode这台服务器宕机,Zookeeper集群长时间接收不到ZKFC的数据,都会得知第一台NameNode运行出现了问题。此时,Zookeeper集群会做选举、推选第二台NameNode作为Active的NameNode来接管集群,之后Zookeeper先通知给第二台NameNode上的ZKFC,由ZKFC将当前这台NameNode状态从Standby切换为Active。fsimage文件在第二台NameNode上有一份,运行过程中edits文件一直写在JournalNode集群上、第二台NameNode可以直接拿到这些edits文件,状态切换之后,便可以先将fsimage加载内存,然后一条一条执行edits日志内容,并且集群在运行过程中DataNode会将各自服务器上block信息汇报给第一台和第二台,第二台上缓存有这些block信息再将它和内存当中部分原数据信息进行拼接。当这些操作全部执行完成之后,此时第二台NameNode内存当中元数据信息和第一台NameNode出现故障时内存当中元数据信息完全一致,这样整个HA便达到了。
HDFS操作命令
文件系统命令


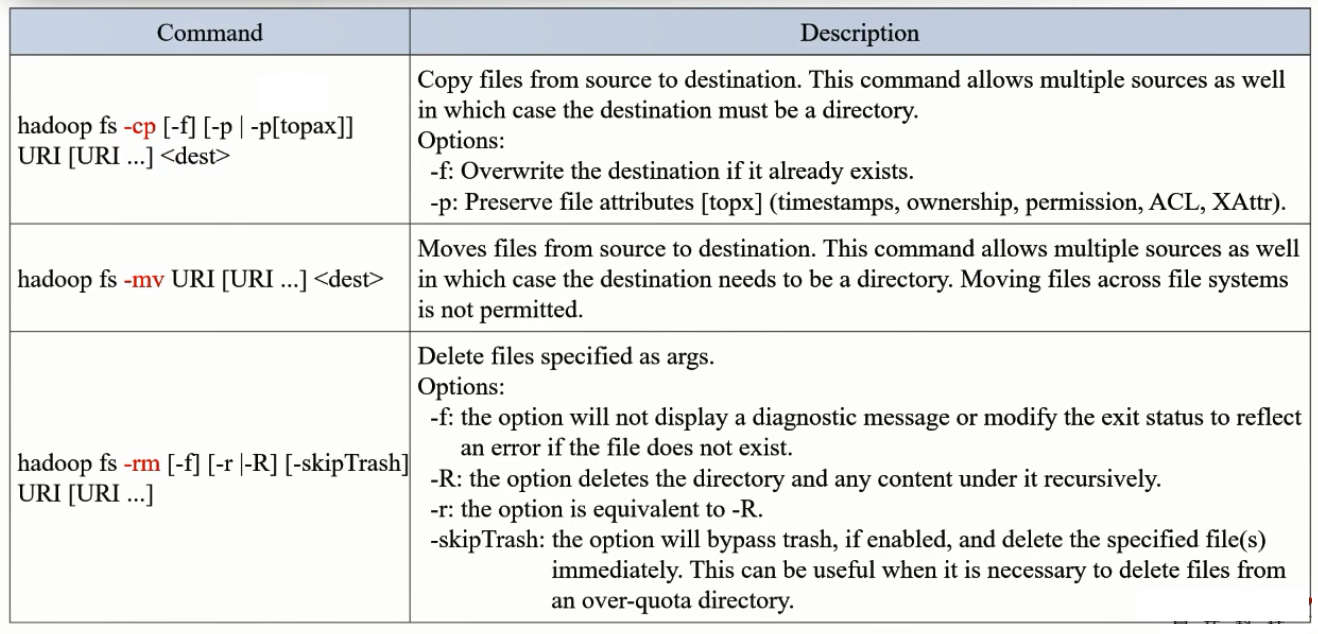
HDFS运维管理

蓝色部分是一段core-site.xml的配置,Hadoop当中大部分配置都是这种xml格式,property标签为配置项名称,value标签为配置值。
fs.defaultFS:配置HDFS默认入口,1.x中只有一台NameNode一般配置为hdfs://namenode:rpcport,但在2.x中有两台NameNode、并且两台会自动状态切换,所以2.x中在hdfs-site.xml中可配置一个nameservice命名服务,通过hdfs://nameservice来访问HDFS、它会自动转到对应Active状态的NameNode来接收请求。

dfs.namenode.name.dir:NameNode结点存放元数据文件fsimage的位置;
dfs.datanode.data.dir:DataNode结点存放数据块block的位置;
dfs.blocksize:数据块block大小;
dfs.datanode.du.reserved:DataNode结点磁盘余留空间大小,防止磁盘被HDFS全部写满;
dfs.replication:block副本数量;
fs.trash.interval:回收站内数据隔多久之后被彻底删除。