解Bug之路-记一次中间件导致的慢SQL排查过程
前言
最近发现线上出现一个奇葩的问题,这问题让笔者定位了好长时间,期间排查问题的过程还是挺有意思的,正好博客也好久不更新了,就以此为素材写出了本篇文章。
Bug现场
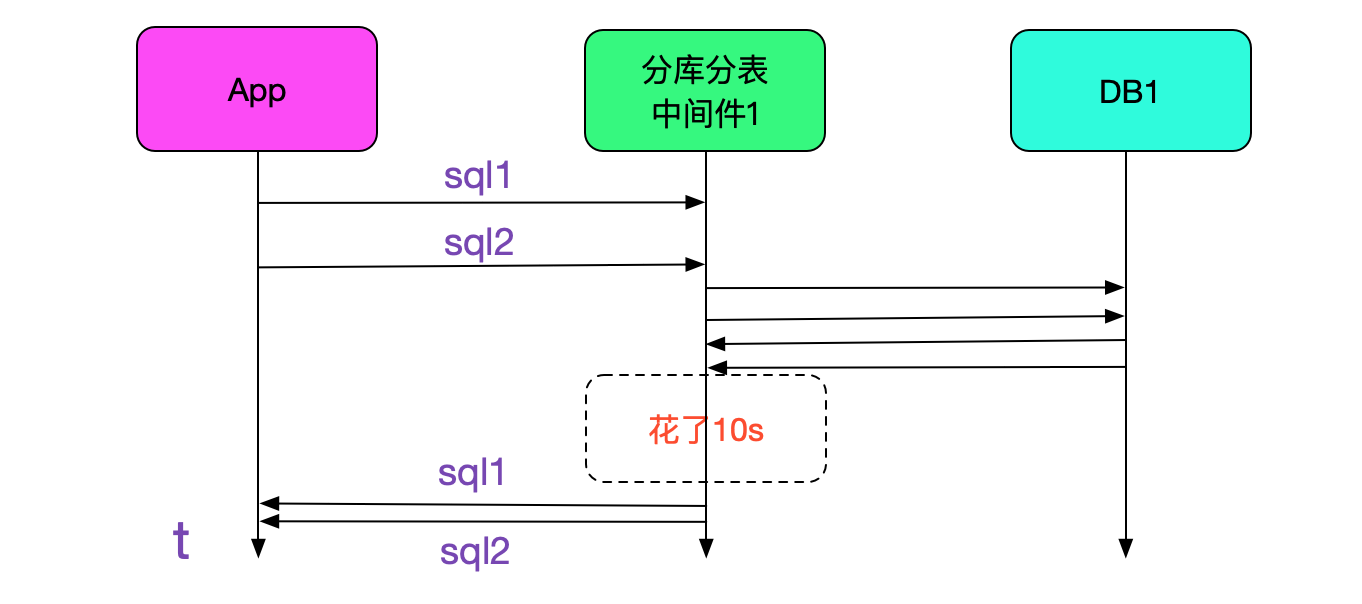
我们的分库分表中间件在经过一年的沉淀之后,已经到了比较稳定的阶段。而且经过线上压测的检验,单台每秒能够执行1.7W条sql。但线上情况还是有出乎我们意料的情况。有一个业务线反映,每天有几条sql有长达十几秒的超时。而且sql是主键更新或主键查询,更奇怪的是出现超时的是不同的sql,似乎毫无规律可寻,如下图所示:
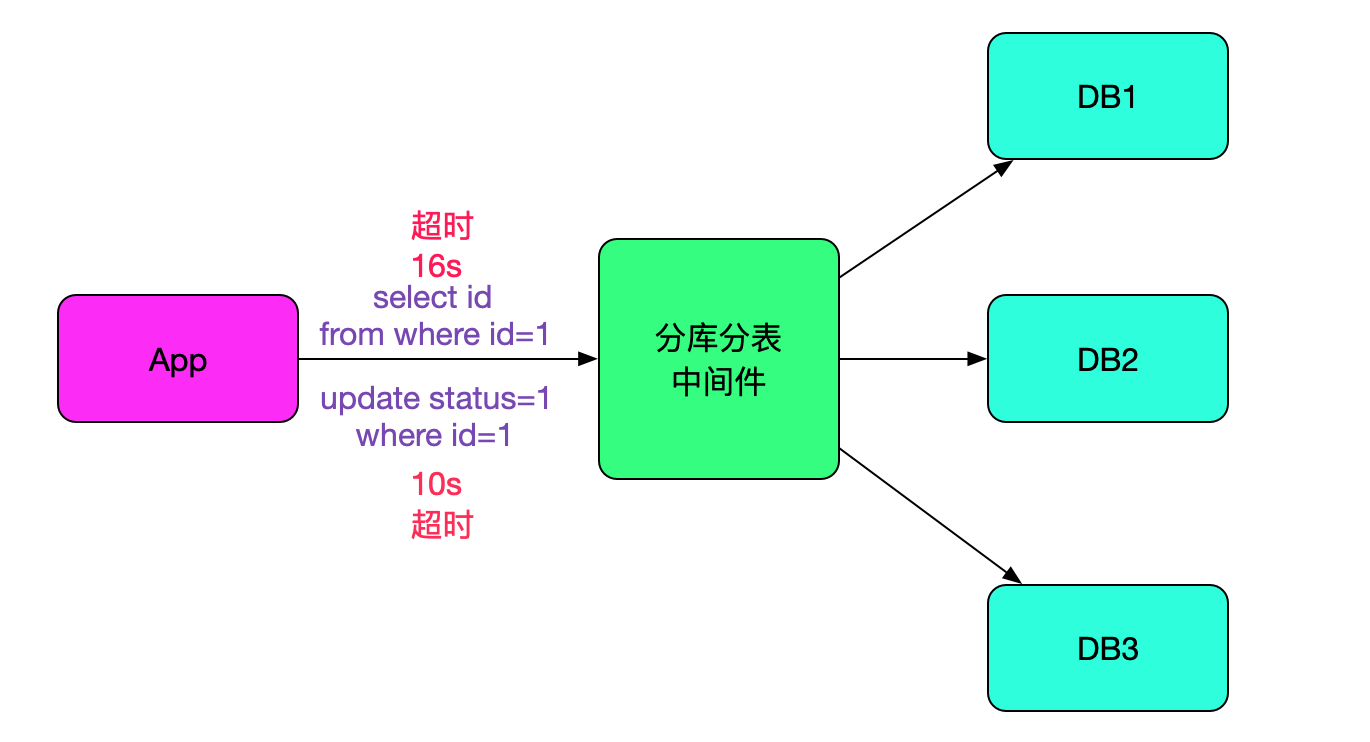
一个值得注意的点,就是此业务只有一部分流量走我们的中间件,另一部分还是直接走数据库的,而超时的sql只会在连中间件的时候出现,如下图所示:
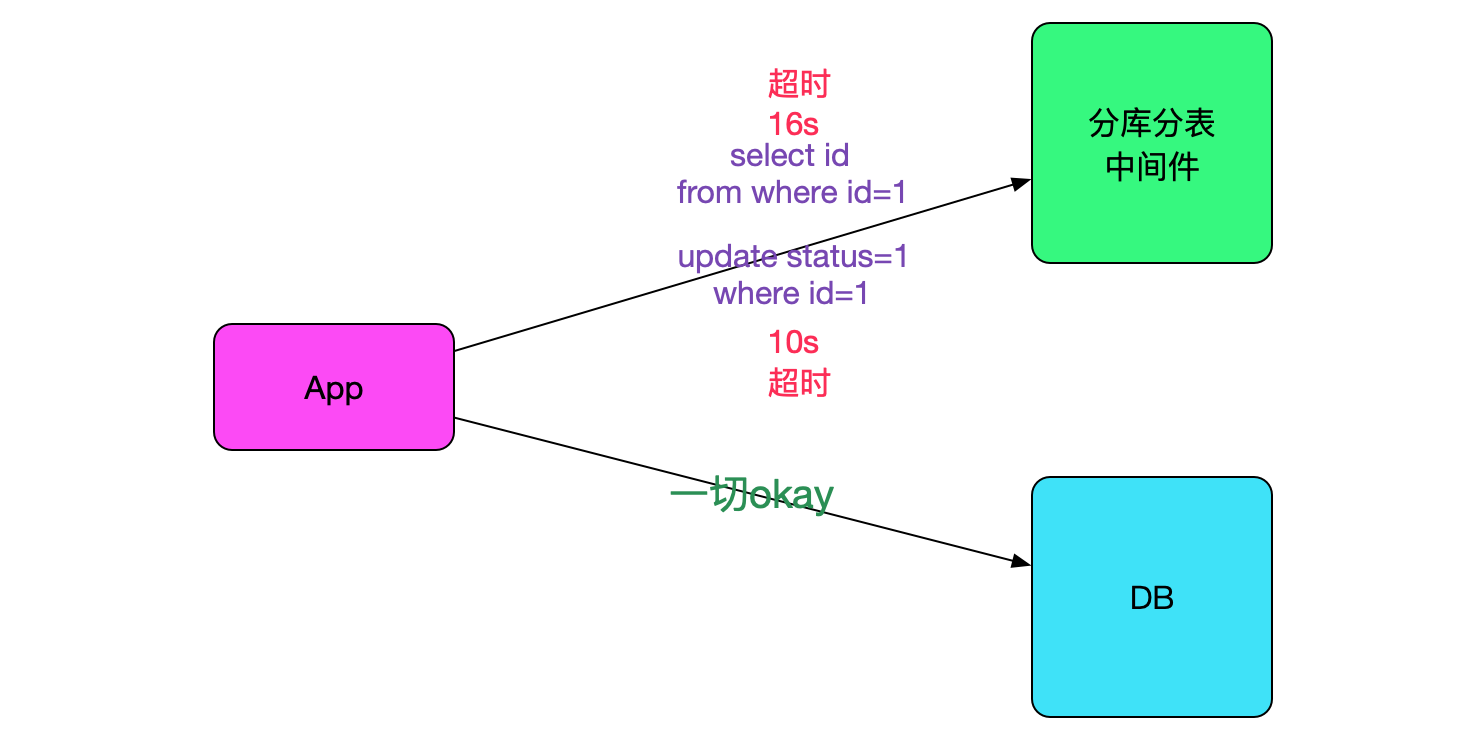
很明显,是引入了中间件之后导致的问题。
排查是否sql确实慢
由于数据库中间件只关心sql,并没有记录对应应用的traceId,所以很难将对应的请求和sql对应起来。在这里,我们先粗略的统计了在应用端超时的sql的类型是否会有超时的情况。
分析了日志,发现那段时间所有的sql在往后端数据执行的时候都只有0.5ms,非常的快。如下图所示:
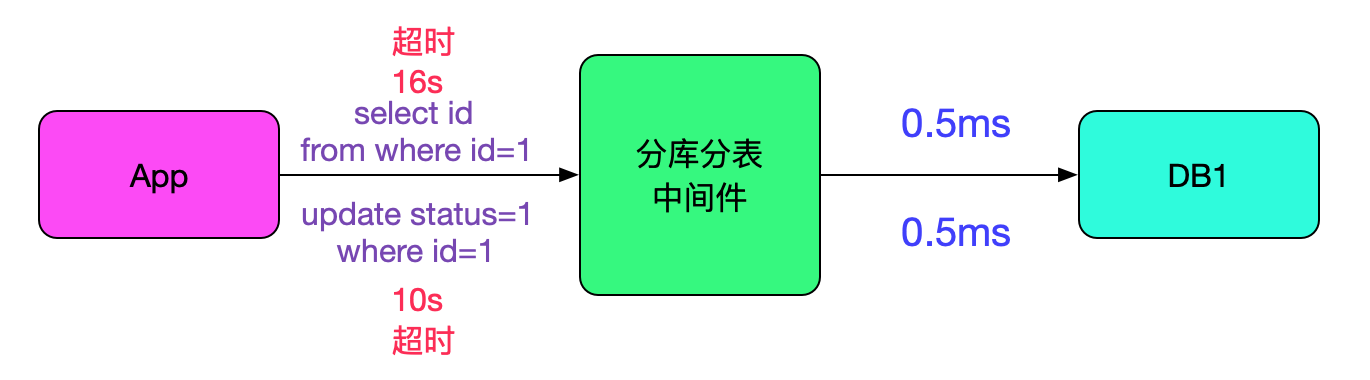
看来是中间件和数据库之间的交互是正常的,那么继续排查线索。
寻找超时规律
由于比较难绑定对应请求和中间件执行sql之间的关系,于是笔者就想着列出所有的异常情况,看看其时间点是否有规律,以排查一些批处理导致中间件性能下降的现象。下面是某几条超时sql业务方给出的信息:
| 业务开始时间 | 执行sql的应用ip | 业务执行耗时(s) |
|---|---|---|
| 2018-12-24 09:45:24 | xx.xx.xx.247 | 11.75 |
| 2018-12-24 12:06:10 | xx.xx.xx.240 | 10.77 |
| 2018-12-24 12:07:19 | xx.xx.xx.138 | 13.71 |
| 2018-12-24 22:43:07 | xx.xx.xx.247 | 10.77 |
| 2018-12-24 22:43:04 | xx.xx.xx.245 | 13.71 |
看上去貌似没什么规律,慢sql存在于不同的应用ip之上,排除某台应用出问题的可能。
超时时间从早上9点到晚上22点都有发现超时,排除了某个点集中性能下降的可能。
注意到一个微小的规律
笔者观察了一堆数据一段时间,终于发现了一点小规律,如下面两条所示:
| 业务开始时间 | 执行sql的应用ip | 业务执行耗时(s) |
|---|---|---|
| 2018-12-24 22:43:07 | xx.xx.xx.247 | 10.77 |
| 2018-12-24 22:43:04 | xx.xx.xx.245 | 13.71 |
这两笔sql超时对应的时间点挺接近的,一个是22:43:07,一个是22:43:04,中间只差了3s,然后与后面的业务执行耗时相加,发现更接近了,让我们重新整理下:
| 业务开始时间 | 执行sql的应用ip | 业务执行耗时(s) | 业务完成时间(s) |
|---|---|---|---|
| 2018-12-24 22:43:07 | xx.xx.xx.247 | 10.77 | 22:43:17.77 |
| 2018-12-24 22:43:04 | xx.xx.xx.245 | 13.71 | 22.43:17.71 |
发现这两笔业务虽然开始时间不同,但确是同时完成的,这可能是个巧合,也可能是bug出现导致的结果。于是继续看下是否有这些规律的慢sql,让业务又提供了最近的慢sql,发现这种现象虽然少,但是确实发生了不止一次。笔者突然感觉到,这绝对不是巧合。
由上述规律导致的思考
笔者联想到我们中间件有好多台,假设是中间件那边卡住的话,如果在那一瞬间,有两台sql同时落到同一台的话,中间件先卡住,然后在中间件恢复的那一瞬间,以0.5ms的速度执行完再返回就会导致这种现象。如下图所示:
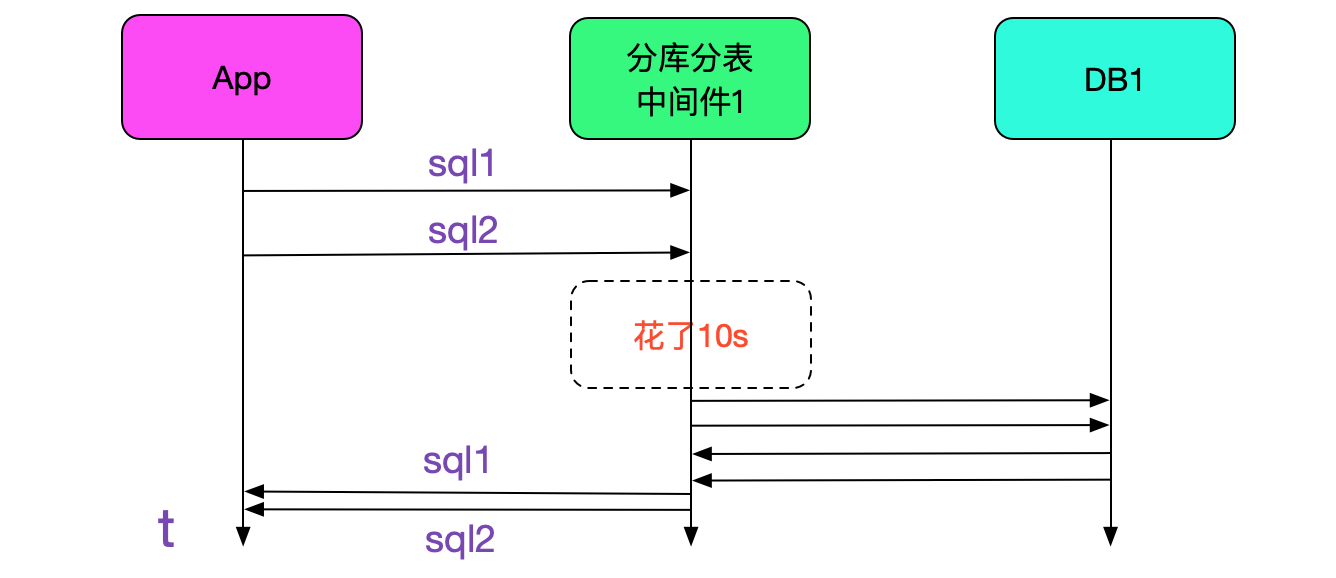
当然了还有另一种可能,就是sql先以0.5ms的速度执行完,然后中间件那边卡住了,和上面的区别只是中间件卡的位置不同而已,另一种可能如下图所示:
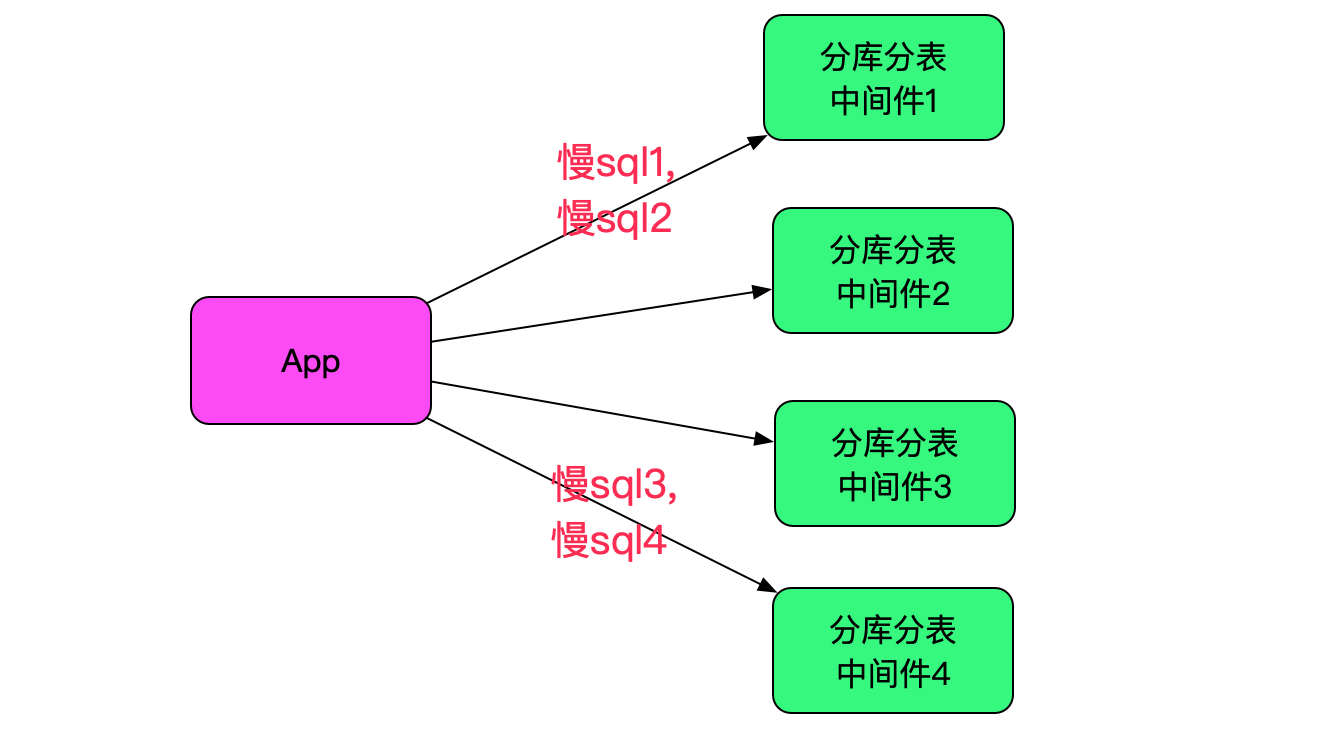
是否落到同一台中间件
线上一共4台中间件,在经历了一堆复杂线上日志捞取分析相对应之后,发现那两条sql确实落在了同一台中间件上。为了保证猜想无误,又找了两条符合此规律的sql,同样的也落在同一台中间件上面,而且这两台中间件并不是同一台,排除某台机器有问题。如下图所示:
业务日志和中间件日志相对照
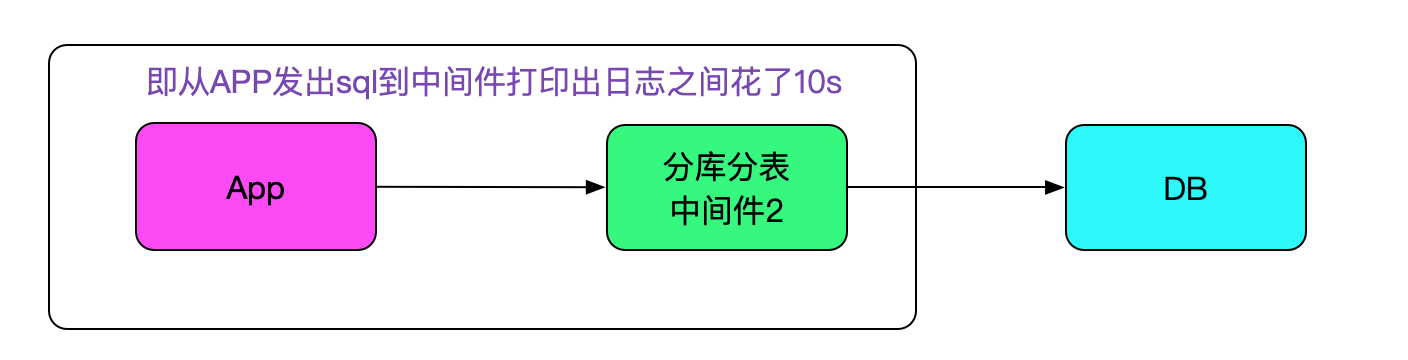
在上述发现的基础上,又经历了各种日志分析对应之后,终于找到了耗时sql日志和业务日志对应的关联。然后发现一个关键信息。中间件在接收到sql时候会打印一条日志,发现在应用发出sql到接收到sql还没来得及做后面的路由逻辑之前就差了10s左右,然后sql执行到返回确是非常快速的,如下图所示:
查看对应中间件那个时间点其它sql有无异常
笔者捞取了那个时间点中间件的日志,发现除了这两条sql之外,其它sql都很正常,整体耗时都在1ms左右,这又让笔者陷入了思考之中。
再从日志中找信息
在对当前中间件的日志做了各种思考各种分析之后,又发现一个诡异的点,发现在1s之内,处理慢sql对应的NIO线程的处理sql数量远远小于其它NIO线程。更进一步,发现在这1s的某个时间点之前,慢sql所在的NIO线程完全不打印任何日志,如下图所示:
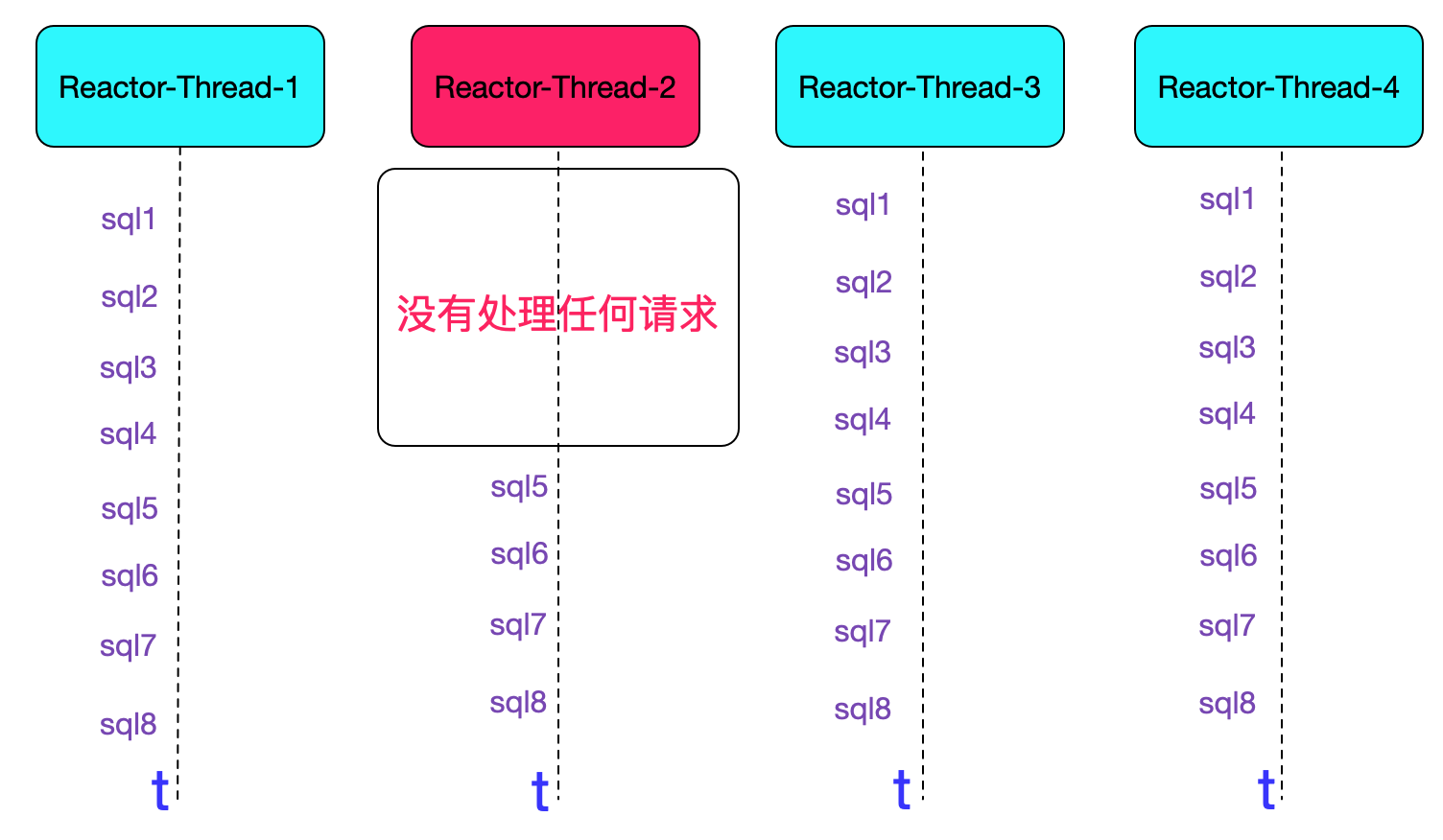
同时也发现两条sql都落在对应的Reactor-Thread-2的线程里面,再往前回溯,发现近10s内的线程都没有打印任何信息,好像什么都没处理。如下图所示:

感觉离真相越来越近了。这边就很明显了,reactor线程被卡住了!
寻找reactor线程为何被卡住
笔者继续顺藤摸瓜,比较了一下几个卡住的reactor线程最后打印的日志,发现这几条日志对应的sql都很快返回了,没什么异常。然后又比较了一下几个卡住的reactor线程恢复后打印出来的第一条sql,发现貌似它们通过路由解析起来都很慢,达到了1ms(正常是0.01ms),然后找出了其对应的sql,发现这几条sql都是150K左右的大小,按正常思路,这消失的10s应该就是处理这150K的sql了,如下图所示:

为何处理150K的sql会耗时10s
排查是否是网络问题
首先,这条sql在接入中间件之前就有,也就耗时0.5ms左右。而且中间件在往数据库发送sql的过程中也是差不多的时间。如果说网络有问题的话,那么这段时间应该会变长,此种情况暂不考虑。
排查是否是nio网络处理代码的问题
笔者鉴于可能是中间件nio处理代码的问题,构造了同样的sql在线下进行复现,发现执行很快毫无压力。笔者一度怀疑是线上环境的问题,traceroute了一下发现网络基本和线下搭建的环境一样,都是APP机器直连中间件机器,MTU都是1500,中间也没任何路由。思路一下又陷入了停滞。
柳暗花明
思考良久无果之后。笔者觉得排查一下是否是构造的场景有问题,突然发现,线上是用的prepareStatement,而笔者在命令行里面用的是statement,两者是有区别的,prepare是按照select ?,?,?带参数的形式而statement直接是select 1,2,3这样的形式。
而在我们的中间件中,由于后端的数据库对使用prepareStatement的sql具有较大的性能提升,我们也支持了prepareStatement。而且为了能够复用原来的sql解析代码,我们会在接收到对应的sql和参数之后将其还原成不带?的sql算出路由到的数据库节点后,再将原始的带?的sql和参数prepare到对应的数据库,如下图所示:
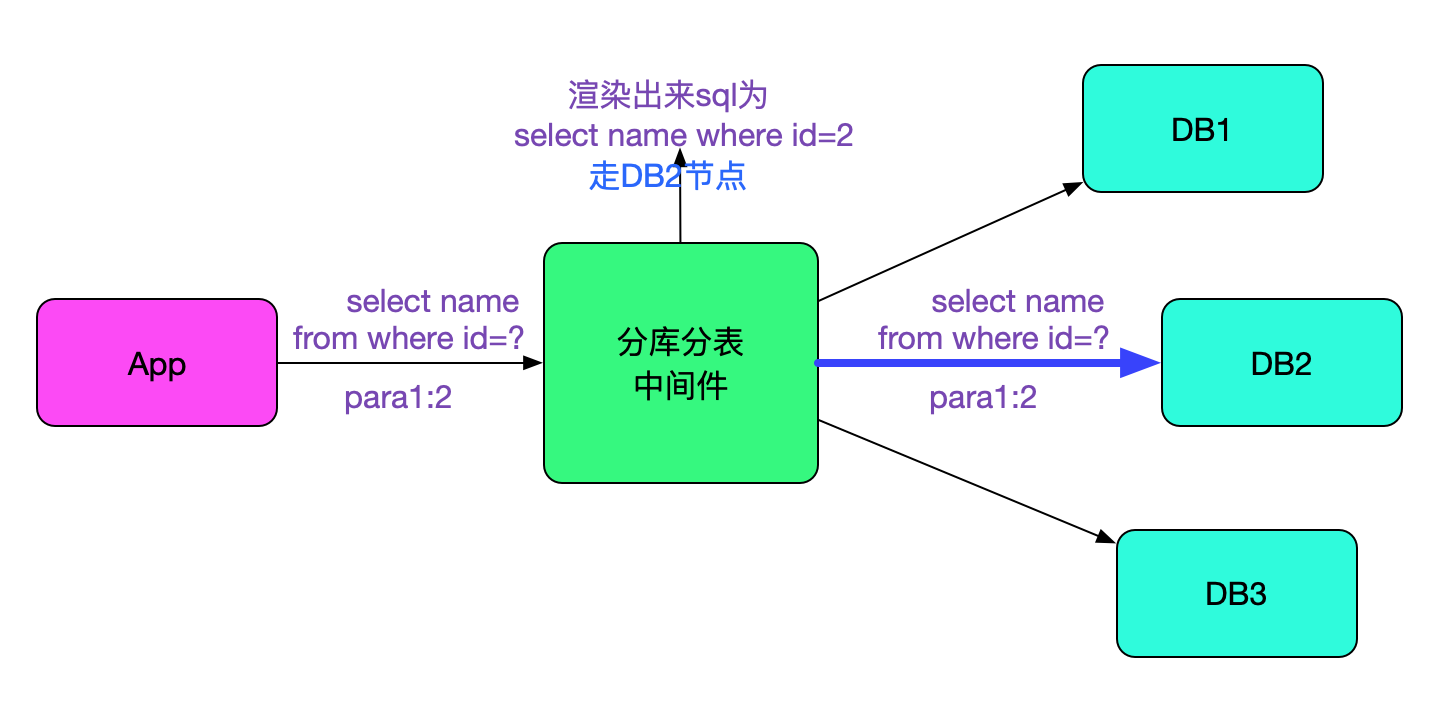
重新构造prepareStatement场景
笔者重新构造了prepareStatement场景之后,发现在150K的sql下,确实耗时达到了10s,感觉终于见到曙光了。
最终原因字符串拼接
由于是线下,在各种地方打日志之后,终于发现耗时就是在这个将带?的sql渲染为不带问号的sql上面。下面是代码示意:
String sql="select ?,?,?,?,?,?...?,?,?...";
for(int i=0 ; i < paramCount;i++){
sql = sql.replaceFirst("\?",param[i]);
}
return sql;
这个replaceFirst在字符串特别大,需要替换的字符频率出现的特别多的时候方面有巨大的性能消耗。之前就发现replaceFirst这个操作里面有正则的操作导致特殊符号不能正确渲染sql(另外参数里面带?也不能正确渲染),于是其改成了用split ?的方式进行sql的渲染。但是这个版本并没有在此应用对应的集群上使用。可能也正是这些额外的正则操作导致了这个replaceFirst性能在这种情况下特别差。
对应优化
将其改成新版本后,新代码如下所示:
String splits[] = sql.split("\?");
String result="";
for(int i=0;i<splits.length;i++){
if(i<paramNumber){
result+=splits[i]+getParamString(paramNumber);
}else{
result+=splits[i];
}
}
return result;
这个解析时间从10s下降至2s,但感觉还是不够满意。
经同事提醒,试下StringBuilder。由于此应用使用的是jdk1.8,笔者一直觉得jdk1.8已经可以直接用原生的字符串拼接不需要用StringBuilder了。但还是试了一试,发现从2s下降至8ms!
改成StringBuilder的代码后如下所示:
String splits[] = sql.split("\?");
StringBuilder builder = new StringBuilder();
for(int i=0;i<splits.length;i++){
if(i<paramNumber){
builder.append(splits[i]).append(getParamString(paramNumber));
}else{
builder.append(splits[i]);
}
}
return builder.toString();
笔者查了下资料,发现jdk 1.8虽然做了优化,但是每做一次拼接还是新建了一个StringBuilder,所以在大字符串频繁拼接的场景还是需要用一个StringBuilder,以避免额外的性能损耗。
总结
IO线程不能做任何耗时的操作,这样会导致整个吞吐量急剧下降,对应分库分表这种基础组件在编写代码的时候必须要仔细评估,连java原生的replaceFirst也会在特定情况下出现巨大的性能问题,不能遗漏任何一个点,否则就是下一个坑。
每一次复杂Bug的分析过程都是一次挑战,解决问题最重要也是最困难的是定位问题。而定位问题需要的是在看到现象时候能够浮现出的各种思路,然后通过日志等信息去一条条否决自己的思路,直至达到唯一的那个问题点。
公众号
关注笔者公众号,获取更多干货文章:

