记录一次OCR程序开发的尝试
最近工作中涉及到一部分文档和纸质文档的校验工作,就想把纸质文件拍下来,用文字来互相校验。想到之前调用有道智云接口做了文档翻译。看了下OCR文字识别的API接口,有道提供了多种OCR识别的不同接口,有手写体、印刷体、表格、整题识别、购物小票识别、身份证、名片等。干脆这次就继续用有道智云接口做个小demo,把这些功能都试了试,当练手,也当为以后的可能用到的功能做准备了。
调用API接口的准备工作
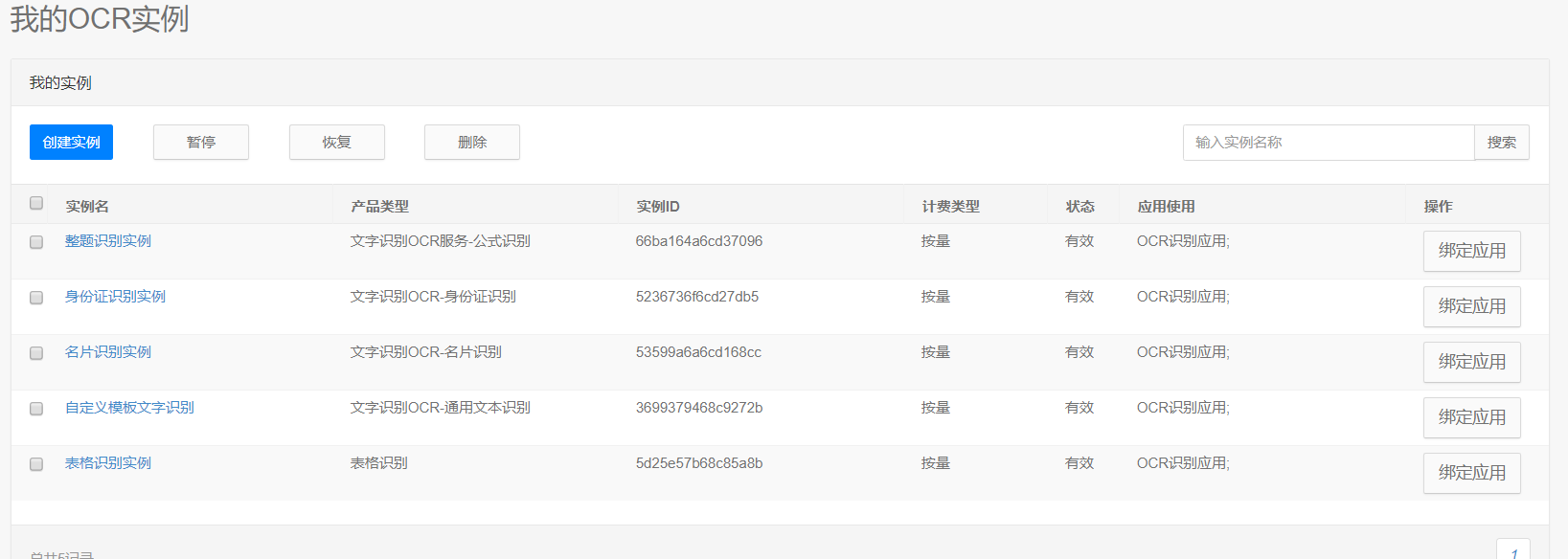
首先,是需要在有道智云的个人页面上创建实例、创建应用、绑定应用和实例,获取到应用的id和密钥。具体个人注册的过程和应用创建过程详见文章分享一次批量文件翻译的开发过程

开发过程详细介绍
下面介绍具体的代码开发过程:
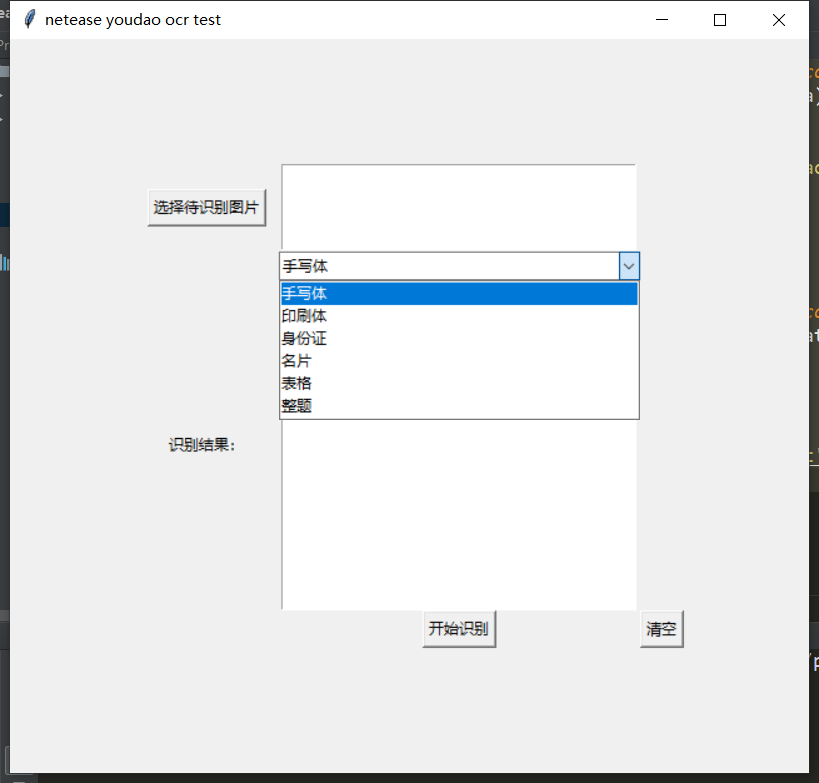
这次的demo使用python3开发,包括maindow.py,ocrprocesser.py,ocrtools.py三个文件。界面部分,为了简化开发过程,使用python自带的tkinter库,提供选择待识别文件和识别类型、展示识别结果的功能;ocrprocesser.py根据所选类型调用相应api接口,完成识别过程并返回结果;ocrtools.py封装了经整理后的有道ocr 的各类api,实现了分类调用。
-
界面部分:
界面部分代码如下,使用了tkinter的grid来排列元素。
root=tk.Tk() root.title("netease youdao ocr test") frm = tk.Frame(root) frm.grid(padx='50', pady='50') btn_get_file = tk.Button(frm, text='选择待识别图片', command=get_files) btn_get_file.grid(row=0, column=0, padx='10', pady='20') text1 = tk.Text(frm, width='40', height='5') text1.grid(row=0, column=1) combox=ttk.Combobox(frm,textvariable=tk.StringVar(),width=38) combox["value"]=img_type_dict combox.current(0) combox.bind("<<ComboboxSelected>>",get_img_type) combox.grid(row=1,column=1) label=tk.Label(frm,text="识别结果:") label.grid(row=2,column=0) text_result=tk.Text(frm,width='40',height='10') text_result.grid(row=2,column=1) btn_sure=tk.Button(frm,text="开始识别",command=ocr_files) btn_sure.grid(row=3,column=1) btn_clean=tk.Button(frm,text="清空",command=clean_text) btn_clean.grid(row=3,column=2) root.mainloop()其中btn_sure的绑定事件ocr_files()将文件路径和识别类型传入ocrprocesser:
def ocr_files(): if ocr_model.img_paths: ocr_result=ocr_model.ocr_files() text_result.insert(tk.END,ocr_result) else : tk.messagebox.showinfo("提示","无文件") -
ocrprocesser中主要方法为ocr_files(),将图片base64处理后调用封装的api。
def ocr_files(self): for img_path in self.img_paths: img_file_name=os.path.basename(img_path).split('.')[0] #print('==========='+img_file_name+'===========') f=open(img_path,'rb') img_code=base64.b64encode(f.read()).decode('utf-8') f.close() print(img_code) ocr_result= self.ocr_by_netease(img_code, self.img_type) print(ocr_result) return ocr_result -
经本人通读整理有道api的文档,大致分为以下四个api入口:手写体/印刷体识别、身份证/名片识别、表格识别、整题识别,每个接口的url不同,请求参数也不全一致,因此demo中首先根据识别类型加以区分:
# 0-hand write # 1-print # 2-ID card # 3-name card # 4-table # 5-problem def get_ocr_result(img_code,img_type): if img_type==0 or img_type==1: return ocr_common(img_code) elif img_type==2 or img_type==3 : return ocr_card(img_code,img_type) elif img_type==4: return ocr_table(img_code) elif img_type==5: return ocr_problem(img_code) else: return "error:undefined type!"而后根据接口所需的参数组织data等字段,并针对不同接口的返回值进行简单解析和处理,并返回:
def ocr_common(img_code): YOUDAO_URL='https://openapi.youdao.com/ocrapi' data = {} data['detectType'] = '10012' data['imageType'] = '1' data['langType'] = 'auto' data['img'] =img_code data['docType'] = 'json' data=get_sign_and_salt(data,img_code) response=do_request(YOUDAO_URL,data)['regions'] result=[] for r in response: for line in r['lines']: result.append(line['text']) return result def ocr_card(img_code,img_type): YOUDAO_URL='https://openapi.youdao.com/ocr_structure' data={} if img_type==2: data['structureType'] = 'idcard' elif img_type==3: data['structureType'] = 'namecard' data['q'] = img_code data['docType'] = 'json' data=get_sign_and_salt(data,img_code) return do_request(YOUDAO_URL,data) def ocr_table(img_code): YOUDAO_URL='https://openapi.youdao.com/ocr_table' data = {} data['type'] = '1' data['q'] = img_code data['docType'] = 'json' data=get_sign_and_salt(data,img_code) return do_request(YOUDAO_URL,data) def ocr_problem(img_code): YOUDAO_URL='https://openapi.youdao.com/ocr_formula' data = {} data['detectType'] = '10011' data['imageType'] = '1' data['img'] = img_code data['docType'] = 'json' data=get_sign_and_salt(data,img_code) response=do_request(YOUDAO_URL,data)['regions'] result = [] for r in response: for line in r['lines']: for l in line: result.append(l['text']) return resultget_sign_and_salt()为data加入了必要的签名等信息:
def get_sign_and_salt(data,img_code): data['signType'] = 'v3' curtime = str(int(time.time())) data['curtime'] = curtime salt = str(uuid.uuid1()) signStr = APP_KEY + truncate(img_code) + salt + curtime + APP_SECRET sign = encrypt(signStr) data['appKey'] = APP_KEY data['salt'] = salt data['sign'] = sign return data
效果展示
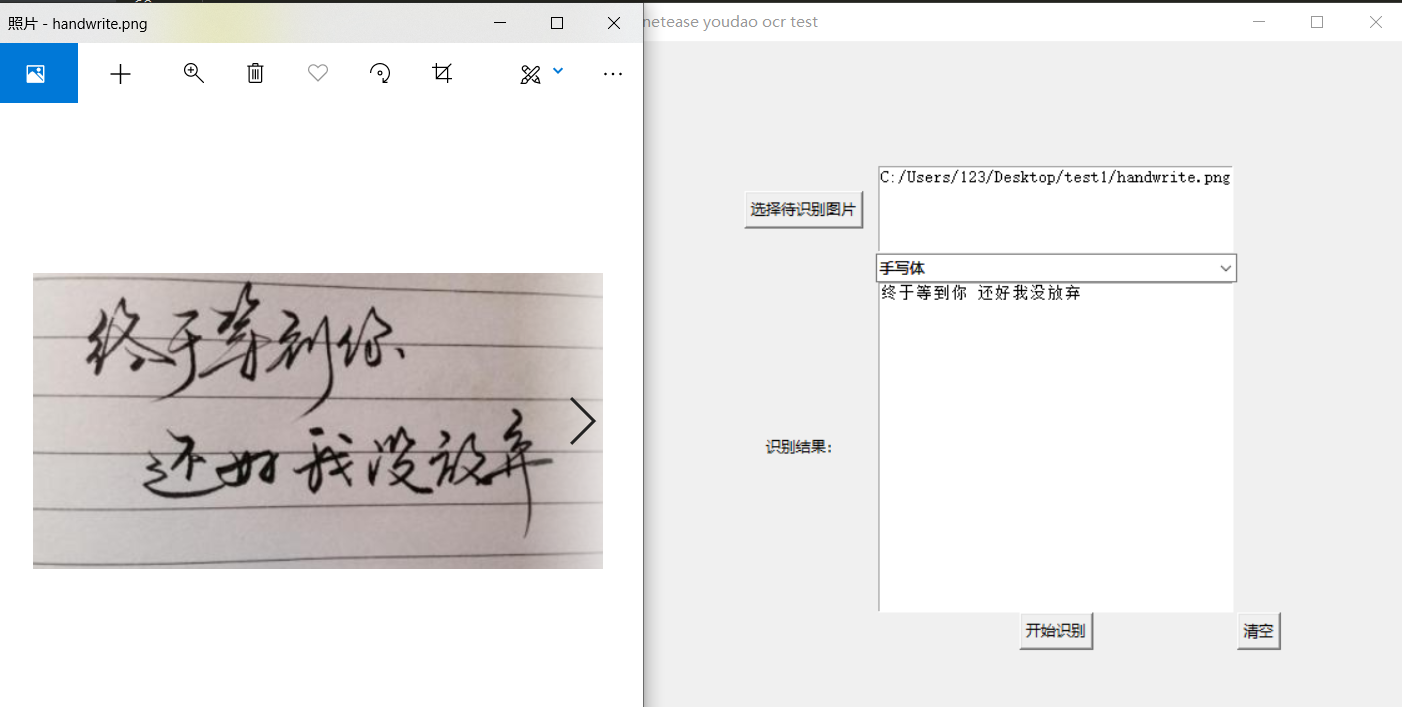
手写体结果展示:
印刷体(程序媛拿来代码识别一番):

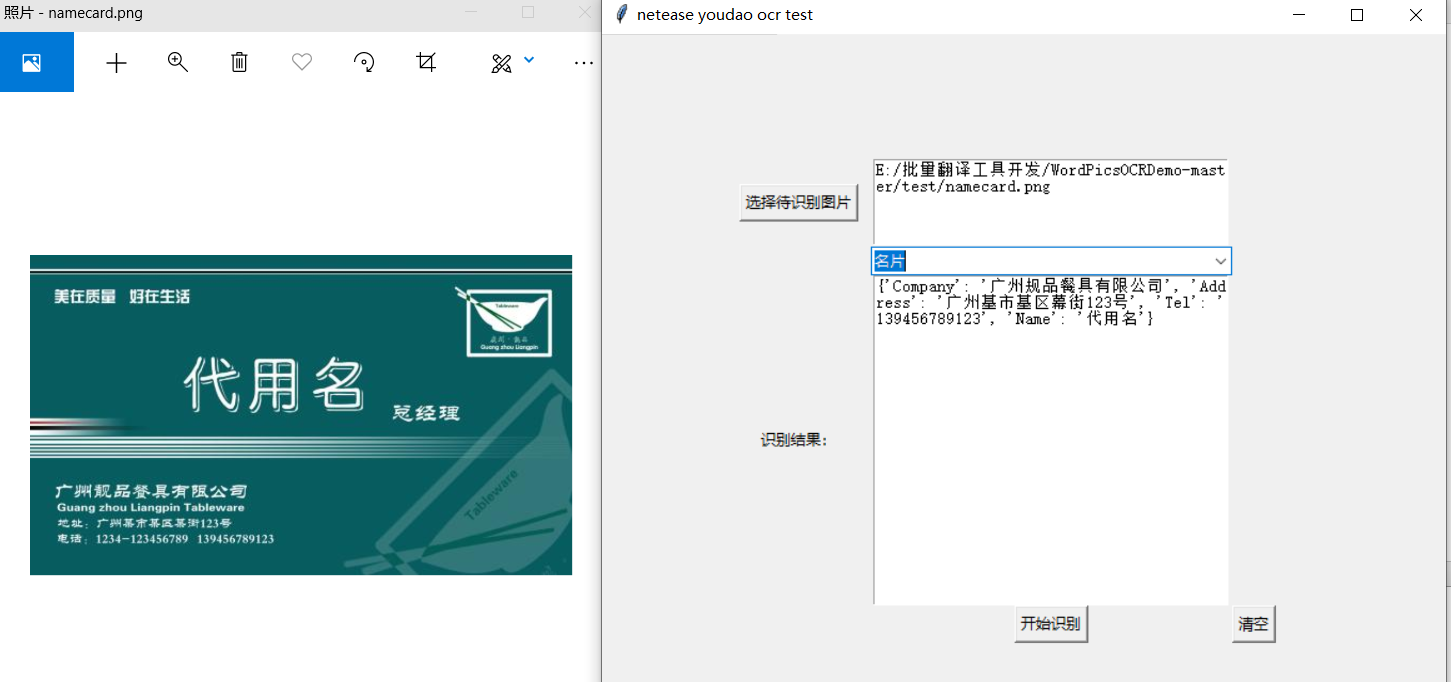
名片识别,这里我找来了一个名片模板,看起来准度还是可以的:
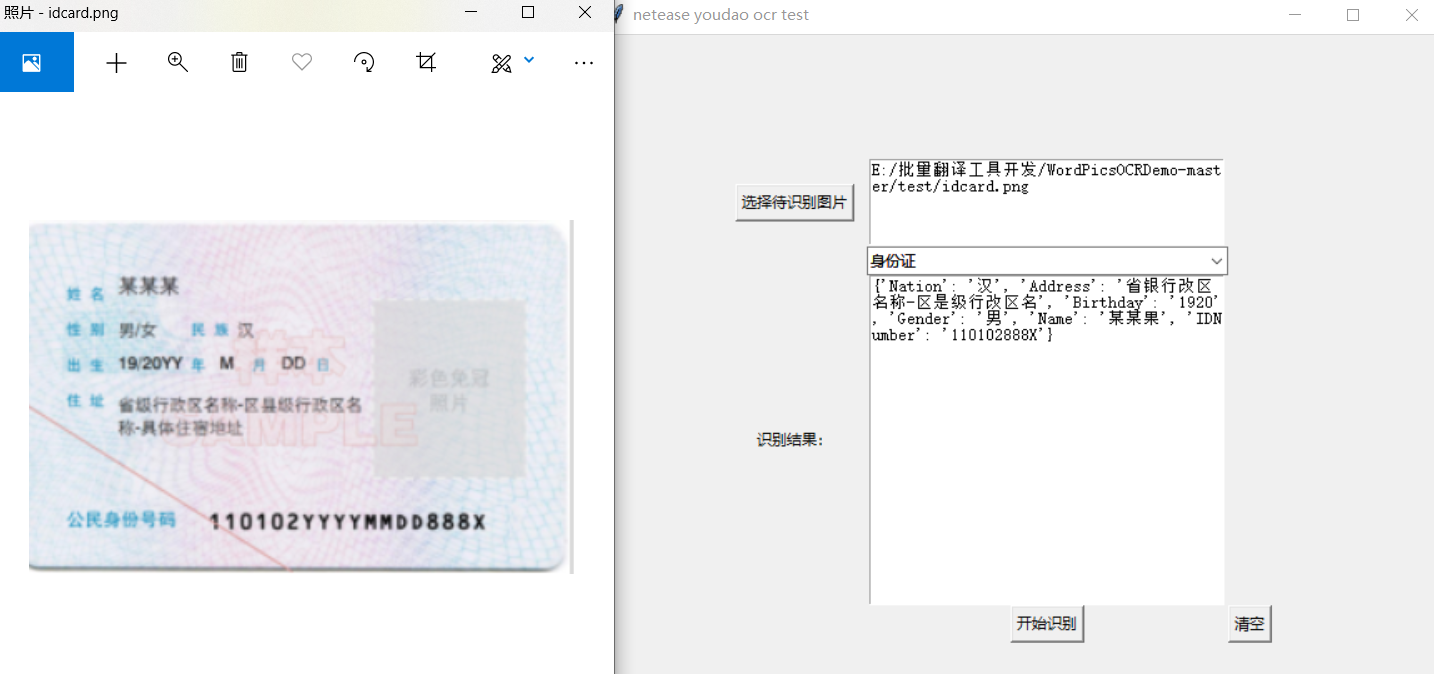
身份证(同样是模板):
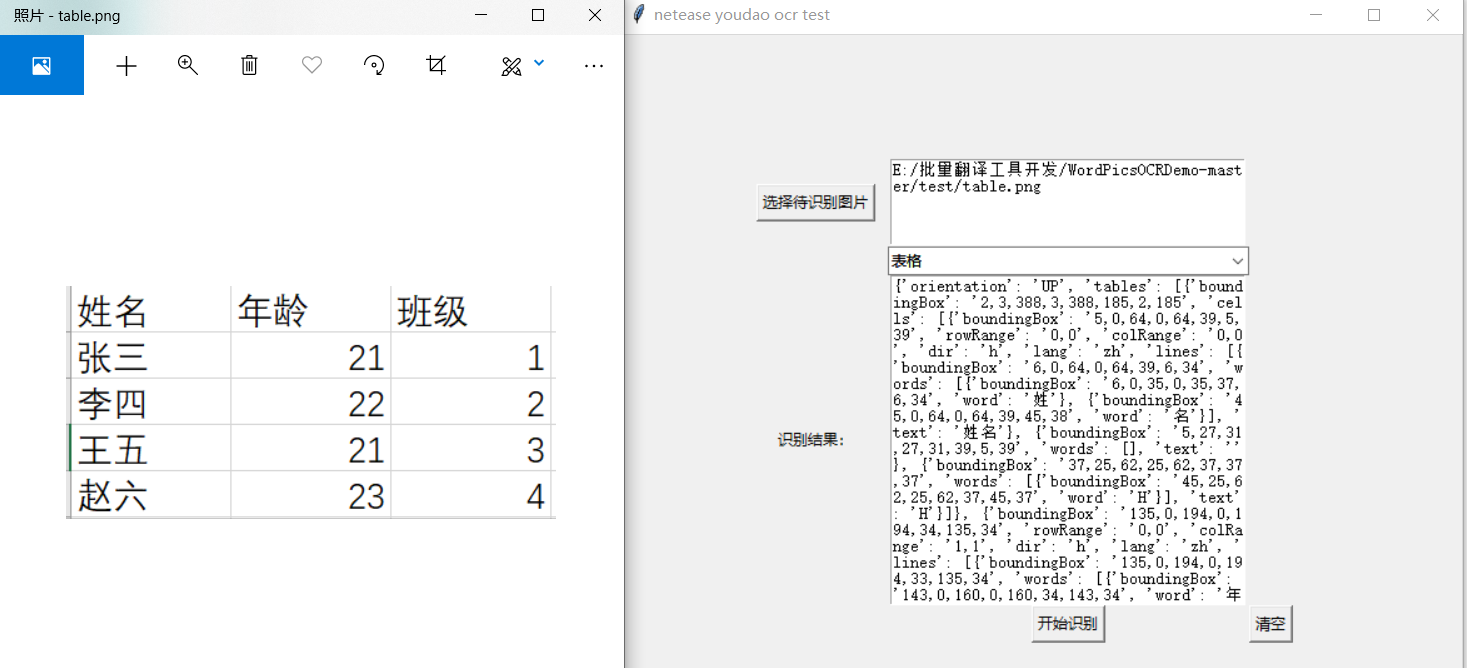
表格识别(这超长的json, >_< emmm......):
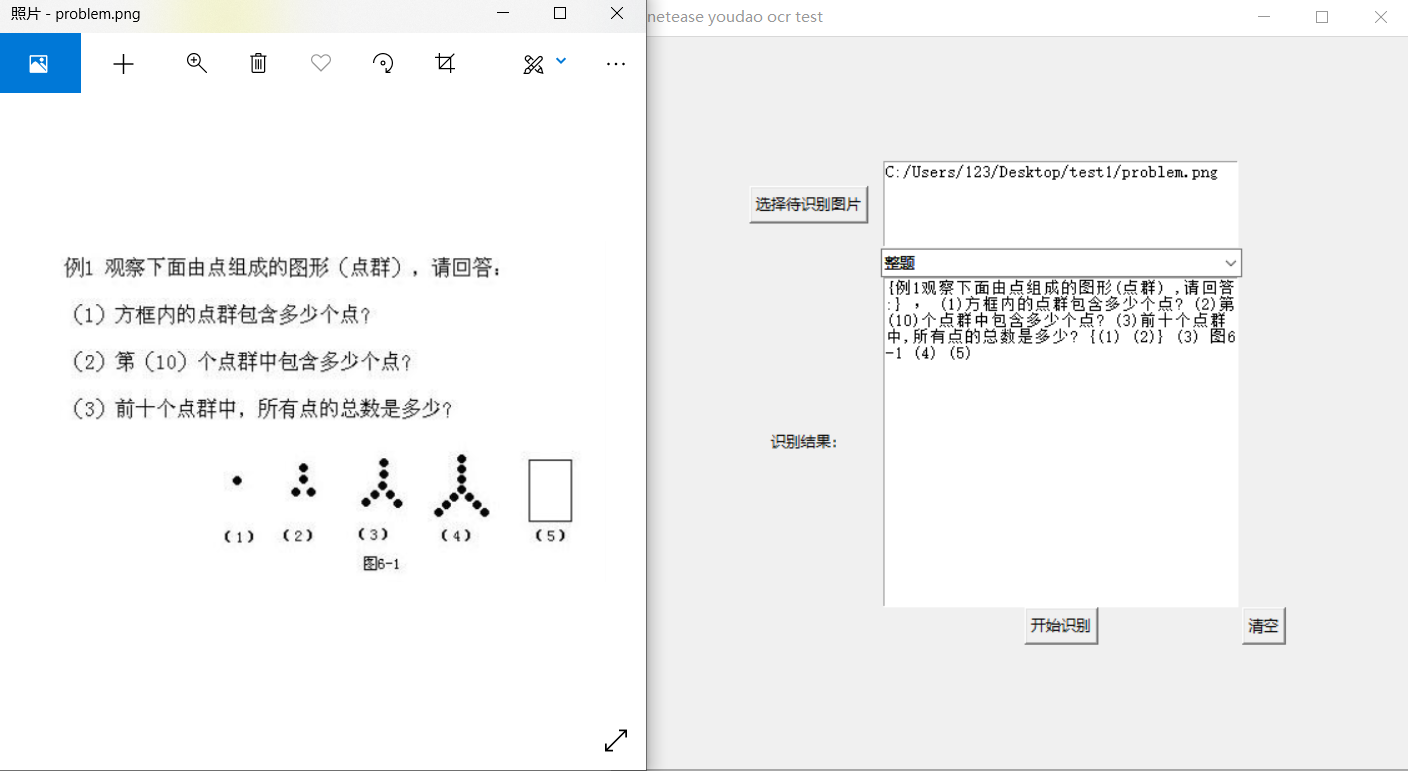
整题识别(公式识别也有做,识别结果json比较长,看起来没那么直观,就不在这里贴了):
总结
总的而言,接口功能还是很强大的,各种都支持。就是视觉算法工程师没有做分类功能,需要自己分别对每一类的图像进行分接口调用,而且接口完全不可混用,比如在开发过程中我将名片图片当作身份证提交给api,结果返回了“Items not found!”,对于调用api的开发者来讲有点麻烦,当然这样也在一定程度上提高了识别准确率,而且个人猜测应该也是为了方便分接口计费 : P。