Prometheus时序数据库-磁盘中的存储结构
前言
之前的文章里,笔者详细描述了监控数据在Prometheus内存中的结构。而其在磁盘中的存储结构,也是非常有意思的,关于这部分内容,将在本篇文章进行阐述。
磁盘目录结构
首先我们来看Prometheus运行后,所形成的文件目录结构
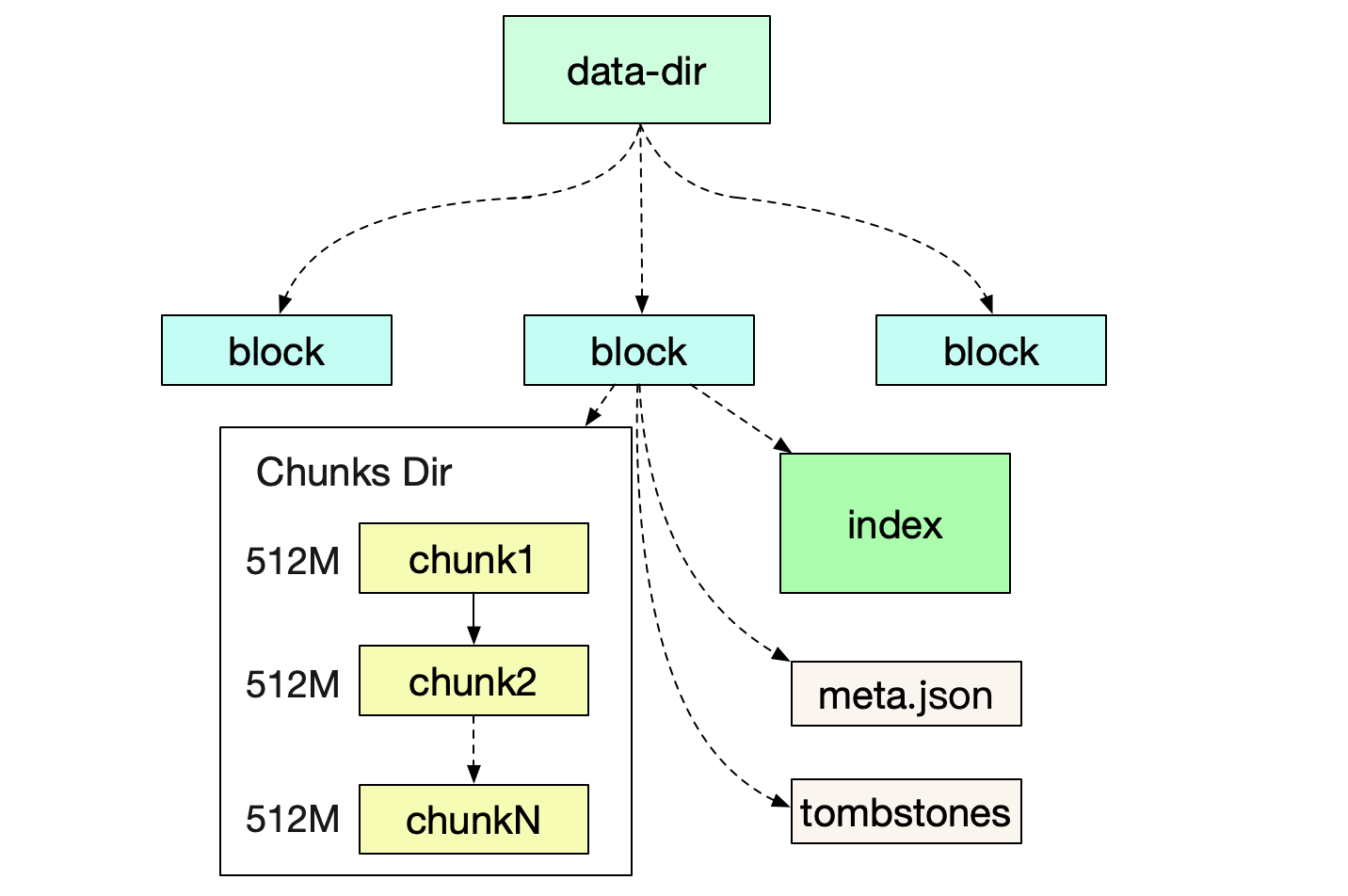
在笔者自己的机器上的具体结构如下:
prometheus-data
|-01EY0EH5JA3ABCB0PXHAPP999D (block)
|-01EY0EH5JA3QCQB0PXHAPP999D (block)
|-chunks
|-000001
|-000002
.....
|-000021
|-index
|-meta.json
|-tombstones
|-wal
|-chunks_head
Block
一个Block就是一个独立的小型数据库,其保存了一段时间内所有查询所用到的信息。包括标签/索引/符号表数据等等。Block的实质就是将一段时间里的内存数据组织成文件形式保存下来。
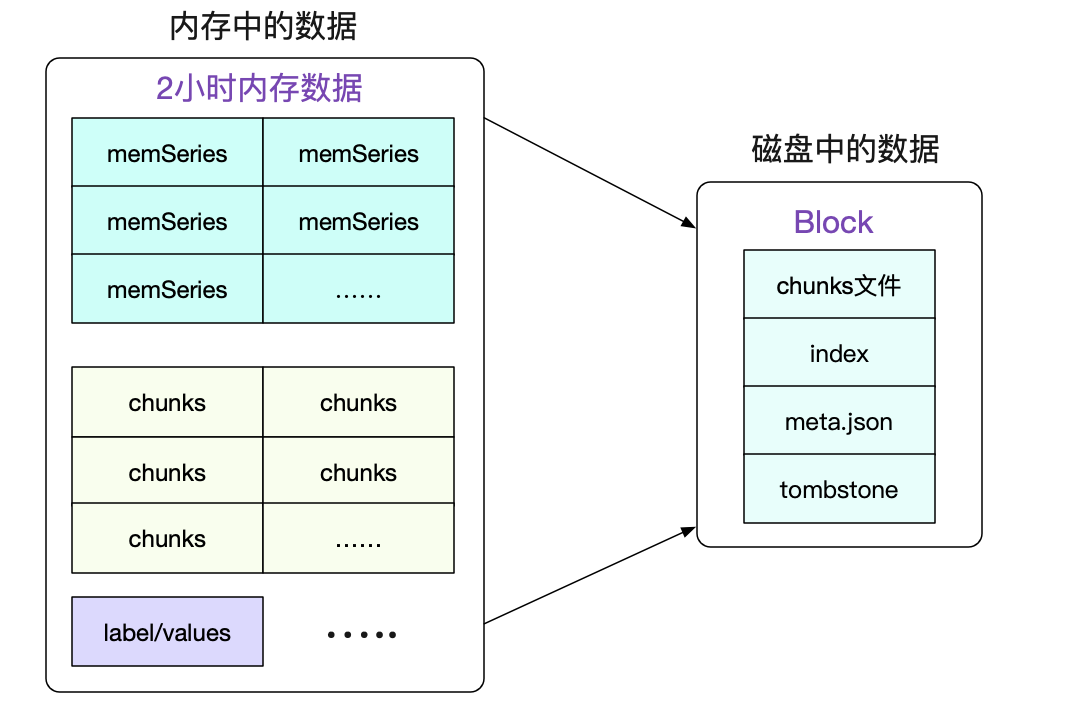
最近的Block一般是存储了2小时的数据,而较为久远的Block则会通过compactor进行合并,一个Block可能存储了若干小时的信息。值得注意的是,合并操作只是减少了索引的大小(尤其是符号表的合并),而本身数据(chunks)的大小并没有任何改变。
meta.json
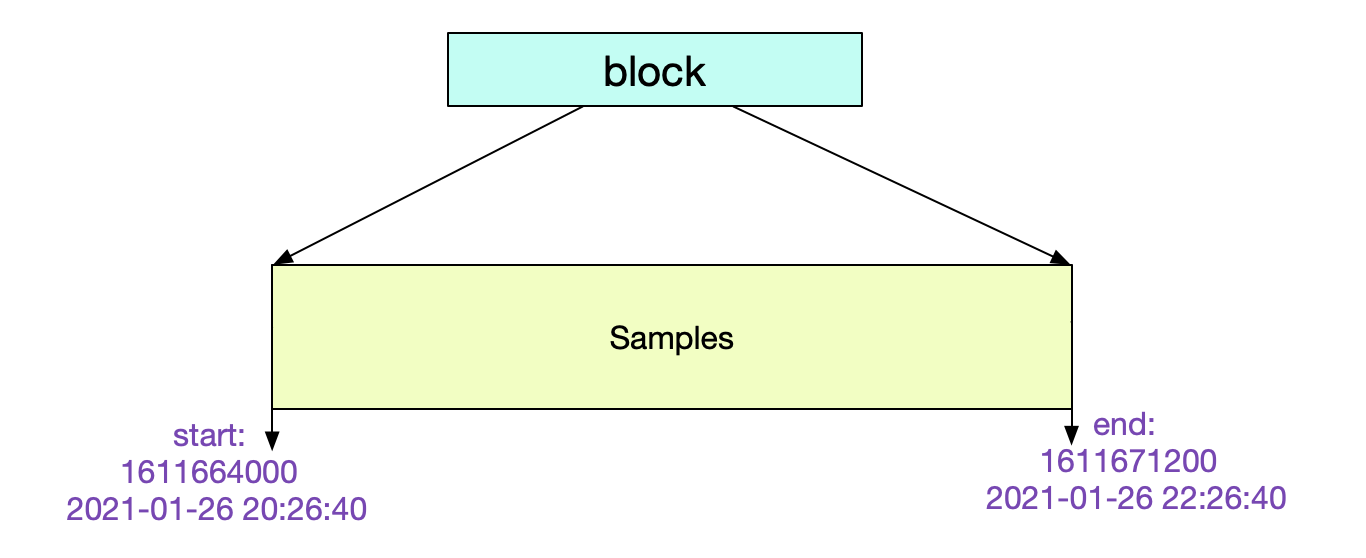
我们可以通过检查meta.json来得到当前Block的一些元信息。
{
"ulid":"01EY0EH5JA3QCQB0PXHAPP999D"
// maxTime-minTime = 7200s => 2 h
"minTime": 1611664000000
"maxTime": 1611671200000
"stats": {
"numSamples": 1505855631,
"numSeries": 12063563,
"numChunks": 12063563
}
"compaction":{
"level" : 1
"sources: [
"01EY0EH5JA3QCQB0PXHAPP999D"
]
}
"version":1
}
其中的元信息非常清楚明了。这个Block记录了从2个小时的数据。
让我们再找一个比较陈旧的Block看下它的meta.json.
"ulid":"01EXTEH5JA3QCQB0PXHAPP999D",
// maxTime - maxTime =>162h
"minTime":1610964800000,
"maxTime":1611548000000
......
"compaction":{
"level": 5,
"sources: [
31个01EX......
]
},
"parents: [
{
"ulid": 01EXTEH5JA3QCQB1PXHAPP999D
...
}
{
"ulid": 01EXTEH6JA3QCQB1PXHAPP999D
...
}
{
"ulid": 01EXTEH5JA31CQB1PXHAPP999D
...
}
]
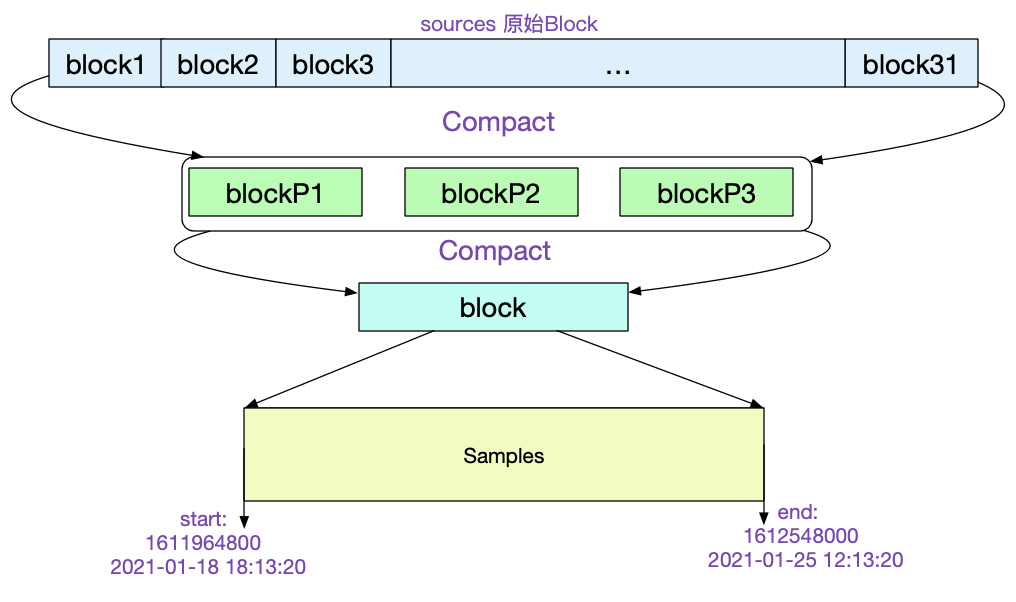
从中我们可以看到,该Block是由31个原始Block经历5次压缩而来。最后一次压缩的三个Block ulid记录在parents中。如下图所示:
Chunks结构
CUT文件切分
所有的Chunk文件在磁盘上都不会大于512M,对应的源码为:
func (w *Writer) WriteChunks(chks ...Meta) error {
......
for i, chk := range chks {
cutNewBatch := (i != 0) && (batchSize+SegmentHeaderSize > w.segmentSize)
......
if cutNewBatch {
......
}
......
}
}
当写入磁盘单个文件超过512M的时候,就会自动切分一个新的文件。
一个Chunks文件包含了非常多的内存Chunk结构,如下图所示:
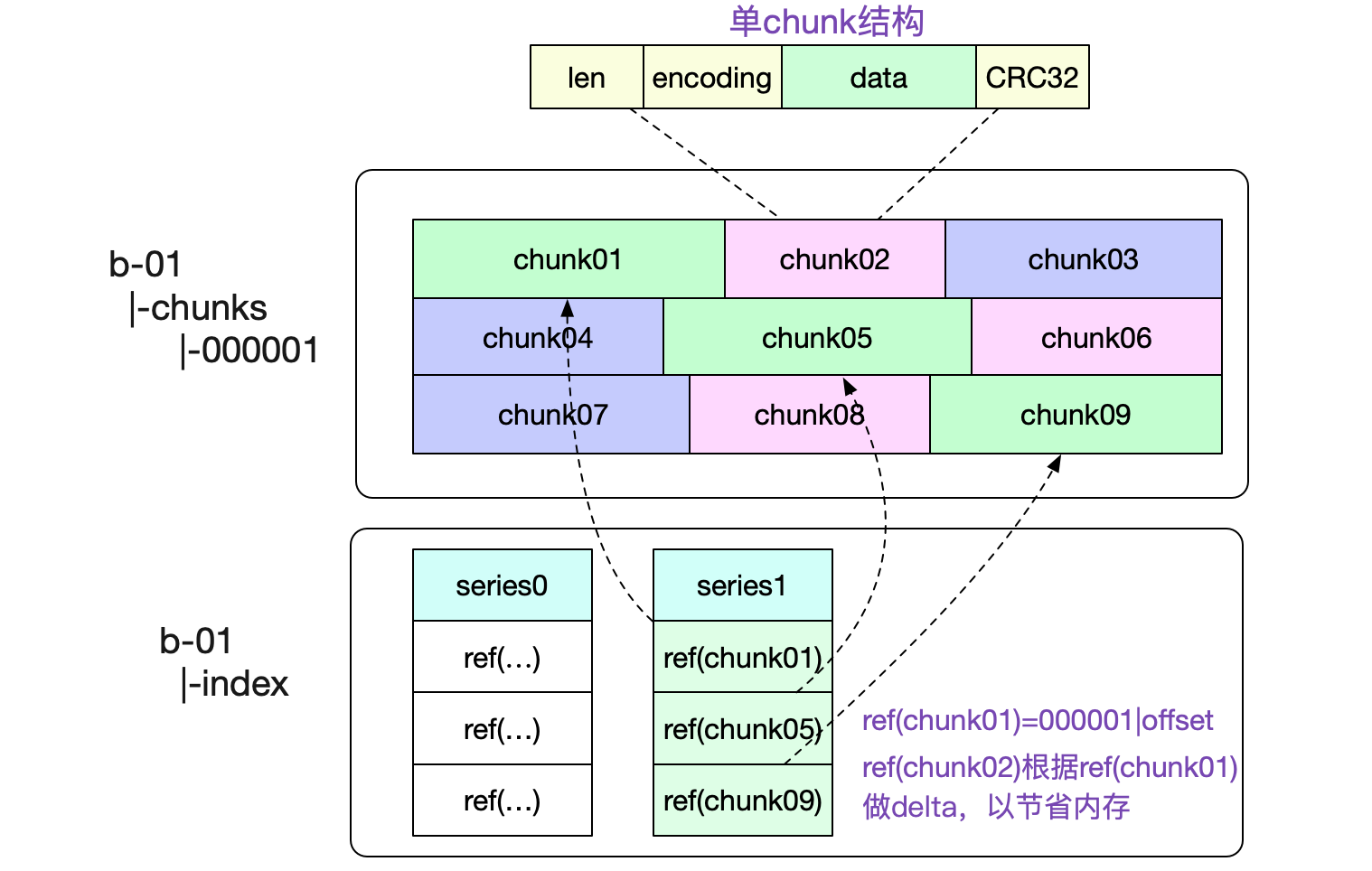
图中也标出了,我们是怎么寻找对应Chunk的。通过将文件名(000001,前32位)以及(offset,后32位)编码到一个int类型的refId中,使得我们可以轻松的通过这个id获取到对应的chunk数据。
chunks文件通过mmap去访问
由于chunks文件大小基本固定(最大512M),所以我们很容易的可以通过mmap去访问对应的数据。直接将对应文件的读操作交给操作系统,既省心又省力。对应代码为:
func NewDirReader(dir string, pool chunkenc.Pool) (*Reader, error) {
......
for _, fn := range files {
f, err := fileutil.OpenMmapFile(fn)
......
}
......
bs = append(bs, realByteSlice(f.Bytes()))
}
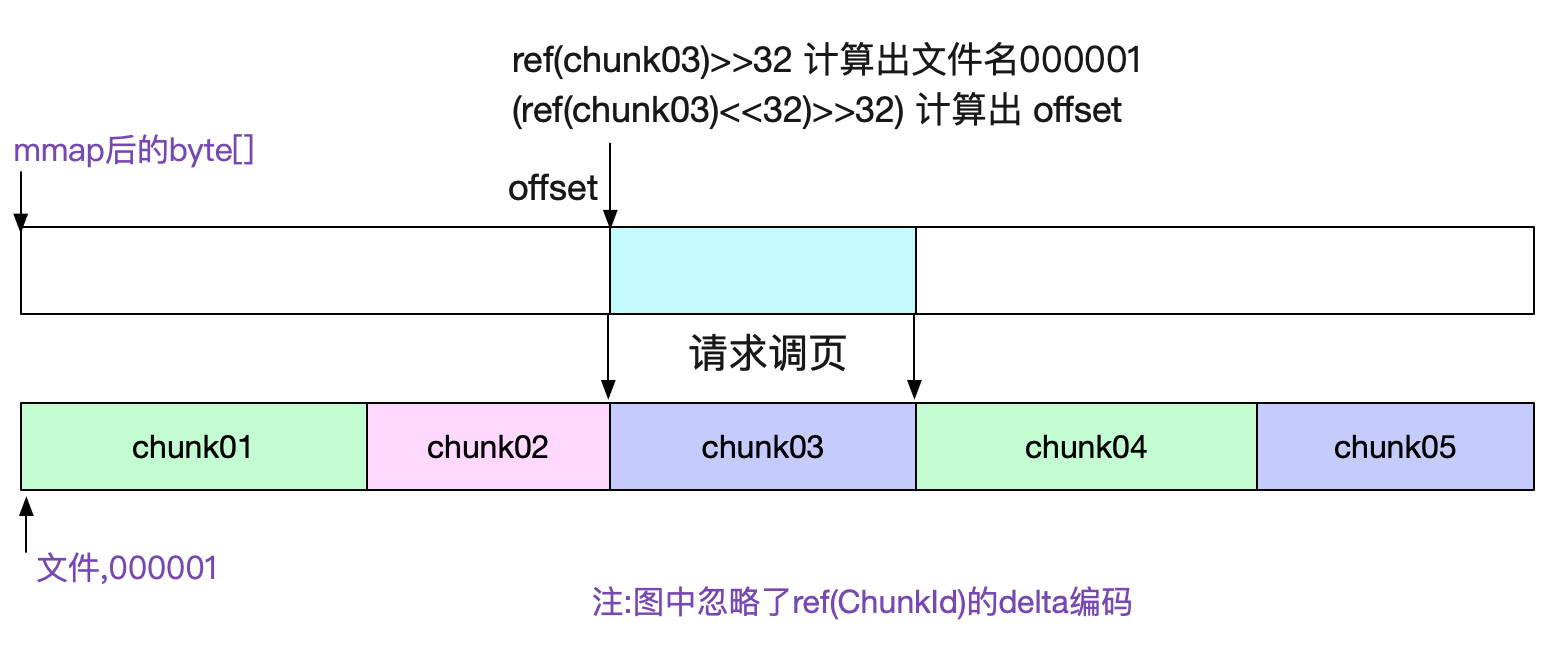
通过sgmBytes := s.bs[offset]就直接能获取对应的数据
index索引结构
前面介绍完chunk文件,我们就可以开始阐述最复杂的索引结构了。
寻址过程
索引就是为了让我们快速的找到想要的内容,为了便于理解。笔者就通过一次数据的寻址来探究Prometheus的磁盘索引结构。考虑查询一个
拥有系列三个标签
({__name__:http_requests}{job:api-server}{instance:0})
且时间为start/end的所有序列数据
我们先从选择Block开始,遍历所有Block的meta.json,找到具体的Block
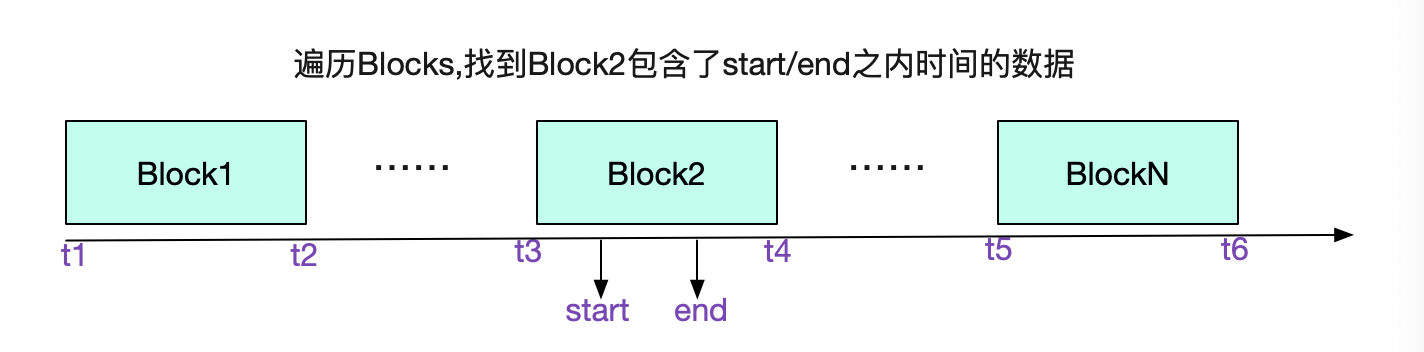
前文说了,通过Labels找数据是通过倒排索引。我们的倒排索引是保存在index文件里面的。 那么怎么在这个单一文件里找到倒排索引的位置呢?这就引入了TOC(Table Of Content)
TOC(Table Of Content)
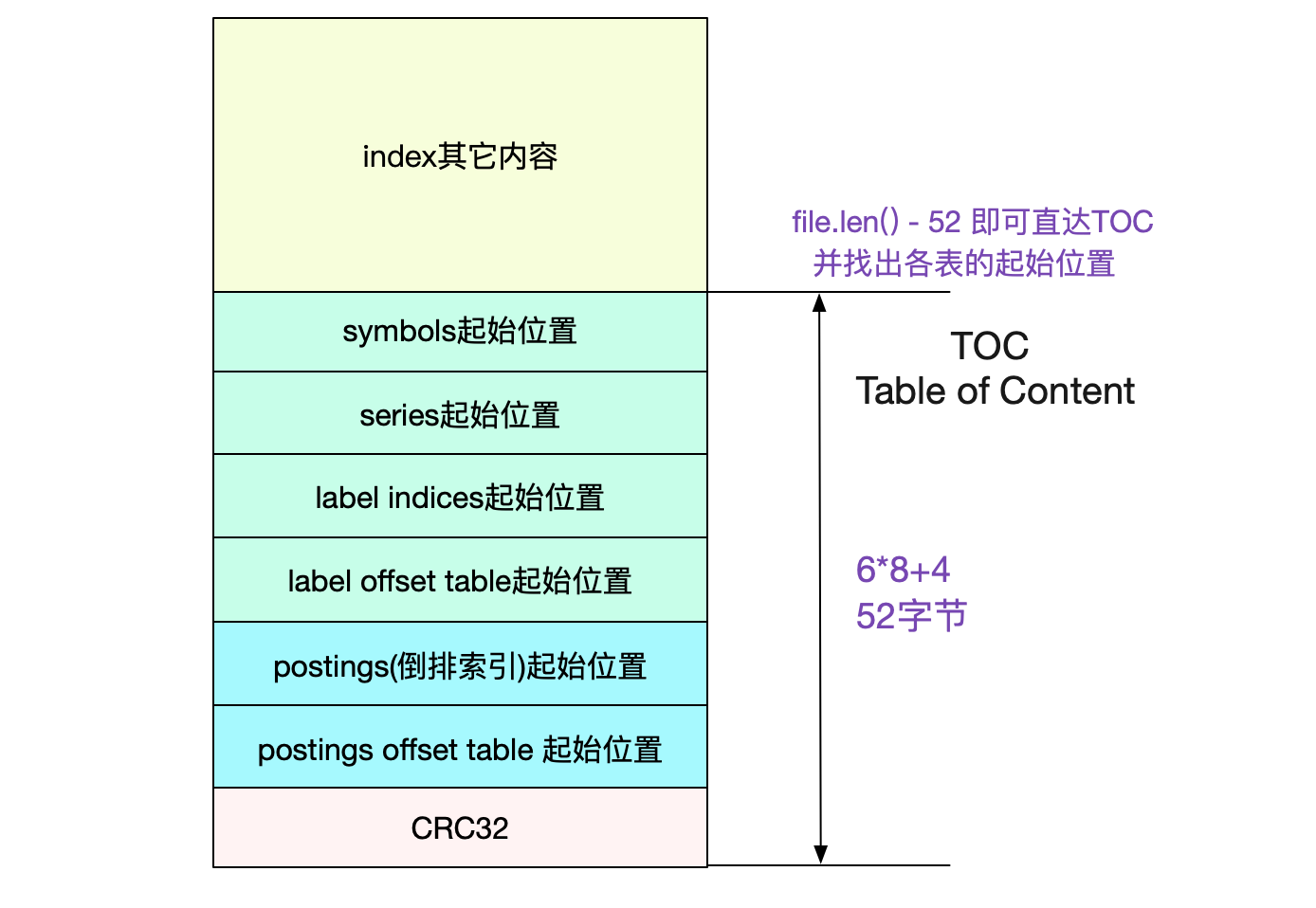
由于index文件一旦形成之后就不再会改变,所以Prometheus也依旧使用mmap来进行操作。采用mmap读取TOC非常容易:
func NewTOCFromByteSlice(bs ByteSlice) (*TOC, error) {
......
// indexTOCLen = 6*8+4 = 52
b := bs.Range(bs.Len()-indexTOCLen, bs.Len())
......
return &TOC{
Symbols: d.Be64(),
Series: d.Be64(),
LabelIndices: d.Be64(),
LabelIndicesTable: d.Be64(),
Postings: d.Be64(),
PostingsTable: d.Be64(),
}, nil
}
Posting offset table 以及 Posting倒排索引
首先我们访问的是Posting offset table。由于倒排索引按照不同的LabelPair(key/value)会有非常多的条目。所以Posing offset table就是决定到底访问哪一条Posting索引。offset就是指的这一Posting条目在文件中的偏移。
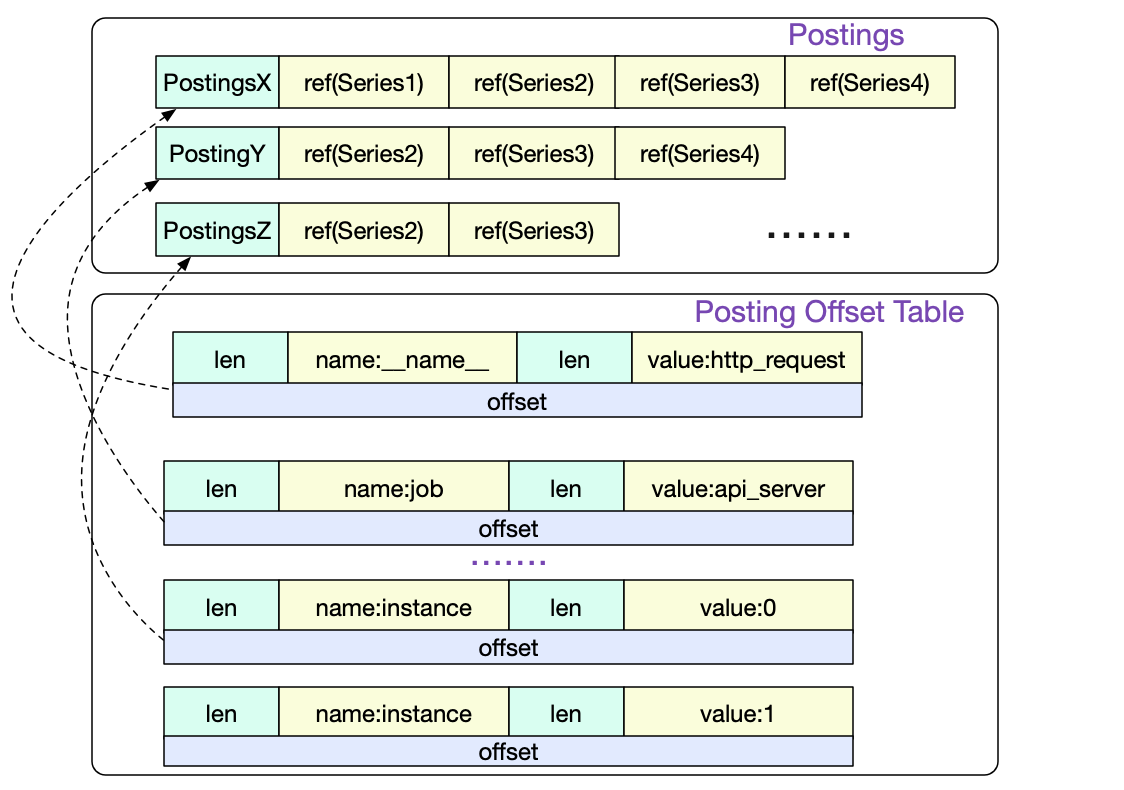
Series
我们通过三条Postings倒排索引索引取交集得出
{series1,Series2,Series3,Series4}
∩
{series1,Series2,Series3}
∩
{Series2,Series3}
=
{Series2,Series3}
也就是要读取Series2和Serie3中的数据,而Posting中的Ref(Series2)和Ref(Series3)即为这两Series在index文件中的偏移。
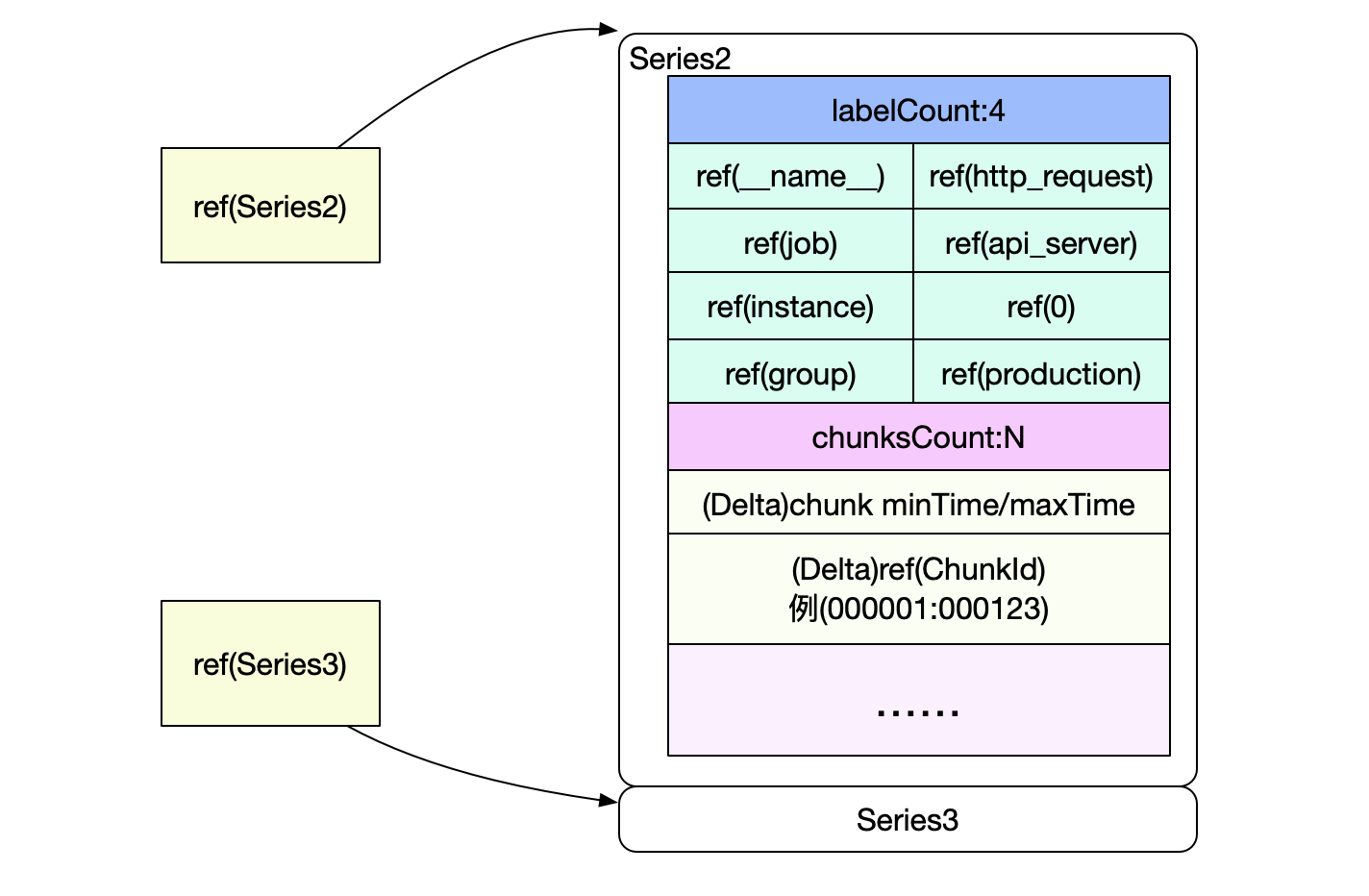
Series以Delta的形式记录了chunkId以及该chunk包含的时间范围。这样就可以很容易过滤出我们需要的chunk,然后再按照chunk文件的访问,即可找到最终的原始数据。
SymbolTable
值得注意的是,为了尽量减少我们文件的大小,对于Label的Name和Value这些有限的数据,我们会按照字母序存在符号表中。由于是有序的,所以我们可以直接将符号表认为是一个
[]string切片。然后通过切片的下标去获取对应的sting。考虑如下符号表:
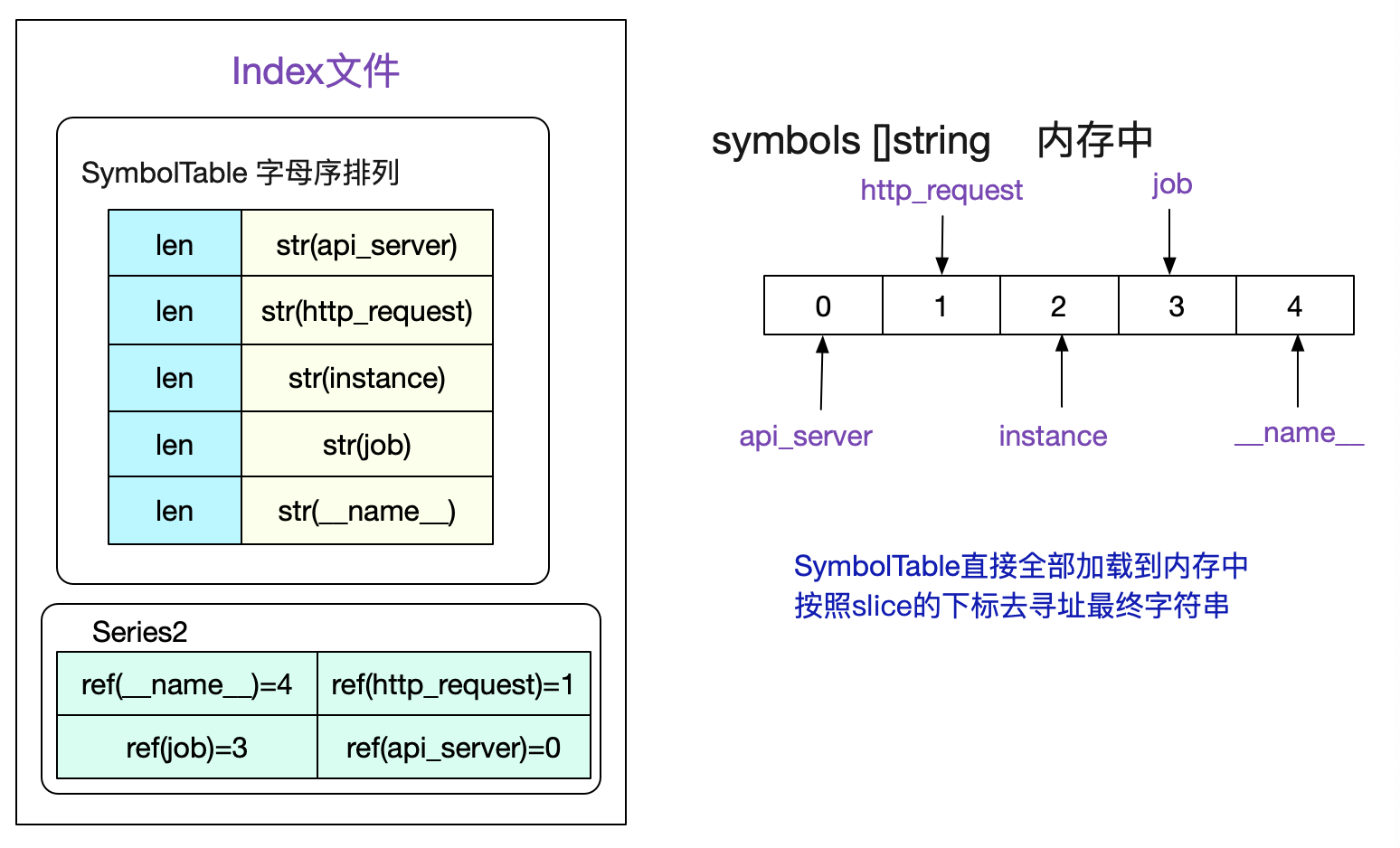
读取index文件时候,会将SymbolTable全部加载到内存中,并组织成symbols []string这样的切片形式,这样一个Series中的所有标签值即可通过切片下标访问得到。
Label Index以及Label Table
事实上,前面的介绍已经将一个普通数据寻址的过程全部讲完了。但是index文件中还包含label索引以及label Table,这两个是用来记录一个Label下面所有可能的值而存在的。
这样,在正则的时候就可以非常容易的找到我们需要哪些LabelPair。详情可以见前篇。
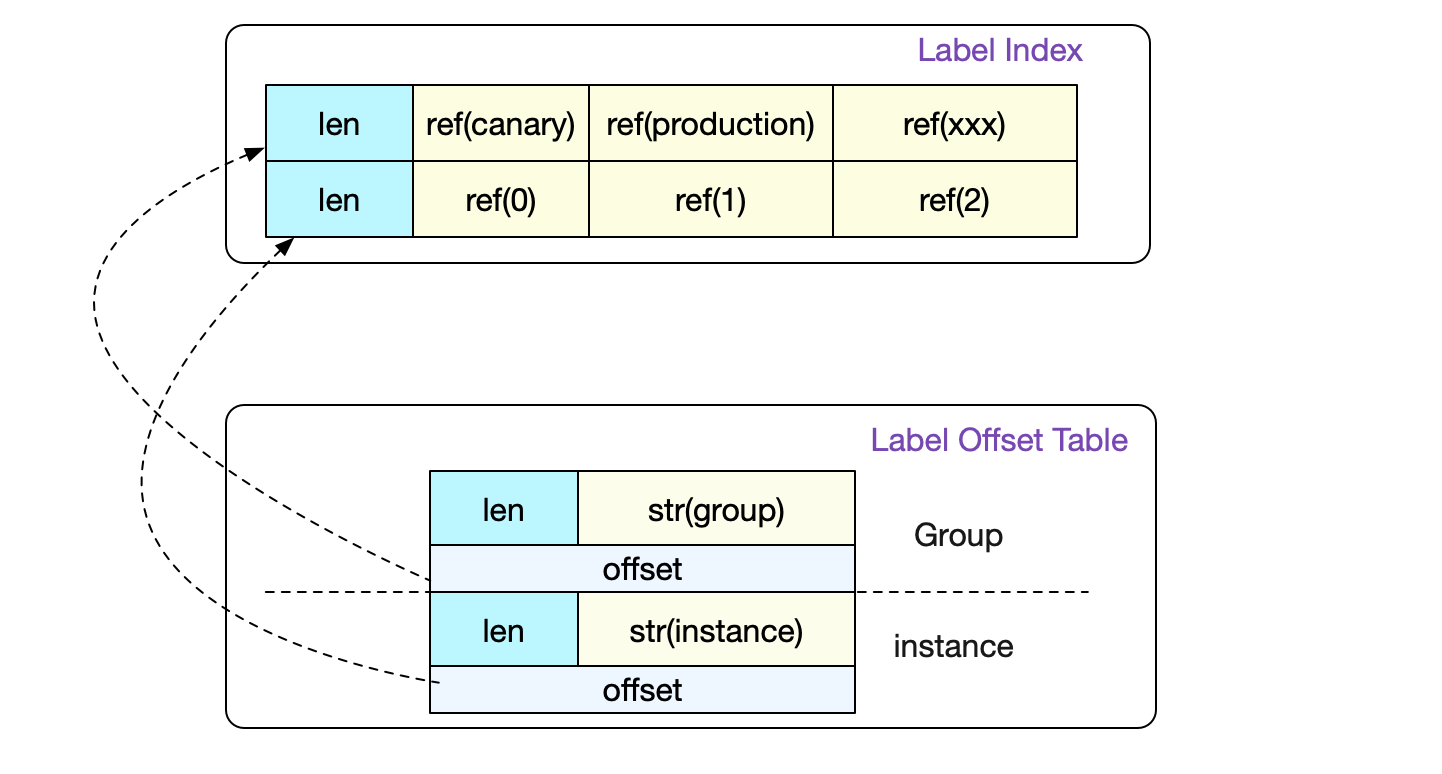
事实上,真正的Label Index比图中要复杂一点。它设计成一条LabelIndex可以表示(多个标签组合)的所有数据。不过在Prometheus代码中只会采用存储一个标签对应所有值的形式。
完整的index文件结构
这里直接给出完整的index文件结构,摘自Prometheus中index.md文档。
┌────────────────────────────┬─────────────────────┐
│ magic(0xBAAAD700) <4b> │ version(1) <1 byte> │
├────────────────────────────┴─────────────────────┤
│ ┌──────────────────────────────────────────────┐ │
│ │ Symbol Table │ │
│ ├──────────────────────────────────────────────┤ │
│ │ Series │ │
│ ├──────────────────────────────────────────────┤ │
│ │ Label Index 1 │ │
│ ├──────────────────────────────────────────────┤ │
│ │ ... │ │
│ ├──────────────────────────────────────────────┤ │
│ │ Label Index N │ │
│ ├──────────────────────────────────────────────┤ │
│ │ Postings 1 │ │
│ ├──────────────────────────────────────────────┤ │
│ │ ... │ │
│ ├──────────────────────────────────────────────┤ │
│ │ Postings N │ │
│ ├──────────────────────────────────────────────┤ │
│ │ Label Index Table │ │
│ ├──────────────────────────────────────────────┤ │
│ │ Postings Table │ │
│ ├──────────────────────────────────────────────┤ │
│ │ TOC │ │
│ └──────────────────────────────────────────────┘ │
└──────────────────────────────────────────────────┘
tombstones
由于Prometheus Block的数据一般在写完后就不会变动。如果要删除部分数据,就只能记录一下删除数据的范围,由下一次compactor组成新block的时候删除。而记录这些信息的文件即是tomstones。
总结
Prometheus作为时序数据库,设计了各种文件结构来保存海量的监控数据,同时还兼顾了性能。只有彻底了解其存储结构,才能更好的指导我们应用它!
欢迎大家关注我公众号,里面有各种干货,还有大礼包相送哦!
