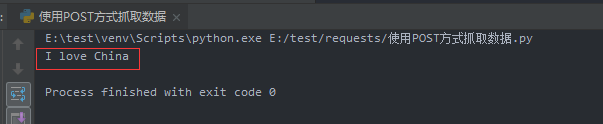
安装requests库 pip install requests
1.使用GET方式抓取数据:
import requests #导入requests库 url="http://www.cntour.cn/" #需要爬取的网址 strhtml = requests.get(url); #使用GET方式,获取网页数据 print(strhtml.text) #打印html源码

2.使用POST方式抓取数据
网址:有道翻译:http://fanyi.youdao.com/
按F12 进入开发者模式,单击Network,此时内容为空,如图:
输入‘’我爱中国‘’,翻译就会出现:

单击Headers,发现请求数据的方式为POST:

将url指取出来赋值:url=‘http://fanyi.youdao.com/translate?smartresult=dict&smartresult=rule’(把_o去掉)
POST请求获取数据的方式不同于GET,POST请求数据必须构建请求头才可以,所以把Form Data中的请求参数复制出来构建新字典:

#!/usr/bin/env python # -*- coding:utf-8 -*- # Author:XXC import requests import json #定义获取信息函数 def get_translate_date(word=None): url='http://fanyi.youdao.com/translate?smartresult=dict&smartresult=rule' Form_data = { 'i': '我爱中国', 'from': 'AUTO', 'to': 'AUTO', 'smartresult': 'dict', 'client': 'fanyideskweb', 'salt': '1539098682270', 'sign': 'f293c39aa50f57d4d35eb6822f162f72', 'doctype': 'json', 'version': '2.1', 'keyfrom':'fanyi.web', 'action': 'FY_BY_REALTIME', 'typoResult': 'false', } #请求表单数据 response = requests.post(url,data=Form_data) #将json格式字符串转字典 content = json.loads(response.text) #打印翻译后的数据 print(content['translateResult'][0][0]['tgt']) if __name__ == '__main__': get_translate_date('我爱中国')