鸡汤之人丑就要读书
推荐:《追风筝的人》《白鹿原》《阿甘正传》《幸德勒的名单》
三元运算
三元运算又称三目运算,是对简单的条件语句的简写,如:
简单条件语句:
if 条件成立: val = 1 else: val = 2
改为三元运算:
val = 1 if 条件成立 else 2
例子:
>>> a = 2 >>> b = 5 >>> val = a if a < b else b >>> val 2 >>> val = a if 3 > 6 else b >>> val 5 >>>
文件处理
假如有一个文件“保密资料.txt”,如何查看里面的内容呢?
1. 安装文本编辑器
2. 选中右键,利用文本编辑器软件打开
3. 查看 or 写入
4. 保存,关闭
以上是我们通常在电脑中对一个文件从打开到关闭的操作流程。
在Python中文件操作分为读、写、修改,我们先从读开始学习。
文件处理-读(r,rb):
文件不存在会报错。
f = open(file="保密资料.txt", mode="r", encoding="utf-8") # 打开文件 data = f.read() # 读文件 print(data) # 输出内容
f.close() # 关闭文件
运行输出内容为:我是测试文件
file="保密资料.txt" 表示文件路径,如果文件不在当前目录要写绝对路径
mode="r" 表示以只读模式打开(还有其他的模式,后面讲述)
encoding="utf-8" 表示将硬盘上的0101010按照utf-8的规则去“断句”,再将“断句”后的每一段0101010转换成unicode的01010101,unicode对照表中有01010101和字符的对应关系
r.read() 表示读取所有内容,内容是已经转换完毕的字符串
f.close() 表示关闭文件
关于编码说明:
如果文件本身是以gbk存的,那么python在打开的时候就需要指定encoding="gbk",如果以utf-8是会乱码的。
二进制模式读文件:
f = open(file="保密资料.txt", mode="rb") # 打开文件 data = f.read() # 读文件
print(data) #输出内容 f.close() # 关闭文件
运行输出内容为:b'xe6x88x91xe6x98xafxe6xb5x8bxe8xafx95xe6x96x87xe4xbbxb6'
mode为 b 时,就不用写encoding了,因为 b 表示二进制模式,不进行转码,硬盘怎么存的就怎么取出来,但取出来的是二进制数据,不能很好的阅读,所以通常用于网络传输。
智能检测编码的工具:
上面两个例子有啥区别呢?就是在第2个例子中没有指定encoding,因为是直接以rb模式打开了文件,rb是指二进制模式,数据读到内存里直接是bytes格式,如果想看内容,还需要手动decode,因此在文件打开阶段,不需要指定编码。
那么问题来了,假如你不知道你要处理的文件是什么编码的怎么办呢?
有一个工具(chardet)可以告诉你:
f = open(file="测试文件.txt", mode="rb") data = f.read() print(data) # 输出 b'xcexd2xcaxc7xb2xe2xcaxd4xcexc4xbcxfe' 不可读/不易读 f.close() import chardet # 引入chardet模块 res = chardet.detect(open(file="测试文件.txt", mode="rb").read()) print(res) # 输出 {'encoding': 'GB2312', 'confidence': 0.99, 'language': 'Chinese'} 得到文件编码99%可能是GB2312 print(data.decode("GB2312")) # 对二进制数据进行按GB2312解码,正确输出内容:我是测试文件
文件处理-写(w,wb):
文件不存在不会报错,会直接创建一个。文件存在会直接清空掉原有的内容,写入新的内容。
# “路飞学城”是unicode的,写文件的时候以gbk方式进行写入 f = open(file="测试文件2.txt", mode="w", encoding="gbk") f.write("路飞学城") f.close()
wb模式:
f = open("测试文件3.txt", "wb") # f.write("路飞学城") # 直接write的话会报错,TypeError: a bytes-like object is required, not 'str' f.write("路飞学城".encode("gbk")) # “路飞学城”是字符串,需要encode,如果encode什么都不写默认是utf-8,这里我们以gbk来写入 f.close()
文件处理-追加(a,ab):
f = open(file="测试文件3.txt",mode="a",encoding="gbk") f.write("我是追加内容") f.close()
ab模式:
f = open(file="测试文件3.txt",mode="ab") f.write(" 第二行追加内容".encode("gbk")) f.close()
注意:
文件操作时,以“a”或“ab”模式打开,则只能追加,即:在原来内容的尾部追加内容
写到硬盘上时,必须是某种编码的0101010,打开时需要注意:
ab,写入时需要直接传入以某种编码的0100101,即字节类型
a和encoding,写入时需要传入unicode字符串,内部会根据encoding指定的编码将unicode字符串转换为改编码的010101010
文件处理-混合模式(r+,w+):
r+ 模式:
f = open(file="测试文件3.txt", mode="r+", encoding="gbk") data = f.read() # 读文件的内容 print("content:", data) # 打印文件的内容 f.write(" 新内容1") # 写入新内容 f.write(" 新内容2") # 写入新内容 print("new content:", f.read()) # 再次读文件内容 f.close()
运行结果:
content: 第一行内容 第二行内容 新内容1 新内容2 new content:
从运行结果可以看到,之前的内容已经完整输出了,但是后面一次读的时候什么也没有输出来。
因为:
r+ (读写,先读后写,写是追加写):因为文件一打开文件光标在最开始的位置,在读了一遍之后,光标就到了最后了,然后又写入内容到文件,每写完新的内容光标都会依次位移到最后,第二次读的时候没有读到内容,是因为此时的光标已经在最后了,再读的话他会读光标之后的数据,而光标后在最后已经没有数据了,所以读不到。可以通过 f.seek(0) 的方式将光标移到文件开始就可以读到全部内容了。
w+(写读,以写的模式打开,支持读):会先把原来的内容清掉,然后新写入内容,读的话就只能读新写的内容。
w+模式:
f = open(file="测试文件3.txt", mode="w+", encoding="gbk") data = f.read() # 读文件的内容,w模式已经将文件清掉,读不到内容 print("content:", data) # 打印文件的内容 f.write(" 新内容1") # 写入新内容 f.write(" 新内容2") # 写入新内容 print("new content", f.read()) # 再次读文件内容,光标没有在文件开始,读不到内容 f.close()
文件操作的其他方法:
def fileno(self, *args, **kwargs): # real signature unknown 返回文件句柄在内核中的索引值,以后做IO多路复用时可以用到 def flush(self, *args, **kwargs): # real signature unknown 把文件从内存buffer里强制刷新到硬盘 def readable(self, *args, **kwargs): # real signature unknown 判断是否可读 def readline(self, *args, **kwargs): # real signature unknown 只读一行,遇到 or 为止 def seek(self, *args, **kwargs): # real signature unknown 把操作文件的光标移到指定位置 *注意seek的长度是按字节算的, 字符编码存每个字符所占的字节长度不一样。 如“路飞学城” 用gbk存是2个字节一个字,用utf - 8就是3个字节,因此以gbk打开时,seek(4)就把光标切换到了“飞”和“学”两个字中间。 但如果是utf8, seek(4)会导致,拿到了飞这个字的一部分字节,打印的话会报错,因为处理剩下的文本时发现用utf8处理不了了,因为编码对不上了,少了一个字节。 def seekable(self, *args, **kwargs): # real signature unknown 判断文件是否可进行seek操作 def tell(self, *args, **kwargs): # real signature unknown 返回当前文件操作关标位置 def truncate(self, *args, **kwargs): # real signature unknown 按指定长度截断文件 *指定长度的话,就从文件开头开始截断指定长度,不指定长度的话,就从当前位置到文件尾部的内容全去掉。 def writable(self, *args, **kwargs): # real signature unknown 判断文件是否可写
注意:
w 模式下不能读,可用readable()判断,返回结果为False
tell 和 seek 找的都是字节
read读的是字符
文件处理-文件修改:
尝试直接以 r+ 模式打开文件,默认会把新增的内容追加到文件最后面。但我想要的是修改中间的内容,怎么办?为什么会把内容添加到尾部呢?
我们已经学了seek,现在告诉你,之所以内容会追加到后面,是因为,文件一打开,要写的时候,光标会默认移到文件尾部,再开始写。现在我想修改中间的部分,是不是seek(中间位置)再写就可以了呢?
首先,我的文件内容是“路飞学城牛逼”,代码如下:
f = open(file="测试文件2.txt", mode="r+", encoding="gbk") f.seek(4) f.write("中国") f.close()
如代码按道理应该在“路飞”和“学城牛逼”中间插入“中国”,然而并不是,“中国”把路飞给覆盖掉了,文件内容变成后“路飞中国牛逼”,为啥呢?
这是由硬盘的存储机制导致的,你在创建文件的时候就已经决定了文件在硬盘上的位置,如果修改是插入数据,原来的数据顺移的话会导致其他的数据出现问题,所以修改数据并不是我们所想象的那样。
修改数据通常有两种方式:一种是将文件内容全部读取到内存中,在内存中对文件进行修改,然后再一次性的重新写回到文件,这种方式有个弊端就是假如文件特别大,达到了G级别,就会需要很多内存来支撑,同时假如断电的话,内存中的数据就会丢失,所以有了另一种方式,将文件内存逐行读取,读取的时候将需要修改的内容进行修改,然后写入到另一个文件里,这样就不会耗费大量的内存空间。
以下就分别举例说明两种方式:
文件内容:
床前明月光, 疑是地上霜。 举头望明月, 低头思故乡。
例子1:
f = open(file="测试文件2.txt", mode="r+", encoding="gbk") data = f.read() f.seek(0) f.write(data.replace("明月", "彩霞")) f.close()
运行结果:
床前彩霞光, 疑是地上霜。 举头望彩霞, 低头思故乡。
例子2:
import os f1_name = "测试文件2.txt" f2_name = "测试文件2.txt.new" f = open(file=f1_name, mode="r", encoding="gbk") f2 = open(file=f2_name, mode="w", encoding="utf-8") for line in f: if "明月" in line: line = line.replace("明月", "彩霞") f2.write(line) f.close() f2.close() os.remove(f1_name) os.rename(f2_name, f1_name)
运行结果:
床前彩霞光, 疑是地上霜。 举头望彩霞, 低头思故乡。
函数
函数基本介绍
为什么要学习函数?试想一下,现在老板要求写一个监控程序,全天24小时的监控公司的网站服务器系统情况,当cpu,memory,disk等指标达到某个阀值的时候就发邮件报警,这时候怎么办,费劲心思写下来类似于下面这样的代码:
while True: if cpu利用率 > 90 %: # 发送报警邮件 连接邮件服务器 发送邮件 关闭连接 if 磁盘使用率 > 90 %: # 发送报警邮件 连接邮件服务器 发送邮件 关闭连接 if 内存使用率 > 80 %: # 发送报警邮件 连接邮件服务器 发送邮件 关闭连接
以上程序一看就 low ,大量的重复代码,如果一旦某天邮件服务器连接信息要修改,就意味着所有的地方都要修改,多么庞大的工程啊。这时候就想啊,能不能把重复的部分提取出来,以后要改就该一处呢,那必须是可以的呀,函数就是来解决这个问题的。
提取后大概就如下:
def sendmail(内容): # 发送报警邮件 连接邮件服务器 发送邮件 关闭连接 while True: if cpu利用率 > 90 %: sendmail("cpu报警") if 磁盘使用率 > 90 %: sendmail("磁盘报警") if 内存使用率 > 80 %: sendmail("内存报警")
现在看起来是不是就清爽很多了,假如修改邮件服务器信息,只需要修改一处就可以了。
函数的定义:函数是指将一组语句的集合通过一个名字(函数名)封装起来,要想执行这个函数,只需调用其函数名即可。
特征:
减少重复代码
使程序变的可扩展
使程序变的易维护
def sayhi(): # 函数名 print("Heloo, I'm Alex!") sayhi() # 调用函数
可以带参数:
# 下面这段代码 a, b = 5, 8 c = a ** b print(c) # 改成用函数写 def calc(x, y): res = x ** y return res # 返回函数执行结果 c = calc(a, b) # 结果赋给变量c print(c)
函数的参数
形式参数(形参):
只有在被调用时才分配内存单元,在调用结束时,即刻释放所分配的内存单元。因此,形参只在函数内部有效。函数调用结束返回主调用函数后则不能再使用该形参变量。
实际参数(实参):
可以是常量、变量、表达式、函数等,无论实参是何种类型的量,在进行函数调用时,他们都必须有确定的值,以便把这些值传送给形参。因此应预先用赋值,输入等办法是参数获得确定值。
def calc(x, y): # x和y 是形参 res = x ** y return res c = calc(2, 3) # 2和3 是实参 print(c)
位置参数:
位置参数就是形式参数。
默认参数:
如下的例子:
def register(name, pwd, country, course):
print(name, pwd, country, course) register("Alex", "abc123", "CN", "ptyhon") register("Jack", "bbb123", "CN", "Linux") register("Lily", "aaa456", "CN", "Linux") register("Tim", "dddd456", "US", "Python,Linux")
输出:
Alex abc123 CN ptyhon Jack bbb123 CN Linux Lily aaa456 CN Linux Tim dddd456 US Python,Linux
我们可以看到,country参数对应的基本上都是“CN”,只有Tim是“US”,对于参数可能绝大部分都相同的情况,我们可以在函数定义的时候给他设定成一个默认的参数,这样在调用的时候就可以不用再填写此参数的值,如果确实有不同国籍的用户,也可以填写,最后就取填写的国籍。经过修改可以这样写:
def register(name, pwd, course, country="CN"): print(name, pwd, country, course) register("Alex", "abc123", "ptyhon") register("Jack", "bbb123", "Linux") register("Lily", "aaa456", "Linux") register("Tim", "dddd456", "Python,Linux", "US")
输出:
Alex abc123 CN ptyhon Jack bbb123 CN Linux Lily aaa456 CN Linux Tim dddd456 US Python,Linux
可以看到前3个用户就没有填写country参数的值了,因为有了默认的country参数值,最后一个不是CN,那么就填写了自己对应的值,最后取得就是自己填的值US.
注意:默认参数必须要放到位置参数的后面。
关键参数:
前面的位置参数在调用时都是要按照顺序进行传参的,后来增加了默认参数,减少在调用传参时工作量,但是必须要放到位置参数的后面。
接下来学习 关键参数 ,关键参数在定义时其实和默认参数一样,定义时都必须放到位置参数的后面,如果有2个以上的默认参数在函数里,在调用的时候,这两个默认参数的顺序就可以调换,如下例子:
def register(name, pwd, course, country="CN", sex="male"): print(name, pwd, country, course, sex) register("Tim", "dddd456", "Python,Linux", sex="female", country="US")
输出:
Tim dddd456 US Python,Linux female
可以看到,在定义阶段,sex是在country的后面,在调用的时候,sex是在country的前面的,没有问题。
注意:关键参数也是和默认参数一样,都必须要放到位置参数的后面。
非固定参数:
前面的位置参数,默认参数,关键参数 这些都是固定的参数,也就是说传入的每个值对应每个参数。
但有的时候若函数在定义时不确定用户想传入多少个参数,就可以使用非固定参数,
非固定参数之 *args
如下例子:
def register(name, age, *args): # *args 会把传入的参数变成一个元组形式 print(name, age, args) register("Alex", "22") # 输出: Alex 22 () # 最后的这个 () 就是args,由于没有传值,所以为空 register("Jack", 28, "CN", "Python") # 输出:Jack 28 ('CN', 'Python') # 首先进行位置参数匹配正常输出Jack和28,然后把多余的参数都交给*args,*args会将传入的参数变成一个元组 ('CN', 'Python')
另一个例子,模拟给用户发报警:
def send_alert(msg, *users): for u in users: print("发送报警给:", u) send_alert("有报警啦", "alex", "jack") send_alert("有报警啦", *["alex", "jack", "rose"]) # 也可以写成这样
输出:
发送报警给: alex 发送报警给: jack 发送报警给: rose 发送报警给: alex 发送报警给: jack 发送报警给: rose
非固定参数之 **args
如下例子:
def register(name, age, *args, **kwargs): # **args 会把传入的参数变成一个dict字典形式 print(name, age, args, kwargs) register("Alex", "22") # Alex 22 () {} # 最后的这个 {} 就是kwargs,由于没有传值,所以为空字典 register("Jack", 28, "CN", "Python", sex="male", province="Sichaun") # 输出:Jack 28 ('CN', 'Python') {'sex': 'male', 'province': 'Sichaun'} # 首先进行位置参数匹配正常输出Jack和28,然后把多余的参数都交给*args, # *args会将传入的参数变成一个元组 ('CN', 'Python') # **kwargs会将传入的多个关键参数变成一个字典 {'sex': 'male', 'province': 'Sichaun'}
函数-返回值
函数外部的代码想要获取函数的执行结果,就可以在函数里用return语句把结果返回。
比如下面这个简单的登录程序:
def login(user, pwd): if user == "alex" and pwd == "abc123": return True else: return False res = login("alex", "abc123") if res: print("登录成功") else: print("登录失败")
函数-局部变量:
全局变量:在程序的一开始定义的变量称为全局变量,全部变量作用域是整个程序,全局能使用。
局部变量:在函数中定义的变量称为局部变量,局部变量作用域是定义该变量的函数,值在局部生效,函数一旦执行完毕,函数内的变量即失效。
在函数内部,可以引用全局变量,但是函数内不能更改全局变量的值。
如果全局和局部都有相同的变量名字,函数会先在函数内部找,如果内部没有则去函数外部找。
全局不能调用局部的变量。
看个例子:
name = "Alex Chen" # 全局变量 def change_name(): name = "Jack Ma" # 局部变量 print(name) # 输出:Jack Ma,局部有变量就找局部的 change_name() print(name) # 输出:Alex Chen,函数内不能修改全局的变量,函数外不能去局部里找,所以还是 Alex Chen
那如果我一定要在函数内修改全局变量的值怎么做呢?用 global
name = "Alex Chen" def change_name(): global name # global 后面跟要拿到内部的变量名 name = "Jack Ma" print("修改后在函数里面:", name) # 输出:Jack Ma change_name() print("修改后在函数外面:", name) # 输出:Jack Ma ,因为global把全局变量拿到函数内部修改了
局部变量不能声明在 global 之前,会报错。
实际开发中,一般情况下不建议用global,因为可能该全局变量还在其他地方有调用。具体以业务情况为准。
在函数里修改列表数据:
和之前的局部变量一样,也是改不了在全局的列表值的。
names = ["alex", "jack", "Tim"] def change_name(): names = [11, 22, 33] print(names) # 输出:[11, 22, 33] change_name() print(names) # 输出:["alex", "jack", "Tim"]
但是在函数里可以修改列表里面元素的值:
names = ["alex", "jack", "Tim"] def change_name(): names[0] = 11 names[2] = 33 print(names) # 输出:[11, 'jack', 33] change_name() print(names) # 输出:[11, 'jack', 33]
如果一定要改函数外列表的值也可以使用 global
names = ["alex", "jack", "Tim"] def change_name(): global names names = [77, 88, 99, 100] print(names) # 输出:[77, 88, 99, 100] change_name() print(names) # 输出:[77, 88, 99, 100]
函数-嵌套函数
嵌套函数就是函数里再包含一个或多个函数。
函数外部是不能够调用到内部嵌套的函数的,直接调用会报错。可以通过其他的方式,后面的知识后面讲。
name = "Alex" def change_name(): name = "Alex2" def change_name2(): name = "ALex3" print("第3层打印", name) change_name2() print("第2层打印", name) change_name() print("第1层打印", name)
输出:
第3层打印 ALex3 第2层打印 Alex2 第1层打印 Alex
函数-作用域
在Python中函数就是一个作用域(和JavaScript类似),局部变量放置在作用域中
在C#,Java中作用域是 { } 大括号括起来的
代码定义完成后,作用域已经生成,作用域链向上查找。怎么理解?简单来讲就是 比如多个函数嵌套中,最里层的函数要打印一个 name变量的值,假如最里层函数没有name变量就到函数的上一级去找,还找不到就去再上层,知道找到为止,全部都找完了没有的话就报错了。
name = "Alex"
def change_name():
name = "Alex2"
def change_name2():
print("第3层打印", name) # Alex2,第三层没有name变量,所以去上层找到了name = “Alex2”
change_name2()
print("第2层打印", name) # Alex2
change_name()
print("第1层打印", name) # Alex
函数-匿名函数
匿名函数就是不需要显式的指定函数名。
下面这段普通函数的代码:
def calc(x, y): return x ** y print(calc(2, 5))
写成匿名函数:
lambda x, y: x ** y
# 但是你需要使用它呀,怎么调用呢,可以写成这样:
calc = lamda x, y: x ** y print(calc(2, 5))
输出结果都是32
匿名函数 + 三元运算:
# 普通写法
def calc(x, y):
if x < y:
return x ** y
else:
return x / y
# 写成匿名函数:
func = lambda x, y: x ** y if x < y else x / y
# 调用
print(calc(16, 8)) # 结果:2.0
print(func(16, 8)) # 结果:2.0
匿名函数还可以和其他函数搭配使用:
res = map(lambda x: x ** 2, [1, 5, 7, 4, 8]) # 传入一个列表,对列表里每个元素求平方 for i in res: print(i)
输出:
1 25 49 16 64
另一个例子:
把列表里的值进行自乘:
''' 需求:把列表里的元素进行自乘 ''' data = list(range(10)) print(data) # 输出:[0, 1, 2, 3, 4, 5, 6, 7, 8, 9]
# 普通写法 def f2(n): return n * n print(list(map(f2, data))) # 输出:[0, 1, 4, 9, 16, 25, 36, 49, 64, 81]
# 匿名函数写法: print(list(map(lambda n: n * n, data))) # 输出:[0, 1, 4, 9, 16, 25, 36, 49, 64, 81]
匿名函数作用:
1. 节省代码量
2. 看着高级
函数-高阶函数
变量可以指向函数,函数的参数能接收变量,那么一个函数就可以接收另一个函数作为参数,这种函数就称之为高阶函数。
只需满足一下任意一个条件,即时高阶函数:
1. 接收一个或多个函数作为输入
2. return 返回另外一个函数
def func(x, y): # 定义func函数,返回传入参数的和 return x + y def calc(x): # 定义calc函数,返回传入参数 return x f = calc(func) # 将func函数作为参数传给calc函数,而calc函数是直接return这个传入的参数的,得到的值赋给f,这里的f实际上得到的是func函数的内存地址 print(f) # 打印一下看看得到:<function func at 0x000002E7DB952E18> print(f(5, 9)) # 将 5 和 9 传给f,就相当于将5和9传给func函数求和,得到结果为14
函数-递归
参考大王的博客:http://www.cnblogs.com/alex3714/articles/8955091.html
递归介绍:
递归,就是函数的运行的过程中调用自己。
代码示例:
def recursion(n): print(n) recursion(n + 1) # 函数内部再来自己调自己,然后+1 recursion(1)
运行结果:
993
994
995
996
997
998Traceback (most recent call last):
File "D:/PycharmProjects/python_fullstack_middle/第二模块:函数编程/第1章·函数、装饰器、迭代器、内置方法/函数/递归2.py", line 6, in <module>
recursion(1)
File "D:/PycharmProjects/python_fullstack_middle/第二模块:函数编程/第1章·函数、装饰器、迭代器、内置方法/函数/递归2.py", line 3, in recursion
recursion(n + 1)
File "D:/PycharmProjects/python_fullstack_middle/第二模块:函数编程/第1章·函数、装饰器、迭代器、内置方法/函数/递归2.py", line 3, in recursion
recursion(n + 1)
File "D:/PycharmProjects/python_fullstack_middle/第二模块:函数编程/第1章·函数、装饰器、迭代器、内置方法/函数/递归2.py", line 3, in recursion
recursion(n + 1)
[Previous line repeated 993 more times]
File "D:/PycharmProjects/python_fullstack_middle/第二模块:函数编程/第1章·函数、装饰器、迭代器、内置方法/函数/递归2.py", line 2, in recursion
print(n)
RecursionError: maximum recursion depth exceeded while calling a Python object
可以看到运行到998就出错了,报错信息说超过了最大递归深度限制,什么意思呢?
首先我们来看看python默认的最大递归深度:
import sys # 引入sys模块 print(sys.getrecursionlimit()) # 为 1000 sys.setrecursionlimit(1500) # 修改最大递归深度调整为1500 print(sys.getrecursionlimit()) # 得到修改后的最大递归深度为 1500
为什么要限制递归深度呢?
通俗的来讲,就是因为函数每执行一次,函数内部就又在调用,而上一次函数是没有正在的执行完成的,他必须等到里面的函数执行完成,而里面的函数又在不断的调用自己,就是一个死循环永远不会退出的。由于在执行中是要消耗内存的,函数一直不结束就会造成内存得不到释放,不断的积压,最后造成内存占用无限增大,导致内存溢出,所以必须要做限制。
从本质上讲,就是在计算机中,函数调用时通过栈(stack)这种数据结构实现的,每当进入一个函数调用,栈就会加一层栈帧,每当函数返回,栈就会减一层栈帧。由于栈的大小不是无限的,所以,递归调用的次数过多,会导致栈溢出。(尾递归除外,继续往后学习)
函数调用的栈结构:
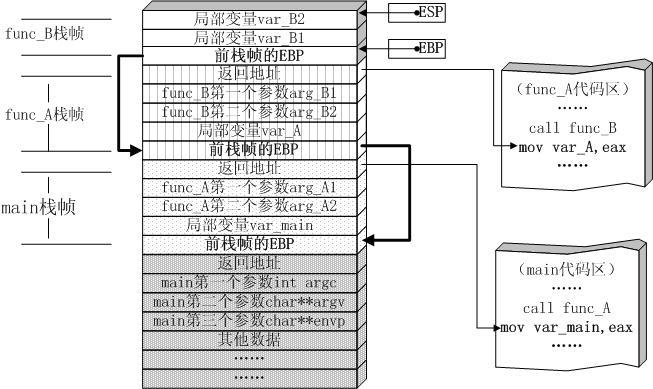
递归的特点:
来看例子,下面使用递归写的,让10不断除以2,知道0为止。
def calc(n): print(n) if int(n / 2) > 0: calc(int(n / 2)) else: print("------") print(n) calc(10)
输出结果为:
5 2 1 ------ 1 2 5 10
为什么会打印出上面这样的结果呢?
第一层,首先将10传入函数,第一次打印10没毛病,然后判断10/2的值取整是否大于0,结果是5是大于0的,所以进入下一步第二层继续调用函数,传入的值为10/2的结果取整也就是5,
第二层,5传入后首先还是进行打印 打印出5 ,没毛病,继续判断5/2的值并取整是2,是大于0 的,继续下一步进入第三层,调用函数传入的值为5/2的值取整也就是2,
第三层,2传入后首先还是进行打印 打印出2,没毛病,继续判断2/2的值并取整是1,是大于0的,继续下一步进入第四层,调用函数传入的值为2/2的值取整也就是1,
第四层,1传入后首先还是进行打印 打印出1,没毛病,继续判断1/2的值并取整是0,这时候小于0了,就不继续调用函数了,于是打印“-----” ,那么第四层就结束了,结束过后还要打印一下当前的值也就是1,然后回到第三层
回到第三层,由于之前还在等待第四层的结束,现在第四层结束了,第三层继续运行剩下的代码,打印第三层的时候的当前值,也就是2,然后回到第二层,
回到第二层,由于之前还在等待第三层的结束,现在第三层技术了,第二层继续运行剩下的代码,打印第二层的时候的当前值,也就是5,然后回到第一层,
回到第一层,由于之前还在等待第二层的结束,现在第二层技术了,第一层继续运行剩下的代码,打印第一层的时候的当前值,也就是10,然后整个程序运行结束。
至此,程序运行结束,最后打印出了上面的结果。
相当于下图,递归就是一层层的进去,还要一层层的出来:
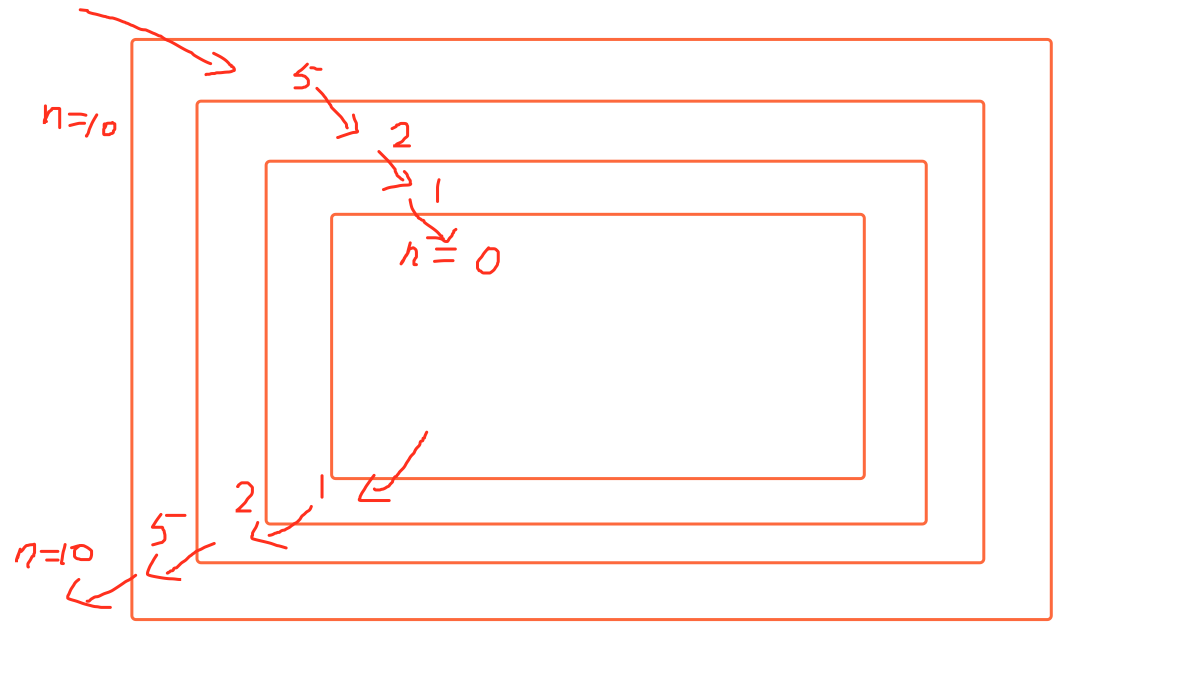
通过上面的例子,我们可以总结出递归的几个特点:
1. 必须有一个明确的结束条件,要不就会变成死循环了,最终撑爆系统
2. 每次进入更深一层递归时,问题规模相比上次递归都应有所减少
3. 递归执行效率不高,递归层次过多会导致栈溢出
堆栈扫盲:http://www.cnblogs.com/lln7777/archive/2012/03/14/2396164.html
递归有什么作用呢?
递归可以用于解决很多算法问题,把复杂的问题分成一个个小问题,一一解决。
比如求斐波那契数列、汉诺塔、多级评论树、二分查找、求阶乘等。用递归求斐波那契数列、汉诺塔 对初学者来讲可能理解起来不太容易,所以我们用阶乘和二分查找来给大家演示一下。
求阶乘:
任何大于1的自然数n阶乘表示方法:
n!=1x2x3x......xn
或
n!=nx(n-1)!
举例:4! = 4x3x2x1 = 24
递归实现:
def factorial(n): if n == 1: # 当n为1的时候表示到最深处了,然后返回会1与上一次的2相乘 return 1 return n * (factorial(n - 1)) print(factorial(4)) # 结果为:24
二分查找:
自己写的例子:
def guess(n, li): mid = int(len(li) / 2) # 获取到列表一般的长度 if n > li[mid]: li = li[mid:len(li)] # 如果找的值比中间值大,就从中间值往最后截取 print(li) # 打印一下当前列表的内容 return guess(n, li) # 继续调用函数查找 elif n < li[mid]: li = li[0:mid] # 如果找的值比中间值小,就从开始往中间值截取 print(li) # 打印一下当前列表的内容 return guess(n, li) # 继续调用函数查找 else: print("ok", li[mid]) # 找到 guess(19, li)
输出:
[0, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15, 16, 17, 18, 19, 20, 21, 22, 23, 24, 25, 26, 27, 28, 29, 30, 31, 32, 33, 34, 35, 36, 37, 38, 39, 40, 41, 42, 43, 44, 45, 46, 47, 48, 49] [0, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15, 16, 17, 18, 19, 20, 21, 22, 23, 24] [12, 13, 14, 15, 16, 17, 18, 19, 20, 21, 22, 23, 24] [18, 19, 20, 21, 22, 23, 24] [18, 19, 20] ok 19
可以看到每一次的查找返回都比原来少了一半。
大王的例子:
data_set = list(range(101)) def b_search(n, low, high, d): mid = int((low + high) / 2) # 找到列表中间的值 if low == high: print("not find") return if d[mid] > n: # 列表中间值>n, 代数要找的数据在左边 print("go left:", low, high, d[mid]) b_search(n, low, mid, d) # 去左边找 elif d[mid] < n: # 代数要找的数据在左边 print("go right:", low, high, d[mid]) b_search(n, mid + 1, high, d) # 去右边找 else: print("find it ", d[mid]) b_search(48, 0, len(data_set), data_set)
输出:
go left: 0 101 50 go right: 0 50 25 go right: 26 50 38 go right: 39 50 44 go right: 45 50 47 go left: 48 50 49 find it 48
补充:
在将特性时,我们说递归效率不高,因为没递归一次就多了一层栈,递归次数太多还会导致栈溢出,这也是为什么python会默认限制递归次数的原因。但有一种方式可以实现递归过程中不产生多层栈的,即尾递归。
尾递归:
用的场景不多。
如果一个函数中所有递归形式的调用都出现在函数的末尾,我们称这个递归函数是尾递归的。当递归调用时整个函数体重最后执行的语句且它的返回值不属于表达式的一部分时,这个递归调用就是尾递归。尾递归函数的特点是在回归过程中不用做任何操作,这个特性很重要,因为大多数现在的编译器会利用这种特点自动生成优化的代码。
当编译器检测到一个函数调用时尾递归的时候,他就覆盖当前的活动记录而不是在栈中去创建一个新的。编译器可以做到这点吗,因为递归调用是当前活跃期内最后一条待执行的语句,于是当这个调用返回时栈帧中并没有其他事情可做,因此也就没有保存栈帧的必要了。通过覆盖当前的栈帧而不是在其之上重新添加一个,这样所使用的栈空间就大大缩减了,这使得实际的运行效率会变得更高。
尾递归例子:
def calc(n): print(n - 1) if n > -50: return calc(n-1)
我们 之前求的阶乘是尾递归吗?
答案:不是
def factorial(n): if n == 0: #是0的时候,就运算完了 return 1 return n * factorial(n-1) # 每次递归相乘,n值都较之前小1 d = factorial(4) print(d)
上面这种递归计算最终的return操作时乘法操作,所以不是尾递归。因为每个活跃期的返回值都依赖于用n乘以下一个活跃期的返回值,因此每次调用产生的栈帧将不得不保存在栈上直到下一个调用的返回值确定。
说明:Python里写了尾递归也没有用。
函数-内置方法
Python的len为什么你可以直接使用?这是因为解释器启动时就定义好了。
Python的内置方法有以下:

官方说明文档,请查看:https://docs.python.org/3/library/functions.html
下面对一些方法进行讲解:
abs()
返回一个数字的绝对值。参数可以是整数或浮点数。
>>> abs(-10)
10
all()
如果可迭代对象所有的元素都是True返回True,否则返回False,如果为空,返回True
>>> all([1,2,3,4]) True >>> all([]) True >>> all([0]) False
any()
如果可迭代对象有一个元素为True就返回True,否则返回False,如果为空返回False
>>> any([1,2,3,4]) True >>> any([]) False >>> any([0,1,2,3,4]) True >>>
ascii()
bin()
转为2进制。
bool()
判断是True还是False
>>> bool(1) True >>> bool(-1) True >>> bool(False) False
>>> bool([])
False
bytearray()
我们知道字符串是不能修改的,重新赋值实际上是开辟了一块新的内存空间,如果字符串假如有500M,只要改其中一个文字,那么重新赋值一下子就占内存2倍了,肯定不行,通过bytearray()对原内存地址进行修改,不是开辟新空间就不占内存,很少用。
bytes()
byte类型。
callable()
查看对象是否可调用。
>>> a=[1,2,3,4] >>> callable(a) False >>> >>> def func(): ... pass ... >>> callable(f) False >>> callable(func) True >>>
chr()
根据编号返回ASCII码表中的对应字符。相反的见ord()
>>> chr(97) 'a'
classmethod()
面向对象讲。
compile()
编译代码,现在用不上。
complex()
把一个数变成复数。
>>> complex(3,5)
(3+5j)
delattr()
面向对象讲。
dict()
把一个数据转为字典
dir()
打印当前程序的所有变量。 vars()可打印变量名和对应的值。
>>> abc="hahahaha" >>> >>> dir() ['__annotations__', '__builtins__', '__doc__', '__loader__', '__name__', '__package__', '__spec__', 'a', 'abc']
divmod()
divmod(x, y, /) Return the tuple (x//y, x%y).
传入两个数,返回一个数组包含两个数的整除的值和余数。
>>> divmod(10,3)
(3, 1)
enumerate()
li = ["aa", "bb", "cc", "dd"] for i in enumerate(li): print(i)
输出:
(0, 'aa') (1, 'bb') (2, 'cc') (3, 'dd')
eval()
直接将字符串转为代码执行。只能处理单行代码,处理多行见exec()。
>>> f="1+3/2" >>> f '1+3/2' >>> eval(f) 2.5 >>> s="print('Hello...')" >>> eval(s) Hello...
exec()
和eval()一样,但是可以处理多行代码。eval()可以拿到返回值,exec()拿不到返回值。
>>> res1=eval("1+2+3") >>> print(res1) 6 >>> res2=exec("1+2+3") >>> print(res2) None # exec拿不到返回值
code = ''' def foo(): print("run foo") return 1234 foo() ''' res = exec(code) print("res:", res)
输出:
run foo res: None # 拿不到返回的1234
filter()
过滤。(map, filter, reduce三剑客)
>>> list(filter(lambda x:x>3, [1,2,3,4,5])) [4, 5]
float()
浮点类型。
format()
字符串格式化。
frozenset()
不可变的集合。
>>> s = {1,2,5,34}
>>> s = frozenset(s) # 此时s的一些修改的方法将不可调用。
>>>
getattr()
面向对象讲。
globals()
打印全局变量,无论在函数内或函数外。
hasattr()
面向对象讲。
hash()
将一串字符变为一串数字的哈希值。
>>> hash("abcde") 6849925132025635063
help()
查看帮助。
hex()
将一个数字转为16进制。
>>> hex(34) '0x22'
id()
查看内存地址
input()
接收用户输入。
int()
转为整数。
isinstance()
面向对象讲。
issubclass()
面向对象讲。
iter()
迭代器讲。
len()
查看长度。
list()
列表。
locals()
打印函数的局部变量。
abc = "aaaaa" def f(): qqqqqq = "adsfdsf" print(locals()) f()
输出:
{'qqqqqq': 'adsfdsf'}
map()
(map, filter, reduce三剑客)
>>> list(map(lambda x:x*x, [1,2,3,4,5])) # 自乘 [1, 4, 9, 16, 25]
reduce() (map, filter, reduce三剑客)
python3不在内置函数中,python2在内置函数中。
>>> import functools >>> functools.reduce(lambda x,y:x*y,[1,34,2,56,256,2,3]) # 累乘 5849088 >>> functools.reduce(lambda x,y:x*y,[1,34,2,56,256,2,3],3) # 从第3个开始乘 17547264 >>>
max()
取最大值。
>>> a=[1,4,2,3,-256,10,45] >>> max(a) 45
memoryview()
用于有大量数据时使用,现在用不到。
min()
取最小值。
>>> a=[1,4,2,3,-256,10,45] >>> min(a) -256
next()
之后讲。
object()
oct()
将一个整数转为8进制。
open()
打开文件。
ord()
通过字符返回字符在ASCII码表中的位置。相反的见chr()
>>> ord("a") 97
pow()
返回多少次幂。
>>> pow(2,3) 8 >>> pow(2,4) 16
print()
print(value, ..., sep=' ', end=' ', file=sys.stdout, flush=False)
mes = "又回到最初的起点" f = open("print_to_file.txt", "w", encoding="UTF-8") print(mes, "记忆中你青涩的脸", sep=">>>", end="", file=f) print(mes, "记忆中你青涩的脸", sep=">>>", end="", file=f)
生成的文件内容:
又回到最初的起点>>>记忆中你青涩的脸又回到最初的起点>>>记忆中你青涩的脸
property()
面向对象讲。
range()
创建一个整数列表。
repr()
>>> s frozenset({1, 2, 34, 5}) >>> >>> repr(s) 'frozenset({1, 2, 34, 5})' # 变成了字符串
reversed()
和sorted()一样的,只不过默认反转。
round()
保留指定位数的小数,默认1位。
>>> round(1.234345456546345) 1 >>> round(1.234345456546345,3) 1.234
set()
变成集合。
setattr()
在面向对象讲。
slice()
切片。没什么卵用。
>>> l = list(range(10)) >>> l [0, 1, 2, 3, 4, 5, 6, 7, 8, 9]
>>> l[1:7:2] # 传统切片方式 [1, 3, 5]
>>> s = slice(1,7,2) >>> l[s] # slice方式 [1, 3, 5]
sorted()
sorted(iterable, /, *, key=None, reverse=False)
>>> l [0, 1, 2, 3, 4, 5, 6, 7, 8, 9, 12, 122, 54] >>> sorted(l) [0, 1, 2, 3, 4, 5, 6, 7, 8, 9, 12, 54, 122] >>> >>> d = {} >>> for i in range(10): ... d[i]=i-50 ... >>> d {0: -50, 1: -49, 2: -48, 3: -47, 4: -46, 5: -45, 6: -44, 7: -43, 8: -42, 9: -41} >>> >>> sorted(d.items()) # 实际上已经排序了,只不过数据太少看不出来。 [(0, -50), (1, -49), (2, -48), (3, -47), (4, -46), (5, -45), (6, -44), (7, -43), (8, -42), (9, -41)] >>> >>> sorted(d.items(),key=lambda x:x[1]) # 实际上已经排序了,只不过数据太少看不出来。 key=lambda x:x[1]表示将d.items()的每个值给x,x得到的就是一个个的小元组,x[1]就是取元组的第2位,就是以value来排序 [(0, -50), (1, -49), (2, -48), (3, -47), (4, -46), (5, -45), (6, -44), (7, -43), (8, -42), (9, -41)] >>> >>> d[0]=666 # 改一个值 >>> sorted(d.items(),key=lambda x:x[1]) # 再来排一次 [(1, -49), (2, -48), (3, -47), (4, -46), (5, -45), (6, -44), (7, -43), (8, -42), (9, -41), (0, 666)] # 按照升序排的 >>> >>> sorted(d.items(),key=lambda x:x[1],reverse=True) # 反转排倒序 [(0, 666), (9, -41), (8, -42), (7, -43), (6, -44), (5, -45), (4, -46), (3, -47), (2, -48), (1, -49)] >>>
staticmethod()
str()
转为字符串。
sum()
求和。
>>> a = [1,4,2,7,-20,3,9] >>> sum(a) 6
super()
类里面讲。
tuple()
变成元组。
type()
查看数据类型。
vars()
打印当前所有的变量。
vars()会打印变量名和变量对应的值,dir()只会打印变量名。
zip()
>>> a = [1,2,3,4,5] >>> b=["a","b","c"] >>> >>> list(zip(a,b)) [(1, 'a'), (2, 'b'), (3, 'c')]
__import__()
模块的时候讲。
函数练习题:
我的版本:
""" 在一个文件里存多个人的个人信息, username password age position department alex abc123 24 Engineer IT rain df2@432 25 Teacher Teching .... 1.输入用户名密码,正确后登录系统 ,打印 1. 修改个人信息 2. 打印个人信息 3. 修改密码 2.每个选项写一个方法 3.登录时输错3次退出程序 """ account_file = "account.txt" account_dict = {} def get_info_from_file(): f = open(file="account.txt", mode="r+", encoding="utf-8") for line in f: line = line.strip().split(",") account_dict[line[0]] = line f.close() def write_info_back_to_file(): f = open(file="account.txt", mode="w+", encoding="utf-8") for key in account_dict: line = (",".join(account_dict[key])) f.write(line + " ") f.close() def login(username, password): if username in account_dict and password == account_dict[username][1]: print("登录成功.") return True else: print("用户名或密码错误") return False def print_info(username): print("你的信息如下:".center(50, "-"), end="") print(""" 姓名: %s 年龄: %s 职位: %s 部门: %s """ % (account_dict[username][0], account_dict[username][2], account_dict[username][3], account_dict[username][4])) print("".center(50, "-")) def update_info(username): account_list = account_dict[username] print(account_list) print(""" 2. 年龄: %s 3. 职位: %s 4. 部门: %s """ % (account_dict[username][2], account_dict[username][3], account_dict[username][4])) choose_num = input("请选择编号进入修改:").strip() if choose_num.isdigit(): choose_num = int(choose_num) if choose_num == 2: new_age = input("请输入新年龄:") account_dict[username][choose_num] = new_age elif choose_num == 3: new_position = input("请输入新职位:") account_dict[username][choose_num] = new_position elif choose_num == 4: new_dep = input("请输入新部门名称:") account_dict[username][choose_num] = new_dep else: print("无此编号") else: print("输入错误") def change_password(username): print("当前密码:", account_dict[username][1]) new_pwd = input("输入新密码:") account_dict[username][1] = new_pwd print("修改成功") return True get_info_from_file() run_flag = True run_flag2 = True count = 0 while run_flag: username = input("pelase input your username: ") password = input("please input your password: ") if login(username, password): while run_flag2: print(""" 1. 打印个人信息 2. 修改个人信息 3. 修改密码 4. 保存退出 5. 直接退出 """) choose = input("请选择编号进行操作:").strip() if choose.isdigit(): choose = int(choose) if choose == 1: print_info(username) elif choose == 2: update_info(username) elif choose == 3: change_password(username) elif choose == 4: write_info_back_to_file() run_flag = False run_flag2 = False elif choose == 5: run_flag = False run_flag2 = False else: print("输入错误") else: count += 1 if count == 3: print("错误超过3次,程序退出") run_flag = False
book上的大王版本:
def print_personal_info(account_dic,username): """ print user info :param account_dic: all account's data :param username: username :return: None """ person_data = account_dic[username] info = ''' ------------------ Name: %s Age : %s Job : %s Dept: %s Phone: %s ------------------ ''' %(person_data[1], person_data[2], person_data[3], person_data[4], person_data[5], ) print(info) def save_back_to_file(account_dic): """ 把account dic 转成字符串格式 ,写回文件 :param account_dic: :return: """ f.seek(0) #回到文件头 f.truncate() #清空原文件 for k in account_dic: row = ",".join(account_dic[k]) f.write("%s "%row) f.flush() def change_personal_info(account_dic,username): """ change user info ,思路如下 1. 把这个人的每个信息打印出来, 让其选择改哪个字段,用户选择了的数字,正好是字段的索引,这样直接 把字段找出来改掉就可以了 2. 改完后,还要把这个新数据重新写回到account.txt,由于改完后的新数据 是dict类型,还需把dict转成字符串后,再写回硬盘 :param account_dic: all account's data :param username: username :return: None """ person_data = account_dic[username] print("person data:",person_data) column_names = ['Username','Password','Name','Age','Job','Dept','Phone'] for index,k in enumerate(person_data): if index >1: #0 is username and 1 is password print("%s. %s: %s" %( index, column_names[index],k) ) choice = input("[select column id to change]:").strip() if choice.isdigit(): choice = int(choice) if choice > 0 and choice < len(person_data): #index不能超出列表长度边界 column_data = person_data[choice] #拿到要修改的数据 print("current value>:",column_data) new_val = input("new value>:").strip() if new_val:#不为空 person_data[choice] = new_val print(person_data) save_back_to_file(account_dic) #改完写回文件 else: print("不能为空。。。") account_file = "account.txt" f = open(account_file,"r+") raw_data = f.readlines() accounts = {} #把账户数据从文件里读书来,变成dict,这样后面就好查询了 for line in raw_data: line = line.strip() if not line.startswith("#"): items = line.split(",") accounts[items[0]] = items menu = ''' 1. 打印个人信息 2. 修改个人信息 3. 修改密码 ''' count = 0 while count <3: username = input("Username:").strip() password = input("Password:").strip() if username in accounts: if password == accounts[username][1]: # print("welcome %s ".center(50,'-') % username ) while True: #使用户可以一直停留在这一层 print(menu) user_choice = input(">>>").strip() if user_choice.isdigit(): user_choice = int(user_choice) if user_choice == 1: print_personal_info(accounts,username) elif user_choice == 2: change_personal_info(accounts,username) elif user_choice == 'q': exit("bye.") else: print("Wrong username or password!") else: print("Username does not exist.") count += 1 else: print("Too many attempts.")