数据结构与算法(Python)
Why?
我们举一个可能不太恰当的例子:
如果将最终写好运行的程序比作战场,我们码农便是指挥作战的将军,而我们所写的代码便是士兵和武器。
那么数据结构和算法是什么?答曰:兵法!
我们可以不看兵法在战场上肉搏,如此,可能会胜利,可能会失败。即使胜利,可能也会付出巨大的代价。我们写程序亦然:没有看过数据结构和算法,有时面对问题可能会没有任何思路,不知如何下手去解决;大部分时间可能解决了问题,可是对程序运行的效率和开销没有意识,性能低下;有时会借助别人开发的利器暂时解决了问题,可是遇到性能瓶颈的时候,又不知该如何进行针对性的优化。
如果我们常看兵法,便可做到胸有成竹,有时会事半功倍!同样,如果我们常看数据结构与算法,我们写程序时也能游刃有余、明察秋毫,遇到问题时亦能入木三分、迎刃而解。
故,数据结构和算法是一名程序开发人员的必备基本功,不是一朝一夕就能练成绝世高手的。冰冻三尺非一日之寒,需要我们平时不断的主动去学习积累。
通过三天的学习,我们希望让大家能理解其概念,掌握常用的数据结构和算法。
引入
先来看一道题:
如果 a+b+c=1000,且 a^2+b^2=c^2(a,b,c 为自然数),如何求出所有a、b、c可能的组合?
第一次尝试
import time start_time = time.time() # 注意是三重循环 for a in range(0, 1001): for b in range(0, 1001): for c in range(0, 1001): if a**2 + b**2 == c**2 and a+b+c == 1000: print("a, b, c: %d, %d, %d" % (a, b, c)) end_time = time.time() print("elapsed: %f" % (end_time - start_time)) print("complete!")
运行结果:
a, b, c: 0, 500, 500 a, b, c: 200, 375, 425 a, b, c: 375, 200, 425 a, b, c: 500, 0, 500 elapsed: 214.583347 complete!
注意运行的时间:214.583347秒
算法的提出
算法的概念
算法是计算机处理信息的本质,因为计算机程序本质上是一个算法来告诉计算机确切的步骤来执行一个指定的任务。一般地,当算法在处理信息时,会从输入设备或数据的存储地址读取数据,把结果写入输出设备或某个存储地址供以后再调用。
算法是独立存在的一种解决问题的方法和思想。
对于算法而言,实现的语言并不重要,重要的是思想。
算法可以有不同的语言描述实现版本(如C描述、C++描述、Python描述等),我们现在是在用Python语言进行描述实现。
算法的五大特性
- 输入: 算法具有0个或多个输入
- 输出: 算法至少有1个或多个输出
- 有穷性: 算法在有限的步骤之后会自动结束而不会无限循环,并且每一个步骤可以在可接受的时间内完成
- 确定性:算法中的每一步都有确定的含义,不会出现二义性
- 可行性:算法的每一步都是可行的,也就是说每一步都能够执行有限的次数完成
第二次尝试
import time start_time = time.time() # 注意是两重循环 for a in range(0, 1001): for b in range(0, 1001-a): c = 1000 - a - b if a**2 + b**2 == c**2: print("a, b, c: %d, %d, %d" % (a, b, c)) end_time = time.time() print("elapsed: %f" % (end_time - start_time)) print("complete!")
运行结果:
a, b, c: 0, 500, 500 a, b, c: 200, 375, 425 a, b, c: 375, 200, 425 a, b, c: 500, 0, 500 elapsed: 0.182897 complete!
注意运行的时间:0.182897秒
算法效率衡量
执行时间反应算法效率
对于同一问题,我们给出了两种解决算法,在两种算法的实现中,我们对程序执行的时间进行了测算,发现两段程序执行的时间相差悬殊(214.583347秒相比于0.182897秒),由此我们可以得出结论:实现算法程序的执行时间可以反应出算法的效率,即算法的优劣。
单靠时间值绝对可信吗?
假设我们将第二次尝试的算法程序运行在一台配置古老性能低下的计算机中,情况会如何?很可能运行的时间并不会比在我们的电脑中运行算法一的214.583347秒快多少。
单纯依靠运行的时间来比较算法的优劣并不一定是客观准确的!
程序的运行离不开计算机环境(包括硬件和操作系统),这些客观原因会影响程序运行的速度并反应在程序的执行时间上。那么如何才能客观的评判一个算法的优劣呢?
时间复杂度与“大O记法”
我们假定计算机执行算法每一个基本操作的时间是固定的一个时间单位,那么有多少个基本操作就代表会花费多少时间单位。算然对于不同的机器环境而言,确切的单位时间是不同的,但是对于算法进行多少个基本操作(即花费多少时间单位)在规模数量级上却是相同的,由此可以忽略机器环境的影响而客观的反应算法的时间效率。
对于算法的时间效率,我们可以用“大O记法”来表示。
“大O记法”:对于单调的整数函数f,如果存在一个整数函数g和实常数c>0,使得对于充分大的n总有f(n)<=c*g(n),就说函数g是f的一个渐近函数(忽略常数),记为f(n)=O(g(n))。也就是说,在趋向无穷的极限意义下,函数f的增长速度受到函数g的约束,亦即函数f与函数g的特征相似。
时间复杂度:假设存在函数g,使得算法A处理规模为n的问题示例所用时间为T(n)=O(g(n)),则称O(g(n))为算法A的渐近时间复杂度,简称时间复杂度,记为T(n)
如何理解“大O记法”
对于算法进行特别具体的细致分析虽然很好,但在实践中的实际价值有限。对于算法的时间性质和空间性质,最重要的是其数量级和趋势,这些是分析算法效率的主要部分。而计量算法基本操作数量的规模函数中那些常量因子可以忽略不计。例如,可以认为3n2和100n2属于同一个量级,如果两个算法处理同样规模实例的代价分别为这两个函数,就认为它们的效率“差不多”,都为n2级。
最坏时间复杂度
分析算法时,存在几种可能的考虑:
- 算法完成工作最少需要多少基本操作,即最优时间复杂度
- 算法完成工作最多需要多少基本操作,即最坏时间复杂度
- 算法完成工作平均需要多少基本操作,即平均时间复杂度
对于最优时间复杂度,其价值不大,因为它没有提供什么有用信息,其反映的只是最乐观最理想的情况,没有参考价值。
对于最坏时间复杂度,提供了一种保证,表明算法在此种程度的基本操作中一定能完成工作。
对于平均时间复杂度,是对算法的一个全面评价,因此它完整全面的反映了这个算法的性质。但另一方面,这种衡量并没有保证,不是每个计算都能在这个基本操作内完成。而且,对于平均情况的计算,也会因为应用算法的实例分布可能并不均匀而难以计算。
因此,我们主要关注算法的最坏情况,亦即最坏时间复杂度。
时间复杂度的几条基本计算规则
- 基本操作,即只有常数项,认为其时间复杂度为O(1)
- 顺序结构,时间复杂度按加法进行计算
- 循环结构,时间复杂度按乘法进行计算
- 分支结构,时间复杂度取最大值
- 判断一个算法的效率时,往往只需要关注操作数量的最高次项,其它次要项和常数项可以忽略
- 在没有特殊说明时,我们所分析的算法的时间复杂度都是指最坏时间复杂度
算法分析
- 第一次尝试的算法核心部分
for a in range(0, 1001): for b in range(0, 1001): for c in range(0, 1001): if a**2 + b**2 == c**2 and a+b+c == 1000: print("a, b, c: %d, %d, %d" % (a, b, c))
时间复杂度:
T(n) = O(n*n*n) = O(n3)
- 第二次尝试的算法核心部分
for a in range(0, 1001): for b in range(0, 1001-a): c = 1000 - a - b if a**2 + b**2 == c**2: print("a, b, c: %d, %d, %d" % (a, b, c))
时间复杂度:
T(n) = O(n*n*(1+1)) = O(n*n) = O(n2)
由此可见,我们尝试的第二种算法要比第一种算法的时间复杂度好多的。
常见时间复杂度
| 执行次数函数举例 | 阶 | 非正式术语 |
|---|---|---|
| 12 | O(1) | 常数阶 |
| 2n+3 | O(n) | 线性阶 |
| 3n2+2n+1 | O(n2) | 平方阶 |
| 5log2n+20 | O(logn) | 对数阶 |
| 2n+3nlog2n+19 | O(nlogn) | nlogn阶 |
| 6n3+2n2+3n+4 | O(n3) | 立方阶 |
| 2n | O(2n) | 指数阶 |
注意,经常将log2n(以2为底的对数)简写成logn
常见时间复杂度之间的关系
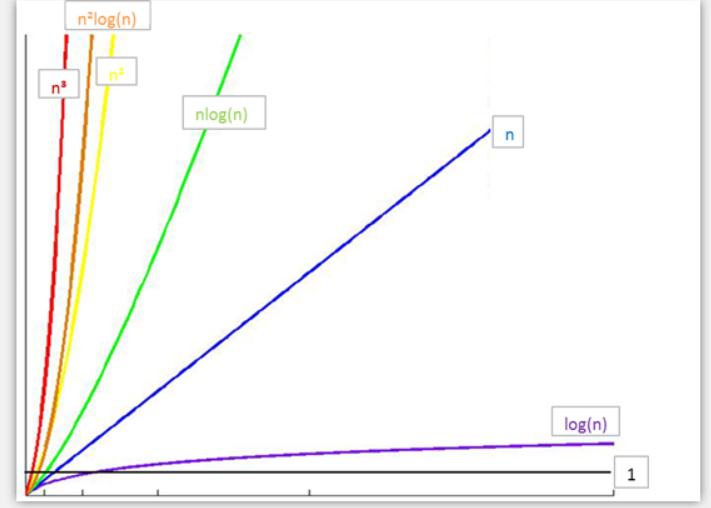
所消耗的时间从小到大
O(1) < O(logn) < O(n) < O(nlogn) < O(n2) < O(n3) < O(2n) < O(n!) < O(nn)
练习: 时间复杂度练习( 参考算法的效率规则判断 )
O(5)
O(2n + 1)
O(n²+ n + 1)
O(3n³+1)
Python内置类型性能分析
timeit模块
timeit模块可以用来测试一小段Python代码的执行速度。
class timeit.Timer(stmt='pass', setup='pass', timer=<timer function>)
Timer是测量小段代码执行速度的类。
stmt参数是要测试的代码语句(statment);
setup参数是运行代码时需要的设置;
timer参数是一个定时器函数,与平台有关。
timeit.Timer.timeit(number=1000000)
Timer类中测试语句执行速度的对象方法。number参数是测试代码时的测试次数,默认为1000000次。方法返回执行代码的平均耗时,一个float类型的秒数。
list的操作测试
def test1(): l = [] for i in range(1000): l = l + [i] def test2(): l = [] for i in range(1000): l.append(i) def test3(): l = [i for i in range(1000)] def test4(): l = list(range(1000)) from timeit import Timer t1 = Timer("test1()", "from __main__ import test1") print("concat ",t1.timeit(number=1000), "seconds") t2 = Timer("test2()", "from __main__ import test2") print("append ",t2.timeit(number=1000), "seconds") t3 = Timer("test3()", "from __main__ import test3") print("comprehension ",t3.timeit(number=1000), "seconds") t4 = Timer("test4()", "from __main__ import test4") print("list range ",t4.timeit(number=1000), "seconds") # ('concat ', 1.7890608310699463, 'seconds') # ('append ', 0.13796091079711914, 'seconds') # ('comprehension ', 0.05671119689941406, 'seconds') # ('list range ', 0.014147043228149414, 'seconds')
pop操作测试
x = range(2000000) pop_zero = Timer("x.pop(0)","from __main__ import x") print("pop_zero ",pop_zero.timeit(number=1000), "seconds") x = range(2000000) pop_end = Timer("x.pop()","from __main__ import x") print("pop_end ",pop_end.timeit(number=1000), "seconds") # ('pop_zero ', 1.9101738929748535, 'seconds') # ('pop_end ', 0.00023603439331054688, 'seconds')
测试pop操作:从结果可以看出,pop最后一个元素的效率远远高于pop第一个元素
可以自行尝试下list的append(value)和insert(0,value),即一个后面插入和一个前面插入???
list内置操作的时间复杂度

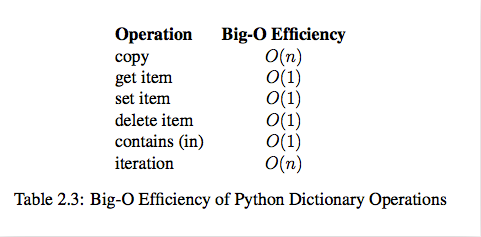
dict内置操作的时间复杂度
数据结构
我们如何用Python中的类型来保存一个班的学生信息? 如果想要快速的通过学生姓名获取其信息呢?
实际上当我们在思考这个问题的时候,我们已经用到了数据结构。列表和字典都可以存储一个班的学生信息,但是想要在列表中获取一名同学的信息时,就要遍历这个列表,其时间复杂度为O(n),而使用字典存储时,可将学生姓名作为字典的键,学生信息作为值,进而查询时不需要遍历便可快速获取到学生信息,其时间复杂度为O(1)。
我们为了解决问题,需要将数据保存下来,然后根据数据的存储方式来设计算法实现进行处理,那么数据的存储方式不同就会导致需要不同的算法进行处理。我们希望算法解决问题的效率越快越好,于是我们就需要考虑数据究竟如何保存的问题,这就是数据结构。
在上面的问题中我们可以选择Python中的列表或字典来存储学生信息。列表和字典就是Python内建帮我们封装好的两种数据结构。
概念
数据是一个抽象的概念,将其进行分类后得到程序设计语言中的基本类型。如:int,float,char等。数据元素之间不是独立的,存在特定的关系,这些关系便是结构。数据结构指数据对象中数据元素之间的关系。
Python给我们提供了很多现成的数据结构类型,这些系统自己定义好的,不需要我们自己去定义的数据结构叫做Python的内置数据结构,比如列表、元组、字典。而有些数据组织方式,Python系统里面没有直接定义,需要我们自己去定义实现这些数据的组织方式,这些数据组织方式称之为Python的扩展数据结构,比如栈,队列等。
算法与数据结构的区别
数据结构只是静态的描述了数据元素之间的关系。
高效的程序需要在数据结构的基础上设计和选择算法。
程序 = 数据结构 + 算法
总结:算法是为了解决实际问题而设计的,数据结构是算法需要处理的问题载体
抽象数据类型(Abstract Data Type)
抽象数据类型(ADT)的含义是指一个数学模型以及定义在此数学模型上的一组操作。即把数据类型和数据类型上的运算捆在一起,进行封装。引入抽象数据类型的目的是把数据类型的表示和数据类型上运算的实现与这些数据类型和运算在程序中的引用隔开,使它们相互独立。
最常用的数据运算有五种:
- 插入
- 删除
- 修改
- 查找
- 排序