网站流量日志分析的意义
通过分析用户的行为数据 让更多的用户沉淀下来变成会员 赚取更多的钱。
如何进行网站分析
流量分析
- 质量分析 在看重数量的同时 需要关注流量的质量 所谓的质量指的是流量所能带来产生的价值。
- 多维度细分 维度指的是分析的问题的角度 在不同的维度下 问题所展示的特性是不一样的
内容导航分析
从页面的角度分析 用户的访问行为轨迹
转化分析(漏斗模型分析)
从转化目标分析 分析所谓的流失率转化率 漏斗模型:层层递减 逐级流失的形象描述
网站流量日志分析的数据处理流程
按照数据的流转流程进行 通俗概括就是数据从哪里来一直到数据到哪儿去
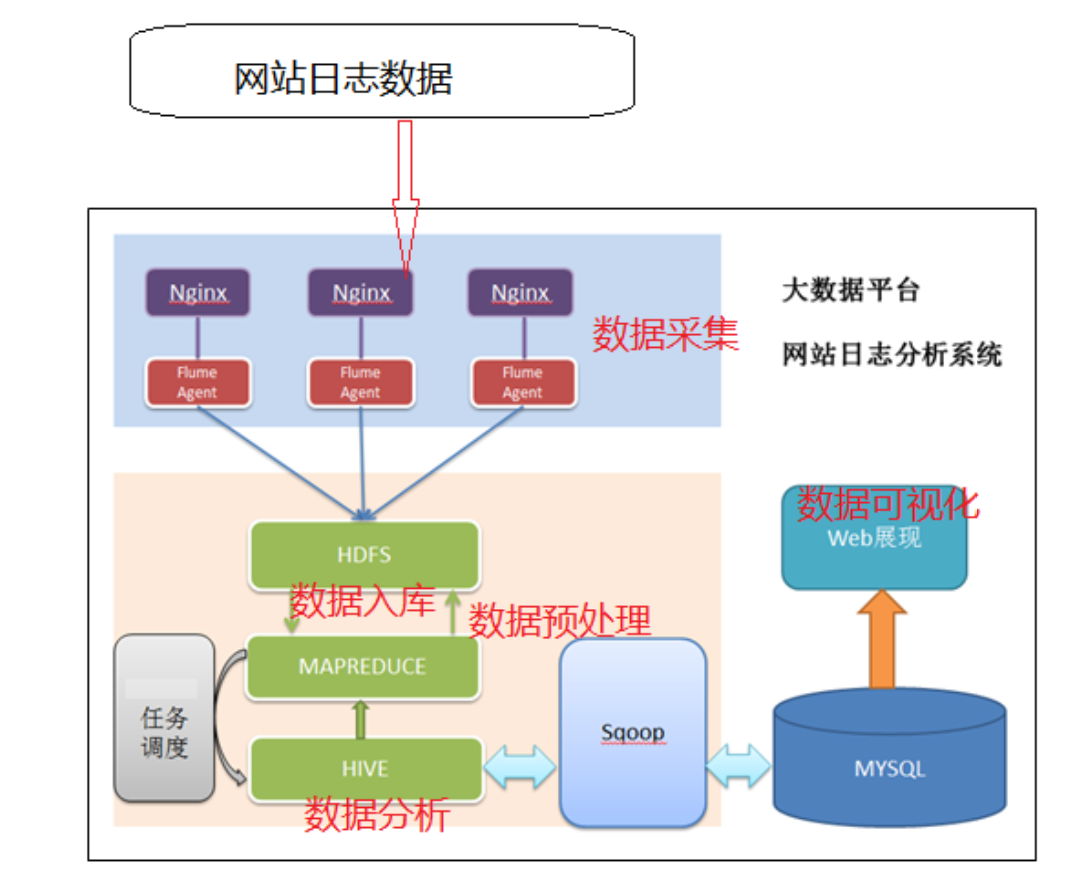
数据采集
- 数据从无到有的过程:通过技术把客观事件量化成为数据(传感器收集 服务器日志收集)
- 数据搬运过程:把数据从一个存储介质传递到另一个存储介质中(Apache Flume)
数据预处理
- 目的:保证后续正式处理的数据是格式统一、干净规则的结构化数据
- 技术:任何语言软件只要能够接受数据处理数据并且最终输出数据 都可以用于数据预处理
**选择MapReduce**
- MR本身是java程序,语言比较熟悉 可以无缝的调用java现有的开源库进行数据处理
- MR是分布式的程序 在预处理中 如果数据量比较大 可以分布式并行计算处理 提高效率
数据入库
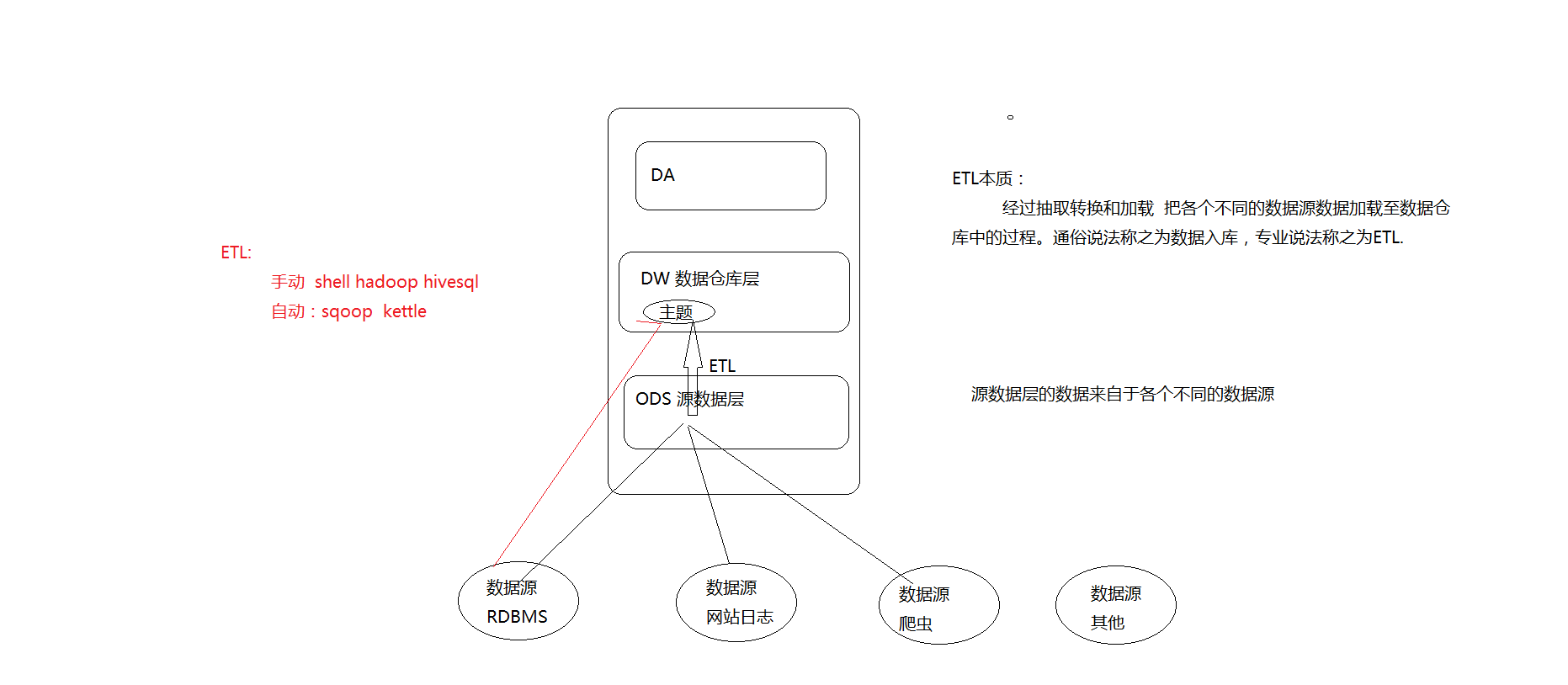
- 库:面向分析的数据仓库,也是就会Apache Hive
- 入库的本质:经过ETL(抽取、转换、加载)把各个不同的数据源集中加载到数仓的分析主题下面。
数据分析
- 本质:根据业务需求 使用hive sql计算统计出各种不同的指标 分析是一个持续的过程
数据可视化
尽量的使用图形表格的形式 把分析的结果规律展示给别人看 也称之为数据报表
埋点数据采集
数据从无到有的采集 如何把用户的访问行为记录下来变成网站访问日志
数据采集方式及其优缺点
### 网站日志文件
网站的web服务器自带日志记录的功能 简单便捷的收集一些基础的属性信息
常见的web服务器(Tomcat nginx apache server(httpd))
优点:简单便捷 自带功能 不需要配置就可以使用
缺点:收集的信息确定 不利于维护 收集的信息不够完整全面
### 埋点JavaScript收集
- 目标:不以影响用户的正常浏览体验作为标准 数据采集分析锦上添花
- 何为埋点
```
在待采集数据的页面上,预先置入一段JavaScript代码,当用户的某种行为满足JavaScript执行条件,触发JavaScript的执行,在执行的过程中进行数据的采集工作。
```
- 标准的URL
```
协议://主机:端口/资源路径?k1=v1&k2=v2
```
- 好处:可以根据业务需求 定制化收集的属性信息 在不影响用户浏览体验的情况下 进行更多数据的收集
埋点js代码实现自定义收集用户数据

(除了追求能跑通,还要考虑性能和后期维护)
问题: js和html页面耦合在一起 不利于后续js维护
```
把js单独提取处理变成一个文件 然后通过src属性引入页面 进行所谓解耦合
```
问题: 一台服务器身兼多职 压力过大 降低服务器请求压力
```
单独的去部署服务器 专门用于采集数据的请求响应
可能会产生跨域问题(限制js跨域的数据发送)
**以请求图片的形式 把采集的数据拼接成为图片的参数 发送到指定的服务器上去 绕开js的跨域问题**
(图片的请求没有域的限制,js的请求会有。跨域问题:不能从一台服务器上的js发送至另一台。主机,协议,端口任何一个不一样,就是不同域。跨域的本质是为了限制js的请求不安全,是针对js的限制。在页面收集领域,通常采用 以请求图片的形式绕开所谓的跨域问题)
为了降低请求的图片对页面的视觉干扰,将图片定义为1*1像素。
```
确定收集的信息
通常在收集数据之前结合业务需求 分析的需求确定收集哪些信息字段 和收集途径
- 可以通过nginx内置的日志收集功能获取到
- 可以通过页面上内置的对象常见的属性获取到
- 可以自定义编写js代码进行相关属性的收集
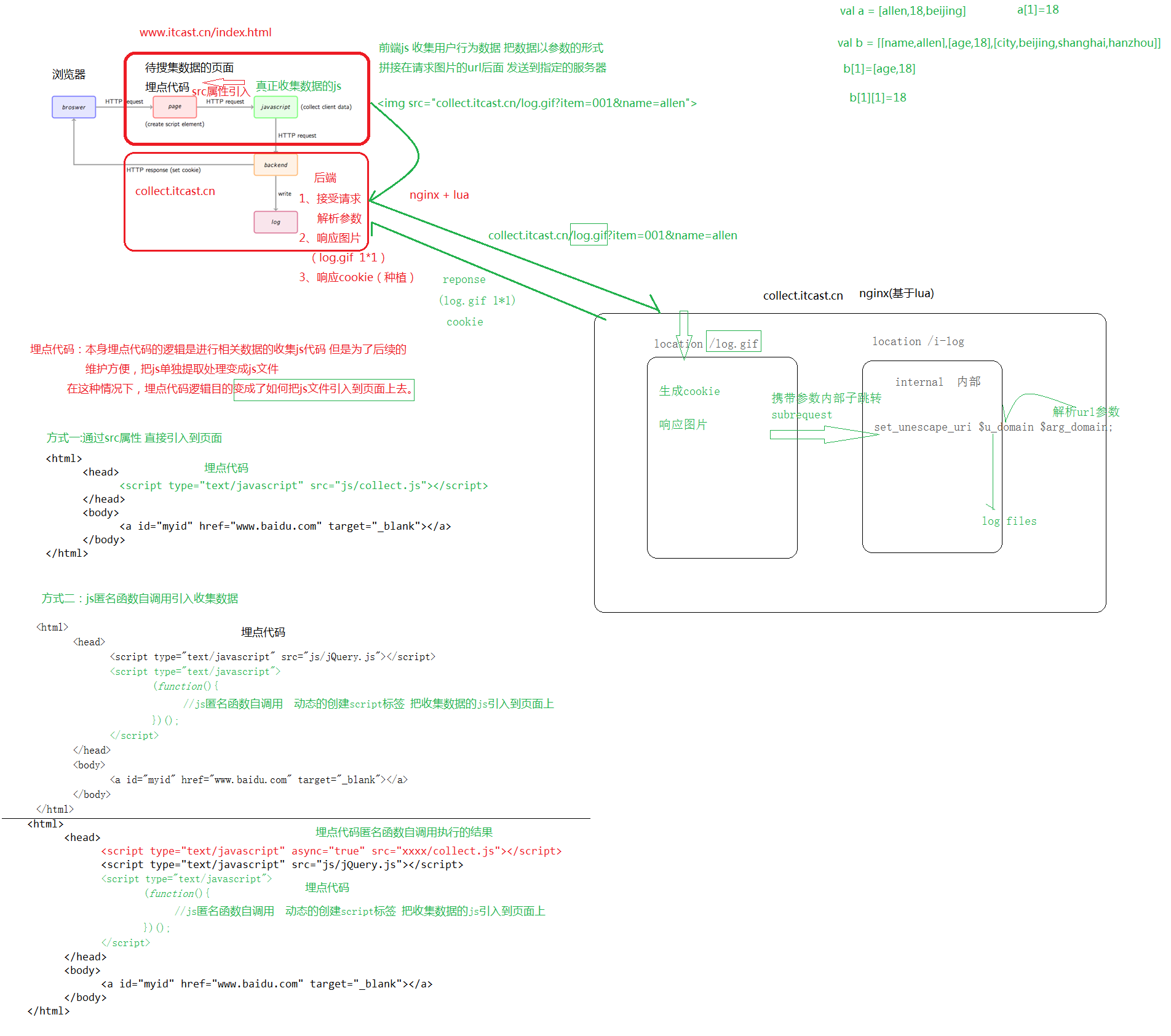
埋点代码的编写
本来埋点代码的逻辑就是真正进行数据收集的逻辑,但是为了后续维护方便 把真正收集数据的js提取出变成了js文件,在这种情况下,埋点代码的变成了如何把这个js文件引入到页面上。
直接通过src属性引入
```
<script src="www.itcast.cn/collect.js">
```
js匿名函数自调用
创建匿名函数 自己调用自己 并且调用一次 通常用于页面初始化操作
```
(function() {
var ma = document.createElement('script'); ma.type = 'text/javascript'; ma.async = true;
ma.src = 'www.itcast.cn/collect.js';
var s = document.getElementsByTagName('script')[0]; s.parentNode.insertBefore(ma, s);
})();
```
前端收集数据js
依然是一个匿名函数自调用的格式 保证被引入到页面上之后 自己可以调用自己执行且执行一次
- 通过页面内置的对象获取一些属性信息
- 通过解析全局数据 获取一些信息
- 把收集的属性信息按照url格式进行拼接 并且进行url编码
- 页面创建一个图片标签 把标签的src属性指向后端收集数据的服务器
- 把收集数据拼接的参数放置请求图片的url后面 传递给后端
后端脚本
所谓后端就是接受解析前端发送采集数据的服务器
- 接受请求 解析参数 保存数据
- 响应图片 log.gif 1*1
- 响应cookie cookiekey cookievalue path
注意搞清楚nginx 中 location模块的具体职责:用于请求url资源路径的匹配。
日志格式
考虑日志中字段之间的分隔符问题 以有利于后续程序处理数据方便为标准
常见的分隔符 制表符 空格 特殊符号 �01
日志切分
nginx默认把日志一直写在一个文件中access.log 不利于后续的维护移动操作处理
通过shell脚本给nginx进程发送usr1信号 告知其重载配置文件 在重载配置文件的时候 重新打开一个新的日志文件 在配合crontab定时器 从而完成间接的通过时间控制文件的滚动
flume数据采集
kafka 和 flume 都是日志系统,kafka 是分布式消息中间件,自带存储,提供push 和 pull 存取数据功能。
flume分为 agent (数据采集器),collector (数据简单处理和写入),storage(存储器)三部分,每一部分都是可以定制的。比如 agent 采用 RPC(Thrift-RPC)、text(文件)等,storage 指定用 hdfs 做。
flume每一部分都是可以定制。kafka更合适做日志缓存,flume数据采集部分做的很好,可以定制很多数据源,减少开发量。
-
flume 新source taildir
- 监控一个文件的变化,此时相当于exec source :tail -f xxx
- 监控一个文件夹下文件的变化,并且支持正则匹配 此时相当于spooldir source
- 支持断点续传功能 通过文件记录上传的位置 待重启或者出现故障的时候 可以继续工作
-
需求:在使用flume采集数据到hdfs的时候 以文件大小进行控制滚动,大小为:128M
a1.sinks.k1.hdfs.rollInterval = 0 a1.sinks.k1.hdfs.rollSize = 134217728 a1.sinks.k1.hdfs.rollCount = 0
当通过flume上传文件至hdfs当中 如果控制文件滚动的条件不满足怎么办?
如果不满足 位于hdfs上的文件将会一直处于临时状态 xxx.tmp
a1.sinks.k1.hdfs.rollInterval = 0 时间间隔
a1.sinks.k1.hdfs.rollSize = 134217728 文件的大小
a1.sinks.k1.hdfs.rollCount = 0 event数量
解决:基于文件空闲时间滚动
hdfs.idleTimeout 默认值是0 如果配置指定的时间 比如30s
意味着如果30s之内 文件没有数据写入 即是其他的滚动条件不满足 此时已然进行文件的滚动
避免文件一致处于所谓的临时状态