方式一:select * from 学生表 where 姓名 in(select 姓名 from 学生表 group by 姓名 having count(姓名)>=2)
分析:from 学生表 :找到要查询的表名, where 姓名 in:过滤条件让姓名符合小括号里面内容 group by 姓名 :按照姓名来分组,也就是说姓名相同的会放在同一组里面,其他字段可能包括多条信息,having count(姓名)>=2:过滤分组内容中姓名达到两个以及以上的信息)
方式二:select 姓名,count(姓名) from 学生表 group by 姓名 having count(姓名)>=2
注意方式二:select 姓名 from 学生表 group by 姓名 having count(姓名)>=2即可,count(姓名)是自己又在返回的视图看到了另一个字段,这个字段用来显示出现的重复姓名的次数。
GROUP BY语句,经过研究和练习,终于明白如何使用了,在此记录一下同时添加了一个自己举的小例子,通过写这篇文章来加深下自己学习的效果,还能和大家分享下,同时也方便以后查阅,一举多得![]()
一、GROUP BY
GROUP BY语句用来与聚合函数(aggregate functions such as COUNT, SUM, AVG, MIN, or MAX.)联合使用来得到一个或多个列的结果集。
语法如下:
SELECT column1, column2, ... column_n, aggregate_function (expression)
FROM tables
WHERE predicates
GROUP BY column1, column2, ... column_n;
举例
比如说我们有一个学生表格(student),包含学号(id),课程(course),分数(score)等等多个列,我们想通过查询得到每个学生选了几门课程,此时我们就可以联合使用COUNT函数与GROUP BY语句来得到这一结果
SELECT id, COUNT(course) as numcourse
FROM student
GROUP BY id
因为我们是使用学号来进行分组的,这样COUNT函数就是在以学号分组的前提下来实现的,通过COUNT(course)就可以计算每一个学号对应的课程数。
注意
因为聚合函数通过作用于一组数据而只返回一个单个值,因此,在SELECT语句中出现的元素要么为一个聚合函数的输入值,要么为GROUP BY语句的参数,否则会出错。
例如,对于上面提到的表格,我们做一个这样的查询:
SELECT id, COUNT(course) as numcourse, score
FROM student
GROUP BY id
此时查询便会出错,错误提示如下:
Column ‘student.score' is invalid in the select list because it is not contained in either an aggregate function or the GROUP BY clause.
出现以上错误的原因是因为一个学生id对应多个分数,如果我们简单的在SELECT语句中写上score,则无法判断应该输出哪一个分数。如果想用score作为select语句的参数可以将它用作一个聚合函数的输入值,如下例,我们可以得到每个学生所选的课程门数以及每个学生的平均分数:
SELECT id, COUNT(course) as numcourse, AVG(score) as avgscore
FROM student
GROUP BY id
二、HAVING
HAVING语句通常与GROUP BY语句联合使用,用来过滤由GROUP BY语句返回的记录集。
HAVING语句的存在弥补了WHERE关键字不能与聚合函数联合使用的不足。
语法:
SELECT column1, column2, ... column_n, aggregate_function (expression)
FROM tables
WHERE predicates
GROUP BY column1, column2, ... column_n
HAVING condition1 ... condition_n;
同样使用本文中的学生表格,如果想查询平均分高于80分的学生记录可以这样写:
SELECT id, COUNT(course) as numcourse, AVG(score) as avgscore
FROM student
GROUP BY id
HAVING AVG(score)>=80;
在这里,如果用WHERE代替HAVING就会出错
SQL中group by详解
看一下测试表test
对这个表写group by时,可能就会发生下面这样的怪事:
select name from test group by name -- ok
select * from test group by name --error
select name,sum(number) from test group by name -- ok
- 1
- 2
- 3
行吧,接下来一步步的来看。
1. 单列group by
对 test表(表1)执行下面语句
select name from test group by name
- 1
结果很明显,这是表2
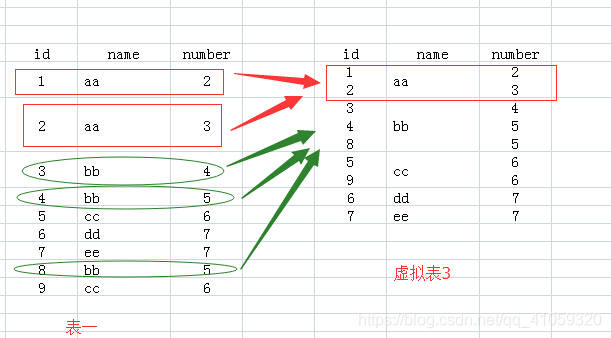
为了能够更好的理解“group by”多个列“和”聚合函数“的应用,由表1到表2的过程中,增加一个虚构的中间表:虚拟表3。下面说说如何来思考上面SQL语句执行情况:
-
from test:sql执行的第一步,找表,这个没啥变化;
-
from test group by name:没有join 和 where 操作,就是group by了,这时候的过程就如下图所示了,找到name那一列,将具有相同name值的行,合并成同一行。比如nama = aa时,就将<1,aa,2>和<2,aa,3>这两行合并,其它字段(id,number)合并在一个单元格;
-
接下来就对产生的虚拟表3进行select操作了,这时候就可以看出上面的几句select的问题出在哪了。
(1)直接 select name 是没问题的,因为group by 的字段就是name,每个单元格只有一个name,某闷忒;
(2)执行 select * 的话,就是从表3中选择,可是id 和 number 字段中的单元格里的内容有多个值,关系型数据库是不允许这样的,这样就无法形成严格的关系约束条件了,所以会报错;
那么,对于 id 和 number列咋办呢?聚合函数。
不知道大家有没有遇到过 aggregator blah blah 之类的报错,我用 group by 的时候就放过这个错,现在想来应该就是 后面用了 group by,却没对字段进行聚合,导致单元格里有多个值。
聚合函数,就是用来输入多个数据,输出一个数据的,如count(id), sum(number),每个聚合函数的输入就是每一个多数据的单元格。
因此,这里可以执行
select name,sum(number) from test group by name
- 1
那么sum 函数就是对虚拟表3中,每个name对应的number单元格进行sum操作,就可以得到:
2. 对多列进行 group by
那要是group by 多个字段怎么理解呢, 比如还是在test 表中,group by name,number,此时我们可以将name 和 number 看成一个整体字段,将其作为一个整体来进行判断划分的。如图:
这里只有 <bb, 5>和<cc, 6>是 name 和 number 都相等的,所以将其进行合并,其余并不完全一样,所以没有进行分组合并。
此时执行以下语句
select name,sum(id) from test group by name,number
- 1
就可以得到
SQL Count(*)函数,GROUP_By,Having的联合使用
COUNT(*) 函数返回在给定的选择中被选的行数。
语法:SELECT COUNT(*) FROM table
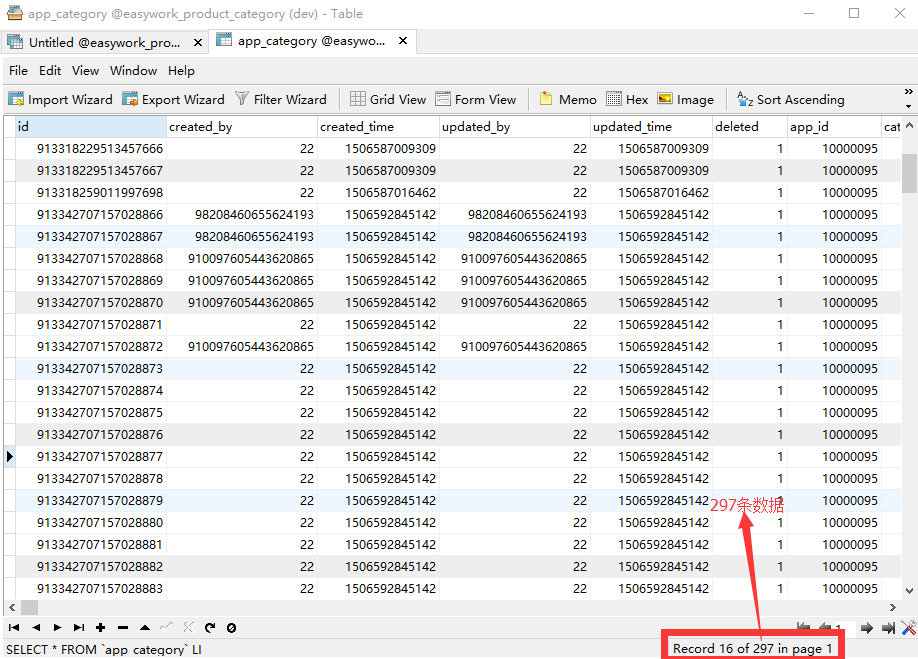
使用:现在有一个表,名叫app_category,从Navicat中可以看到表中所有数据,如图所示,可见表中有297条数据
使用count函数的时候可以看到:
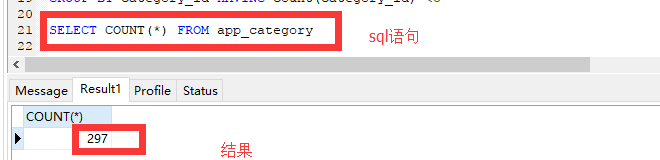
当然仅仅是这个样子,是木有意义的,我用个可视化工具一眼看穿,要这个函数就显得鸡肋了,那么我们继续往下看。
场景是这样的:表app_category与表category关联。且表间关系是一对多,即同一个app_category_id 对应多个category-id,现在我需要统计出每一个category_id在app_category表中出现的次数那么该如何实现呢,请看接下来的操作:

这样依然有点不够酷炫,那么我们还可以在后面继续追加sql语句呀
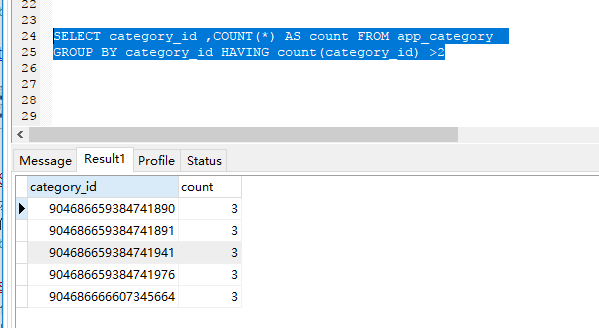
例如这条语句:
SELECT category_id ,COUNT(*) AS count FROM app_category
GROUP BY category_id HAVING count(category_id) >2
其查询的结果是只有count的值大于2 的时候,才是需要的结果