说点题外的:
MySQL当中的 “My” 是什么意思?
MySQL的发明者名叫 Michael “Monty” Widenius,MySQL是以他女儿的名字 “My” 来命名的。对这位发明者来说,MySQL数据库就仿佛是他可爱的女儿。
她的二女儿叫什么呢?二女儿叫Maria,MariaDB名字的来源。
正题:
在从一堆数据中查找指定的数据时,我们常用的数据结构是哈希表和二叉查找树,表本质上就是一堆数据的集合,所以MySQL数据库用了哈希表和B+树来实现索引
B+树是通过二叉查找树,再由平衡二叉树,B树(又名B-树)演化而来的,B+树中的B不是代表二叉(binary),而是代表平衡(balance),因为B+树是从最早的平衡二叉树演化而来,但是B+树不是一个二叉树。
二叉查找树
二叉查找树是带有特殊属性的二叉树,需要满足以下属性
- 非叶子节点最多拥有两个子节点
- 非叶子节值大于左边子节点、小于右边子节点(左小右大)
- 没有值相等重复的节点;
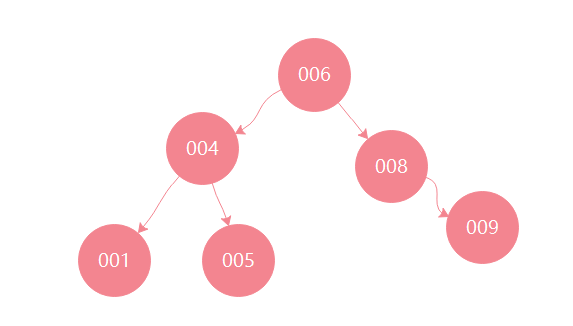
对上图这个二叉树进行查找,如查键值为5的记录,先找到根,其值时6,大于5,查找6的左子树,找到4,4小于5,再找其右子树,一共找了3次。同理,查找键值为8的记录,用了1次。所有键值平均查找次数为(1+2+2+3+3+3)/6=2.3次,假如对这些键值进行顺序查找,平均查找次数为(1+2+3+4+5+6)/6=3.3(查找顺序摆放的数,第一个数肯定是1次,而第2个数是2次,以此类推),显然二叉查找树的平均查找速度比顺序查找更快
二叉查找树可以任意的构造,假如二叉查找树按照如下方式构造
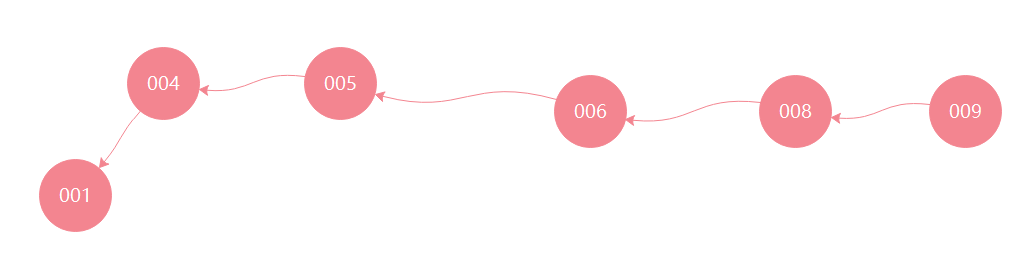
平均查找速度为(1+2+3+4+5+5)/6=3.16次,和顺序查找差不多。为了提高二叉查找树的查询效率,需要二叉查找数是平衡的,这就引出了平衡二叉树。
平衡二叉树:
平衡二叉树除了满足上面3个属性,还要满足如下1个属性
- 树的左右两边的层级数相差不会大于1
平衡二叉树的查找效率确实很快,但维护一颗平衡二叉树的代价是非常大的,需要1次或多次左旋和右旋来得到插入或更新后树的平衡性。左旋右旋就是选定一个节点作为目标节点,此目标节点就变成左节点/右节点
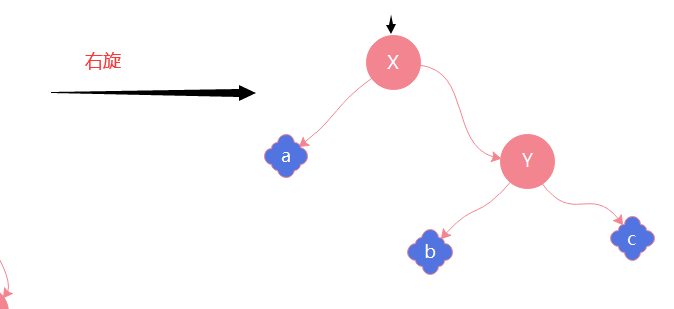
举个栗子:
有一个x节点,对x进行左旋意味着将x变为一个左节点

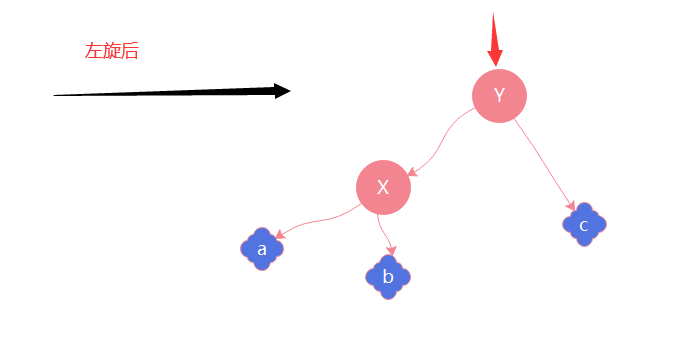
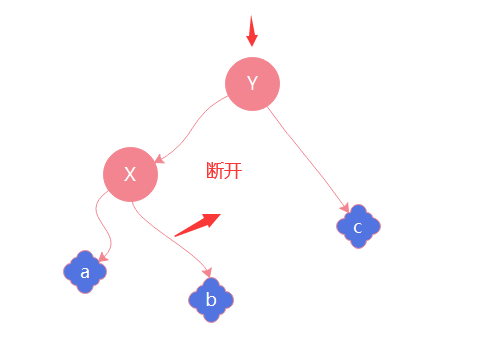
同理有一个y节点,对y进行右旋意味着将y变为一个右节点
B树和B+树
B树和B-树是同一种树,假如用平衡二叉树实现索引效率已经很高了,查找一个节点所做的IO次数是这个节点所处的树的高度,因为我们无法把整个索引都加载到内存,并且节点数据在磁盘中不是顺序排放的。所以最快情况下,磁盘的IO次数为数的高度。
虽然平衡二叉树查找效率确实很高,但是频繁的IO才是阻碍提高性能的瓶颈,怎样减少IO次数呢?前辈们很聪明的提出了局部性原理,分为时间局部性原理,即加入你查询id为1的用户数据,过一段时间你还会查询id为1的数据,所以会将这部分数据缓存下来。空间局部性原理,当你查询id为1的用户数据的时候,你有很大的概率会去查询id为2,3,4的用户的数据,所以会一次性的把id为1,2,3,4的数据都读到内存中去,这个最小的单位就是页。
借用别人的图展示下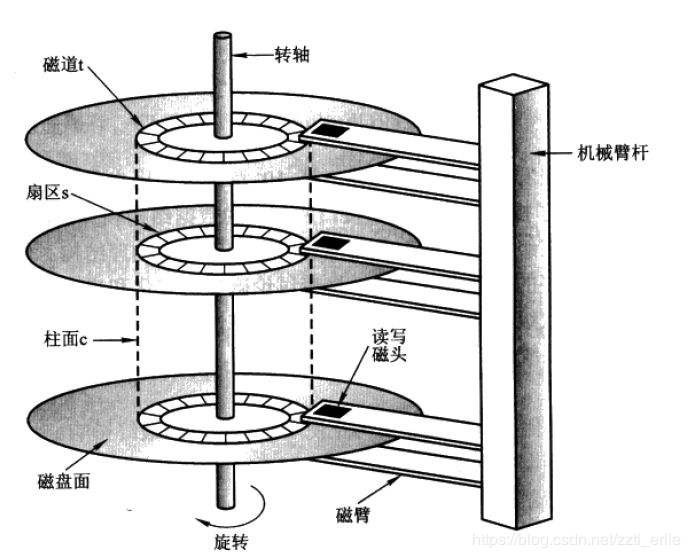
简单来说CPU进行运算是电子运动,计算速度很快。而将数据从硬盘读取到内存中是机械运动,很慢。我们在买硬盘的时候经常问这个硬盘是多少转(每分钟转动的圈数),7200转,5400转。所以说转动的越快加载数据越快,但是和CPU比起来差的还很远,所以说要减低IO次数。
B树和B+树的区别:
B+跟B树不同B+树的非叶子节点不保存键值对应的数据,这样使得B+树每个节点所能保存的键值大大增加;
B+树叶子节点保存了父节点的所有键值和键值对应的数据,每个叶子节点的关键字从小到大链接;
B+树的根节点键值数量和其子节点个数相等;
B+的非叶子节点只进行数据索引,不会存实际的键值对应的数据,所有数据必须要到叶子节点才能获取到,所以每次数据查询的次数都一样;
B树
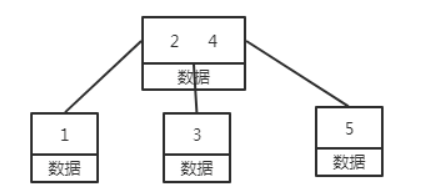
B+树
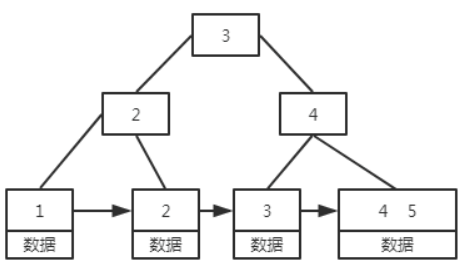
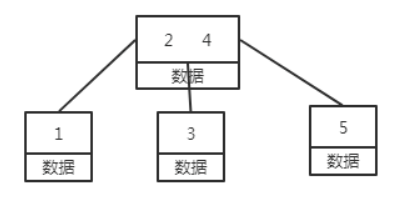
在B树的基础上每个节点存储的关键字数更多,树的层级更少所以查询数据更快,所有关键字指针都存在叶子节点,所以每次查找的次数都相同所以查询速度更稳定。除此之外,B+树的叶子节点是跟后序节点相连接的,这对范围查找是非常有用的。
B+树的非叶子节点是主键,主键占用的空间越小,每个节点能放的主键就能更多,这就是为什么我们的主键一般不设置太大的原因。主键占用的空间小,能降低树高,减少IO次数。
聚集索引和联合索引
在InnoDB存储引擎中,是以主键为索引来组织数据的。在InnoDB存储引擎中,每张表都有个主键,如果再创建表时没有显示的定义主键,则InnoDB存储引擎会按如下方式选择或创建主键。
首先判断表中是否有非空的唯一索引,如果有,则该列即为主键
如果不符合上述条件,InnoDB存储引擎自动创建一个6字节大小的指正作为索引
如果有多个非空唯一索引时,InnoDB存储引擎将选择建表时第一个定义的非空唯一索引作为主键
假如说有如下数据,用户id为主键(1, jack),(2,mike),(3,tom),(4,apple),(5,angle)则数据是这样存储的 如图一
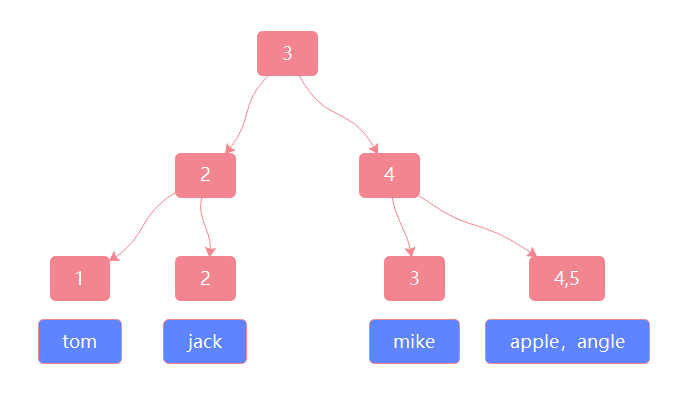
假如说我们现在对用户名建索引,用户名索引是怎么存的呢 如图二

用户名索引主键存储的是主键,所以当我们运行如下sql语句时
select * from table_name where name ="jack"
过程是这样的,先在name索引上找到对应的主键,在根据对应的主键去建表时建立的B+树上找到对应的记录,即先在图2上找,再到图1上找。
聚集索引:数据行的物理顺序与列值(一般是主键的那一列)的逻辑顺序相同,一个表中只能拥有一个聚集索引。图1用的就是聚集索引
非聚集索引:定义:该索引中索引的逻辑顺序与磁盘上行的物理存储顺序不同,一个表中可以拥有多个非聚集索引。图2用的就是非聚集索引
多个键值得B+树是如下存储的
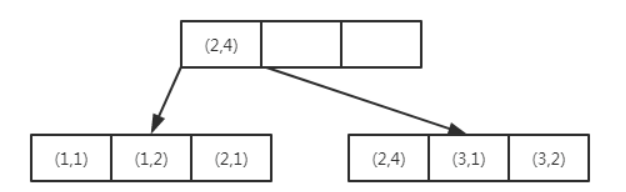
可以看到键值都是排序的,就上面的例子来说(1,1)(1,2)(2,1)(2,4)(3,1)(3,2),数据按照(a,b)的顺序进行了存放。
因此对于查询select * from table where a = xxx and b = xxx,显然是可以使用(a,b)这个联合索引的。对于单个的a列查询select * from table where a = xxx,也可以使用(a,b)这个索引。但对于b列的查询select * from table where b = xxx,则不可以使用这颗B+树索引。可以发现叶子节点上的b值为1,2,1,4,1,2,显然不是排序的,因此对于b列的查询使用不到(a,b)的索引
那么为什么mysql索引要用b+树原因如下:
- B+树能显著减少IO次数,提高效率
- B+树的查询效率更加稳定,因为数据放在叶子节点
- B+树能提高范围查询的效率,因为叶子节点指向下一个叶子节点