你应该从网上看过太多的文章说缓存穿透怎么解决?无非就是布隆过滤器,缓存空值什么的。
但是,更深入的一个问题,缓存空值有没有问题?如果缓存的空值太多怎么办?
如果用的redis,那么太多的空值会不会打爆你的redis?如果用的本地缓存,会不会打爆你的内存?继而引发的问题就是还是会打爆你的数据库。
解决方案
前置过滤
在数据量不大的情况下直接把所有的key全部从数据库查出来缓存下来,查数据库之前直接根据key过滤一把,如果不存在就直接返回,不要走数据库查询了
根据一定的范围规则去提前过滤,比如缓存的key明确知道在1-10万的范围之后,那么过滤掉在这个范围之外的请求直接返回就可以了。
当然,很明显这种简单的规则过滤适用于数据量不是很大,并且数据不会频繁发生改变的情况。
布隆过滤器
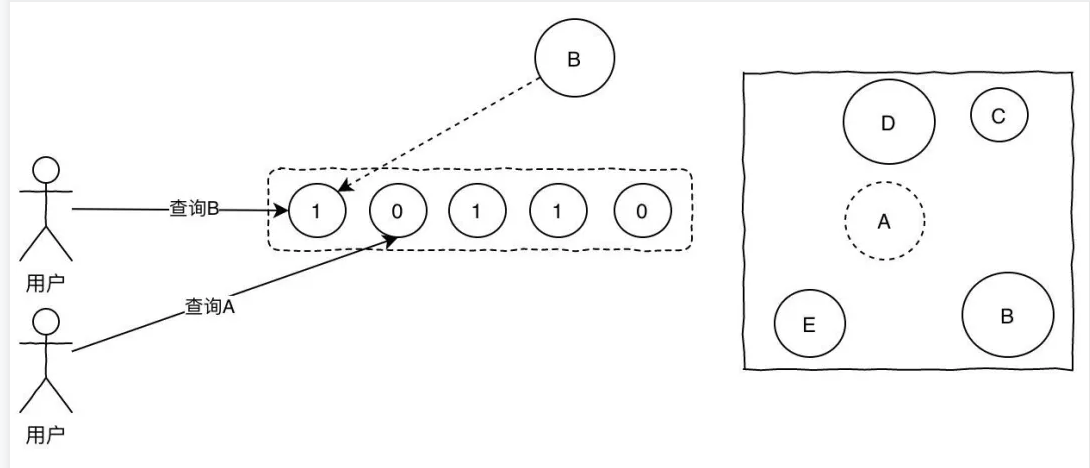
如果说数据量很大的话,比如有一亿个key,使用布隆过滤器就是个更优解。
我们可以每天定时把所有的配置信息从数据库中查询出来构建成bitmap。
如果查询的位置都是1的话说明key存在,反之只要有一个0则说明肯定不存在。
使用布隆过滤器的缺点也很明显,存在一定概率的误判。当然,既然用了,对于误判比例、内存占用等等问题应该事先评估好。
缓存空值
这个是网上说烂的问题,但是缓存空值的空值太多明显也是有问题的,再进一步解决方案就是快速过期。
一般来说,普通的缓存的写法如下,先查缓存,如果缓存存在则直接返回,如果缓存没有则去数据库查询,结果不是空就保存到缓存中。

改进版的写法就是缓存空对象,针对空的数据,设置过期时间,比如10分钟,快速过期,防止太多的空值问题。

但是这个解决方案仍然有点小问题,就是短暂的数据不一致的问题。
想象一下如果缓存的空值这时候实际上已经有值了,那么在过期时间的这段时间内就可能存在短暂的数据不一致。
总结
缓存穿透的问题总结下来就是三点,这三个方式不是说是隔离的解决方案,他们可以结合在一起使用。
首先看数据量,如果数据量很小并且没有频繁变更的话,选择前置过滤的方式,根据具体的业务规则来处理就可以。
如果数据量大的话,可以选择使用布隆过滤器,但是存在一定概率的误判。
通过前置的拦截,应该拦截住大部分的流量,避免直接打爆数据库。
最后,可以使用缓存空值并且设置快速过期的方式来作为一个兜底的方案。
如果还有问题,那么就是限流、降级了。