一、mysql索引匹配
全值匹配值的是和索引中所有的列进行匹配
先说一下mysql官网中资料,官网中提供的sql语句,几乎是基于下图中几个数据库中演练的
https://dev.mysql.com/doc/index-other.html
以sakila database 为例
1、将下载的sakila database 导入到mysql中
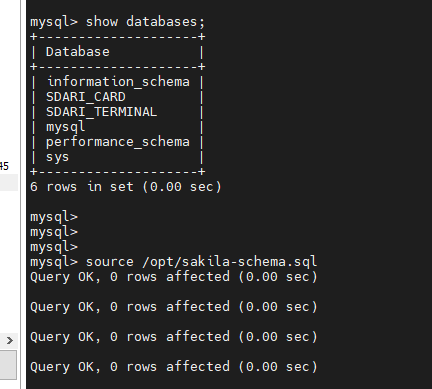
进入sakila 库中:
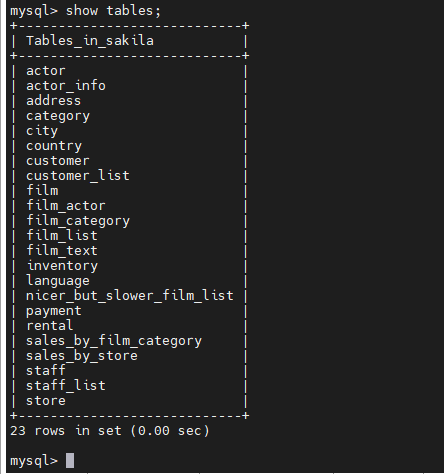
具体每张表对应的关系可以通过view观察

创建一张表
DROP TABLE IF EXISTS `staffs`; CREATE TABLE `staffs` ( `id` int(11) NOT NULL AUTO_INCREMENT, `name` varchar(255) CHARACTER SET latin1 COLLATE latin1_swedish_ci NOT NULL, `age` int(5) NOT NULL, `pos` varchar(255) CHARACTER SET latin1 COLLATE latin1_swedish_ci NULL DEFAULT NULL, `add_time` datetime(0) NULL DEFAULT NULL, PRIMARY KEY (`id`) USING BTREE, INDEX `index`(`name`, `age`, `pos`) USING BTREE ) ENGINE = InnoDB AUTO_INCREMENT = 2 CHARACTER SET = latin1 COLLATE = latin1_swedish_ci ROW_FORMAT = Dynamic; SET FOREIGN_KEY_CHECKS = 1;
全值匹配 :
explain select * from staffs where name ='Jon' and age = '23';

id:选择标识符 --SELECT识别符。这是SELECT的查询序列号
select_type:表示查询的类型。
table:输出结果集的表
partitions:匹配的分区
type:表示表的连接类型 ALL、index、range、 ref、eq_ref、const、system、NULL(从左到右,性能从差到好)
possible_keys:表示查询时,可能使用的索引
key:表示实际使用的索引
key_len:索引字段的长度
ref:列与索引的比较 ,const(常量值)
rows:扫描出的行数(估算的行数,不是真实执行的行数)
filtered:按表条件过滤的行百分比
Extra:执行情况的描述和说明
select_type:表示查询的类型。
table:输出结果集的表
partitions:匹配的分区
type:表示表的连接类型 ALL、index、range、 ref、eq_ref、const、system、NULL(从左到右,性能从差到好)
possible_keys:表示查询时,可能使用的索引
key:表示实际使用的索引
key_len:索引字段的长度
ref:列与索引的比较 ,const(常量值)
rows:扫描出的行数(估算的行数,不是真实执行的行数)
filtered:按表条件过滤的行百分比
Extra:执行情况的描述和说明
匹配最左前缀:

此时ref有两个常量值
匹配列前缀:

此时ref是null,type 是要求最小的range
匹配范围值:

精确匹配某一列并范围匹配另外一列:

它与最左前缀是不同的

type和ref列的值是不同的,此时pos是无关值
只访问索引的查询:

extra 这一列出现了using index 说明出现了索引覆盖
题外话:回表出现的充分必要条件是普通索引
二、哈希索引
1、基于哈希表实现,只有精确匹配索引所有列的查询才有
2、在mysql 中只有memory存储引擎支持哈希索引
3、哈希索引自身只需要存储对应的hash值,所以索引的结构十分紧凑,查询的速度非常快
哈希索引的限制:
1、哈希索引只包含哈希值和行指针,而不存储字段值,索引不能使用索引中的值还避免读取行
2、哈希表无法排序
3、不支持部分列匹配查找,哈希索引时使用索引列的全部内容来计算哈希值
4、哈希索引支持等值比较查询,不支持任何范围查询
5、如果有很多哈希冲突,存储引擎必须遍历链表中所有行指针,逐行比较,知道找到所有符合条件的行
二、组合索引
1、当包含多个列作为索引,需要注意正确的的顺序依赖于该索引的查询,需要考虑如何更好的满足排序和分组的需要
案例:
现在建立了a,b,c组合索引:
| where a = 3 | 只使用a | |
| where a= 3 and b = 5 | 使用a,b | |
| where a= 3 and b = 5 and c = 7 | 使用a,b,c | |
| where b = 5 and c = 7 | 没有使用 | |
| where a= 3 and c = 7 | 只使用a | |
| where a= 3 and b > 5 and c = 7 | 使用a,b | |
| where a= 3 and b like '%4%' and c = 7 | 只使用a |