索引可以说是数据库中的一个大心脏了,如果说一个数据库少了索引,那么数据库本身存在的意义就不大了,和普通的文件没什么两样。
所以说一个好的索引对数据库系统尤其重要,今天来说说 MySQL 索引,从细节和实际业务的角度看看在 MySQL 中 B+ 树索引好处,以及我们在使用索引时需要注意的知识点。
1. 合理利用索引
在工作中,我们可能判断数据表中的一个字段是不是需要加索引的最直接办法就是:这个字段会不会经常出现在我们的 where 条件中。
从宏观的角度来说,这样思考没有问题,但是从长远的角度来看,有时可能需要更细致的思考,比如我们是不是不仅仅需要在这个字段上建立一个索引?多个字段的联合索引是不是更好?
以一张用户表为例,用户表中的字段可能会有用户的姓名、用户的身份证号、用户的家庭地址等等。
1.1 普通索引的弊端
现在有个需求需要根据用户的身份证号找到用户的姓名。这时候很显然想到的第一个办法就是在 id_card 上建立一个索引,严格来说是唯一索引,因为身份证号肯定是唯一的。
那么当我们执行以下查询的时候:
SELECT name FROM user WHERE id_card=341124199408203232
它的流程应该是这样的:
- 先在 id_card 索引树上搜索,找到 id_card 对应的主键 id;
- 通过 id 去主键索引上搜索,找到对应的 name。

解释一下回表:
----------------------start-------------------
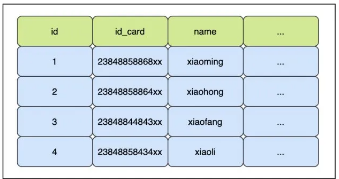
现在表中有四条记录:
1, sj, m, A
3, zs, m, A
5, ls, m, A
9, ww, f, B
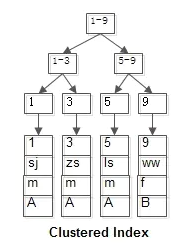
id是聚集索引,name是普通索引
两个B+树索引分别如上图:
(1)id为PK,聚集索引,叶子节点存储行记录;
(2)name为KEY,普通索引,叶子节点存储PK值,即id;
既然从普通索引无法直接定位行记录,那普通索引的查询过程是怎么样的呢?
通常情况下,需要扫码两遍索引树。
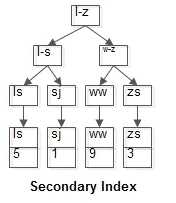
select * from t where name='ls';
执行效果

如粉红色路径,需要扫码两遍索引树:
(1)先通过普通索引定位到主键值id=5;
(2)在通过聚集索引定位到行记录;
这就是所谓的回表查询,先定位主键值,再定位行记录,它的性能较扫一遍索引树更低。
----------------------end---------------------1.2 主键索引的陷阱
既然问题是回表,造成了在两棵树都检索了,那么核心问题就是看看能不能只在一棵树上检索。
这里从业务的角度你可能发现了一个切入点:身份证号是唯一的,那么我们的主键是不是可以不用默认的自增 id 了?
我们把主键设置成我们的身份证号,这样整个表的只需要一个索引,并且通过身份证号可以查到所有需要的数据包括我们的姓名。
简单一想似乎有道理,只要每次插入数据的时候,指定 id 是身份证号就行了,但是仔细一想似乎有问题。
这里要从 B+ 树的特点来说,B+ 树的数据都存在叶子节点上,并且数据是页式管理的,一页是 16K。这是什么意思呢?
哪怕我们现在是一行数据,它也要占用 16K 的数据页。只有当我们的数据页写满了之后才会写到一个新的数据页上,
新的数据页和老的数据页在物理上不一定是连续的。而且有一点很关键,虽然数据页物理上是不连续的,但是数据在逻辑上是连续的
也许你会好奇,这和我们说的身份证号当主键ID有什么关系?
这时你应该关注「连续」这个关键字。身份证号不是连续的,这意味着什么?
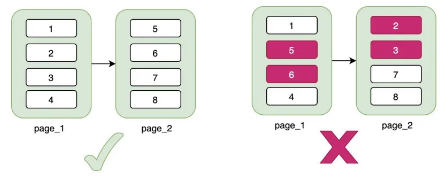
当我们插入一条不连续的数据的时候,为了保持连续,需要移动数据。比如,原来在一页上的数据有1->5,这时候插入了一条3,那么就需要把5移到3后面
也许你会说这也没多少开销。但是如果当新的数据 3 造成这个页 A 满了,那么就要看它后面的页 B 是否有空间。
如果有空间,这时候页 B 的开始数据应该是这个从页 A 溢出来的那条,对应的也要移动数据。
如果此时页 B 也没有足够的空间,那么就要申请新的页 C,然后移一部分数据到这个新页 C 上,并且会切断页 A 与页 B 之间的关系。
在两者之间插入一个页 C,从代码的层面来说,就是切换链表的指针
总结来说,不连续的身份证号当主键可能会造成页数据的移动、随机 IO、频繁申请新页相关的开销。如果我们用的是自增的主键,
那么对于 id 来说一定是顺序的,不会因为随机 IO 造成数据移动的问题,在插入方面开销一定是相对较小的。
其实不推荐用身份证号当主键的还有另外一个原因:身份证号作为数字来说太大了,得用 bigint 来存。
正常来说一个学校的学生用 int 已经足够了。我们知道一页可以存放 16K,当一个索引本身占用的空间越大时,会导致一页能存放的数据越少。
所以在一定数据量的情况下,使用 bigint 要比 int 需要更多的页也就是更多的存储空间
1.3 联合索引的矛与盾
由上面两条结论可以得出:
- 尽量不要去回表
- 身份证号不适合当主键索引
所以自然而然地想到了联合索引。创建一个【身份证号+姓名】的联合索引,注意联合索引的顺序,要符合最左原则。这样当我们同样执行以下 SQL 时:
select name from user where id_card=xxx
不需要回表就可以得到我们需要的 name 字段。然而,还是没有解决身份证号本身占用空间过大的问题。这是业务数据本身的问题,如果你要解决它的话,我们可以通过一些转换算法将原本大的数据转换成小的数据,比如 crc32
crc32.ChecksumIEEE([]byte("341124199408203232"))
可以将原本需要 8 个字节存储空间的身份证号用 4 个字节的 crc 码替代。因此,我们的数据库需要再加个字段 crc_id_card,联合索引也从【身份证号+姓名】变成了【crc32(身份证号)+姓名】,联合索引占的空间变小了
但是这种转换也是有代价的:
- 每次额外的 crc,导致需要更多 CPU 资源;
- 额外的字段。虽然让索引的空间变小了,但是本身也要占用空间;
- crc 会存在冲突的概率。这需要我们查询出来数据后,再根据 id_card 过滤一下。过滤的成本根据重复数据的数量而定,重复越多过滤越慢。
关于联合索引存储优化,这里有个小细节。假设现在有两个字段 A 和 B,分别占用 8 个字节和 20 个字节,我们在联合索引已经是 [A,B] 的情况下,还要支持 B 的单独查询。
因此,自然而然我们在 B 上也建立个索引。那么,两个索引占用的空间为 8+20+20=48。现在,无论我们通过 A 还是通过 B 查询都可以用到索引。
如果在业务允许的条件下,我们是否可以建立 [B,A] 和 A 索引?这样的话,不仅满足单独通过 A 或者 B 查询数据用到索引,还可以占用更小的空间:20+8+8=36。
1.4 前缀索引的短小精悍
有时候我们需要索引的字段是字符串类型的,并且这个字符串很长。我们希望这个字段加上索引,但是我们又不希望这个索引占用太多的空间。
这时可以考虑建立个前缀索引,以这个字段的前一部分字符建立个索引,这样既可以享受索引的好处,又可以节省空间。
需要注意的是在前缀重复度较高的情况下,前缀索引和普通索引的速度应该是有差距的。
alter table xx add index(name(7));#name前7个字符建立索引 select xx from xx where name="JamesBond"
1.5 唯一索引的快与慢
在说唯一索引之前,我们先了解下普通索引的特点,我们知道对于 B+ 树而言,叶子节点的数据是有序的
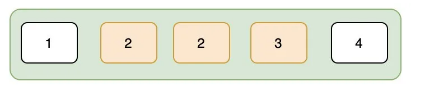
假设现在我们要查询 2 这条数据,那么在通过索引树找到 2 的时候,存储引擎并没有停止搜索。因为可能存在多个 2,这表现为存储引擎会在叶子节点上接着向后查找。在找到第二个2之后,就停止了吗?
答案是“否”,因为存储引擎并不知道后面还有没有更多的2,所以得接着向后查找,直至找到第一个不是2的数据,也就是3。找到3之后,停止检索,这就是普通索引的检索过程。
唯一索引就不一样了,因为唯一性,不可能存在重复的数据。所以,在检索到我们的目标数据之后直接返回,不会像普通索引那样还要向后多查找一次。
从这个角度来看,唯一索引是要比普通索引快的。但是当普通索引的数据都在一个页内的话,其实也并不会快多少。
在数据的插入方面,唯一索引可能就稍逊色。因为唯一性,每次插入的时候,都需要将判断要插入的数据是否已经存在,而普通索引不需要这个逻辑,并且很重要的一点是唯一索引会用不到 change buffer(见下文)。
1.6 不要盲目加索引
在工作中,你可能会遇到这样的情况:这个字段我需不需要加索引?
对于这个问题,我们常用的判断手段就是:查询会不会用到这个字段,如果这个字段经常在查询的条件中,我们可能会考虑加个索引。但是如果只根据这个条件判断,你可能会加了一个错误的索引。
我们来看个例子:假设有张用户表,大概有 100 万的数据。用户表中有个性别字段表示男女,男女差不多各占一半。现在我们要统计所有男生的信息,然后我们给性别字段加了索引,并且我们这样写下了 SQL:
select * from user where sex="男"
如果不出意外的话,InnoDB 是不会选择性别这个索引的。如果走性别索引,那么一定是需要回表的。
在数据量很大的情况下,回表会造成什么样的后果?
我贴一张和上面一样的图想必大家都知道了:

主要就是大量的 IO。
一条数据需要 4 次,那么 50 万的数据呢?结果可想而知。
因此针对这种情况,MySQL 的优化器大概率走全表扫描,直接扫描主键索引。因为这样性能可能会更高
2. 索引优化
2.1 change buffer
我们知道在更新一条数据的时候,要先判断这条数据的页是否在内存里。
如果在内存中的话,直接更新对应的内存页;如果不在的话,只能去磁盘把对应的数据页读到内存中来,然后再更新。
这会有什么问题呢?
- 去磁盘的读这个动作稍显的有点慢;
- 如果同时更新很多数据,那么即有可能发生很多离散的 IO。
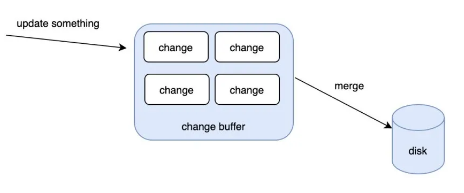
为了解决这种情况下的速度问题,change buffer 出现了。
首先,不要被 buffer 这个单词误导。change buffer 除了会在公共的 buffer pool 里之外,也是会持久化到磁盘的。
当有了 change buffer 之后,我们更新的过程中,如果发现对应的数据页不在内存里的话,也不去磁盘读取相应的数据页了,而是把要更新的数据放入到 change buffer 中。
那 change buffer 的数据何时被同步到磁盘上去?如果此时发生读动作怎么办?
首先,后台有个线程会定期把 change buffer 的数据同步到磁盘上去的。如果线程还没来得及同步,但是又发生了读操作,那么也会触发把 change buffer 的数据 merge 到磁盘的事件。
需要注意的是,并不是所有的索引都能用到 changer buffer。像主键索引和唯一索引就用不到。
因为唯一性,所以它们在更新的时候要判断数据存不存在。如果数据页不在内存中,就必须去磁盘上把对应的数据页读到内存里,而普通索引就没关系了,不需要校验唯一性。change buffer 越大,理论收益就越大,这是因为首先离散的读 IO 变少了。
其次,当一个数据页上发生多次变更,只需 merge 一次到磁盘上。
当然并不是所有的场景都适合 change buffer。如果你的业务是更新之后,需要立马去读,change buffer 会适得其反。
因为需要不停地触发 merge 动作,导致随机 IO 的次数不会变少,反而增加了维护 change buffer 的开销
2.2 索引下推
前面我们说了联合索引,联合索引要满足最左原则,即在联合索引是 [A,B] 的情况下,我们可以通过以下的 SQL 用到索引:
select * from table where A="xx" select * from table where A="xx" AND B="xx"
其实联合索引也可以使用最左前缀的原则,即:
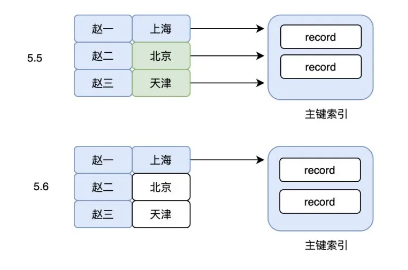
select * from table where A like "赵%" AND B="上海市"
但是这里需要注意的是,因为使用了 A 的一部分,在 MySQL 5.6 之前,上面的 SQL 在检索出所有 A 是“赵”开头的数据之后,就立马回表(使用的 select *)。然后,再对比 B 是不是“上海市”这个判断。
这里是不是有点懵?为什么 B 这个判断不直接在联合索引上判断,这样的话回表的次数不就少了吗?
造成这个问题的原因还是因为使用了最左前缀的问题。导致索引虽然能使用部分 A,但是完全用不到 B,看起来是有点“傻”。
于是在 MySQL5.6 之后,就出现了索引下推这个优化(Index Condition Pushdown)。有了这个功能以后,虽然使用的是最左前缀,但是也可以在联合索引上搜索出符合 A% 的同时也过滤非 B 的数据,大大减少了回表的次数。
2.3 刷新邻接页
在说刷新邻接页之前,我们先说下脏页。
我们知道在更新一条数据的时候,得先判断这条数据所在的页是否在内存中。如果不在内存中的话,需要把这个数据页先读到内存中,然后再更新内存中的数据。
这时会发现内存中的页有最新的数据,但是磁盘上的页却依然是老数据,那么此时这条数据所在的内存中的页就是脏页,需要刷到磁盘上来保持一致。
所以问题来了,何时刷?每次刷多少脏页才合适?
如果每次变更就刷,那么性能会很差,如果很久才刷,脏页就会堆积很多,造成内存池中可用的页变少,进而影响正常的功能。所以刷的速度不能太快但要及时。
MySQL 有个清理线程会定期执行,保证了不会太快。当脏页太多或者 redo log 已经快满了也会立刻触发刷盘,保证了及时。
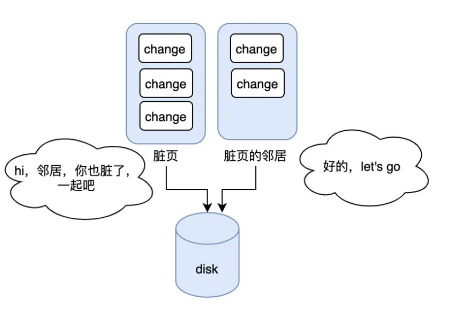
在脏页刷盘的过程中,InnoDB 这里有个优化:如果要刷的脏页的邻居页也脏了,那么就顺带一起刷。
这样的好处就是可以减少随机 IO,在机械磁盘的情况下,优化应该挺大。但是这里可能会有坑。如果当前脏页的邻居脏页在被一起刷入后,邻居页立马因为数据的变更又变脏了,那此时是不是有种多此一举的感觉,并且反而浪费了时间和开销。更糟糕的是如果邻居页的邻居也是脏页...,那么这个连锁反应可能会出现短暂的性能问题。
2.4 MRR
在实际业务中,我们可能会被告知尽量使用覆盖索引,不要回表。因为回表需要更多 IO,耗时更长。但是有时候我们又不得不回表,回表不仅仅会造成过多的 IO,更严重的是过多的离散 IO。
select * from user where grade between 60 and 70
现在要查询成绩在 60-70 之间的用户信息,于是我们的 SQL 写成上面的那样。当然,我们的 grade 字段是有索引的。
按照常理来说,会先在 grade 索引上找到 grade=60 这条数据,然后再根据 grade=60 这条数据对应的 id 去主键索引上找,最后再次回到 grade 索引上,不停重复同样的动作……
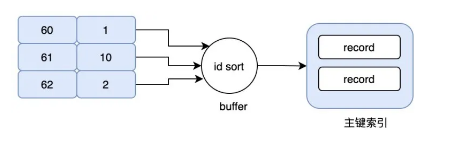
假设现在:
-
grade=60 对应的 id=1,数据是在 page_no_1 上;
-
grade=61 对应的 id=10,数据是在 page_no_2 上;
-
grade=62 对应的 id=2,数据是在 page_no_1上。
所以,真实的情况就是先在 page_no_1 上找数据,然后切到 page_no_2,最后又切回 page_no_1 上。
但其实 id=1 和 id=2 完全可以合并,读一次 page_no_1 即可。不仅节省了 IO,同时避免了随机 IO,这就是 MRR。
当使用 MRR 之后,辅助索引不会立即去回表,而是将得到的主键 id,放在一个 buffer中。然后再对其排序,排序后再去顺序读主键索引,大大减少了离散的 IO。