本文收录在Linux运维企业架构实战系列
一、收集切割公司自定义的日志
很多公司的日志并不是和服务默认的日志格式一致,因此,就需要我们来进行切割了。
1、需切割的日志示例
2018-02-24 11:19:23,532 [143] DEBUG performanceTrace 1145 http://api.114995.com:8082/api/Carpool/QueryMatchRoutes 183.205.134.240 null 972533 310000 TITTL00 HUAWEI 860485038452951 3.1.146 HUAWEI 5.1 113.552344 33.332737 发送响应完成 Exception:(null)
2、切割的配置
在logstash 上,使用fifter 的grok 插件进行切割
input { beats { port => "5044" } } filter { grok { match => { "message" => "%{TIMESTAMP_ISO8601:timestamp} [%{NUMBER:thread:int}] %{DATA:level} (?<logger>[a-zA-Z]+) %{NUMBER:executeTime:int} %{URI:url} %{IP:clientip} %{USERNAME:UserName} %{NUMBER:userid:int} %{NUMBER:AreaCode:int} (?<Board>[0-9a-zA-Z]+[-]?[0-9a-zA-Z]+) (?<Brand>[0-9a-zA-Z]+[-]?[0-9a-zA-Z]+) %{NUMBER:DeviceId:int} (?<TerminalSourceVersion>[0-9a-z.]+) %{NUMBER:Sdk:float} %{NUMBER:Lng:float} %{NUMBER:Lat:float} (?<Exception>.*)" } remove_field => "message" } date { match => ["timestamp","dd/MMM/YYYY:H:m:s Z"] remove_field => "timestamp" } geoip { source => "clientip" target => "geoip" database => "/etc/logstash/maxmind/GeoLite2-City.mmdb" } } output { elasticsearch { hosts => ["http://192.168.10.101:9200/"] index => "logstash-%{+YYYY.MM.dd}" document_type => "apache_logs" } }
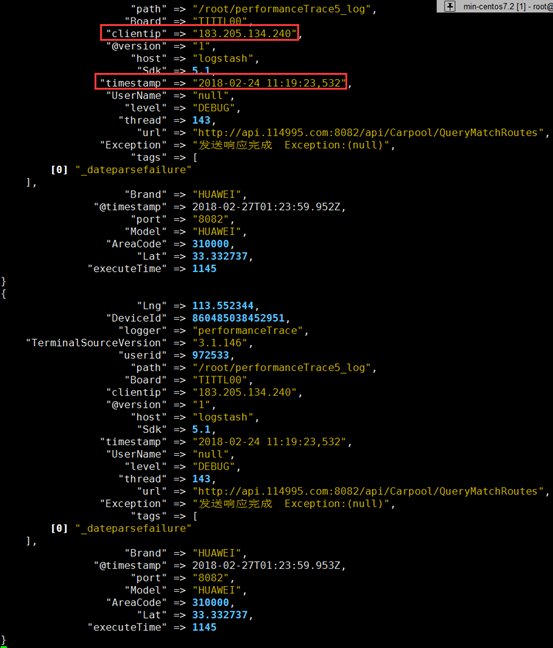
3、切割解析后效果
4、最终kibana 展示效果
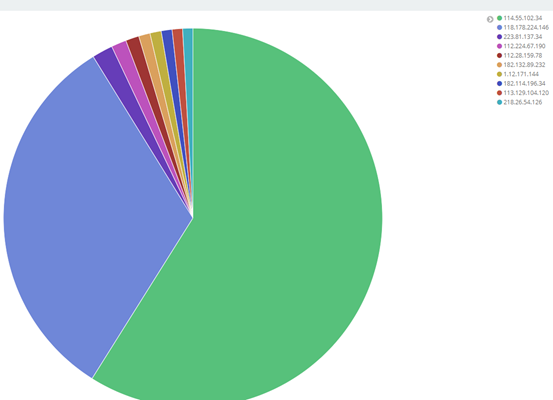
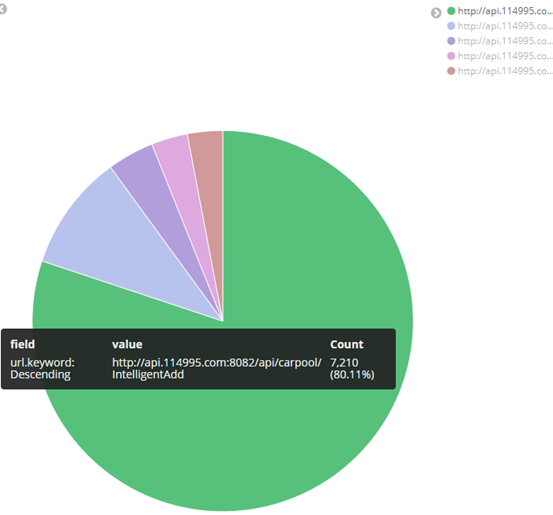
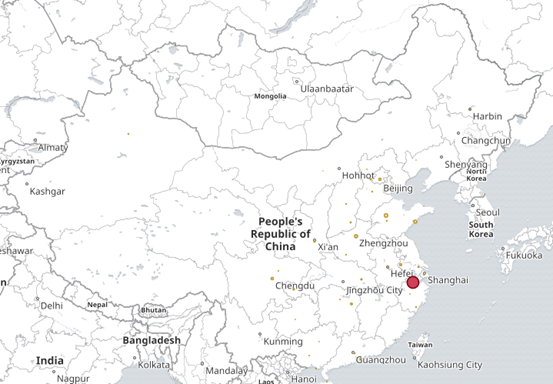
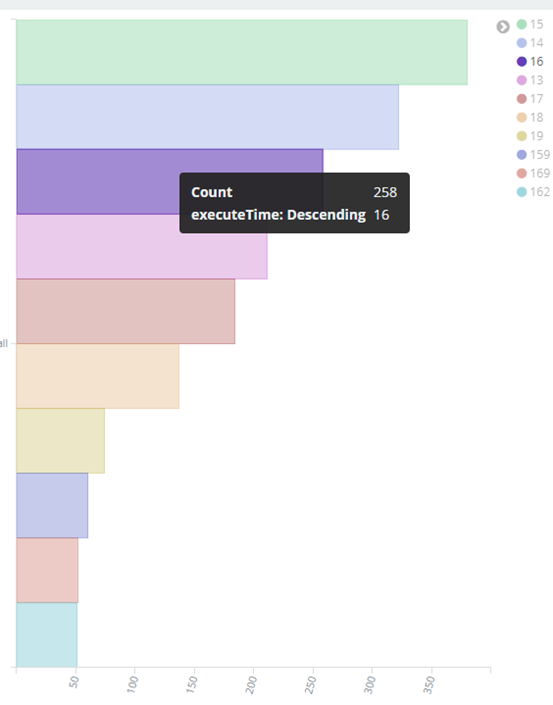
⑥ 其他字段都可进行设置,多种图案,也可将多个图形放在一起展示
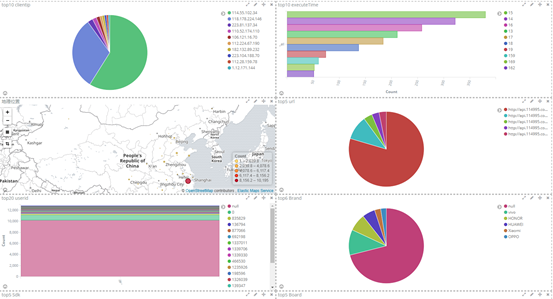
二、grok 用法详解
1、简介
Grok是迄今为止使蹩脚的、无结构的日志结构化和可查询的最好方式。Grok在解析 syslog logs、apache and other webserver logs、mysql logs等任意格式的文件上表现完美。
Grok内置了120多种的正则表达式库,地址:https://github.com/logstash-plugins/logstash-patterns-core/tree/master/patterns。
2、入门例子
55.3.244.1 GET /index.html 15824 0.043
这条日志可切分为5个部分,IP(55.3.244.1)、方法(GET)、请求文件路径(/index.html)、字节数(15824)、访问时长(0.043),对这条日志的解析模式(正则表达式匹配)如下:
%{IP:client} %{WORD:method} %{URIPATHPARAM:request} %{NUMBER:bytes} %{NUMBER:duration}
filter { grok { match => { "message" => "%{IP:client} %{WORD:method} %{URIPATHPARAM:request} %{NUMBER:bytes} %{NUMBER:duration}"} } }
client: 55.3.244.1 method: GET request: /index.html bytes: 15824 duration: 0.043
3、解析任意格式日志
② 对每一块进行分析,如果Grok中正则满足需求,直接拿来用。如果Grok中没用现成的,采用自定义模式。
③ 学会在Grok Debugger中调试。
# less /usr/share/logstash/vendor/bundle/jruby/1.9/gems/logstash-patterns-core-4.1.1/patterns/grok-patterns
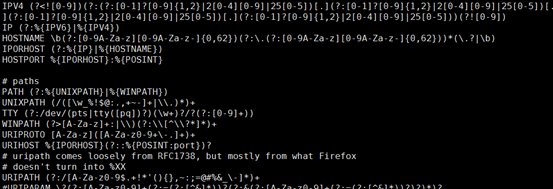
grok_pattern 由零个或多个 %{SYNTAX:SEMANTIC}组成
其中SYNTAX 是表达式的名字,是由grok提供的:例如数字表达式的名字是NUMBER,IP地址表达式的名字是IP
SEMANTIC 表示解析出来的这个字符的名字,由自己定义,例如IP字段的名字可以是 client
使用格式:(?<field_name>the pattern here)
例:(?<Board>[0-9a-zA-Z]+[-]?[0-9a-zA-Z]+)
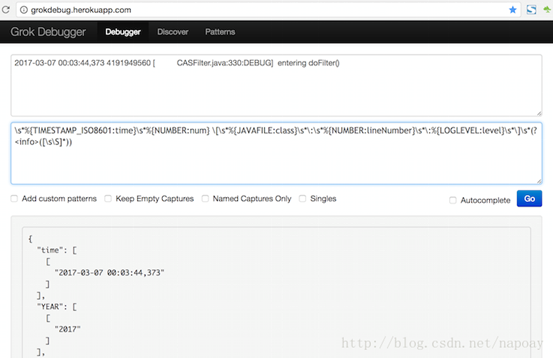
(3)正则解析容易出错,强烈建议使用Grok Debugger调试,姿势如下(我打开这个网页不能用)
三、使用mysql 模块,收集mysql 日志
1、官方文档使用介绍
https://www.elastic.co/guide/en/beats/filebeat/current/filebeat-module-mysql.html
2、配置filebeat ,使用mysql 模块收集mysql 的慢查询
#=========================== Filebeat prospectors =============================
filebeat.modules:
- module: mysql
error:
enabled: true
var.paths: ["/var/log/mariadb/mariadb.log"]
slowlog:
enabled: true
var.paths: ["/var/log/mariadb/mysql-slow.log"]
#----------------------------- Redis output --------------------------------
output.redis:
hosts: ["192.168.10.102"]
password: "ilinux.io"
key: "httpdlogs"
datatype: "list"
db: 0
timeout: 5
3、elk—logstash 切割mysql 的慢查询日志
input { redis { host => "192.168.10.102" port => "6379" password => "ilinux.io" data_type => "list" key => "httpdlogs" threads => 2 } }
filter {
if [fields][type] == "pachongmysql" {
grok {
match => {
"message" => "^# Time: (?<Time>.*)"
}
match => {
"message" => "^# User@Host: (?<User>.*)[exiuapp] @ [%{IP:hostip}] Id: %{NUMBER:Id:int}"
}
match => {
"message" => "^# Query_time: %{NUMBER:Query_time:float} Lock_time: %{NUMBER:Lock_time:float} Rows_sent: %{NUMBER:Rows_sent:int} Rows_examined: %{NUMBER:Rows_examined:int}"
}
match => {
"message" => "^use (?<database>.*)"
}
match => {
"message" => "^SET timestamp=%{NUMBER:timestamp:int};"
}
match => {
"message" => "(?<sql>.*);"
}
remove_field => "message"
}
}
}
output {
elasticsearch { hosts => ["http://192.168.10.101:9200/"] index => "logstash-%{+YYYY.MM.dd}" document_type => "mysql_logs" } }
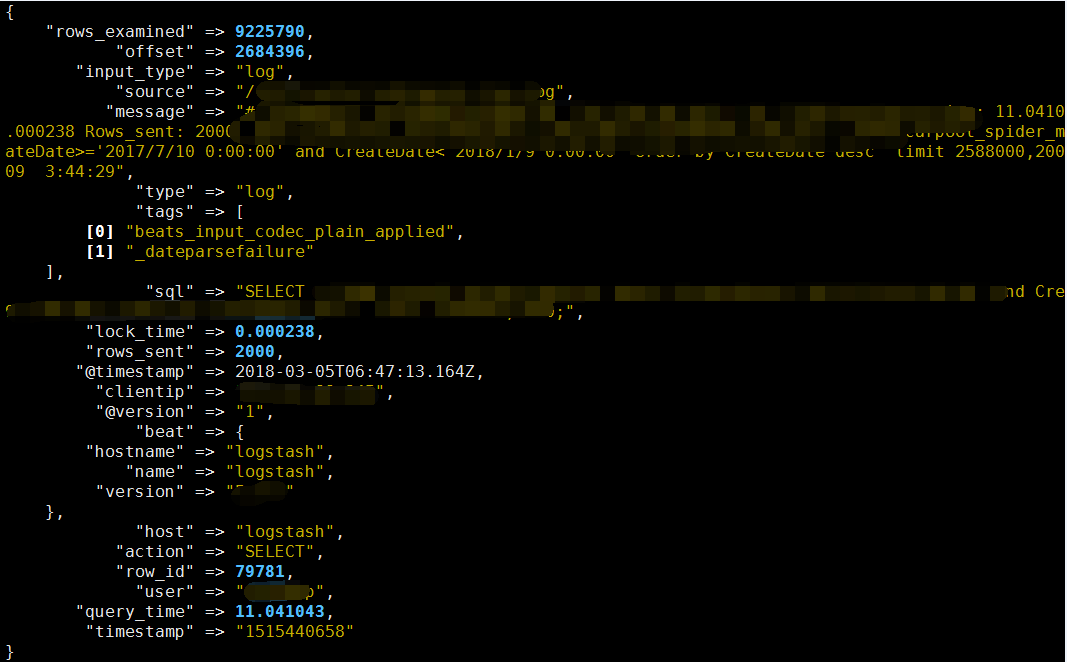
4、kibana 最终显示效果
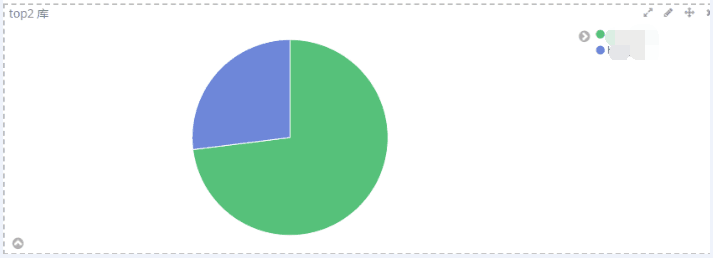
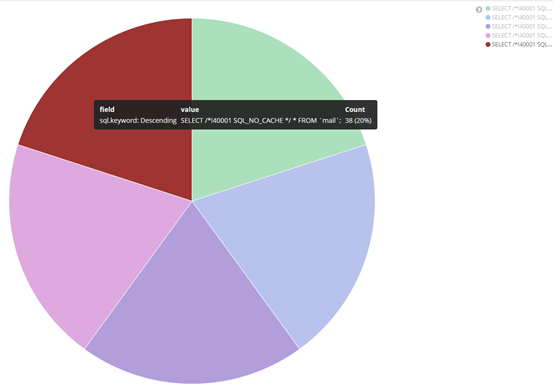
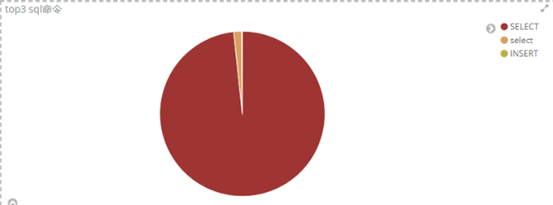
5、使用mysql 模块收集mysql 的慢查询
filter { grok { match => { "message" => "(?<timestamp>d{4}-d{2}-d{2}s+d{2}:d{2}:d{2}) %{NUMBER:pid:int} [%{DATA:level}] (?<content>.*)" } } date { match => ["timestamp","dd/MMM/YYYY:H:m:s Z"] remove_field => "timestamp" } }
四、ELK 收集多实例日志
很多情况下,公司资金不足,不会一对一收集日志;因此,一台logstash 使用多实例收集处理多台agent 的日志很有必要。
1、filebeat 的配置
主要是output 的配置,只需不同agent 指向不同的端口即可
#----------------------------- Logstash output --------------------------------
output.logstash:
# The Logstash hosts
hosts: ["192.168.10.107:5044"]
#----------------------------- Logstash output --------------------------------
output.logstash:
# The Logstash hosts
hosts: ["192.168.10.107:5045"]
2、logstash 的配置
input { beats { port => "5044" } } output { #可以在output 加以区分 elasticsearch { hosts => ["http://192.168.10.107:9200/"] index => "logstash-apache1-%{+YYYY.MM.dd}" document_type => "apache1_logs" } }
input { beats { port => "5045" } } output { #可以在output 加以区分 elasticsearch { hosts => ["http://192.168.10.107:9200/"] index => "logstash-apache2-%{+YYYY.MM.dd}" document_type => "apache2_logs" } }