重新审视RDMA的网络支持
本文为SIGCOMM 2018会议论文。
笔者翻译了该论文。由于时间仓促,且笔者英文能力有限,错误之处在所难免;欢迎读者批评指正。
本文及翻译版本仅用于学习使用。如果有任何不当,请联系笔者删除。
Abstract (摘要)
The advent of RoCE (RDMA over Converged Ethernet) has led to a signifcant increase in the use of RDMA in datacenter networks. To achieve good performance, RoCE requires a lossless network which is in turn achieved by enabling Priority Flow Control (PFC) within the network. However, PFC brings with it a host of problems such as head-of-the-line blocking, congestion spreading, and occasional deadlocks. Rather than seek to fix these issues, we instead ask: is PFC fundamentally required to support RDMA over Ethernet?
RoCE(RDMA over Converged Ethernet,基于融合以太网的RDMA)的出现使得RDMA在数据中心网络中的使用量显着增加。为了获得良好的性能,RoCE要求网络是不丢包网络,这通过在网络中启用优先级流控(Priority Flow Control, PFC)来实现。然而,PFC带来了许多问题,例如队头阻塞、拥塞扩散和偶尔的死锁。 我们不是解决这些问题,而是要询问:为了支持基于以太网上的RDMA,RFC是否是必须的?
We show that the need for PFC is an artifact of current RoCE NIC designs rather than a fundamental requirement. We propose an improved RoCE NIC (IRN) design that makes a few simple changes to the RoCE NIC for better handling of packet losses. We show that IRN (without PFC) outperforms RoCE (with PFC) by 6-83% for typical network scenarios. Thus not only does IRN eliminate the need for PFC, it improves performance in the process! We further show that the changes that IRN introduces can be implemented with modest overheads of about 3-10% to NIC resources. Based on our results, we argue that research and industry should rethink the current trajectory of network support for RDMA.
我们表明,对PFC的需求是当前RoCE NIC设计的一种人为因素,而不是基本要求。我们提出了一种改进的RoCE NIC (IRN)设计,通过对RoCE NIC进行一些简单的更改,以便更好地处理数据包丢失。我们表明,对于典型的网络场景,IRN(没有PFC)优于RoCE(使用PFC) 6-83%。 因此,IRN不仅消除了对PFC的需求,而且还提高了处理过程中的性能!我们进一步表明,IRN引入的更改可以通过大约3-10%的适度NIC资源开销来实现。根据我们的结果,我们认为研究界和工业界应重新考虑当前RDMA的网络支持。
1 Introduction (引言)
Datacenter networks offer higher bandwidth and lower latency than traditional wide-area networks. However, traditional endhost networking stacks, with their high latencies and substantial CPU overhead, have limited the extent to which applications can make use of these characteristics. As a result, several large datacenters have recently adopted RDMA, which bypasses the traditional networking stacks in favor of direct memory accesses.
与传统的广域网相比,数据中心网络具有更高的带宽和更低的延迟。但是,传统的主机端网络协议栈具有高延迟和较大的CPU开销,这限制了应用程序利用数据中心网络高带宽和低延迟特性的程度。因此,最近几个大型数据中心采用了RDMA;RDMA绕过了传统的网络协议栈,采用直接内存访问。
RDMA over Converged Ethernet (RoCE) has emerged as the canonical method for deploying RDMA in Ethernet-based datacenters [23, 38]. The centerpiece of RoCE is a NIC that (i) provides mechanisms for accessing host memory without CPU involvement and (ii) supports very basic network transport functionality. Early experience revealed that RoCE NICs only achieve good end-to-end performance when run over a lossless network, so operators turned to Ethernet’s Priority Flow Control (PFC) mechanism to achieve minimal packet loss. The combination of RoCE and PFC has enabled a wave of datacenter RDMA deployments.
融合以太网上的RDMA(RoCE)已经成为在基于以太网的数据中心中部署RDMA的规范方法[23,38]。RoCE的核心是一个NIC,它(i)提供了在没有CPU参与的情况下访问主机内存的机制,并(ii)支持非常基本的网络传输功能。早期的经验表明,RoCE NIC只有在不丢包网络上运行时才能取得良好的端到端性能,因此运营商转向以太网优先级流控(PFC)机制,以实现最少的数据包丢失。 RoCE和PFC的组合成为数据中心RDMA部署的浪潮。
However, the current solution is not without problems. In particular, PFC adds management complexity and can lead to signifcant performance problems such as head-of-the-line blocking, congestion spreading, and occasional deadlocks [23, 24, 35, 37, 38]. Rather than continue down the current path and address the various problems with PFC, in this paper we take a step back and ask whether it was needed in the first place. To be clear, current RoCE NICs require a lossless fabric for good performance. However, the question we raise is: can the RoCE NIC design be altered so that we no longer need a lossless network fabric?
然而,目前的解决方案仍然存在问题。特别地,PFC增加了管理的复杂性,并可能导致严重的性能问题,如队头阻塞、拥塞传播和偶尔的死锁[23,24,35,37,38]。 与继续沿着当前路径解决PFC的各种问题不同,本文中我们退后一步,询问PFC是否是必须的。 需要明确的是,目前的RoCE NIC需要网络是不丢包的才能获得良好的性能。 但是,我们提出的问题是:RoCE网卡设计是否可以改变,以便我们不再需要不丢包网络?
We answer this question in the affirmative, proposing a new design called IRN (for Improved RoCE NIC) that makes two incremental changes to current RoCE NICs (i) more efficient loss recovery, and (ii) basic end-to-end flow control to bound the number of in-flight packets (§3). We show, via extensive simulations on a RoCE simulator obtained from a commercial NIC vendor, that IRN performs better than current RoCE NICs, and that IRN does not require PFC to achieve high performance; in fact, IRN often performs better without PFC (§4). We detail the extensions to the RDMA protocol that IRN requires (§5) and use comparative analysis and FPGA synthesis to evaluate the overhead that IRN introduces in terms of NIC hardware resources (§6). Our results suggest that adding IRN functionality to current RoCE NICs would add as little as 3-10% overhead in resource consumption, with no deterioration in message rates.
我们肯定地回答了这个问题,提出了一个名为IRN(Improved RoCE NIC,改进的RoCE NIC)的新设计,它对当前的RoCE NIC进行了两个增量式更改(i)更有效的丢包恢复机制,以及(ii)基本的端到端流控(限制飞行中(in-flight)数据包的数量(§3))。 我们在从商用NIC供应商处获得的RoCE仿真器上进行了大量仿真,结果表明IRN的性能优于当前的RoCE NIC,并且IRN不需要PFC来取得高性能。实际上,IRN在没有PFC的情况下通常表现更好(§4)。 我们详细介绍了IRN要求的对RDMA协议的扩展(§5),并使用比较分析和FPGA综合来评估IRN在NIC硬件资源方面引入的开销(§6)。我们的结果表明,在当前的RoCE网卡中添加IRN功能会增加3-10%的资源开销,而不会降低消息速率。
A natural question that arises is how IRN compares to iWARP? iWARP [33] long ago proposed a similar philosophy as IRN: handling packet losses efficiently in the NIC rather than making the network lossless. What we show is that iWARP’s failing was in its design choices. The differences between iWARP and IRN designs stem from their starting points: iWARP aimed for full generality which led them to put the full TCP/IP stack on the NIC, requiring multiple layers of translation between RDMA abstractions and traditional TCP bytestream abstractions. As a result, iWARP NICs are typically far more complex than RoCE ones, with higher cost and lower performance (§2). In contrast, IRN starts with the much simpler design of RoCE and asks what minimal features can be added to eliminate the need for PFC.
一个明显的问题是与iWARP比较,IRN如何?很久以前,iWARP [33]提出了与IRN类似的哲学:在NIC中有效地处理数据包丢失而不是使网络不丢包。我们表明iWARP的失败之处在于它的设计选择。iWARP和IRN设计之间的差异源于他们的出发点:iWARP旨在实现全面的通用性,这使得他们将完整的TCP/IP协议栈实现于NIC中,需要在RDMA抽象和传统的TCP字节流抽象之间进行多层转换。 因此,iWARP NIC通常比RoCE更复杂、成本更高,且性能更低(§2)。相比之下,IRN从更简单的RoCE设计开始,并询问可以通过添加哪些最小功能以消除对PFC的需求。
More generally: while the merits of iWARP vs. RoCE has been a long-running debate in industry, there is no conclusive or rigorous evaluation that compares the two architectures. Instead, RoCE has emerged as the de-facto winner in the marketplace, and brought with it the implicit (and still lingering) assumption that a lossless fabric is necessary to achieve RoCE’s high performance. Our results are the first to rigorously show that, counter to what market adoption might suggest, iWARP in fact had the right architectural philosophy, although a needlessly complex design approach.
更一般地说:虽然iWARP与RoCE的优点一直是业界长期争论的问题,但没有比较两种架构的结论性或严格的评估。相反,RoCE已成为市场上事实上的赢家,并带来了隐含(并且仍然挥之不去)的假设,即不丢包网络是实现RoCE高性能所必需的。我们的结果是第一个严格表明(与市场采用建议相反),尽管具有一种不必要的复杂设计方法,iWARP实际上具有正确的架构理念。
Hence, one might view IRN and our results in one of two ways: (i) a new design for RoCE NICs which, at the cost of a few incremental modifcations, eliminates the need for PFC and leads to better performance, or, (ii) a new incarnation of the iWARP philosophy which is simpler in implementation and faster in performance.
因此,可以通过以下两种方式之一来审视IRN和我们的结果:(i)RoCE NIC的新设计,以少量增量修改为代价,消除了对PFC的需求并导致更好的性能,或者,(ii)iWARP理念的新实现,其实现更简单,性能更好。
2 Background (背景)
We begin with reviewing some relevant background.
我们以回顾一些相关背景开始。
2.1 Infiniband RDMA and RoCE (Infiniband RDMA和ROCE)
RDMA has long been used by the HPC community in special-purpose Infniband clusters that use credit-based flow control to make the network lossless [4]. Because packet drops are rare in such clusters, the RDMA Infiniband transport (as implemented on the NIC) was not designed to efficiently recover from packet losses. When the receiver receives an out-of-order packet, it simply discards it and sends a negative acknowledgement (NACK) to the sender. When the sender sees a NACK, it retransmits all packets that were sent after the last acknowledged packet (i.e., it performs a go-back-N retransmission).
长期以来,HPC(高性能计算)社区一直在特定用途的Infiniband集群中使用RDMA,这些集群使用基于信用的流控制来使网络不丢包[4]。由于数据包丢失在此类群集中很少见,因此RDMA Infiniband传输层(在NIC上实现)并非旨在高效恢复数据包丢失。 当接收方收到无序数据包时,它只是丢弃该数据包并向发送方发送否定确认(NACK)。当发送方看到NACK时,它重新发送在最后一个确认的数据包之后发送的所有数据包(即,它执行回退N重传)。
To take advantage of the widespread use of Ethernet in datacenters, RoCE [5, 9] was introduced to enable the use of RDMA over Ethernet. RoCE adopted the same Infiniband transport design (including go-back-N loss recovery), and the network was made lossless using PFC.
为了利用以太网在数据中心中的广泛使用的优势,引入了RoCE [5,9],以便在以太网上使用RDMA(我们对RoCE [5]及其后继者RoCEv2 [9]使用术语RoCE,RoCEv2使得RDMA不仅可以通过以太网运行,还可以运行在IP路由网络。)。RoCE采用了相同的Infiniband传输层设计(包括回退N重传),并且使用PFC使网络不丢包。
2.2 Priority Flow Control (优先级流控)
Priority Flow Control (PFC) [6] is Ethernet’s flow control mechanism, in which a switch sends a pause (or X-OFF) frame to the upstream entity (a switch or a NIC), when the queue exceeds a certain confgured threshold. When the queue drains below this threshold, an X-ON frame is sent to resume transmission. When confgured correctly, PFC makes the network lossless (as long as all network elements remain functioning). However, this coarse reaction to congestion is agnostic to which flows are causing it and this results in various performance issues that have been documented in numerous papers in recent years [23, 24, 35, 37, 38]. These issues range from mild (e.g., unfairness and head-of-line blocking) to severe, such as “pause spreading” as highlighted in [23] and even network deadlocks [24, 35, 37]. In an attempt to mitigate these issues, congestion control mechanisms have been proposed for RoCE (e.g., DCQCN [38] and Timely [29]) which reduce the sending rate on detecting congestion, but are not enough to eradicate the need for PFC. Hence, there is now a broad agreement that PFC makes networks harder to understand and manage, and can lead to myriad performance problems that need to be dealt with.
优先级流控(PFC)[6]是以太网的流量控制机制,当队列超过某个特定的配置阈值时,交换机会向上游实体(交换机或NIC)发送暂停(或X-OFF)帧。当队列低于此阈值时,将发送X-ON帧以恢复传输。正确配置后,PFC使网络不丢包(只要所有网络元素保持正常运行)。然而,这种对拥堵的粗略反应对哪些流导致拥塞是不可知的,这导致了近年来在许多论文中记载的各种性能问题[23,24,35,37,38]。这些问题的范围从轻微(例如,不公平和线头阻塞)到严重(例如[23]中突出显示的“暂停传播”),甚至是网络死锁[24,35,37]。为了缓解这些问题,已经为RoCE提出了拥塞控制机制(例如,DCQCN [38]和Timely [29]),其降低了拥塞时的发送速率,但是不足以消除对PFC的需求。因此,现在普遍认为PFC使网络更难理解和管理,并且可能导致需要处理的无数性能问题。
2.3 iWARP vs RoCE (iWARP对比RoCE )
iWARP [33] was designed to support RDMA over a fully general (i.e., not loss-free) network. iWARP implements the entire TCP stack in hardware along with multiple other layers that it needs to translate TCP’s byte stream semantics to RDMA segments. Early in our work, we engaged with multiple NIC vendors and datacenter operators in an attempt to understand why iWARP was not more broadly adopted (since we believed the basic architectural premise underlying iWARP was correct). The consistent response we heard was that iWARP is signifcantly more complex and expensive than RoCE, with inferior performance [13].
iWARP [33]旨在通过完全通用(即非不丢包网络)网络支持RDMA。iWARP在硬件中实现了整个TCP栈以及将TCP的字节流语义转换为RDMA分段所需的多个其他层。 在我们的早期工作中,我们与多家NIC供应商和数据中心运营商合作,试图了解为什么iWARP没有得到更广泛的采用(因为我们认为iWARP的基本架构前提是正确的)。我们听到的一致反应是iWARP明显比RoCE更复杂和昂贵,性能较差[13]。
We also looked for empirical datapoints to validate or refute these claims. We ran RDMA Write benchmarks on two machines connected to one another, using Chelsio T-580-CR 40Gbps iWARP NICs on both machines for one set of experiments, and Mellanox MCX416A-BCAT 56Gbps RoCE NICs (with link speed set to 40Gbps) for another. Both NICs had similar specifcations, and at the time of purchase, the iWARP NIC cost $760, while the RoCE NIC cost $420. Raw NIC performance values for 64 bytes batched Writes on a single queue-pair are reported in Table 1. We fnd that iWARP has 3× higher latency and 4× lower throughput than RoCE.

我们还寻找经验数据点以验证或驳斥这些观点。我们在两台相互连接的机器上运行RDMA写入基准测试,两台机器上的Chelsio T-580-CR 40Gbps iWARP网卡用于一组实验,Mellanox MCX416A-BCAT 56Gbps RoCE网卡(链路速度设置为40Gbps)用于另一组实验。两个NIC的规格类似,在购买时,iWARP NIC售价760美元,而RoCE NIC售价420美元。表1中给出了单个队列对上64字节批量写入的原始NIC性能值。我们发现iWARP的延迟比RoCE高3倍,吞吐量低4倍。
| NIC | 吞吐量 | 延迟 |
| Chelsio T-580-CR (iWARP) | 3.24 Mpps | 2.89 us |
| Mellanox MCX416A-BCAT (RoCE) | 14.7 Mpps | 0.94 us |
These price and performance differences could be attributed to many factors other than transport design complexity (such as differences in profit margins, supported features and engineering effort) and hence should be viewed as anecdotal evidence as best. Nonetheless, they show that our conjecture (in favor of implementing loss recovery at the endhost NIC) was certainly not obvious based on current iWARP NICs.
这些价格和性能差异可归因于除运输层设计复杂性之外的许多因素(例如,利润率差异、支持的特征和工程效率),因此应被视为最佳的轶事证据。尽管如此,他们表明:基于当前的iWARP NIC,我们的猜想(支持在终端主机NIC上实现丢包恢复)肯定是不明显的。
Our primary contribution is to show that iWARP, somewhat surprisingly, did in fact have the right philosophy: explicitly handling packet losses in the NIC leads to better performance than having a lossless network. However, efficiently handling packet loss does not require implementing the entire TCP stack in hardware as iWARP did. Instead, we identify the incremental changes to be made to current RoCE NICs, leading to a design which (i) does not require PFC yet achieves better network-wide performance than both RoCE and iWARP (§4), and (ii) is much closer to RoCE’s implementation with respect to both NIC performance and complexity (§6) and is thus signifcantly less complex than iWARP.
我们的主要贡献是表明iWARP实际上确实具有正确的理念(尽管有些惊讶):在NIC中显式处理数据包丢失导致比不丢包网络更好的性能。但是,有效地处理数据包丢失并不需要像iWARP那样在硬件中实现整个TCP栈。相反,我们确定了对当前RoCE NIC进行的增量更改,从而导致一种设计(i)不需要PFC,但取得比RoCE和iWARP(§4)更好的网络范围性能,并且(ii)就NIC性能和复杂度而言,更接近于RoCE的实现(§6),因此复杂度比iWARP显著简化。
3 IRN Design (IRN设计)
We begin with describing the transport logic for IRN. For simplicity, we present it as a general design independent of the specific RDMA operation types. We go into the details of handling specific RDMA operations with IRN later in §5.
我们首先描述IRN的传输层逻辑。 为了简单起见,我们将其作为一种独立于特定RDMA操作类型的通用设计。我们将在§5中详细介绍如何使用IRN处理特定的RDMA操作。
Changes to the RoCE transport design may introduce overheads in the form of new hardware logic or additional perflow state. With the goal of keeping such overheads as small as possible, IRN strives to make minimal changes to the RoCE NIC design in order to eliminate its PFC requirement, as opposed to squeezing out the best possible performance with a more sophisticated design (we evaluate the small overhead introduced by IRN later in §6).
对RoCE传输设计的更改可能会以新硬件逻辑或额外的每个流状态的形式引入开销。为了尽可能减少这种开销,IRN努力对RoCE NIC设计进行微小的更改,以消除其PFC要求,而不是通过更复杂的设计来挤出最佳性能(我们在§6评估 IRN引入的小开销)。
IRN, therefore, makes two key changes to current RoCE NICs, as described in the following subsections: (1) improving the loss recovery mechanism, and (2) basic end-to-end flow control (termed BDP-FC) which bounds the number of in-flight packets by the bandwidth-delay product of the network. We justify these changes by empirically evaluating their signifcance, and exploring some alternative design choices later in §4.3. Note that these changes are orthogonal to the use of explicit congestion control mechanisms (such as DCQCN [38] and Timely [29]) that, as with current RoCE NICs, can be optionally enabled with IRN.
因此,IRN对当前的RoCE NIC进行了两个关键更改,如以下小节所述:(1)改进丢包恢复机制,以及(2)基本的端到端流控(称为BDP-FC),它通过网络的带宽-延迟积限制了 网络中数据包数量。 我们通过实证评估它们的重要性来证明这些变化,并在§4.3中探索一些替代设计选择。 请注意,这些更改与使用显式拥塞控制机制(例如DCQCN [38]和Timely [29])正交,与当前的RoCE NIC一样,可以在IRN选择启用它们。
3.1 IRN’s Loss Recovery Mechanism (IRN丢包恢复机制)
As discussed in §2, current RoCE NICs use a go-back-N loss recovery scheme. In the absence of PFC, redundant retransmissions caused by go-back-N loss recovery result in signifcant performance penalties (as evaluated in §4). Therefore, the first change we make with IRN is a more efficient loss recovery, based on selective retransmission (inspired by TCP’s loss recovery), where the receiver does not discard out of order packets and the sender selectively retransmits the lost packets, as detailed below.
如§2中所述,当前的RoCE NIC使用回退N丢包恢复方案。 在没有PFC的情况下,由回退N丢包恢复引起的冗余重传导致显着的性能损失(如§4中所评估的)。因此,我们使用IRN进行的第一个更改是基于选择性重传(受TCP的丢包恢复启发)的更有效的丢失恢复,其中接收方不丢弃无序数据包,并且发送方选择性地重传丢失的数据包,如下所述。
Upon every out-of-order packet arrival, an IRN receiver sends a NACK, which carries both the cumulative acknowledgment (indicating its expected sequence number) and the sequence number of the packet that triggered the NACK (as a simplifed form of selective acknowledgement or SACK).
在每个乱序数据包到达时,IRN接收方发送NACK,其携带累积确认(指示其预期序列号)和触发NACK的数据包的序列号(作为选择性确认或SACK的简化形式)。
An IRN sender enters loss recovery mode when a NACK is received or when a timeout occurs. It also maintains a bitmap to track which packets have been cumulatively and selectively acknowledged. When in the loss recovery mode, the sender selectively retransmits lost packets as indicated by the bitmap, instead of sending new packets. The first packet that is retransmitted on entering loss recovery corresponds to the cumulative acknowledgement value. Any subsequent packet is considered lost only if another packet with a higher sequence number has been selectively acked. When there are no more lost packets to be retransmitted, the sender continues to transmit new packets (if allowed by BDP-FC). It exits loss recovery when a cumulative acknowledgement greater than the recovery sequence is received, where the recovery sequence corresponds to the last regular packet that was sent before the retransmission of a lost packet.
当收到NACK或发生超时时,IRN发送方进入丢包恢复模式。它还维护一个位图,以跟踪哪些数据包已被累积并有选择地确认。当处于丢失恢复模式时,发送方选择性地重新发送丢失的数据包(根据位图信息),而不是发送新的数据包。 在进入丢失恢复时重新发送的第一个数据包对应于累积确认值。 只有在选择性地确认了具有更高序列号的另一个数据包时,才认为后续数据包丢失了。 当没有更多丢失的数据包要重新传输时,发送方继续传输新数据包(如果BDP-FC允许)。 当接收到大于恢复序列号的累积确认时,它退出丢包恢复模式,其中恢复序列号对应于在重传丢失分组之前发送的最后一个常规分组。
SACKs allow efficient loss recovery only when there are multiple packets in flight. For other cases (e.g., for single packet messages), loss recovery gets triggered via timeouts. A high timeout value can increase the tail latency of such short messages. However, keeping the timeout value too small can result in too many spurious retransmissions, affecting the overall results. An IRN sender, therefore, uses a low timeout value of RTOlow only when there are a small N number of packets in flight (such that spurious retransmissions remains negligibly small), and a higher value of RTOhigh otherwise. We discuss how the values of these parameters are set in §4, and how the timeout feature in current RoCE NICs can be easily extended to support this in §6.
只有在有多个飞行中数据包时,SACK才能实现有效的丢包恢复。 对于其他情况(例如,对于单个数据包消息),通过超时触发丢包恢复。 高超时值可能会增加此类短消息的尾部延迟。 但是,保持太小的超时值会导致过多的虚假重传,从而影响整体结果。 因此,IRN发送方仅在存在少量N个飞行中数据包时使用RTOlow的低超时值(使得虚假重传较小且可忽略),否则使用较高的RTOhigh值。 我们将在§4中讨论如何设置这些参数的值,以及在§6中讨论如何轻松扩展当前RoCE NIC中的超时功能以支持此功能。
3.2 IRN’s BDP-FC Mechanism (IRN的BDP-FC机制)
The second change we make with IRN is introducing the notion of a basic end-to-end packet level flow control, called BDP-FC, which bounds the number of outstanding packets in flight for a flow by the bandwidth-delay product (BDP) of the network, as suggested in [17]. This is a static cap that we compute by dividing the BDP of the longest path in the network (in bytes) with the packet MTU set by the RDMA queue-pair (typically 1KB in RoCE NICs). An IRN sender transmits a new packet only if the number of packets in flight (computed as the difference between current packet’s sequence number and last acknowledged sequence number) is less than this BDP cap.
我们对IRN做出的第二个改变是引入了一个基本的端到端数据包级流控的概念,称为BDP-FC,它通过网络的带宽延迟乘(BDP)限制数据流的飞行中数据包的数量, 如[17]中所建议的。 这是一个静态上限,我们通过将网络中最长路径的BDP(以字节为单位)除以RDMA队列对设置的数据包MTU(在RoCE网卡中通常为1KB)来计算。 只有当飞行中的数据包数量(按当前数据包的序列号和最后确认的序列号之间的差异计算)小于此BDP上限时,IRN发送方才会发送新数据包。
BDP-FC improves the performance by reducing unnecessary queuing in the network. Furthermore, by strictly upper bounding the number of out-of-order packet arrivals, it greatly reduces the amount of state required for tracking packet losses in the NICs (discussed in more details in §6).
BDP-FC通过减少网络中不必要的排队来提高性能。 此外,通过严格限制乱序数据包到达的数量,它大大减少了跟踪NIC中数据包丢失所需的状态量(在第6节中有更详细的讨论)。
As mentioned before, IRN’s loss recovery has been inspired by TCP’s loss recovery. However, rather than incorporating the entire TCP stack as is done by iWARP NICs, IRN: (1) decouples loss recovery from congestion control and does not incorporate any notion of TCP congestion window control involving slow start, AIMD or advanced fast recovery, (2) operates directly on RDMA segments instead of using TCP’s byte stream abstraction, which not only avoids the complexity introduced by multiple translation layers (as needed in iWARP), but also allows IRN to simplify its selective acknowledgement and loss tracking schemes. We discuss how these changes effect performance towards the end of §4.
如前所述,IRN的丢包恢复受到了TCP丢包恢复的启发。 但是,IRN不是像iWARP网卡那样整合整个TCP栈,而是:(1)将丢包恢复与拥塞控制解耦,并且不包含涉及慢启动、AIMD或高级快速恢复的TCP拥塞窗口控制的任何概念(2)直接在RDMA分段上运行,而不是使用TCP的字节流抽象,这不仅避免了多个转换层引入的复杂性(在iWARP中需要),而且还允许IRN简化其选择性确认和丢包跟踪方案。 我们将在§4结束时讨论这些变化如何影响性能。
4 Evaluating IRN’s Transport Logic (评估IRN的传输层逻辑)
We now confront the central question of this paper: Does RDMA require a lossless network? If the answer is yes, then we must address the many difculties of PFC. If the answer is no, then we can greatly simplify network management by letting go of PFC. To answer this question, we evaluate the network-wide performance of IRN’s transport logic via extensive simulations. Our results show that IRN performs better than RoCE, without requiring PFC. We test this across a wide variety of experimental scenarios and across different performance metrics. We end this section with a simulation-based comparison of IRN with Resilient RoCE [34] and iWARP [33].
我们现在面对本文的核心问题:RDMA是否需要不丢包网络? 如果答案是肯定的,那么我们必须解决PFC的诸多难题。 如果答案是否定的,那么我们可以通过放弃PFC来大大简化网络管理。 为了回答这个问题,我们通过大量的模拟评估了IRN传输层逻辑的网络性能。 我们的结果表明IRN比RoCE表现更好,并且不需要PFC。 我们在各种实验场景和不同的性能指标中对此进行了测试。 我们以IRN与弹性RoCE [34]和iWARP [33]的模拟比较结束本节。
4.1 Experimental Settings (实验设置)
We begin with describing our experimental settings.
我们首先介绍实验设置。
Simulator: Our simulator, obtained from a commercial NIC vendor, extends INET/OMNET++ [1, 2] to model the Mellanox ConnectX4 RoCE NIC [10]. RDMA queue-pairs (QPs) are modelled as UDP applications with either RoCE or IRN transport layer logic, that generate flows (as described later). We define a flow as a unit of data transfer comprising of one or more messages between the same source-destination pair as in [29, 38]. When the sender QP is ready to transmit data packets, it periodically polls the MAC layer until the link is available for transmission. The simulator implements DCQCN as implemented in the Mellanox ConnectX-4 ROCE NIC [34], and we add support for a NIC-based Timely implementation. All switches in our simulation are input-queued with virtual output ports, that are scheduled using round-robin. The switches can be confgured to generate PFC frames by setting appropriate buffer thresholds.
模拟器:我们的模拟器,从某个商业NIC供应商处获得,其扩展了INET/OMNET++ [1,2],以模拟Mellanox ConnectX4 RoCE NIC [10]。 RDMA队列对(QP)被建模为具有RoCE或IRN传输层逻辑的UDP应用,其生成数据流(如稍后所述)。我们将数据流定义为数据传输单元,包括与[29,38]中相同的源-目的地对之间的一个或多个消息。 当发送方QP准备好发送数据包时,它会周期性地轮询MAC层,直到链路可用于传输。 模拟器实现了在Mellanox ConnectX-4 ROCE NIC [34]中实现的DCQCN,并且我们添加了对基于NIC的Timely实现的支持。 我们模拟中的所有交换机都使用虚拟输出端口的输入端口排队机制,使用循环调度。 通过设置适当的缓冲阈值,可以配置交换机以生成PFC帧。
Default Case Scenario: For our default case, we simulate a 54-server three-tiered fat-tree topology, connected by a fabric with full bisection-bandwidth constructed from 45 6-port switches organized into 6 pods [16]. We consider 40Gbps links, each with a propagation delay of 2µs, resulting in a bandwidth-delay product (BDP) of 120KB along the longest (6-hop) path. This corresponds to ∼110 MTU-sized packets (assuming typical RDMA MTU of 1KB).
默认情景:对于我们的默认情景,我们模拟一个由54台服务器构成的三层胖树拓扑,由一个45个6端口交换机构成网络设施连接,具有完整的折半带宽,组成6个pod[16]。 我们考虑40Gbps链路,每个链路的传播延迟为2μs,导致沿最长(6跳)路径的带宽延迟乘(BDP)为120KB(笔者注:40Gbps*2us*6*2=120KB,最后一个乘2的原因是BDP计算的往返时间)。 这相当于约110个MTU大小的数据包(假设典型的RDMA MTU为1KB)。
Each end host generates new flows with Poisson interarrival times [17, 30]. Each flow’s destination is picked randomly and size is drawn from a realistic heavy-tailed distribution derived from [19]. Most flows are small (50% of the flows are single packet messages with sizes ranging between 32 bytes-1KB representing small RPCs such as those generated by RDMA based key-value stores [21, 25]), and most of the bytes are in large flows (15% of the flows are between 200KB-3MB, representing background RDMA trafc such as storage). The network load is set at 70% utilization for our default case. We use ECMP for load-balancing [23]. We vary different aspects from our default scenario (including topology size, workload pattern and link utilization) in §4.4.
每个终端主机产生具有Poisson到达时间的新数据流[17,30]。 每个数据流的目的地都是随机挑选的,大小来自[19]的现实重尾分布。大多数流量很小(50%的数据流是单个数据包消息,大小介于32字节-1KB之间,表示小型RPC,例如基于RDMA的键值存储生成的那些[21,25]),大多数字节都在大数据流中(15%的数据流在200KB-3MB之间,代表背景RDMA数据流,如存储)。对于我们的默认情景,网络负载设置为70%利用率。 我们使用ECMP进行负载平衡[23]。 我们在§4.4中的改变默认方案(包括拓扑大小,工作负载模式和链路利用率)的不同方面。
Parameters: RTOhigh is set to an estimation of the maximum round trip time with one congested link. We compute this as the sum of the propagation delay on the longest path and the maximum queuing delay a packet would see if the switch buffer on a congested link is completely full. This is approximately 320µs for our default case. For IRN, we set RTOlow to 100µs (representing the desirable upper-bound on tail latency for short messages) with N set to a small value of 3. When using RoCE without PFC, we use a fixed timeout value of RTOhigh. We disable timeouts when PFC is enabled to prevent spurious retransmissions. We use buffers sized at twice the BDP of the network (which is 240KB in our default case) for each input port [17, 18]. The PFC threshold at the switches is set to the buffer size minus a headroom equal to the upstream link’s bandwidth-delay product (needed to absorb all packets in flight along the link). This is 220KB for our default case. We vary these parameters in §4.4 to show that our results are not very sensitive to these specifc choices. When using RoCE or IRN with Timely or DCQCN, we use the same congestion control parameters as specifed in [29] and [38] respectively. For fair comparison with PFC-based proposals [37, 38], the flow starts at line-rate for all cases.
参数:RTOhigh设置为具有一条拥塞链路的估计最大往返时间。我们将其计算为最长路径上的传播延迟与数据包在拥塞链路上的交换机完全满时所经历的最大排队延迟之和。对于我们的默认情况,这大约是320μs。对于IRN,我们将RTOlow设置为100μs(表示短消息的尾部延迟的期望上限),其中N设置为较小的值3。当使用不带PFC的RoCE时,我们使用固定超时值RTOhigh。我们在启用PFC时禁用超时以防止虚假重传。对于每个输入端口,我们使用大小为网络BDP两倍的缓冲区(在默认情况下为240KB)[17,18]。交换机的PFC阈值设置为缓冲区大小减去净空间(等于上游链路的带宽延迟乘,需要吸收沿链路上飞行中的所有数据包)。对于我们的默认情况,这是220KB。我们在§4.4中改变这些参数,以表明我们的结果对这些特定选择不是非常敏感。当使用具有Timely或DCQCN的RoCE或IRN时,我们分别使用与[29]和[38]中指定的相同的拥塞控制参数。为了与基于PFC的方案进行公平比较[37,38],所有情形下数据流均从线速开始。
Metrics: We primarily look at three metrics: (i) average slowdown, where slowdown for a flow is its completion time divided by the time it would have taken to traverse its path at line rate in an empty network, (ii) average flow completion time (FCT), (iii) 99%ile or tail FCT. While the average and tail FCTs are dominated by the performance of throughput-sensitive flows, the average slowdown is dominated by the performance of latency-sensitive short flows.
度量标准:我们主要考虑三个指标:(i)平均放缓,其中数据流的放缓是其完成时间除以在空网络中以线速穿越其路径所花费的时间,(ii)平均流完成时间(FCT),(iii)99%ile或尾部FCT。 虽然平均和尾部FCT主要受吞吐量敏感性数据流的影响,但平均减速主要受延迟敏感性短流的影响。
4.2 Basic Results (基础结果)
We now present our basic results comparing IRN and RoCE for our default scenario. Unless otherwise specified, IRN is always used without PFC, while RoCE is always used with PFC for the results presented here.
我们现在提供我们的基本结果,比较IRN和RoCE的默认情况。 除非另有说明,IRN始终在没有PFC的情况下使用,而RoCE始终与PFC一起使用。
4.2.1 IRN performs better than RoCE. We begin with comparing IRN’s performance with current RoCE NIC’s. The results are shown in Figure 1. IRN’s performance is up to 2.8-3.7× better than RoCE across the three metrics. This is due to the combination of two factors: (i) IRN’s BDP-FC mechanism reduces unnecessary queuing and (ii) unlike RoCE, IRN does not experience any congestion spreading issues, since it does not use PFC. (explained in more details below).
4.2.1 IRN比RoCE表现更好。 我们首先将IRN的性能与当前的RoCE NIC进行比较。 结果如图1所示。在三个指标中,IRN的性能比RoCE高2.8-3.7倍。这是由于两个因素的综合作用:(i)IRN的BDP-FC机制减少了不必要的排队;(ii)与RoCE不同,IRN不会遇到任何拥塞传播问题,因为它不使用PFC。 (在下面更详细地解释)。
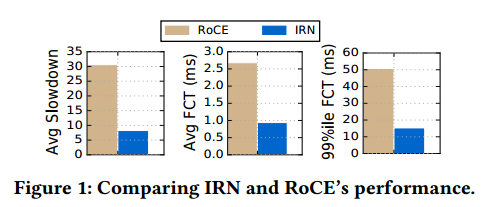
图1:比较IRN和RoCE的性能。
4.2.2 IRN does not require PFC. We next study how IRN’s performance is impacted by enabling PFC. If enabling PFC with IRN does not improve performance, we can conclude that IRN’s loss recovery is sufficient to eliminate the requirement for PFC. However, if enabling PFC with IRN signifcantly improves performance, we would have to conclude that PFC continues to be important, even with IRN’s loss recovery. Figure 2 shows the results of this comparison. Remarkably, we find that not only is PFC not required, but it signifcantly degrades IRN’s performance (increasing the value of each metric by about 1.5-2×). This is because of the head-of-the-line blocking and congestion spreading issues PFC is notorious for: pauses triggered by congestion at one link, cause queue build up and pauses at other upstream entities, creating a cascading effect. Note that, without PFC, IRN experiences significantly high packet drops (8.5%), which also have a negative impact on performance, since it takes about one round trip time to detect a packet loss and another round trip time to recover from it. However, the negative impact of a packet drop (given efficient loss recovery), is restricted to the flow that faces congestion and does not spread to other flows, as in the case of PFC. While these PFC issues have been observed before [23, 29, 38], we believe our work is the first to show that a well-design loss-recovery mechanism outweighs a lossless network.
4.2.2 IRN不需要PFC。我们接下来研究启用PFC如何影响IRN的性能。如果启用PFC不会使IRN的性能提高,我们可以得出结论,IRN的丢包恢复足以消除对PFC的要求。但是,如果启用PFC可以显着提高IRN的性能,我们必须得出结论,即使使用IRN的丢包恢复机制,PFC仍然很重要。图2显示了这种比较的结果。值得注意的是,我们认为不仅不需要PFC,而且它还会显着降低IRN的性能(将每个指标的值增加约1.5-2倍)。这是因为PFC的臭名昭着的线头阻塞和拥塞扩散问题:一条链路上的拥塞引发的暂停,导致队列建立并暂停其他上游实体,从而产生级联效应。请注意,如果没有PFC,IRN会经历显著较高的数据包丢失(8.5%),这也会对性能产生负面影响,因为它需要大约一个往返时间来检测数据包丢失以及另一个往返时间以恢复丢包。然而,数据包丢失的负面影响(考虑有效的丢包恢复机制)仅限于经历拥塞的数据流,并且不会扩散到其它数据流(如PFC的情况)。虽然在[23,29,38]已经观察到这些PFC问题,但我们认为我们的工作首次表明设计良好的丢包恢复机制优于不丢包网络。
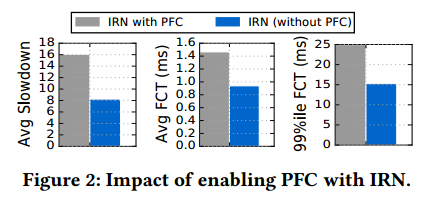
图2: 使能RFC对IRN的影响。
4.2.3 RoCE requires PFC. Given the above results, the next question one might have is whether RoCE required PFC in the first place? Figure 3 shows the performance of RoCE with and without PFC. We fnd that the use of PFC helps considerably here. Disabling PFC degrades performance by 1.5-3× across the three metrics. This is because of the go-back-N loss recovery used by current RoCE NICs, which penalizes performance due to (i) increased congestion caused by redundant retransmissions and (ii) the time and bandwidth wasted by flows in sending these redundant packets.
4.2.3 RoCE需要PFC。 鉴于上述结果,下一个可能的问题是RoCE是否需要PFC? 图3显示了使用和不使用PFC的RoCE的性能。 我们认为PFC的使用在这里有很大帮助。 禁用PFC会使三个指标的性能降低1.5-3倍。 这是因为当前RoCE NIC使用的返回N损失恢复,由于(i)由冗余重传引起的拥塞增加以及(ii)发送这些冗余分组时所浪费的时间和带宽,这会损害性能。
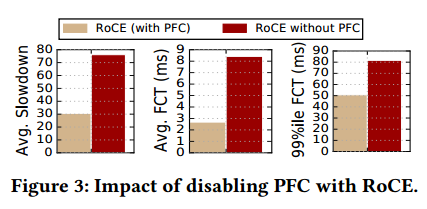
图3:不使用PFC对RoCE的影响。
4.2.4 Effect of Explicit Congestion Control. The previous comparisons did not use any explicit congestion control. However, as mentioned before, RoCE today is typically deployed in conjunction with some explicit congestion control mechanism such as Timely or DCQCN. We now evaluate whether using such explicit congestion control mechanisms affect the key trends described above.
4.2.4显式拥塞控制的影响。 之前的比较没有使用任何显式的拥塞控制。 然而,如前所述,今天的RoCE通常与一些显式拥塞控制机制(例如Timely或DCQCN)一起部署。 我们现在评估使用这种显式拥塞控制机制是否影响上述关键趋势。
Figure 4 compares IRN and RoCE’s performance when Timely or DCQCN is used. IRN continues to perform better by up to 1.5-2.2× across the three metrics.
图4比较了使用Timely或DCQCN时的IRN和RoCE的性能。 在三个指标中,IRN的表现仍然比RoCE高1.5-2.2倍。
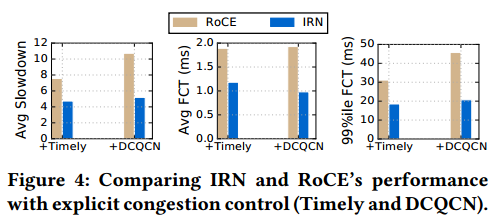
图4:使用显式拥塞控制(Timely和DCQCN)时IRN和RoCE的性能比较。
Figure 5 evaluates the impact of enabling PFC with IRN, when Timely or DCQCN is used. We find that, IRN’s performance is largely unaffected by PFC, since explicit congestion control reduces both the packet drop rate as well as the number of pause frames generated. The largest performance improvement due to enabling PFC was less than 1%, while its largest negative impact was about 3.4%.
图5评估了使用Timely或DCQCN时启用PFC对IRN的影响。 我们发现,由于显式拥塞控制降低了数据包丢包率以及生成的暂停帧数,因此IRN的性能在很大程度上不受PFC的影响。 由于启用PFC,最大性能提升不到1%,而其最大的负面影响约为3.4%。
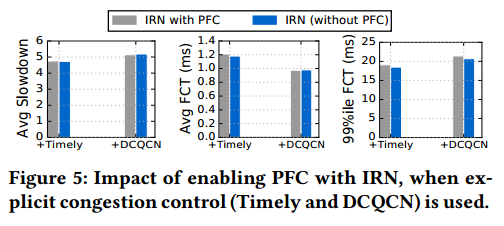
图5:使用显式拥塞控制时,启用RFC对IRN的影响。
Finally, Figure 6 compares RoCE’s performance with and without PFC, when Timely or DCQCN is used.3 We find that, unlike IRN, RoCE (with its inefcient go-back-N loss recovery) requires PFC, even when explicit congestion control is used. Enabling PFC improves RoCE’s performance by 1.35× to 3.5× across the three metrics.
最后,图6比较了使用Timely或DCQCN时,使用和不使用RFC时RoCE的性能。我们发现,与IRN不同,RoCE(使用低效的的回退N丢包恢复)需要PFC,即使使用显式拥塞控制也是如此。 在三个指标中,启用PFC可将RoCE的性能提高1.35倍至3.5倍。
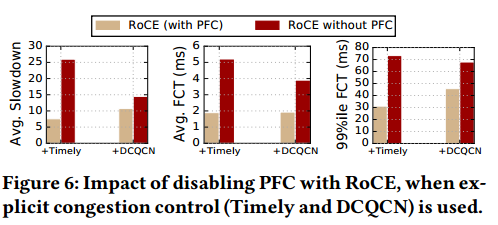
图6:当使用显式控制时,不启用RFC对RoCE的影响。
Key Takeaways: The following are, therefore, the three takeaways from these results: (1) IRN (without PFC) performs better than RoCE (with PFC), (2) IRN does not require PFC, and (3) RoCE requires PFC.
关键要点:因此,以下是这些结果的三个要点:(1)IRN(无PFC)的性能优于RoCE(带PFC),(2)IRN不需要PFC,(3)RoCE需要PFC。
4.3 Factor Analysis of IRN (IRN的因子分析)
We now perform a factor analaysis of IRN, to individually study the signifcance of the two key changes IRN makes to RoCE, namely (1) efcient loss recovery and (2) BDP-FC. For this we compare IRN’s performance (as evaluated in §4.2) with two different variations that highlight the signifcance of each change: (1) enabling go-back-N loss recovery instead of using SACKs, and (2) disabling BDP-FC. Figure 7 shows the resulting average FCTs (we saw similar trends with other metrics). We discuss these results in greater details below.
我们现在进行IRN的因子分析,以单独研究IRN对RoCE做出的两个关键更改的重要性,即(1)有效的丢包恢复和(2)BDP-FC。 为此,我们将IRN的性能(在§4.2中评估)与两个不同的更改进行比较,突出了每个更改的重要性:(1)启用回退N丢包恢复而不是使用SACK,以及(2)禁用BDP-FC。 图7显示了得到的平均FCT(我们看到了与其他指标类似的趋势)。 我们将在下面详细讨论这些结果。
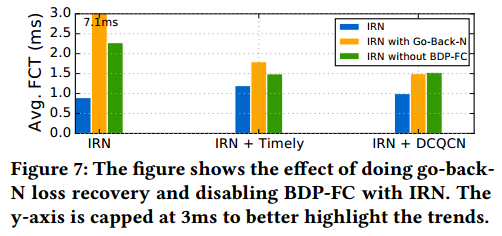
图7:本图给出回退N丢包恢复和不使用BDP-FC时IRN的影响。y轴限制到3ms以更好地突出趋势。
Need for Efficient Loss Recovery: The frst two bars in Figure 7 compare the average FCT of default SACK-based IRN and IRN with go-back-N respectively. We find that the latter results in signifcantly worse performance. This is because of the bandwidth wasted by go-back-N due to redundant retransmissions, as described before.
需要有效的丢包恢复:图7中的前两个条形图分别比较了默认的基于SACK的IRN和使用回退N的IRN的平均FCT。我们认为后者会导致性能显着下降。 这是因为由于回退N的冗余重传导致的带宽浪费,如前所述。
Before converging to IRN’s current loss recovery mechanism, we experimented with alternative designs. In particular we explored the following questions:
在使用IRN目前的丢包恢复机制之前,我们尝试了其它替代设计。 我们特别探讨了以下问题:
(1) Can go-back-N be made more efcient? Go-back-N does have the advantage of simplicity over selective retransmission, since it allows the receiver to simply discard out-oforder packets. We, therefore, tried to explore whether we can mitigate the negative effects of go-back-N. We found that explicitly backing off on losses improved go-back-N performance for Timely (though, not for DCQCN). Nonetheless, SACK-based loss recovery continued to perform significantly better across different scenarios (with the difference in average FCT for Timely ranging from 20%-50%).
(1)回退N可以更有效吗?相比于选择性重传, Go-back-N确实具有简单的优点,因为它允许接收端简单地丢弃乱序数据包。 因此,我们试图探讨是否可以减轻回退N的负面影响。 我们发现:对于Timely(但不是DCQCN)丢失时的显式回退可以提高回退N的性能。 尽管如此,基于SACK的丢包恢复在不同的情景中继续表现得更好(Timely的平均FCT差异在20%-50%之间)。
(2) Do we need SACKs? We tried a selective retransmit scheme without SACKs (where the sender does not maintain a bitmap to track selective acknowledgements). This performed better than go-back-N. However, it fared poorly when there were multiple losses in a window, requiring multiple round-trips to recover from them. The corresponding degradation in average FCT ranged from <1% up to 75% across different scenarios when compared to SACK-based IRN.
(2)我们需要SACK吗?我们尝试了一种没有SACK的选择性重传方案(发送方没有维护位图来跟踪选择性确认)。这比回退N表现得更好。然而,当窗口中出现多处丢包时,它的表现很差,需要多次往返才能从中恢复。 与基于SACK的IRN相比,在不同情况下,平均FCT的相应降级范围从<1%到75%不等。
(3) Can the timeout value be computed dynamically? As described in §3, IRN uses two static (low and high) timeout values to allow faster recovery for short messages, while avoiding spurious retransmissions for large ones. We also experimented with an alternative approach of using dynamically computed timeout values (as with TCP), which not only complicated the design, but did not help since these effects were then be dominated by the initial timeout value.
(3)可以动态计算超时值吗? 如§3所述,IRN使用两个静态(低和高)超时值,以便更快地恢复短消息,同时避免大消息的虚假重传。 我们还尝试了一种使用动态计算超时值的替代方法(与TCP一样),这不仅使设计复杂化,而且没有帮助,因为这些效果随后由初始超时值主导。
Signifcance of BDP-FC: The frst and the third bars in Figure 7 compare the average FCT of IRN with and without BDP-FC respectively. We fnd that BDP-FC signifcantly improves performance by reducing unnecessary queuing. Furthermore, it prevents a flow that is recovering from a packet loss from sending additional new packets and increasing congestion, until the loss has been recovered.
BDP-FC的重要性:图7中的第一和第三条分别比较了有和没有BDP-FC的IRN的平均FCT。 我们认为BDP-FC可以通过减少不必要的排队来显着提高性能。 此外,它可以防止从丢包中恢复的数据流发送额外的新数据包并增加拥塞,直到丢包已经恢复。
Efficient Loss Recovery vs BDP-FC: Comparing the second and third bars in Figure 7 shows that the performance of IRN with go-back-N loss recovery is generally worse than the performance of IRN without BDP-FC. This indicates that of the two changes IRN makes, efcient loss recovery helps performance more than BDP-FC.
BDP-FC和高效丢包恢复对比:比较图7中的第二和第三条柱,显示:回退N丢包恢复的IRN性能通常比没有BDP-FC的IRN性能差。 这表明在IRN做出的两个更改中,有效的丢包恢复比BDP-FC更有助于提高性能。
4.4 Robustness of Basic Results (基础结果的鲁棒性)
We now evaluate the robustness of the basic results from §4.2 across different scenarios and performance metrics.
我们现在评估§4.2在不同场景和性能指标中的基础结果的稳健性。
4.4.1 Varying Experimental Scenario. We evaluate the robustness of our results, as the experimental scenario is varied from our default case. In particular, we run experiments with (i) link utilization levels varied between 30%-90%, (ii) link bandwidths varied from the default of 40Gbps to 10Gbps and 100Gbps, (iii) larger fat-tree topologies with 128 and 250 servers, (iv) a different workload with flow sizes uniformly distributed between 500KB to 5MB, representing background and storage trafc for RDMA, (v) the per-port buffer size varied between 60KB-480KB, (vi) varying other IRN parameters (increasing RTOhiдh value by up to 4 times the default of 320µs, and increasing the N value for using RTOlow to 10 and 15). We summarize our key observations here and provide detailed results for each of these scenarios in Appendix §A of an extended report [31].
4.4.1不同的实验场景。 我们评估结果的稳健性,因为实验场景与我们的默认情景不同。 特别是,我们进行了以下实验:(i)链路利用率水平在30%-90%之间变化,(ii)链路带宽从默认的40Gbps到10Gbps和100Gbps不等,(iii)更大的胖树拓扑结构,128和250台服务器 ,(iv)不同的工作负载,数据流大小均匀分布在500KB到5MB之间,代表RDMA的背景和存储数据流,(v)每端口缓冲区大小在60KB-480KB之间变化,(vi)改变其他IRN参数(增加RTOhigh) 值最多为默认值320μs的4倍,并将使用RTOlow的N值增加到10和15)。 我们在此总结了我们的主要观察结果,并在扩展报告的附录§A中为每个场景提供了详细的结果[31]。
Overall Results: Across all of these experimental scenarios, we find that:
总体结果:在所有这些实验场景中,我们发现:
(a) IRN (without PFC) always performs better than RoCE (with PFC), with the performance improvement ranging from 6% to 83% across different cases.
(a) IRN(没有PFC)总是比RoCE(使用PFC)表现更好,在不同情况下性能改善范围从6%到83%。
(b) When used without any congestion control, enabling PFC with IRN always degrades performance, with the maximum degradation across different scenarios being as high as 2.4×.
(b) 在没有任何拥塞控制的情况下,启用PFC总会降低IRN的性能,不同情况下的最大降级高达2.4倍。
(c) Even when used with Timely and DCQCN, enabling PFC with IRN often degrades performance (with the maximum degradation being 39% for Timely and 20% for DCQCN). Any improvement in performance due to enabling PFC with IRN stays within 1.6% for Timely and 5% for DCQCN.
(c) 即使与Timely和DCQCN一起使用,启用PFC通常会降低IRN的性能(Timely的最大降级为39%,DCQCN的降级最大为20%)。 由于启用PFC导致的性能改善对Timely保持在1.6%之内,对于DCQCN保持在5%之内。
Some observed trends: The drawbacks of enabling PFC with IRN:
一些观察到的趋势:使IRN启用PFC的缺点:
(a) generally increase with increasing link utilization, as the negative impact of congestion spreading with PFC increases.
(a) 通常随着链路利用率的增加而增加,这是因为PFC导致拥塞扩散的负面影响增加。
(b) decrease with increasing bandwidths, as the relative cost of a round trip required to react to packet drops without PFC also increases.
(b) 随着带宽的增加而减少,因为在没有PFC的情况下对丢包做出反应所需的往返的相对成本也会增加。
(c) increase with decreasing buffer sizes due to more pauses and greater impact of congestion spreading.
(c) 随着缓存大小的减少而增加,这是因为更多的暂停帧和更大的拥塞扩散的影响。
We further observe that increasing RTOhigh or N had a very small impact on our basic results, showing that IRN is not very sensitive to the specifc parameter values.
我们进一步观察到,增加RTOhigh或N对我们的基础结果的影响非常小,表明IRN对特定参数值不是非常敏感。
4.4.2 Tail latency for small messages. We now look at the tail latency (or tail FCT) of the single-packet messages from our default scenario, which is another relevant metric in datacenters [29]. Figure 8 shows the CDF of this tail latency (from 90%ile to 99.9%ile), across different congestion control algorithms. Our key trends from §4.2 hold even for this metric. This is because IRN (without PFC) is able to recover from single-packet message losses quickly due to the low RTOlow timeout value. With PFC, these messages end up waiting in the queues for similar (or greater) duration due to pauses and congestion spreading. For all cases, IRN performs signifcantly better than RoCE.
4.4.2小消息的尾部延迟。 我们现在看一下我们的默认场景的单数据包消息的尾部延迟(或尾部FCT),这是数据中心的另一个相关指标[29]。 图8显示了不同拥塞控制算法的尾部延迟(从90%ile到99.9%ile)的CDF。 我们关于§4.2的主要趋势甚至适用于该指标。 这是因为由于RTOlow超时值较低,IRN(无PFC)能够快速从单包消息丢失中恢复。 使用PFC,由于暂停和拥塞传播,这些消息最终会在队列中等待相似(或更长)的持续时间。 对于所有情况,IRN比RoCE表现更好。

图8:本图比较了不同拥塞控制算法下,IRN、使用PFC的IRN和RoCE(使用RFC)的单包消息尾部延迟。
4.4.3 Incast. We now evaluate incast scenarios, both with and without cross-traffic. The incast workload without any cross traffic can be identifed as the best case for PFC, since only valid congestion-causing flows are paused without unnecessary head-of-the-line blocking.
4.4.3 Incast。 我们现在评估incast场景,无论是否有交叉流量。 没有任何交叉流量的incast工作负载被认为PFC的最佳情况,因为只有有效的导致拥塞的数据流被暂停而没有不必要的线头阻塞。
Incast without cross-traffic: We simulate the incast workload on our default topology by striping 150MB of data across M randomly chosen sender nodes that send it to a fixed destination node [17]. We vary M from 10 to 50. We consider the request completion time (RCT) as the metric for incast performance, which is when the last flow completes. For each M, we repeat the experiment 100 times and report the average RCT. Figure 9 shows the results, comparing IRN with RoCE. We find that the two have comparable performance: any increase in the RCT due to disabling PFC with IRN remained within 2.5%. The results comparing IRN’s performance with and without PFC looked very similar. We also varied our default incast setup by changing the bandwidths to 10Gbps and 100Gbps, and increasing the number of connections per machine. Any degradation in performance due to disabling PFC with IRN stayed within 9%.
没有交叉流量的Incast:我们通过在M个随机选择的发送方节点上分送150MB数据来模拟我们默认拓扑中的incast工作负载,这些节点将数据其发送到固定目标节点[17]。 我们将M从10到50变化。我们将请求完成时间(RCT)视为incast性能的度量标准,即最后一个数据流完成的时间。 对于每个M,我们重复实验100次并报告平均RCT。 图9显示了将IRN与RoCE进行比较的结果。 我们发现两者具有相似的性能:不使用IRN的的PFC导致的RCT的增加保持在2.5%以内。 比较IRN在有和没有PFC的情况下的性能结果非常相似。 我们还通过将带宽更改为10Gbps和100Gbps以及增加每台计算机的连接数来改变我们的默认incast设置。 禁用IRN的PFC而导致的性能下降保持在9%以内。
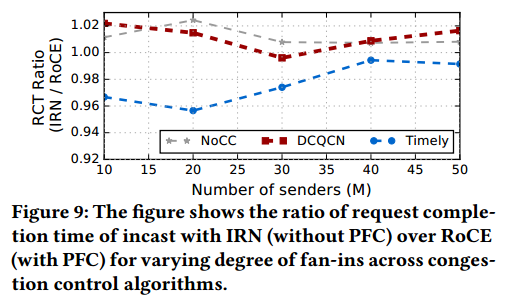
图9: 本图给出IRN(不使用PFC)与RoCE(使用RFC)相比,使用不同的拥塞控制算法,改变扇入度的情况下,请求完成时间的比率。
Incast with cross traffic: In practice we expect incast to occur with other cross traffic in the network [23, 29]. We started an incast as described above with M = 30, along with our default case workload running at 50% link utilization level. The incast RCT for IRN (without PFC) was always lower than RoCE (with PFC) by 4%-30% across the three congestion control schemes. For the background workload, the performance of IRN was better than RoCE by 32%-87% across the three congestion control schemes and the three metrics (i.e., the average slowdown, the average FCT and the tail FCT). Enabling PFC with IRN generally degraded performance for both the incast and the cross-traffic by 1-75% across the three schemes and metrics, and improved performance only for one case (incast workload with DCQCN by 1.13%).
包含交叉流量的incast:在实践中,我们期望在网络中incast和网络中的其它较差流量同时存在[23,29]。 我们如上所述开始了一个M = 30的incast,以及我们的默认案例工作负载以50%的链路利用率运行。 在三种拥塞控制方案中,IRN(没有PFC)的incast RCT总是低于RoCE(使用PFC)4%-30%。 对于后台工作负载,在三种拥塞控制方案和三个指标(即平均减缓,平均FCT和尾部FCT)中,IRN的性能优于RoCE 32%-87%。 启用PFC的IRN通常会使三个方案和指标中的incast和较差流量的性能降低1-75%,并且仅针对一种情况提高性能(DCQCN的工作负载为1.13%)。
4.4.4 Window-based congestion control. We also implemented conventional window-based congestion control schemes such as TCP’s AIMD and DCTCP [15] with IRN and observed similar trends as discussed in §4.2. In fact, when IRN is used with TCP’s AIMD, the benefits of disabling PFC were even stronger, because it exploits packet drops as a congestion signal, which is lost when PFC is enabled.
4.4.4基于窗口的拥塞控制。 我们还实现了传统的基于窗口的拥塞控制方案,如TCP的AIMD和DCTCP [15],并观察到类似于§4.2中讨论的趋势。 事实上,当IRN与TCP的AIMD一起使用时,禁用PFC的好处甚至更强,因为它利用数据包丢包作为拥塞信号,当启用PFC时该好处丢失。
Summary: Our key results i.e., (1) IRN (without PFC) performs better than RoCE (with PFC), and (2) IRN does not require PFC, hold across varying realistic scenarios, congestion control schemes and performance metrics.
总结:我们的关键结果,即(1)IRN(没有PFC)比RoCE(使用PFC)表现更好,(2)IRN不需要PFC,适用于不同的现实场景,拥塞控制方案和性能指标。
4.5 Comparison with Resilient RoCE (与弹性RoCE比较)
A recent proposal on Resilient RoCE [34] explores the use of DCQCN to avoid packet losses in specifc scenarios, and thus eliminate the requirement for PFC. However, as observed previously in Figure 6, DCQCN may not always be successful in avoiding packet losses across all realistic scenarios with more dynamic traffic patterns and hence PFC (with its accompanying problems) remains necessary. Figure 10 provides a direct comparison of IRN with Resilient RoCE. We fnd that IRN, even without any explicit congestion control, performs signifcantly better than Resilient RoCE, due to better loss recovery and BDP-FC.
最近关于弹性RoCE [34]的提案探讨了在特定情况下使用DCQCN来避免数据包丢失,从而消除了对PFC的要求。 然而,如先前在图6中所观察到的,DCQCN可能并不总是成功地避免在具有更多动态数据流模式的所有现实场景中的分组丢失,因此PFC(及其伴随的问题)仍然是必要的。 图10提供了IRN与弹性RoCE的直接比较。 我们发现IRN,即使没有任何显式的拥塞控制,由于更好的丢包恢复和BDP-FC,也比弹性RoCE表现得更好。
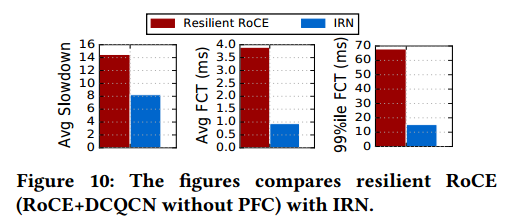
图10: IRN和弹性RoCE(RoCE+DCQCN,没有PFC)的比较。
4.6 Comparison with iWARP (与iWARP对比)
We finally explore whether IRN’s simplicity over the TCP stack implemented in iWARP impacts performance. We compare IRN’s performance (without any explicit congestion control) with full-blown TCP stack’s, using INET simulator’s in-built TCP implementation for the latter. Figure 11 shows the results for our default scenario. We fnd that absence of slow-start (with use of BDP-FC instead) results in 21% smaller slowdowns with IRN and comparable average and tail FCTs. These results show that in spite of a simpler design, IRN’s performance is better than full-blown TCP stack’s, even without any explicit congestion control. Augmenting IRN with TCP’s AIMD logic further improves its performance, resulting in 44% smaller average slowdown and 11% smaller average FCT as compared to iWARP. Furthermore, IRN’s simple design allows it to achieve message rates comparable to current RoCE NICs with very little overheads (as evaluated in §6). An iWARP NIC, on the other hand, can have up to 4× smaller message rate than a RoCE NIC (§2). Therefore, IRN provides a simpler and more performant solution than iWARP for eliminating RDMA’s requirement for a lossless network.
我们最后探讨IRN比iWARP中实现的更简单的TCP栈是否会影响性能。我们将IRN的性能(没有任何显式的拥塞控制)与完整的TCP栈进行比较,使用INET模拟器的内置TCP实现来实现后者。图11显示了我们的默认方案的结果。我们认为没有慢启动(使用BDP-FC代替)导致IRN减缓减少21%,并且平均和尾部FCT相当。这些结果表明,尽管设计更简单,但即使没有任何显式的拥塞控制,IRN的性能也优于完整的TCP栈。使用TCP的AIMD逻辑增强IRN进一步提高了其性能,与iWARP相比,平均减缓降低了44%,平均FCT降低了11%。此外,IRN的简单设计使其能够以非常小的开销实现与当前RoCE NIC相当的消息速率(如§6中所述)。另一方面,iWARP NIC的消息速率最高可比RoCE NIC小4倍(§2)。因此,IRN提供了比iWARP更简单且更高性能的解决方案,以消除RDMA对不丢包网络的要求。
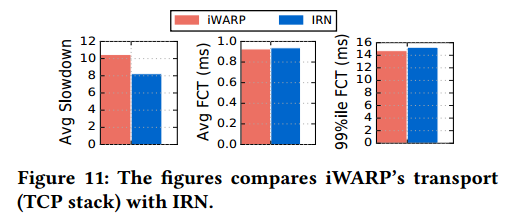
图11: iWARP传输层(TCP栈)和IRN的对比。
5 Implementation Considerations (实现考量)
We now discuss how one can incrementally update RoCE NICs to support IRN’s transport logic, while maintaining the correctness of RDMA semantics as defned by the Infniband RDMA specifcation [4]. Our implementation relies on extensions to RDMA’s packet format, e.g., introducing new fields and packet types. These extensions are encapsulated within IP and UDP headers (as in RoCEv2) so they only effect the endhost behavior and not the network behavior (i.e. no changes are required at the switches). We begin with providing some relevant context about different RDMA operations before describing how IRN supports them.
我们现在讨论如何逐步更新RoCE NIC以支持IRN的传输层逻辑,同时保持RDMA语义的正确性(如Infiniband RDMA规范所定义[4])。 我们的实现依赖于对RDMA数据包格式的扩展,例如,引入新的域和数据包类型。这些扩展封装在IP和UDP头中(如RoCEv2中),因此它们只影响端主机行为,而不影响网络行为(即交换机不需要进行任何更改)。 在描述IRN如何支持它们之前,我们首先提供一些关于不同RDMA操作的相关上下文。
5.1 Relevant Context (相关上下文)
The two remote endpoints associated with an RDMA message transfer are called a requester and a responder. The interface between the user application and the RDMA NIC is provided by Work Queue Elements or WQEs (pronounced as wookies). The application posts a WQE for each RDMA message transfer, which contains the application-specifed metadata for the transfer. It gets stored in the NIC while the message is being processed, and is expired upon message completion. The WQEs posted at the requester and at the responder NIC are called Request WQEs and Receive WQEs respectively. Expiration of a WQE upon message completion is followed by the creation of a Completion Queue Element or a CQE (pronounced as cookie), which signals the message completion to the user application. There are four types of message transfers supported by RDMA NICs:
与RDMA消息传输相关联的两个远程端点称为请求者和响应者。 用户应用程序和RDMA NIC之间的接口由工作队列元素或WQE(发音为wookies)提供。 应用程序为每个RDMA消息传输发布WQE,其中包含用于传输的应用程序特定的元数据。它在处理消息时存储在NIC中,并在消息完成时过期。 在请求者和响应者NIC上发布的WQE分别称为请求WQE和接收WQE。 在消息完成时WQE到期之后是创建完成队列元素或CQE(发音为cookie),其向用户应用程序发信号通知消息完成。 RDMA NIC支持四种类型的消息传输:
Write: The requester writes data to responder’s memory. The data length, source and sink locations are specifed in the Request WQE, and typically, no Receive WQE is required. However, Write-with-immediate operation requires the user application to post a Receive WQE that expires upon completion to generate a CQE (thus signaling Write completion at the responder as well).
写:请求者将数据写入响应者的内存。 数据长度、源和接收者的位置在请求WQE中指定,通常不需要接收WQE。 然而,立即写入操作要求用户应用程序发布在完成时到期的接收WQE以生成CQE(从而也在响应者处发信号通知写入完成)。
Read: The requester reads data from responder’s memory. The data length, source and sink locations are specifed in the Request WQE, and no Receive WQE is required.
读:请求者从响应者的内存中读取数据。 数据长度、源和接收者的位置在请求WQE中指定,并且不需要接收WQE。
Send: The requester sends data to the responder. The data length and source location is specifed in the Request WQE, while the sink location is specifed in the Receive WQE.
发送:请求者将数据发送给响应者。 数据长度和源位置在请求WQE中指定,而接收者位置在接收WQE中指定。
Atomic: The requester reads and atomically updates the data at a location in the responder’s memory, which is specifed in the Request WQE. No Receive WQE is required. Atomic operations are restricted to single-packet messages.
原子:请求者读取并原子地更新响应者内存中某个位置的数据,该位置在请求WQE中指定。 不需要接收WQE。 原子操作仅限于单包消息。
5.2 Supporting RDMA Reads and Atomics (支持RDMA读和原子)
IRN relies on per-packet ACKs for BDP-FC and loss recovery. RoCE NICs already support per-packet ACKs for Writes and Sends. However, when doing Reads, the requester (which is the data sink) does not explicitly acknowledge the Read response packets. IRN, therefore, introduces packets for read (N)ACKs that are sent by a requester for each Read response packet. RoCE currently has eight unused opcode values available for the reliable connected QPs, and we use one of these for read (N)ACKs. IRN also requires the Read responder (which is the data source) to implement timeouts. New timer-driven actions have been added to the NIC hardware implementation in the past [34]. Hence, this is not an issue.
IRN依赖于BDP-FC的每包ACK和丢包恢复。 对于写和发送,RoCE NIC已经支持每个数据包的ACK。 但是,在执行读取时,请求者(数据接收器)不会显式确认读响应数据包。 因此,IRN引入了由请求者为每个读响应数据包发送的读(N)ACK数据包。 RoCE目前有八个未使用的操作码值可用于可靠连接的QP,我们使用其中一个用于读(N)ACK。 IRN还需要Read响应者(它是数据源)实现超时。 过去,新的计时器驱动操作已添加到NIC硬件实现中[34]。 因此,这不是问题。
RDMA Atomic operations are treated similar to a single packet RDMA Read messages.
RDMA原子操作的处理类似于单包RDMA读取消息。
Our simulations from §4 did not use ACKs for the RoCE (with PFC) baseline, modelling the extreme case of all Reads. Therefore, our results take into account the overhead of perpacket ACKs in IRN.
我们从§4开始的模拟没有使用针对RoCE(带有PFC)基线的ACK,对所有读取的极端情况进行建模。 因此,我们的结果考虑了IRN中每数据包ACK的开销。
5.3 Supporting Out-of-order Packet Delivery (支持乱序包交付)
One of the key challenges for implementing IRN is supporting out-of-order (OOO) packet delivery at the receiver – current RoCE NICs simply discard OOO packets. A naive approach for handling OOO packet would be to store all of them in the NIC memory. The total number of OOO packets with IRN is bounded by the BDP cap (which is about 110 MTU-sized packets for our default scenario as described in §4.1) 4. Therefore to support a thousand flows, a NIC would need to buffer 110MB of packets, which exceeds the memory capacity on most commodity RDMA NICs.
实现IRN的关键挑战之一是在接收者上支持无序(OOO)数据包传输 - 当前的RoCE NIC只是简单地丢弃OOO数据包。 处理OOO数据包的一种简单方法是将所有数据包存储在NIC内存中。 IRN中OOO数据包的总数受BDP上限的限制(对于我们的默认情况,大约为110个MTU大小的数据包,如第4.1节所述)。因此,为了支持一千个数据流,一个NIC需要增加110MB的数据包缓存,这超过大多数商用RDMA网卡的内存容量。
We therefore explore an alternate implementation strategy, where the NIC DMAs OOO packets directly to the final address in the application memory and keeps track of them using bitmaps (which are sized at BDP cap). This reduces NIC memory requirements from 1KB per OOO packet to only a couple of bits, but introduces some additional challenges that we address here. Note that partial support for OOO packet delivery was introduced in the Mellanox ConnectX-5 NICs to enable adaptive routing [11]. However, it is restricted to Write and Read operations. We improve and extend this design to support all RDMA operations with IRN.
因此,我们探索了另一种实现策略,其中NIC将OOO数据包直接通过DMA发送到应用程序内存中的最终地址,并使用位图(其大小为BDP上限)追踪它们。 这将NIC内存要求从每个OOO数据包1KB减少到仅几个比特,但是我们在此处提出了一些额外的挑战。 请注意,Mellanox ConnectX-5网卡中引入了对OOO数据包传输的部分支持,以实现自适应路由[11]。 但是,它仅限于写入和读取操作。 我们改进并扩展了此设计,以支持所有的RDMA操作。
We classify the issues due to out-of-order packet delivery into four categories.
我们将由乱序数据包传送引起的问题分为四类。
5.3.1 First packet issues. For some RDMA operations, critical information is carried in the first packet of a message, which is required to process other packets in the message. Enabling OOO delivery, therefore, requires that some of the information in the first packet be carried by all packets.
5.3.1第一个数据包问题。 对于某些RDMA操作,关键信息携带在消息的第一个数据包中,这是处理消息中其他数据包所必需的。 因此,启用OOO传送要求第一个数据包中的某些信息由所有数据包承载。
In particular, the RETH header (containing the remote memory location) is carried only by the first packet of a Write message. IRN requires adding it to every packet.
特别地,RETH报头(包含远程存储器位置)仅由写消息的第一个分组携带。 IRN需要将其添加到每个数据包。
5.3.2 WQE matching issues. Some operations require every packet that arrives to be matched with its corresponding WQE at the responder. This is done implicitly for in-order packet arrivals. However, this implicit matching breaks with OOO packet arrivals. A work-around for this is assigning explicit WQE sequence numbers, that get carried in the packet headers and can be used to identify the corresponding WQE for each packet. IRN uses this workaround for the following RDMA operations:
5.3.2 WQE匹配问题。 某些操作要求到达的每个数据包与响应者处的相应WQE匹配。 对于有序分组到达,这是隐式完成的。 但是,这种隐式匹配会被OOO数据包到达破坏。 解决此问题的方法是分配显式WQE序列号,这些序列号在数据包报头中携带,可用于识别每个数据包的相应WQE。 IRN将此解决方法用于以下RDMA操作:
Send and Write-with-immediate: It is required that Receive WQEs be consumed by Send and Write-with-immediate requests in the same order in which they are posted. Therefore, with IRN every Receive WQE, and every Request WQE for these operations, maintains a recv_WQE_SN that indicates the order in which they are posted. This value is carried in all Send packets and in the last Write-with-Immediate packet, and is used to identify the appropriate Receive WQE. IRN also requires the Send packets to carry the relative offset in the packet sequence number, which is used to identify the precise address when placing data.
发送和立即写入:要求发送和立即写入请求按照发布的相同顺序使用接收WQE。 因此,对于IRN,每个接收WQE以及这些操作的每个请求WQE都维护一个recv_WQE_SN,指示它们的发布顺序。 该值在所有发送数据包和最后一个Write-with-Immediate数据包中携带,用于标识相应的接收WQE。 IRN还要求发送数据包携带数据包序列号中设置的相对偏移值,用于在放置数据时识别精确地址。
Read/Atomic: The responder cannot begin processing a Read/Atomic request R, until all packets expected to arrive before R have been received. Therefore, an OOO Read/Atomic Request packet needs to be placed in a Read WQE buffer at the responder (which is already maintained by current RoCE NICs). With IRN, every Read/Atomic Request WQE maintains a read_WQE_SN, that is carried by all Read/Atomic request packets and allows identifcation of the correct index in this Read WQE buffer.
读/原子:响应者无法开始处理读/原子请求R,直到所有预期在R之前到达的数据包被接收为止。 因此,需要在响应者(已由当前RoCE NIC维护)的读WQE缓冲区中放置OOO读/原子请求包。 使用IRN,每个读/原子请求WQE维护一个read_WQE_SN,由所有读/原子请求包携带,并允许在该读WQE缓冲区中识别正确的索引。
5.3.3 Last packet issues. For many RDMA operations, critical information is carried in last packet, which is required to complete message processing. Enabling OOO delivery, therefore, requires keeping track of such last packet arrivals and storing this information at the endpoint (either on NIC or main memory), until all other packets of that message have arrived. We explain this in more details below.
5.3.3最后的数据包问题。 对于许多RDMA操作,关键信息在最后一个数据包中携带,这是完成消息处理所必需的。 因此,启用OOO传送需要跟踪最后的数据包到达并将此信息存储在端点(NIC或主存储器上),直到该消息的所有其他数据包都到达。 我们将在下面详细解释这一点。
A RoCE responder maintains a message sequence number (MSN) which gets incremented when the last packet of a Write/Send message is received or when a Read/Atomic request is received. This MSN value is sent back to the requester in the ACK packets and is used to expire the corresponding Request WQEs. The responder also expires its Receive WQE when the last packet of a Send or a Write-With-Immediate message is received and generates a CQE. The CQE is populated with certain meta-data about the transfer, which is carried by the last packet. IRN, therefore, needs to ensure that the completion signalling mechanism works correctly even when the last packet of a message arrives before others. For this, an IRN responder maintains a 2-bitmap, which in addition to tracking whether or not a packet p has arrived, also tracks whether it is the last packet of a message that will trigger (1) an MSN update and (2) in certain cases, a Receive WQE expiration that is followed by a CQE generation. These actions are triggered only after all packets up to p have been received. For the second case, the recv_WQE_SN carried by p (as discussed in §5.3.2) can identify the Receive WQE with which the meta-data in p needs to be associated, thus enabling a premature CQE creation. The premature CQE can be stored in the main memory, until it gets delivered to the application after all packets up to p have arrived.
RoCE响应器维护消息序列号(MSN),当接收到写入/发送消息的最后一个包或者接收到读取/原子请求时,该消息序列号增加。该MSN值在ACK分组中被发送回请求者,并用于使相应的请求WQE到期。当接收到Send或Write-With-Immediate消息的最后一个数据包并产生CQE时,响应者也使其接收WQE到期。 CQE填充有关于传输的某些元数据,其由最后一个分组携带。因此,IRN需要确保即使消息的最后一个数据包到达其他数据包之前,完成信令机制也能正常工作。为此,IRN响应者维护2位图,除了跟踪包p是否已到达之外,还跟踪它是否是将触发(1)MSN更新的消息的最后一个包,以及(2)在某些情况下,接收WQE到期,然后是CQE生成。只有在收到所有直到p的数据包后才会触发这些操作。对于第二种情况,由p携带的recv_WQE_SN(如第5.3.2节中所讨论的)可以识别与p中的元数据需要关联的接收WQE,从而实现过早的CQE创建。过早的CQE可以存储在主存储器中,直到它在到达p的所有数据包到达之后被传送到应用程序。
5.3.4 Application-level Issues. Certain applications (for example FaRM [21]) rely on polling the last packet of a Write message to detect completion, which is incompatible with OOO data placement. This polling based approach violates the RDMA specifcation (Sec o9-20 [4]) and is more expensive than ofcially supported methods (FaRM [21] mentions moving on to using the ofcially supported Write-withImmediate method in the future for better scalability). IRN’s design provides all of the Write completion guarantees as per the RDMA specifcation. This is discussed in more details in Appendix §B of the extended report [31].
5.3.4应用程序级问题。 某些应用程序(例如FaRM [21])依赖于轮询Write消息的最后一个数据包来检测完成,这与OOO数据放置不兼容。 这种基于轮询的方法违反了RDMA规范(Sec o9-20 [4]),并且比特别支持的方法更昂贵(FaRM [21]提到将来使用特定支持的Write-withImmediate方法以获得更好的可扩展性)。 IRN的设计根据RDMA规范提供了所有写完成保证。 这在扩展报告[31]的附录§B中有更详细的讨论。
OOO data placement can also result in a situation where data written to a particular memory location is overwritten by a restransmitted packet from an older message. Typically, applications using distributed memory frameworks assume relaxed memory ordering and use application layer fences whenever strong memory consistency is required [14, 36]. Therefore, both iWARP and Mellanox ConnectX-5, in supporting OOO data placement, expect the application to deal with the potential memory over-writing issue and do not handle it in the NIC or the driver. IRN can adopt the same strategy. Another alternative is to deal with this issue in the driver, by enabling the fence indicator for a newly posted request that could potentially overwrite an older one.
OOO数据放置还可能导致写入特定存储器位置的数据被来自较旧消息的重新发送的数据包覆盖的情况。 通常,使用分布式内存框架的应用程序假定放宽内存排序,并在需要强内存一致性时使用应用程序层围栏[14,36]。 因此,支持OOO数据放置的iWARP和Mellanox ConnectX-5都希望应用程序能够处理潜在的内存覆盖问题,而不是在NIC或驱动程序中处理它。 IRN可以采用相同的策略。 另一种方法是在驱动程序中处理此问题,方法是为新发布的请求启用fence指示符,该请求可能会覆盖旧的请求。
5.4 Other Considerations (其它考量)
Currently, the packets that are sent and received by a requester use the same packet sequence number (PSN ) space. This interferes with loss tracking and BDP-FC. IRN, therefore, splits the PSN space into two different ones (1) sPSN to track the request packets sent by the requester, and (2) rPSN to track the response packets received by the requester. This decoupling remains transparent to the application and is compatible with the current RoCE packet format. IRN can also support shared receive queues and send with invalidate operations and is compatible with use of end-to-end credit. We provide more details about these in Appendix §B of the extended report [31].
目前,请求者发送和接收的数据包使用相同的数据包序列号(PSN)空间。 这会干扰丢失跟踪和BDP-FC。 因此,IRN将PSN空间分成两个不同的空间(1)sPSN来跟踪请求者发送的请求包,以及(2)rPSN跟踪请求者接收的响应包。 这种解耦对应用程序仍然是透明的,并且与当前的RoCE数据包格式兼容。 IRN还可以支持共享接收队列,并通过无效操作发送,并与端到端信用的使用兼容。 我们在扩展报告的附录§B中提供了有关这些的更多细节[31]。