复制粘贴功能我们都用过,我们可以把一个文件从一个地方复制到另外一个地方,复制完成之后这个文件和之前的文件也没有一点差别,这就是原型模式的思想:首先创建一个实例,然后通过这个实例去拷贝创建新的实例。这篇文章就好好地分析一下原型模式。
一、认识原型模式
1、概念
用原型实例指定创建对象的种类,并通过拷贝这些原型创建新的对象。
我们拿电脑中复制粘贴的例子来演示一下原型模式.
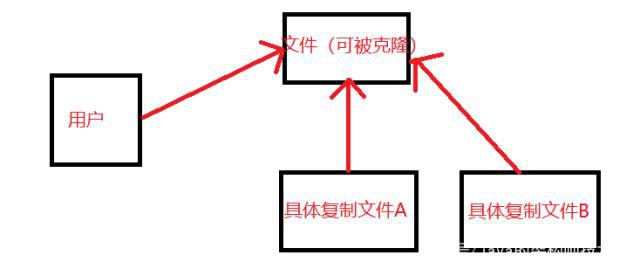
上面这张图已经很明显了,首先我们需要一个文件,这个文件一定要有可以被克隆的功能,那么我们创建这个文件之后,就可以通过它克隆出无数个。
2、java类图分析
下面我们再从类图的角度来分析一下:
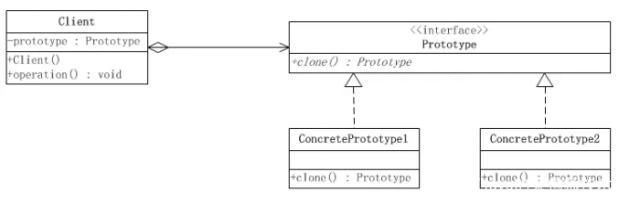
首先我们可以看到一共有三个角色:
(1)客户(Client)角色:客户类提出创建对象的请求;也就是我们用户使用复制粘贴的功能。
(2)抽象原型(Prototype)角色:此角色定义了的具体原型类所需的实现的方法。也就是定义一个文件,说明一下它有被克隆复制的功能。
(3)具体原型(Concrete Prototype)角色:实现抽象原型角色的克隆接口。就是我们的文件实现了可以被复制的功能。
我们会发现其实原型模式的核心就是Prototype(抽象原型),他需要继承Cloneable接口,并且重写Object类中的clone方法才能有复制粘贴的功能。
3、分类
既然我们知道原型模式的核心就是拷贝对象,那么我们能拷贝一个对象实例的什么内容呢?这就要区分深拷贝和浅拷贝之分了。
(1)浅拷贝:我们只拷贝对象中的基本数据类型(8种),对于数组、容器、引用对象等都不会拷贝
(2)深拷贝:不仅能拷贝基本数据类型,还能拷贝那些数组、容器、引用对象等,
下面我们就使用代码去实现一下原型模式。这里实现的是不仅有基本数据类型,还有数组和容器,所以实现的是深拷贝。
二、代码实现原型模式
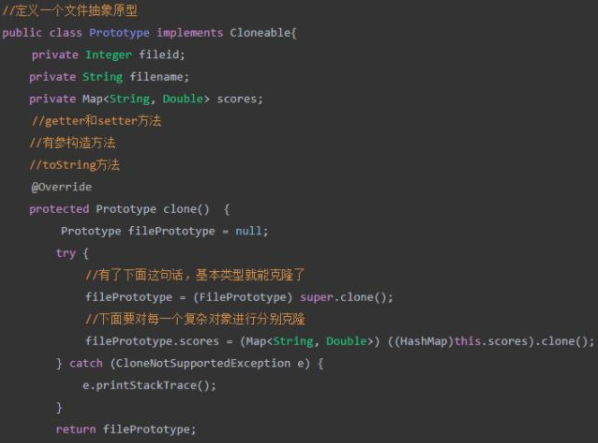
第一步:定义抽象原型
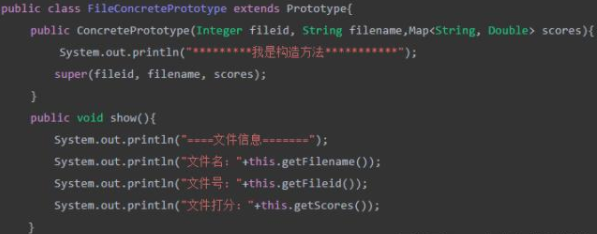
第二步:定义具体原型
第三步:定义用户去模拟过程
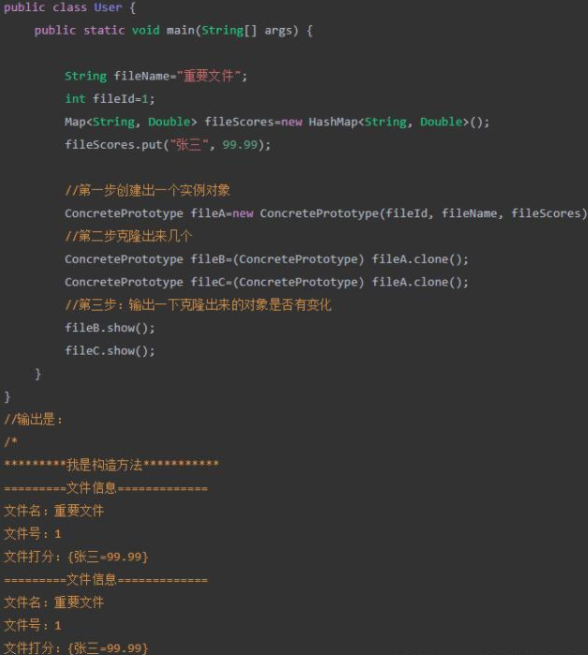
我们可以看到,克隆出来的两个文件和之前的文件是一样的,而且我们实现了深拷贝,对于数组、引用等对象同样的适用。
三、分析原型模式
对于原型模式有几个问题需要我们去注意一下
1、克隆对象不会调用构造方法
从上面的输出其实我们也可以发现,构造方法只在一开始我们创建原型的时候输出了,fileB和fileC都没有调用构造方法,这是因为执行clone方法的时候是直接从内存中去获取数据的,在第一次创建对象的时候就会把数据在内存保留一份,克隆的时候直接调用就好了
2、访问权限对原型模式无效
原理也很简单,我们是从内存中直接复制的,所以克隆起来也会直接无视,复制相应的内容就好了。
3、使用场景
(1)当我们的类初始化需要消耗很多的资源时,就可以使用原型模式,因为我们的克隆不会执行构造方法,避免了初始化占有的时间和空间。
(2)一个对象被其她对象访问,并且能够修改时,访问权限都无效了,什么都能修改。