一个典型的机器学习的过程,首先给出一组输入数据X,我们的算法会通过一系列的过程得到一个估计的函数,这个函数有能力对没有见过的新数据给出一个新的估计Y,也被称为构建一个模型。
我们用X1、X2...Xn 去描述feature里面的分量,用Y来描述我们的估计,得到一下模型:
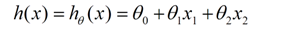
我们需要一种机制去评价这个模型对数据的描述到底够不够准确,而采集的数据x、y通常来说是存在误差的(多数情况下误差服从高斯分布),于是,自然的,引入误差函数:
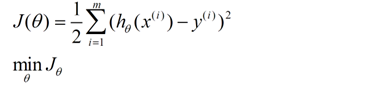
关键的一点是如何调整theta值,使误差函数J最小化。J函数构成一个曲面或者曲线,我们的目的是找到该曲面的最低点:

二、不同梯度下降算法的区别:
-
梯度下降:梯度下降就是我上面的推导,要留意,在梯度下降中,对于θθ的更新,所有的样本都有贡献,也就是参与调整θθ.其计算得到的是一个标准梯度。因而理论上来说一次更新的幅度是比较大的。如果样本不多的情况下,当然是这样收敛的速度会更快啦~
-
随机梯度下降:可以看到多了随机两个字,随机也就是说我用样本中的一个例子来近似我所有的样本,来调整θθ,因而随机梯度下降是会带来一定的问题,因为计算得到的并不是准确的一个梯度,容易陷入到局部最优解中
-
批量梯度下降:其实批量的梯度下降就是一种折中的方法,他用了一些小样本来近似全部的,其本质就是我1个指不定不太准,那我用个30个50个样本那比随机的要准不少了吧,而且批量的话还是非常可以反映样本的一个分布情况的。
三、算法实现与测试:
通过一组数据拟合 y = theta1*x1 +theta2*x2
#Python 3.3.5
import random
# matrix_A 训练集
matrix_A = [[1,4], [2,5], [5,1], [4,2]]
Matrix_y = [19,26,19,20]
theta = [2,5]
#学习速率
leraing_rate = 0.005
loss = 50
iters = 1
Eps = 0.0001
#随机梯度下降
while loss>Eps and iters <1000 :
loss = 0
i = random.randint(0, 3)
h = theta[0]*matrix_A[i][0] + theta[1]*matrix_A[i][1]
theta[0] = theta[0] + leraing_rate*(Matrix_y[i]-h)*matrix_A[i][0]
theta[1] = theta[1] + leraing_rate*(Matrix_y[i]-h)*matrix_A[i][1]
Error = 0
Error = theta[0]*matrix_A[i][0] + theta[1]*matrix_A[i][1] - Matrix_y[i]
Error = Error*Error
loss = loss +Error
iters = iters +1
print ('theta=',theta)
print ('iters=',iters)
"""
#梯度下降
while loss>Eps and iters <1000 :
loss = 0
for i in range(4):
h = theta[0]*matrix_A[i][0] + theta[1]*matrix_A[i][1]
theta[0] = theta[0] + leraing_rate*(Matrix_y[i]-h)*matrix_A[i][0]
theta[1] = theta[1] + leraing_rate*(Matrix_y[i]-h)*matrix_A[i][1]
for i in range(4):
Error = 0
Error = theta[0]*matrix_A[i][0] + theta[1]*matrix_A[i][1] - Matrix_y[i]
Error = Error*Error
loss = loss +Error
iters = iters +1
print ('theta=',theta)
print ('iters=',iters)
"""
"""
#批量梯度下降
while loss>Eps and iters <1000 :
loss = 0
sampleindex = random.sample([0,1,2,3],2)
for i in sampleindex :
h = theta[0]*matrix_A[i][0] + theta[1]*matrix_A[i][1]
theta[0] = theta[0] + leraing_rate*(Matrix_y[i]-h)*matrix_A[i][0]
theta[1] = theta[1] + leraing_rate*(Matrix_y[i]-h)*matrix_A[i][1]
for i in sampleindex :
Error = 0
Error = theta[0]*matrix_A[i][0] + theta[1]*matrix_A[i][1] - Matrix_y[i]
Error = Error*Error
loss = loss +Error
iters = iters +1
print ('theta=',theta)
print ('iters=',iters)
"""
本文来自:http://blog.csdn.net/zbc1090549839/article/details/38149561
仅供学习基础知识。