对学习器的泛化性能进行评估,不仅需要有效的实验估计方法,还需要有衡量模型泛化性能的评准指标,这就是性能度量。性能度量反应任务需求,对比不同模型能力时,使用不同性能度量能导致不同的评判结果。因此,模型的好坏是相对的,模型不仅取决于算法和数据,还绝对于任务需求。
1. 回归任务中常用的性能度量是“均方误差”(mean squared error)
2. 聚类任务中性能度量分为两类:一类是将聚类结果与某个“参考模型”(reference model)进行比较,成为“外部指标”(external index);另一类是直接考察聚类结果而不利用任何参考模型,成为“内部指标”(internal index)。
3. 分类任务中常用的性能度量
3.1 错误率和精度
错误率是分类错误的样本数占样本总数的比例
精度(accuracy)是分类正确的样本数占样本总数的比例
精度=1-错误率
3.2 查准率、查全率与F1
查准率(precision),亦是“准确率”,表示查出来为正确的信息有多少是正确的
查全率(recall),亦是“召回率”,表示查出来为正确的信息占总共正确信息的比例
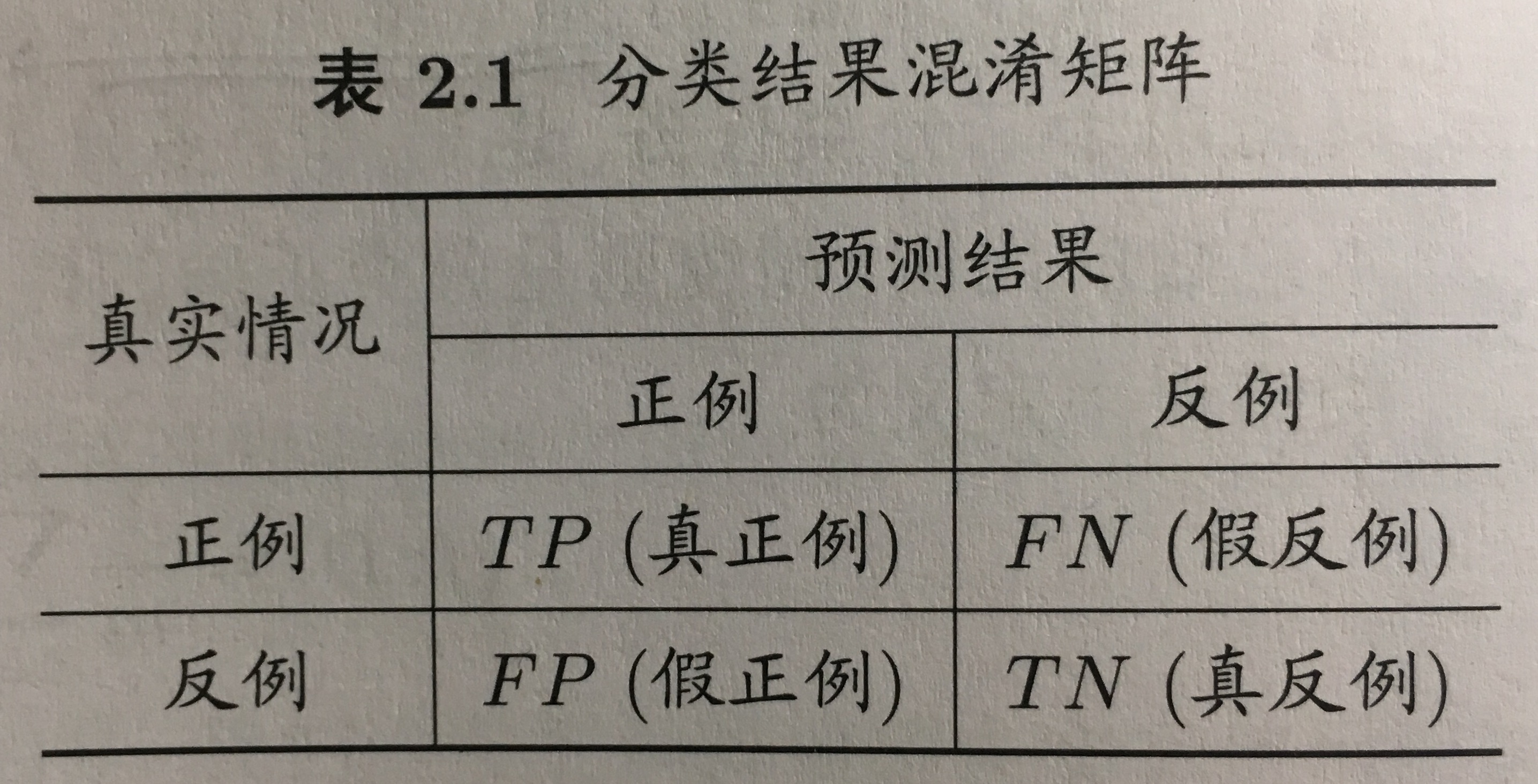
对于二分类问题,可将阳历根据真实类别与学习器预测类别的组合划分为真正例(true positive),假正例(false positive),真反例(true negative),假反例(false negative)四种情况,因此TP+FP+TN+FN=样本总数。分类结果的“混淆矩阵”(confusion matrix)如下
所以查准率P和查全率R分别为:

一般来说,查准率搞得时候, 查全率往往偏低,反之亦然。他们的关系“P-R曲线”如下图:
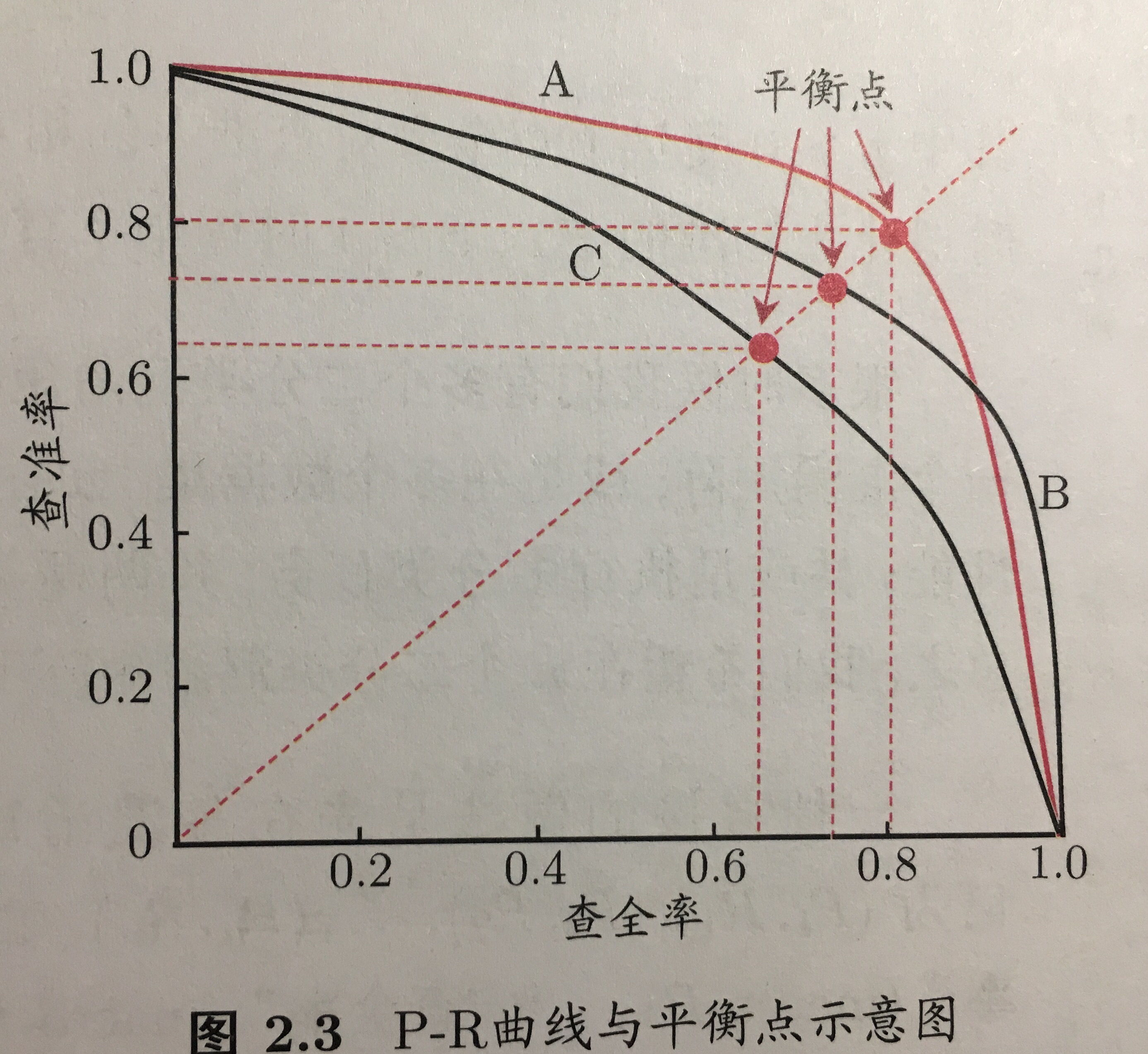
如果一个学习器的P-R曲线把另外一个学习器的曲线包住,则断言前者优于后者。如果两者相交,则不容易观察,因此常用F1来度量,综合考察查准率和查全率。
F1是基于查准率和查全率的调和平均(harmonic mean):
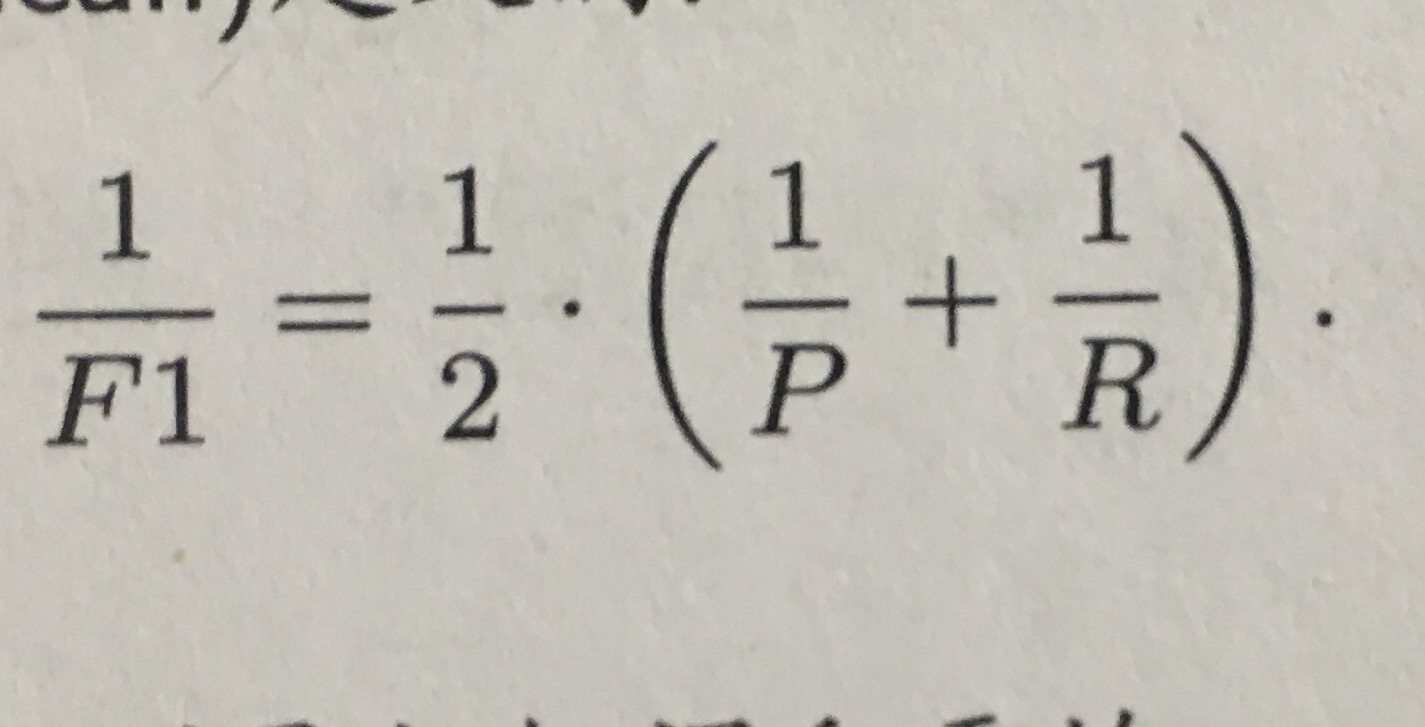
简化得到:
考虑到由于任务要求不同,对查全率和查准率的偏好不同,还有加权调和平均,在参考书1的第2章。与算数平均((P+R)/2)和几何平均相比,调和平均更重视较小值。但最终我们需要的是查准率和查全率都尽可能高,F1可以很好反应这一点,当查准率和召回率都高的时候,F1的值也高。
对于分类器比较,F1数值越大越好。
3.3 ROC与AUC
3.4 代价敏感错误率与代价曲线
参考书:《机器学习》周志华
《统计学习方法》 李航