一、视频学习心得及问题总结
1. 学习心得
王嘉毅:
在《深度学习数学基础》中,我对机器学习三要素(模型、策略、算法)、频率学派&贝叶斯学派、因果推断和群体智能有了初步了解。
机器学习中的主要数学基础有三:线性代数、概率统计和微积分。线性代数在深度学习中作为数据表示和空间变换的有力工具,概率统计是模型假设和策略设计的关键方法,而微积分则是求解目标函数具体算法的数学基础。梯度下降十分重要,是神经网络的共同基础。概率和函数两种形式看似两相对立,实则有机统一,经验风险最小化策略与极大似然策略优化得到的模型参数是一致的。此外,频率学派主要关注可独立重复的随机试验中单个事件发生的概率,其模型参数唯一,需要从有限的观测数据中采用极大似然估计法来估计参数值;而贝叶斯学派则主要关注随机事件的可信程度,其模型参数是随机变量,需要采用最大后验估计法估计参数的整个概率分布。
在《卷积神经网络》中,我对卷积神经网络的应用、其与传统神经网络的差异、以及卷积神经网络的基本组成结构(卷积、池化、全连接)和卷积神经网络的典型结构(AlexNet、ZFnet、VGG、GoogleNet、ResNet)有了初步了解。
卷积神经网络(CNN)在计算机视觉中有重要应用(图像检测、分割、分类、检索、人脸识别、图像生成、风格转化、自动驾驶等)。一个典型的卷积神经网络由卷积层、池化层和全连接层构成。全连接层通常在卷积神经网络的尾部。通过学习五大经典CNN结构,我对卷积神经网络有了一个更为深入的认识。
课程记录如下:
◆ 深度学习——数学基础
◆ 深度学习——卷积神经网络
王泓元:
今天,机器学习的不同方法来源于概率,对机器学习进行研究也需要一定的数学基础。学好数学可以让学习机器学习变得事半功倍。
对于卷积神经网络,人脸识别、图像生成、自动驾驶都是卷积神经网络的基本应用。通过视频资料,对其有了初步的认识,比较难的地方还需要继续学习才能理解。
范新东:
学习了深度学习的部分数学基础,了解了深度学习的大致流程,对其产生了新的见解和认识。
过程笔记:
◆ 卷积神经网络笔记
万文龙:
1. 深度学习数学基础:
自编码器通过函数将输入信息x映射到隐藏空间h,然后再将映射到输出y,前半部分就是编码器,后半部是解码器,并且自编码器通过求解映射使得输入x与输入y的误差最小。自编码器通常用来数据去噪和降维。
神经网络中梯度下降的方式逼近,一般会落在局部最小值处。目前理解神经网络就相当于求解一个多维函数(这里是损失函数)的最小值,从而或者最小值处的权重参数。神经网络中可以通过线性变换实现对输入进行升维降维、放大缩小、旋转平移等。
训练误差到泛化误差。机器学习从训练数据中不断学习使得训练误差不断缩小,说明对训练数据集能够很好地拟合。而在应用当中,实际数据与训练数据不同,如果在这些数据集中的误差也比较小,说明有很好的泛化性。
无免费午餐定理和奥卡姆剃刀原理。前者指出一个算法不可能方方面面都好;后者让我们在解决问题时尽量选择最简单的模型,仅从字面上我就非常赞同这两条。
欠拟合和过拟合,模型的训练误差或泛化误差较大。损失函数,预测值和真实值之间的误差。
2. 卷积神经网络:卷积神经网络的应用:图片的分类检测分割、人脸识别、人脸表情识别、图像生成等。
传统神经网络和卷积神经网络。传统神经网络的参数过多,可能导致过拟合;卷积神经网络实现了局部关联和参数共享,解决了这一问题。权值共享说的是用一个filter(卷积核)扫描图像,这样某个位置都被同一个filter扫过,它们共享这个filter的权重;局部关联说的是,卷积的输出中每一个点只和输入中对应位置的卷积核大小的矩阵包含的点有关,而全连接中输出每一个点和输入所有点相关。因此CNN解决了参数过多的问题。
卷积操作是,将卷积核在输入矩阵上按顺序扫描,对于每个位置,输入为选中小矩阵每个点分别于卷积核上对应的点相乘; 池化和卷积类似,可以防止过拟合并减少计算量。
AlexNet:包含5个卷积层和2个全连接隐藏层和1个全连接输出;并且AlexNet使用ReLU代替sigmoid作为激活函数,收敛更快;采用丢弃法(DropOu),训练中丢弃部分数据;采用图像平移、翻转、裁剪等,扩大数据集,防止过拟合。
VGG:使用更深网络,使用多个33的卷积层和22的maxpooling,。
GoogLeNet:使用多个Inception块,没有额外全连接层。Inception使用4个并行的卷积核(11,33,5*5)进行串联。
ResNet:残差学习,输出F(x)+x,突出细微变化,能够用于更深层网络。
单岳超:
卷积神经网络是一种深度学习模型或类似于人工神经网络的多层感知器,常用来分析视觉图像。卷积神经网络的层级结构可分为5类:数据输入层、卷积计算层、ReLU激励层、池化层 、全连接层。它的算法同一般机器学习算法,先定义Loss function,衡量和实际结果之间差距,找到最小化损失函数的W和b, CNN中用的算法是SGD(随机梯度下降)。
卷积神经网络的优缺点:优点:1.共享卷积核,对高维数据处理无压力。2.无需手动选取特征,训练好权重,即得特征分类效果好。缺点:1.需要调参,需要大样本量,训练最好要GPU。2.物理含义不明确(神经网络本身就是一种难以解释的“黑箱模型”)。
Ps:看完视频还是没搞懂有些概念,懵懵懂懂的。
2. 问题总结:
王嘉毅:
在视频学习过程中,我对变分自编码器的实现、逐层预训练的具体实现过程、损失函数的数学求解过程、GoogleNet和ResNet的结构仍有疑惑,需要继续具体地深入研究学习。
王泓元:
1. 对损失函数的具体作用比较模糊,同时也很难记忆它的公式;
2. 良好的数学基础对学习机器学习是否关键?
范新东:
对于各个深度学习框架还没有详细的了解,无法知道具体的工作原理。
万文龙:
1. 玻尔兹曼机和受限玻尔兹曼机的原理;
2. 自编码器有不同种类,例如正则化编码器给出了一个L2正则化的公式,这些公式在自编码器中具体会应用到哪一层?
3. ResNet残差块输出的是F(x)+x,和F(x)-x,F(x)+ax有什么区别吗,将某层的filter权重加1是不是也可以实现?
单岳超:
1. 卷积神经网络具体怎么训练?
2. 卷积神经网络有哪些大胆而新奇的网络结构?
二、代码练习(关键步骤截图、想法和解读)
1. MNIST 数据集分类:

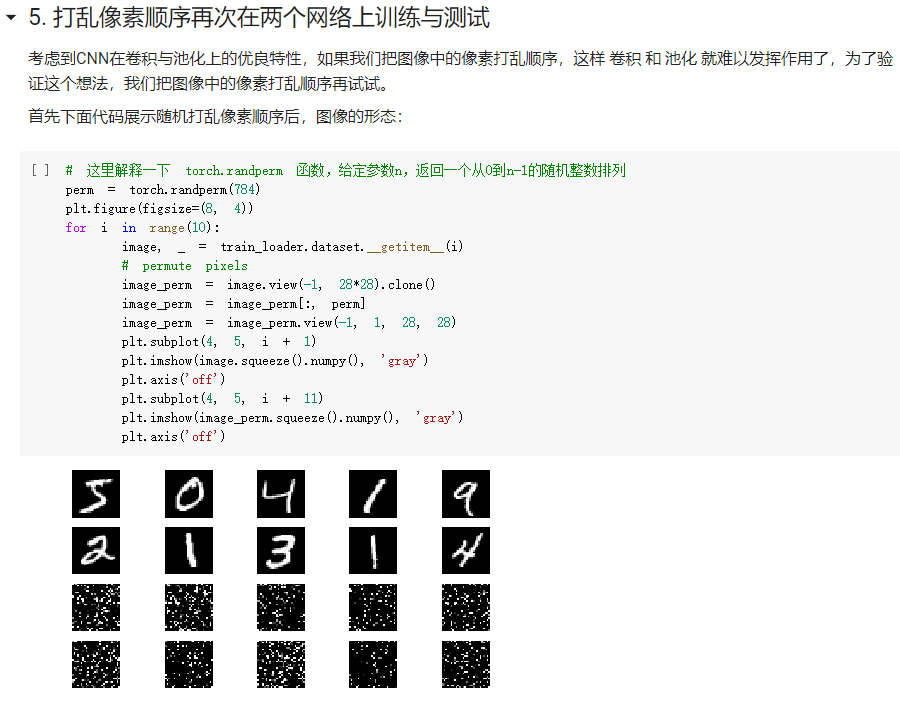
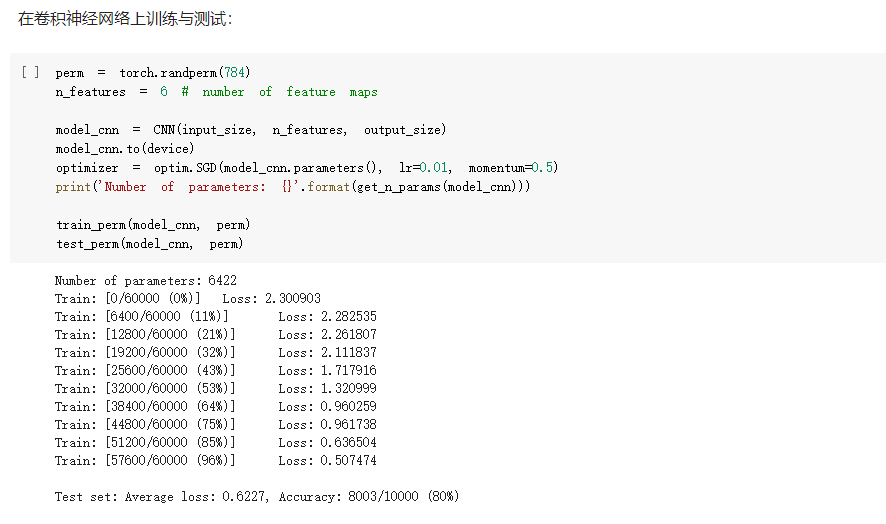
2. CIFAR10 数据集分类:


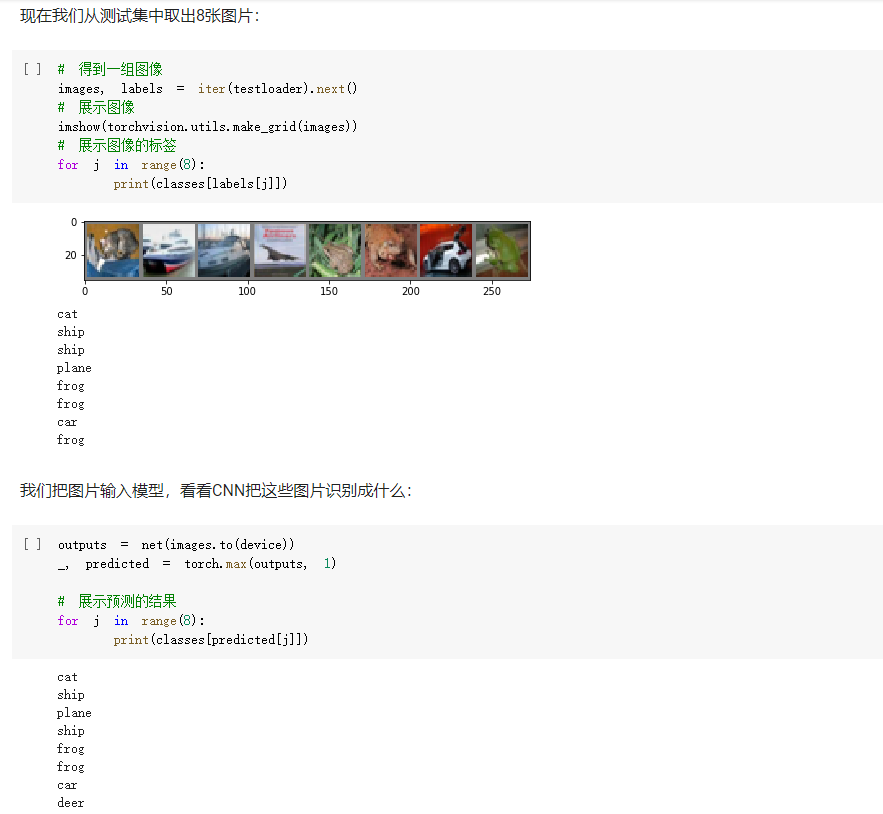
3. 使用 VGG16 对 CIFAR10 分类:


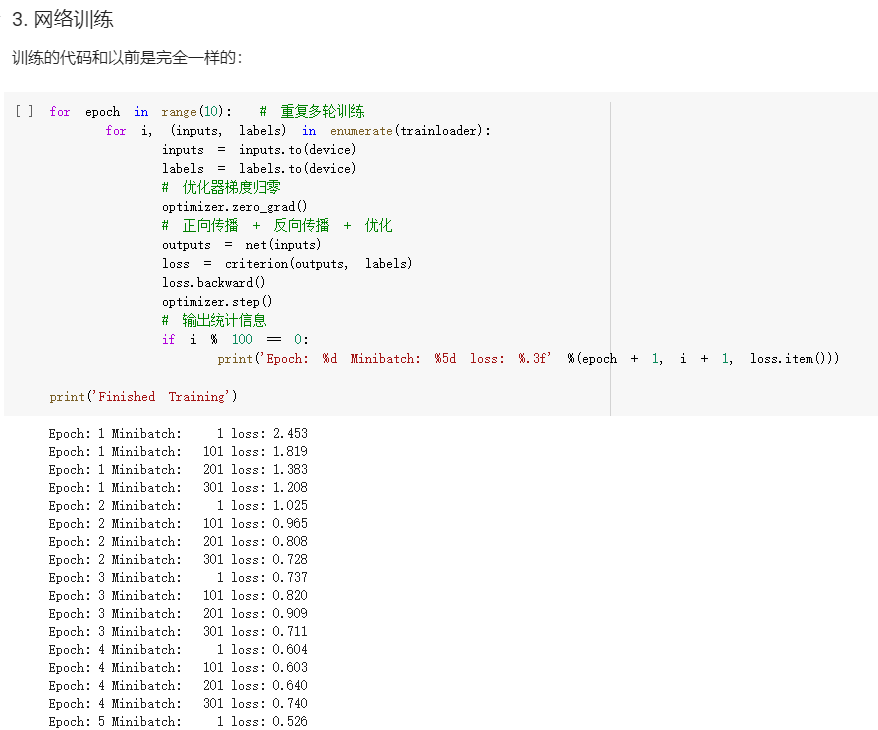
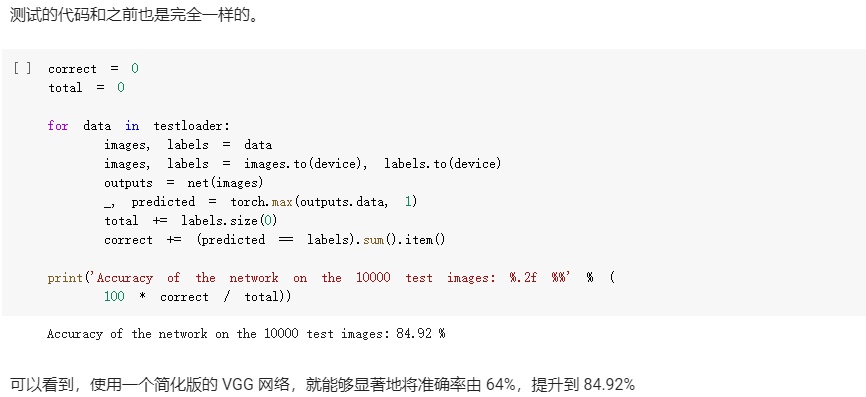
思考:
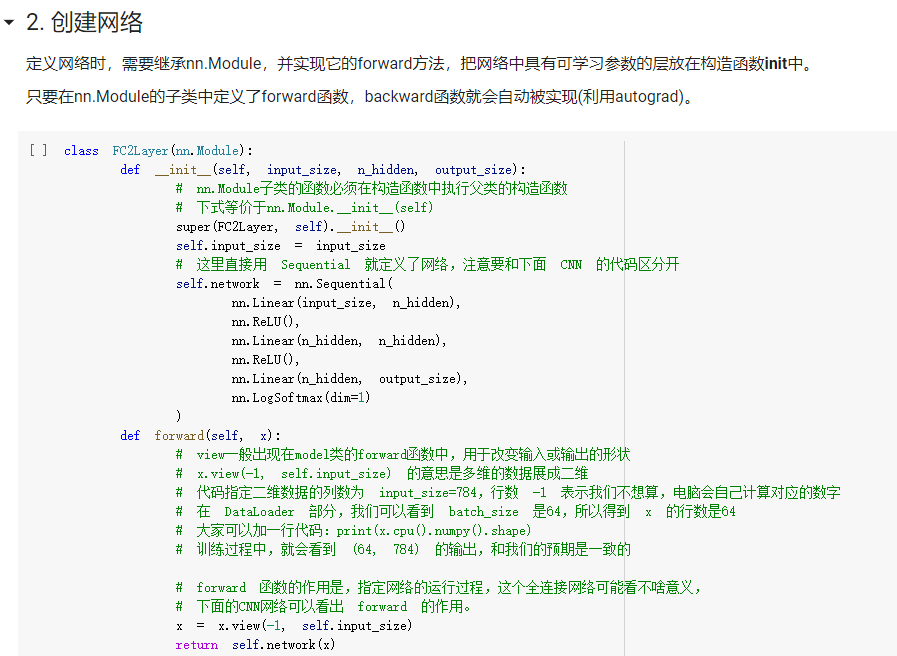
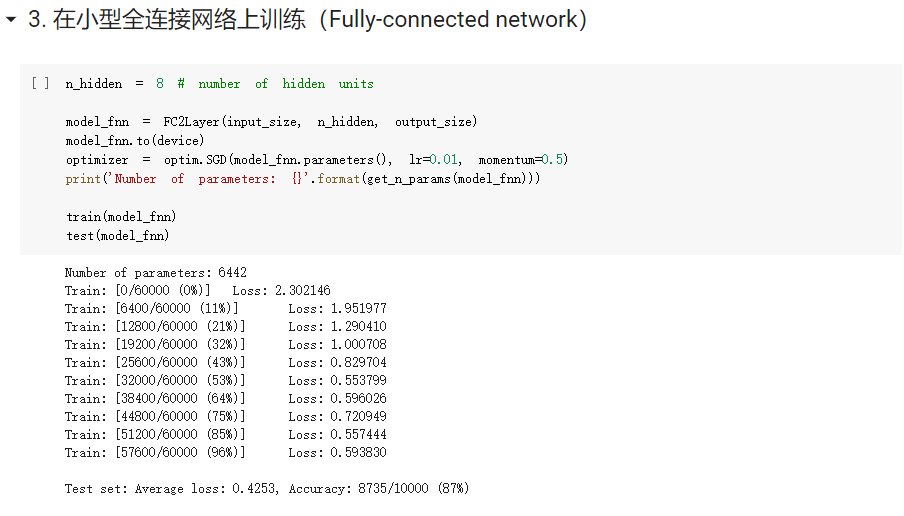
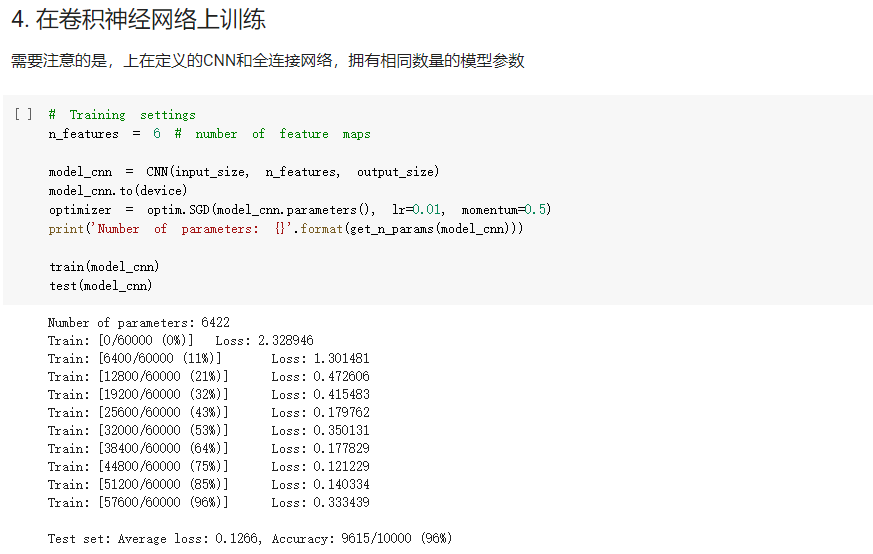
- FC2Layer中包括3个全连接层,全连接层之间使用ReLU作为激活函数,以及最后Softmax层作为输出;CNN使用2个卷积层,2个最大池化层,2个全连接隐藏层,中间使用relu作为激活函数,最后softmax层输出。在训练时采用最常见的SGD作为优化算法。结果显示,同样参数个数下,在正常输入时CNN的训练误差要小于FC2Layer,而在打乱像素顺序后CNN效果稍微比FC2Layer差。
- CNN的卷积层和池化层对比普通的全连接层,首先是卷积层和全连接层需要的参数的数量要远少于全连接层(相同层数),而代码结果显示同样参数CNN也更出色;由于卷积层和池化层是在输入矩阵中不断的从左至右从上到下扫描,包含有一定的空间信息,因此打乱像素就会打乱这一空间信息,从而影响CNN的结果。
- 网络结构为2个卷积层和2个池化层和2个全连接的隐藏层和1个全连接输出层,损失函数采用交叉熵损失函数,优化算法为Adam算法。最后CNN根据计算,输出预测值最大的作为最后的预测结果。