前言
这篇博客介绍了一个基于 Deep Q-network(DQN) 改进的网络框架 Deep Recurrent Q-network (DRQN) 。DRQN 在网络中引入了 long short-term memory (LSTM) 结构,使网络具有记忆性。使网络在仅接受单帧状态作为输入时,也可以达到一定的游戏水平。并且 DRQN 还可以一定程度上解决游戏状态仅部分可知的环境(类似于星际争霸的战争迷雾)。当前顶尖的游戏 AI 如 Alpha Star, OpenAI Five 都在其网络中使用了 LSTM 结构。该论文或许可以为理解这些顶级 AI 为何使用该结构提供理解上的帮助。
论文信息
- Title : Deep Recurrent Q-Learning for Partially Observable MDPs
- Authors : Hausknecht Matthew ; Stone Peter
- Year : 2015
- APA Ref : Hausknecht, M., & Stone, P. (2015, September). Deep recurrent q-learning for partially observable mdps. In 2015 AAAI Fall Symposium Series.
- In-text cication : Hausknecht & Stone , 2015
Abstract :
Deep Reinforcement Learning has yielded proficient controllers for complex tasks. However, these controllers have limited memory and rely on being able to perceive the complete game screen at each decision point. To address these shortcomings, this article investigates the effects of adding recurrency to a Deep Q-Network (DQN) by replacing the first post-convolutional fully-connected layer with a recurrent LSTM. The resulting Deep Recurrent Q-Network (DRQN), although capable of seeing only a single frame at each timestep, successfully integrates information through time and replicates DQN's performance on standard Atari games and partially observed equivalents featuring flickering game screens. Additionally, when trained with partial observations and evaluated with incrementally more complete observations, DRQN's performance scales as a function of observability. Conversely, when trained with full observations and evaluated with partial observations, DRQN's performance degrades less than DQN's. Thus, given the same length of history, recurrency is a viable alternative to stacking a history of frames in the DQN's input layer and while recurrency confers no systematic advantage when learning to play the game, the recurrent net can better adapt at evaluation time if the quality of observations changes.
核心思想
神经网络的记忆力
该文章提出的 DRQN 利用 LSTM 使智能体有了记忆力。在 DQN 的论文中,智能体接受到的游戏状态是连续的四帧。其实并非一定要是连续的四帧,论文提到也可以是连续的三帧或者五帧。但一定要是连续的多帧。因为单帧的游戏状态有时候无法完整的表达所有的游戏信息。以 Atarti 的 Pong 游戏为例。

上图是 Pong,这个游戏很简单,游戏双方各操控一个长方形白块,有一个球在两者之间移动。木板碰到球时,球就会弹回去。没有接到球的一方判负。
对于该游戏,假设仅有单帧游戏状态,那么能知道的信息有双方白块的位置,和球的位置。但球的移动方向,移动速度,白块的移动方向,移动速度都没法得知。只有在连续多帧的游戏状态中,才能得到上述的信息。假设仅利用不完美的游戏信息来进行行动决策,那么此时的决策过程就被称为 Partially-Observable Markov Decision Process (POMDP)。假设仅使用单帧的游戏状态,那么 DQN 在玩 Pong 时就变成了 POMDP 的情况,而 DQN 并不能很好的处理 POMDP。此外固定的游戏帧数具有局限性,对于其他类型的问题,可能游戏信息需要更多的游戏帧数来获得。因此论文作者基于 DQN 引入了 LSTM 结构,使网络具有记忆性,从而可以对之前的游戏状态进行记录。利用 LSTM 结构来决定 “记住” 什么,“忘记” 什么。
Deep Recurrent Q-network
网络结构

DRQN 的网络结构和 DQN 类似。不同之处仅在于在网络最后的全连接层被替换成了 LSTM。具体的网络结构参数如图所示。
基于完整游戏轮数的采样
DQN 中更新网络的方式是从 replay buffer 采样连续的4帧。在 DRQN 中,采样更新网络的方式有两种,一种是采样完整的 episode ,然后从 initial state 开始作为输入更新网络。第二种更新方式是采样完整的 episode,然后从随机的时间点开始作为第一个状态来更新网络。实验结果证明两种方式都是有效的,但是从逻辑上来说,第二种方法更合理一点。因为第一种方法违反了 DQN 随机采样的原则。
闪烁乒乓游戏
论文里为了将 PONG 游戏原本的从 MDP 变为 POMDP ,采用随机将游戏状态抹除的方式(可以想象从将所有像素点的值都置为0)来得到。感觉这是一个挺有意思的实验室方式。
实验结果
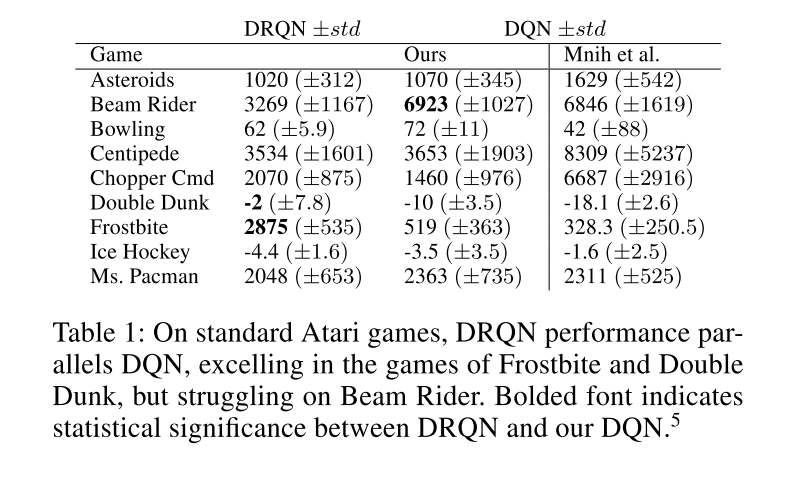
最后论文作者对比了 DRQN 在 Atrai 游戏中的效果。其中 ours DQN 是使用连续十帧作为输入的 DQN可以看到 DRQN 在 Double Dunk 和 Frostbite 中有较好的效果。这两个游戏都是需要用多帧去表示游戏状态的。
总结
当下的深度强化学习网络中都使用到了 LSTM 结构,个人认为该论文可以为为什么要使用这个结构给出一个比较好的解释。