一、基础普及
|
|
接口(interface) |
类(class) |
继承类 |
实现的接口 |
|
Array |
√
|
|
|
|
|
Collection |
√ |
|
|
|
|
Set |
√ |
|
Collection |
|
|
List |
√ |
|
Collection |
|
|
Map |
√ |
|
Collection |
|
|
Vector |
|
√ |
|
List |
|
ArrayList |
|
√ |
|
List |
|
HashMap |
|
√ |
|
Map |
|
Hashtable |
|
√ |
Dictionary |
Map |
|
ConcurrentMap |
√ |
|
Map
|
|
|
ConcurrentHashMap
|
|
√ |
|
ConcurrentMap |
二、对比
1、HashMap与Hashtable区别
|
|
是否线程安全 |
允不允许null值 |
|
Hashtable |
线程安全。 因为里面的方法使用了synchronized进行同步 |
不允许。 key和value都不允许出现null值,否则会抛出NullPointerException异常。 |
|
HashMap |
非线程安全。 可以通过以下方式进行同步: Map m = Collections.synchronizeMap(hashMap); |
允许。 null可以作为键,这样的键只有一个;可以有一个或多个键所对应的值为null。 |
Tip:
1、Hashtable是线程安全的,多个线程可以共享一个Hashtable;而如果没有正确的同步的话,多个线程是不能共享HashMap的。Java 5提供了ConcurrentHashMap,它是HashTable的替代,比HashTable的扩展性更好。
2、由于Hashtable是线程安全的也是synchronized,所以在单线程环境下它比HashMap要慢。如果你不需要同步,只需要单一线程,那么使用HashMap性能要好过Hashtable。
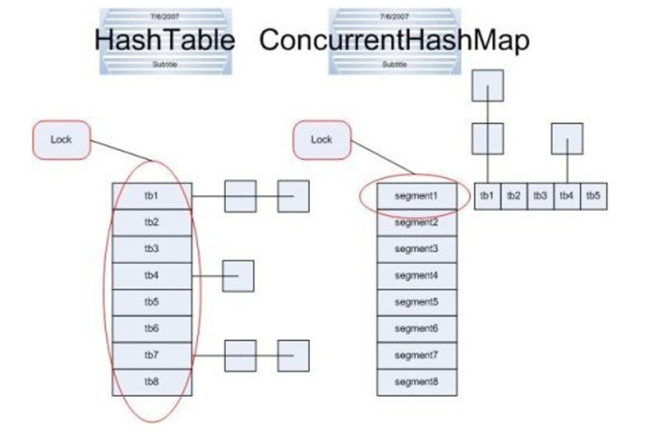
2、Hashtable和ConcurrentHashMap在lock表区别图
三、java并发包(java.util.concurrent)
1、线程池:
1.1、为什么要用到线程池
使用线程池的好处是减少在创建和销毁线程上所花的时间以及系统资源的开销,解决资源不足的问题。
如果不使用线程池,有可能造成系统创建大量同类线程而导致消耗完内存或者“过度切换”的问题。
1.2、线程池创建方式(常用)
1)固定数量的线程池newFixedThreadPool
int cpu = Runtime.getRuntime().availableProcessors();
final ExecutorService es = Executors.newFixedThreadPool(cpu);
2)可调度的线程池Scheduled Thread Pool :
ScheduledExecutorService scheduledThreadPool = Executors.newScheduledThreadPool(4);
2、Java容器:
2.1、同步类容器
第一类:
同步类:Vector、Stack、Hashtable
非同步类:ArrayList、LinkedList、HashMap
第二类:Collections提供的一些工厂类(静态)
2.2、并发类容器
java.util.concurrent提供了多种并发容器,总体上来说有4类:
- 队列Queue类型的BlockingQueue和ConcurrentLinkedQueue
- Map类型的ConcurrentMap
- Set类型的ConcurrentSkipListSet和CopyOnWriteArraySet
- List类型的CopyOnWriteArrayList
在并发比较大的情况下,用ConcurrentMap来替代HashTable
使用CopyOnWriteArrayList替代Vector
2.3、concurrentHashMap
2.3.1、为什么采用concurrentHashMap:
Hashtable写操作会锁住整张表,效率低,写操作无法并行
concurrentHashMap分成16个桶(把整张表分成16份),适合高并发
2.3.2、ConcurrentHashMap介绍:
ConcurrentHashMap采用了分段锁的设计,只有在同一个分段内才存在竞态关系,不同的分段锁之间没有锁竞争。
相比于对整个Map加锁的设计,分段锁大大的提高了高并发环境下的处理能力。
2.3.3、Hashtable和ConcurrentHashMap在lock表区别图
2.3.4、ConcurrentSkipListMap
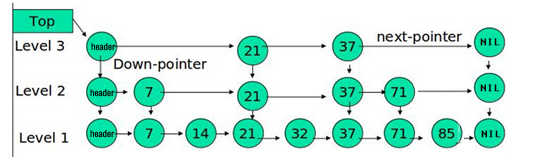
跳表查询,比ConcurrentHashMap效率快。
四、Java并发包消息队列
1、BlockingQueue 阻塞队列
主要的方法是:put、take一对阻塞存取;add、poll一对非阻塞存取。
put(anObject):把anObject加到BlockingQueue里,如果BlockQueue没有空间,则调用此方法的线程被阻塞直到BlockingQueue里面有空间再继续。
take():取走BlockingQueue里排在首位的对象,若BlockingQueue为空,阻断进入等待状态直到Blocking有新的对象被加入为止。
2、BlockingQueue成员介绍
2.1、ArrayBlockingQueue:
基于数组实现的有界阻塞队列,查找快,增删慢。生产者和消费者用的是同一把锁,并发效率低
消费的方式:FIFO
2.2、LinkedBlockingQueue:
基于链表实现的阻塞队列,链表是增删快,定位慢,生产者和消费者用的锁相互独立,并发性能略高于ArrayBlockingQueue
2.3、DelayQueue(延时队列):
DelayQueue中的元素,只有指定的延迟时间到了,才能够从队列中获取到该元素。
DelayQueue是一个没有大小限制的队列,因此往队列中插入数据的操作(生产者)永远不会被阻塞,而只有获取数据的操作(消费者)才会被阻塞
应用场景
1、客户端长时间占用连接的问题,超过这个空闲时间了,可以移除的
2、处理长时间不用的缓存;如果队列里面的对象长时间不用,超过了空闲时间,就移除
3、任务超时处理
2.4、PriorityBlockingQueue(优先级队列):
PriorityBlockingQueue并不会阻塞数据生产者,而只会在没有可消费的数据时,阻塞数据的消费者不阻塞生产者
compareTo()方法决定优先级。
2.5、SynchronousQueue(同步无缓冲队列):
一种无缓冲的等待队列,来一个任务就执行这个任务,这期间不能太添加任何的任务。也就是不用阻塞了,其实对于少量任务而言,这种做法更高效
声明一个SynchronousQueue有两种不同的方式,它们之间有着不太一样的行为。
公平模式和非公平模式的区别:
如果采用公平模式:SynchronousQueue会采用公平锁,并配合一个FIFO队列来阻塞多余的生产者和消费者,从而体系整体的公平策略;
但如果是非公平模式(SynchronousQueue默认):SynchronousQueue采用非公平锁,同时配合一个LIFO队列来管理多余的生产者和消费者,而后一种模式,如果生产者和消费者的处理速度有差距,则很容易出现饥渴的情况,即可能有某些生产者或者是消费者的数据永远都得不到处理。
2.5、concurrentLinkedQueue(高并发无锁队列)