“本篇文章将开始我们训练自己的物体检测模型之旅的第一步—— 数据标注。”
上篇文章介绍了如何基于训练好的模型检测图片和视频中的物体,若你也想先感受一下物体检测,可以看看上篇文章:《手把手教你用深度学习做物体检测(一):快速感受物体检测的酷炫 》。
其实,网上关于数据标注的文章已有很多,但大多数都会有一些细节问题,比如中文编码问题,比如标注的数据放置的目录结构不对导致训练报错的问题等等,而这些问题,在本篇文章中都考虑到了,所以只要你按照步骤一步步来,并且使用本文中的代码,将会避免遇到上面所说的问题。
我们已经知道,物体检测,简言之就是框出图像中的目标物体,就像下图这样:

然而,能够识别出该图中的人、狗、马的模型是经过了大量数据训练得到的,这些训练用的数据,包含了图片本身,图片中的待检测目标的类别和矩形框的坐标等。一般而言,初始的数据都是需要人工来标注的,比如下面这张图:

我们除了要把图片本身喂给神经网络,还要把图片中的长颈鹿、斑马的类别以及在图片中的位置信息一并喂给神经网络,现在你可能会想,类别信息倒还好,看一眼就知道有哪些类别了,但是目标的位置信息如何得到?难道要用像素尺量么?
其实,已经有很多物体检测的先驱者们开发出了一些便捷的物体检测样本标注工具,这里我们会介绍一个很好用的工具——labelImg,该工具已经在github上开源了,地址:https://github.com/tzutalin/labelImg

该工具对于windows、Linux、Mac操作系统都支持,这里介绍windows和Linux下的安装方法,Mac下的安装可以去看项目的README文档。
- Windows
github上提供了windows下的exe文件,下载下来后直接双击运行即可打开labelImg,进行数据的标注,下载链接如下:https://github.com/tzutalin/labelImg/files/2638199/windows_v1.8.1.zip - Linux
Linux下的安装,需要从源码构建,README文档中提供了python2 + Qt4和python3+Qt5的构建方法,这里仅介绍后者,在终端中输入以下命令:
--构建
sudo apt-get install pyqt5-dev-tools
sudo pip3 install -r requirements/requirements-linux-python3.txt
make qt5py3
--打开
python3 labelImg.py
python3 labelImg.py [IMAGE_PATH] [PRE-DEFINED CLASS FILE]
无论是windows还是linux下,都提供了一个预定义的类别文件,data/predefined_classes.txt,其内容如下:

这是方便我们在标注目标类别的时候可以从下拉框中选择,所以当然也可以修改这个文件,定义好自己要检测的目标的类别,支持中文。
接下来,我们以windows为例,双击labelImage.exe,稍等几秒钟,就会看到如下界面:

然后,我们加载一个图片目录,第一张图片会自动打开,此时我们按下 w 键,就可以标注目标了,如果发现快捷键不能用,可能是目前处在中文输入法状态,切换到英文状态就好了:
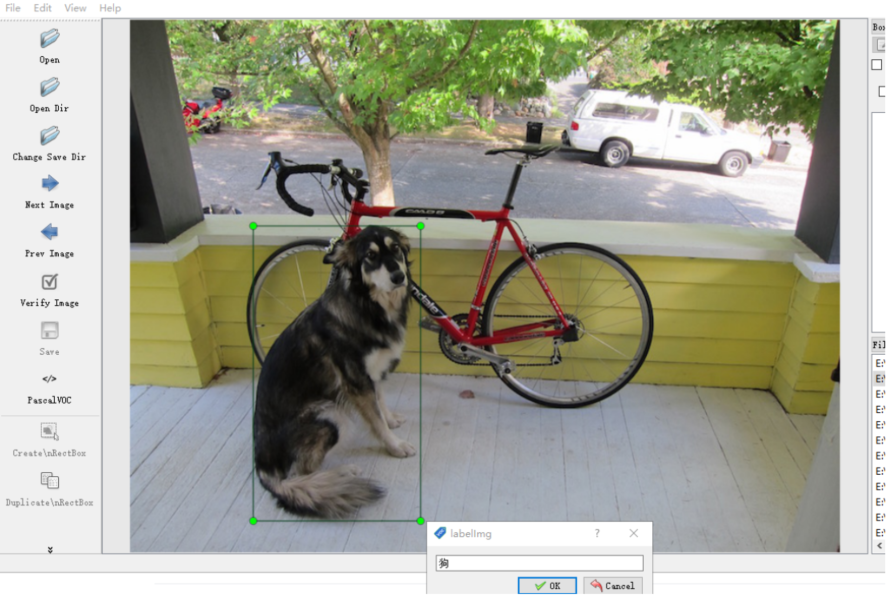
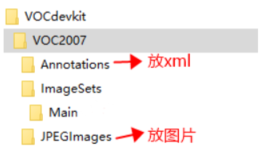
标注完成后记得保存操作,然后按下快捷键 d,就可以切换到下一张继续标注。当所有的图片标注完成后,我们还有一些事情要做,就是按照voc2007的数据集标准将图片和xml文件放到固定的目录结构下,具体的结构如下:
接着,我们要将图片数据集划分成训练集、验证集、测试集,可以使用如下python代码,将该代码文件和ImageSets目录放在同一级执行:
"""
将voc_2007格式的数据集划分下训练集、测试集和验证集
"""
import os
import random
trainval_percent = 0.96
train_percent = 0.9
xmlfilepath = 'Annotations'
txtsavepath = 'ImageSetsMain'
total_xml = os.listdir(xmlfilepath)
num=len(total_xml)
list=range(num)
tv=int(num*trainval_percent)
tr=int(tv*train_percent)
trainval= random.sample(list,tv)
train=random.sample(trainval,tr)
ftrainval = open('ImageSets/Main/trainval.txt', 'w', encoding="utf-8")
ftest = open('ImageSets/Main/test.txt', 'w', encoding="utf-8")
ftrain = open('ImageSets/Main/train.txt', 'w', encoding="utf-8")
fval = open('ImageSets/Main/val.txt', 'w', encoding="utf-8")
for i in list:
name=total_xml[i][:-4]+'
'
if i in trainval:
ftrainval.write(name)
if i in train:
ftrain.write(name)
else:
fval.write(name)
else:
ftest.write(name)
ftrainval.close()
ftrain.close()
fval.close()
ftest .close()
执行后,会在ImageSets/Main目录下生成如下文件:

接下来,可以生成 yolov3 需要的数据格式了,我们使用如下代码,将代码文件和VOCdevkit目录放在同一级执行,注意修改代码中的classes为你想要检测的目标类别集合:
import xml.etree.ElementTree as ET
import pickle
import os
from os import listdir, getcwd
from os.path import join
# sets=[('2012', 'train'), ('2012', 'val'), ('2007', 'train'), ('2007', 'val'), ('2007', 'test')]
sets=[('2007', 'train'), ('2007', 'val'), ('2007', 'test')]
# classes = ["aeroplane", "bicycle", "bird", "boat", "bottle", "bus", "car", "cat", "chair", "cow", "diningtable", "dog", "horse", "motorbike", "person", "pottedplant", "sheep", "sofa", "train", "tvmonitor"]
classes = ["人","狗","鼠标","车"]
def convert(size, box):
dw = 1./(size[0])
dh = 1./(size[1])
x = (box[0] + box[1])/2.0 - 1
y = (box[2] + box[3])/2.0 - 1
w = box[1] - box[0]
h = box[3] - box[2]
x = x*dw
w = w*dw
y = y*dh
h = h*dh
return (x,y,w,h)
def convert_annotation(year, image_id):
in_file = open('VOCdevkit/VOC%s/Annotations/%s.xml'%(year, image_id))
out_file = open('VOCdevkit/VOC%s/labels/%s.txt'%(year, image_id), 'w')
tree=ET.parse(in_file)
root = tree.getroot()
size = root.find('size')
w = int(size.find('width').text)
h = int(size.find('height').text)
for obj in root.iter('object'):
difficult = obj.find('difficult').text
cls = obj.find('name').text
if cls not in classes or int(difficult)==1:
continue
cls_id = classes.index(cls)
xmlbox = obj.find('bndbox')
b = (float(xmlbox.find('xmin').text), float(xmlbox.find('xmax').text), float(xmlbox.find('ymin').text), float(xmlbox.find('ymax').text))
bb = convert((w,h), b)
out_file.write(str(cls_id) + " " + " ".join([str(a) for a in bb]) + '
')
wd = getcwd()
for year, image_set in sets:
if not os.path.exists('VOCdevkit/VOC%s/labels/'%(year)):
os.makedirs('VOCdevkit/VOC%s/labels/'%(year))
image_ids = open('VOCdevkit/VOC%s/ImageSets/Main/%s.txt'%(year, image_set)).read().strip().split()
list_file = open('%s_%s.txt'%(year, image_set), 'w')
for image_id in image_ids:
list_file.write('%s/VOCdevkit/VOC%s/JPEGImages/%s.jpg
'%(wd, year, image_id))
convert_annotation(year, image_id)
list_file.close()
# os.system("cat 2007_train.txt 2007_val.txt 2012_train.txt 2012_val.txt > train.txt")
# os.system("cat 2007_train.txt 2007_val.txt 2007_test.txt 2012_train.txt 2012_val.txt > train.all.txt")
os.system("cat 2007_train.txt 2007_val.txt > train.txt")
os.system("cat 2007_train.txt 2007_val.txt 2007_test.txt > train.all.txt")
执行后,会在当前目录生成几个文件:
2007_train.txt ——训练集
2007_val.txt ——验证集
2007_test.txt ——测试集
train.txt —— 训练集+验证集
train.all.txt —— 训练集+验证集+测试集
我们只需要测试集和训练集,所以保留train.txt和2007_test.txt,其它文件可以删除,然后把train.txt重命名为2007_train.txt(不重命名也可以的,只是为了和2007_test.txt名字看起来风格一致),如此我们就有了两个符合yolov3训练和测试要求的数据集2007_train.txt和2007_test.txt,注意,这两个txt中包含的仅仅是图片的路径。
除了上面的几个文件外,我们还会发现在VOCdevkit/VOC2007目录下生成了一个labels目录,该目录下生成了和JPEGImages目录下每张图片对应的txt文件,所以如果有500张图片,就会有500个txt,具体内容如下:

可以看到,每一行代表当前txt所对应的图片里的一个目标的标注信息,总共有5列,第一列是该目标的类别,第二、三列是目标的归一化后的中心位置坐标,第四、五列是目标的归一化后的宽和高。
当我们得到了2007_train.txt、2007_test.txt、labels目录和其下的txt文件后,数据标注工作就算完成了,那么如何使用这些数据来训练我们自己的物体检测模型呢?
既然我们准备的数据是符合yolov3要求的,那么我们当然是基于yolov3算法来使用这些数据训练出我们自己的模型,具体步骤将会在下一篇《手把手教你用深度学习做物体检测(三):模型训练》中介绍。
ok,本篇就这么多内容啦,感谢阅读O(∩_∩)O,88
名句分享
孩兒立志出鄉関,學不成名誓不還,埋骨何須桑梓地,人生無處不青山。——毛澤東
为您推荐
手把手教你用深度学习做物体检测(一): 快速感受物体检测的酷炫
ubuntu16.04安装Anaconda3
Unbuntu下持续观察NvidiaGPU的状态
想看更多好文?长按识别下方二维码关注涤生吧O(∩_∩)O~