selenium
目录
一、seleniumwebdriver环境搭建
二、selenium浏览器常见操作
三、selenium框架原理
四、cookie管理
正文
一、seleniumwebdriver环境搭建
1.什么是selenium?
selenium是浏览器自动化框架,只是对于测试人员来说,是用来做web自动化测试(基本就是测UI)。
误区:不是单纯的自动化测试框架
1.1 知识对比:
web自动化测试VS接口自动化
--web自动化测试成本高,为什么还要做?
来看看测试金字塔,底层的单元测试unittest一般是开发自己自测,但是国内基本没有开发自测unittest,所以集成测试(接口测试)就比较看重。
接口测试是web自动化测试更重要的。

web自动化测试有具体的测试场景:重复性很高的工作,做web自动化测试比较合适。
比如场景有:冒烟测试,测试主流程的时候;回归测试;正向用例
(接口自动化注重的是测试的覆盖率)
1.2.面试题:做自动化测试是因为时间紧急?---------X
做自动化,编写自动化测试脚本是很费时间的,如果时间紧急,就直接人工测试,更不能实现自动化。
什么时候实现自动化?项目稳定、空闲的时候----(项目没有完成,UI没有实现,元素无法定位等,所以必须要项目稳定才能做web自动化)
接口自动化什么时候实现?接口还没有实现的时候就可以写测试脚本,做自动化,用mock去做。
2.selenium的安装
2.1 安装:pip install selenium
在命令行安装失败,可以在下面的路径里安装
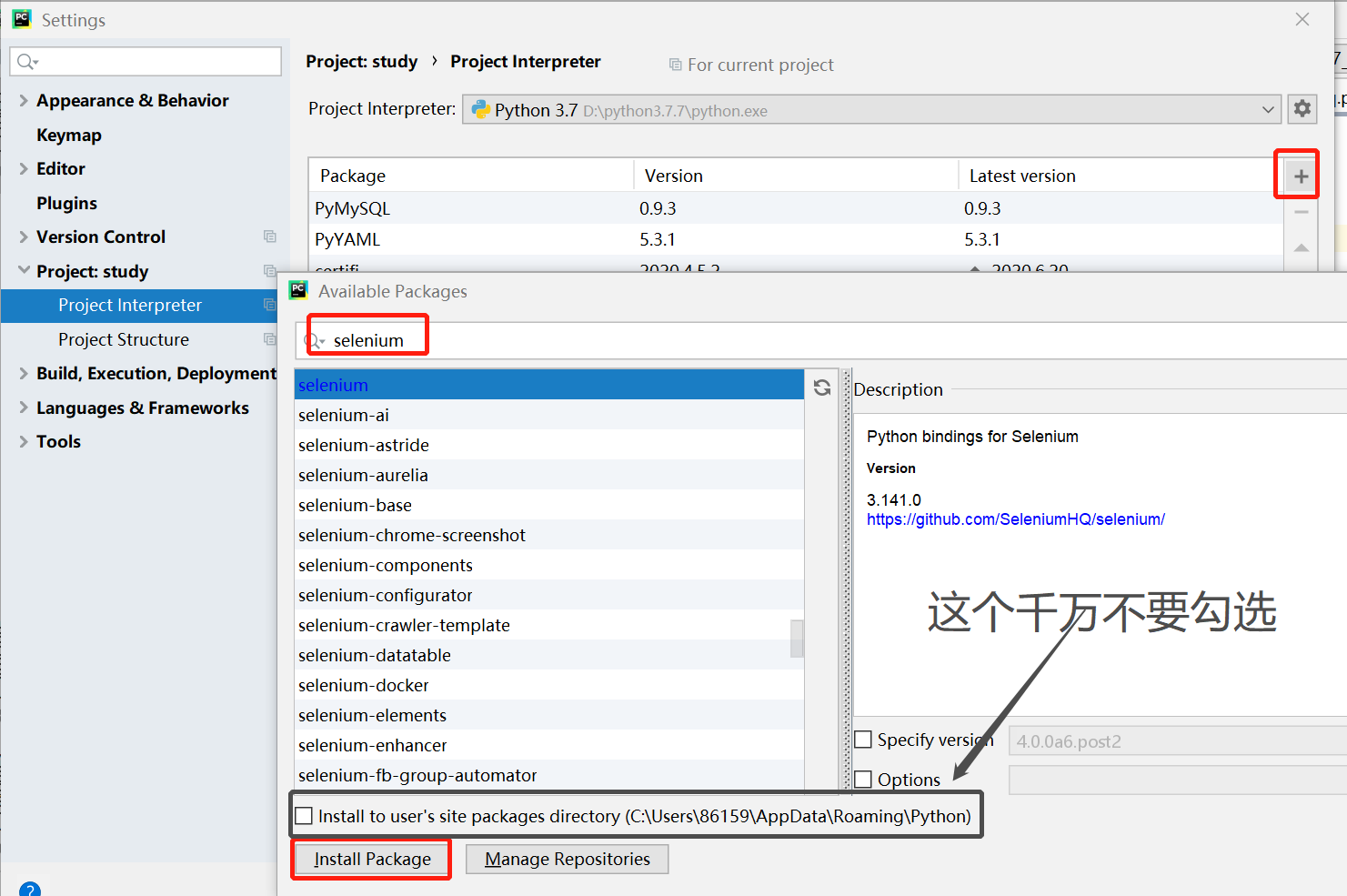
注意,不要勾选上图黑框里的选项,涉及到权限问题。
安装成功,如下,多了了两个库:selenium,urllib3,点击确定即可。

2.2虚拟环境
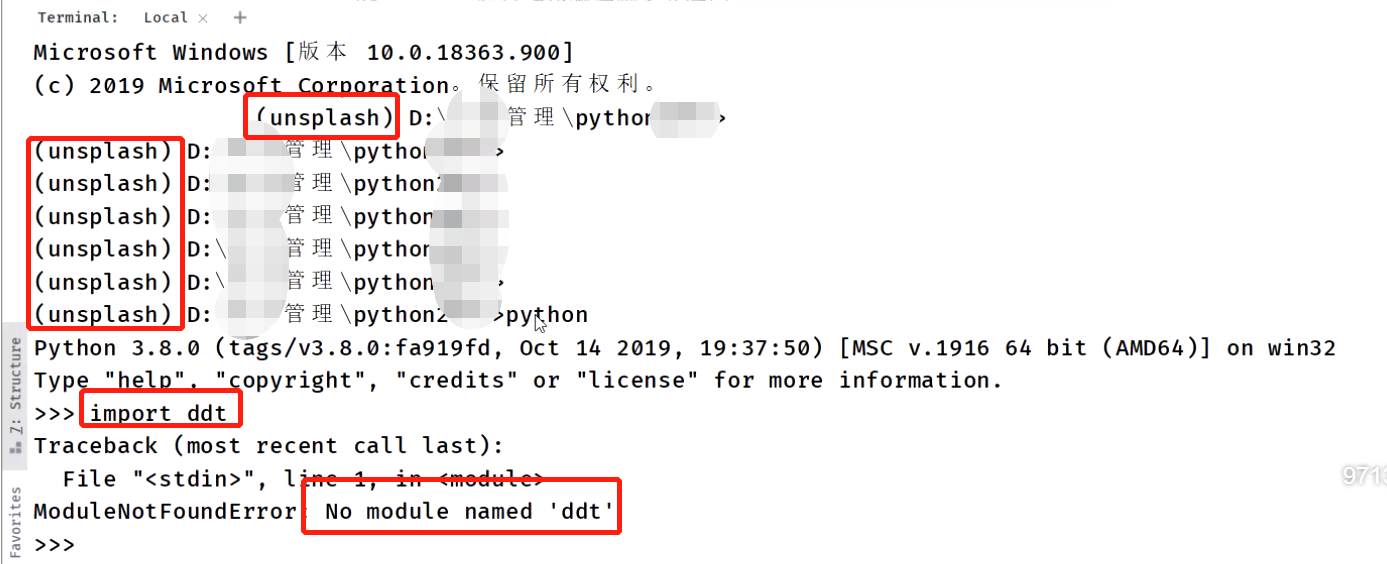
1)如果已经安装了库,但是运行的时候总是报:找不到的错误,说明你可能是在虚拟环境中运行的。
2)如何判断你是在虚拟环境中?-----命令行查看路径前是不是有括号,如下图所示
3)如何设置虚拟环境?---(初学者暂时不需要在虚拟环境中运行!!!)

4)虚拟环境的作用
多个项目的时候,将项目分开.每个项目使用的库是不一样的,安装的库太多,不方便管理,可能会影响别的项目。
所以每个项目放在一个虚拟环境中的。
2.3 下载chromedriver驱动(对应谷歌浏览器)
1)下载地址:https://npm.taobao.org/mirrors/chromedriver 我在这里下载的是71.0.3578.80
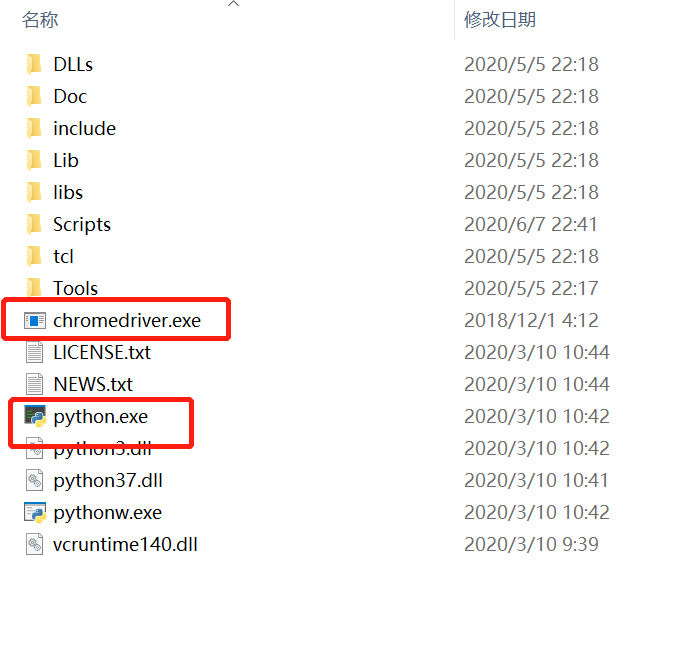
2)将下载好解压的chromedriver.exe放到环境变量的路径中去,我这里放在python的安装根目录里面
2.4 启动浏览器
1)先导入驱动 :from selenium import webdriver
from selenium import webdriver #启动谷歌浏览器 #先安装好chromedriver.exe安装好 driver = webdriver.Chrome()
或者
from selenium.webdriver import Chrome driver = Chrome()
运行即可打开谷歌浏览器
2)如果chromedriver.exe驱动没有放到环境变量中去,可以executable_path去配置
#用executable_path去配置驱动chromedriver.exe driver_new = webdriver.Chrome(executable_path=r"D:chromedriver.exe")
3)常用操作

窗口最大化用的比较多,因为默认窗口不是最大化,打开浏览器一般会先最大化。
代码实现
from selenium import webdriver #先安装好chromedriver.exe
#初始化一个浏览器对象driver
driver = webdriver.Chrome() #打开网址 driver.get("http://www.baidu.com") #窗口最大化 driver.maximize_window() #窗口最小化 driver.minimize_window() #设置窗口大小 driver.set_window_size(800,600) #再次打开一个网址,豆瓣 driver.get("http://douban.com") #后退 driver.back() #前进 driver.forward() #刷新 driver.refresh() #退出 driver.quit()
上面代码运行时,速度快,难以看清楚的话,可以加入休眠时间
导入time库
import time . . . #后退 driver.back() #休眠2s(强制等待) time.sleep(2) #前进 driver.forward() #休眠2s time.sleep(2)

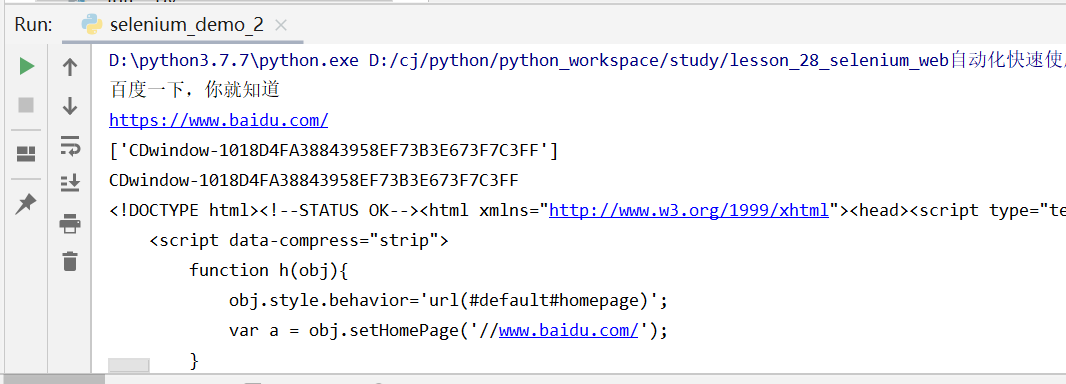
Window_handles:窗口句柄(窗口的id)
current_window_handle:当前窗口句柄
title:网页标题
current_url:当前页面的URL
page_sourde:当前页面的源码(前端编写的HTML的文件,HTML是进行web自动化的依据。元素定位)
代码如下:
from selenium.webdriver import Chrome driver = Chrome() driver.get("http://www.baidu.com") #网页标题 print(driver.title) #网页URL print(driver.current_url) #窗口句柄--就是窗口的id #打开了多少个标签页(窗口),就有多少个元素存在返回的列表中 print(driver.window_handles) #当前窗口句柄 print(driver.current_window_handle) #当前页面的源代码--前端编写的HTML的文件,HTML是进行web自动化的依据。元素定位 print(driver.page_source)
运行结果
4)元素定位 8大元素定位法
元素:网页页面的一个组件
定位:查找要操作的元素的过程
网页中如何定位原代码?
①网页按F12,调出源代码,以百度首页为例,F12调出源码,点击左边的定位符号,在网页中需要定的地方单击(背景蓝色),下面的源码会自动定位到,如下图源码的灰色背景的地方。
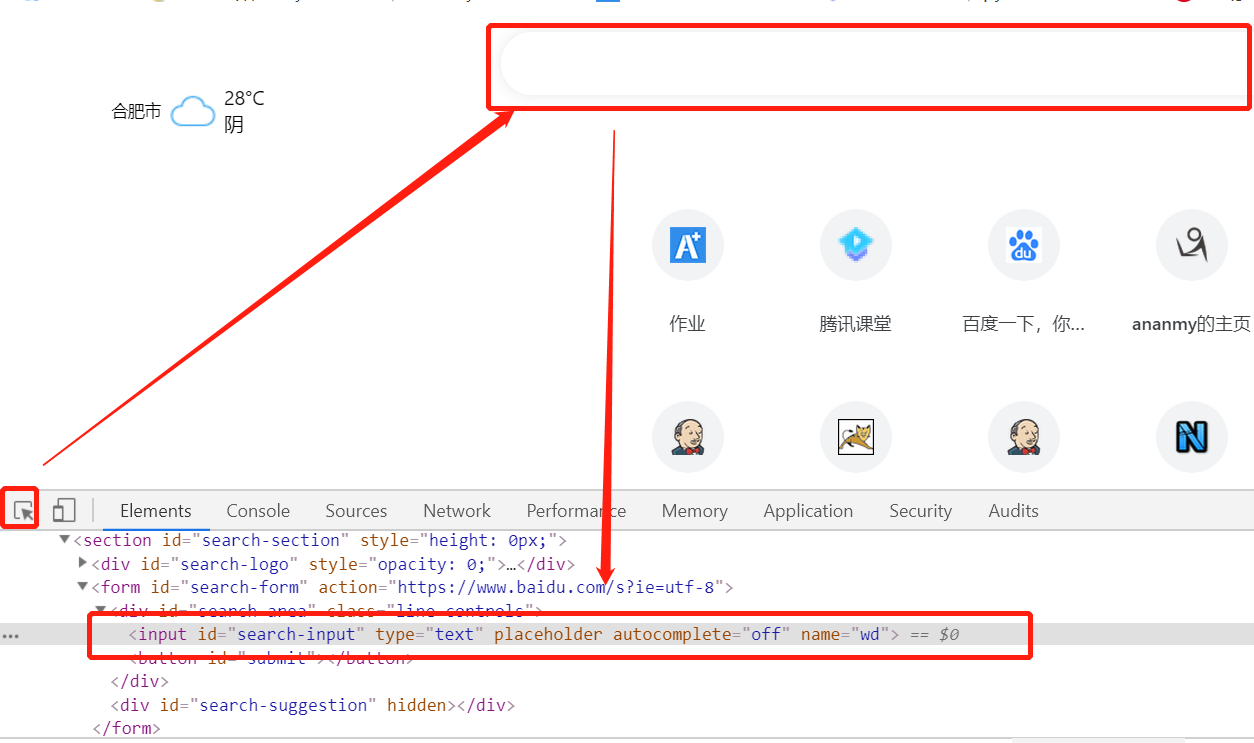
代码实现元素定位
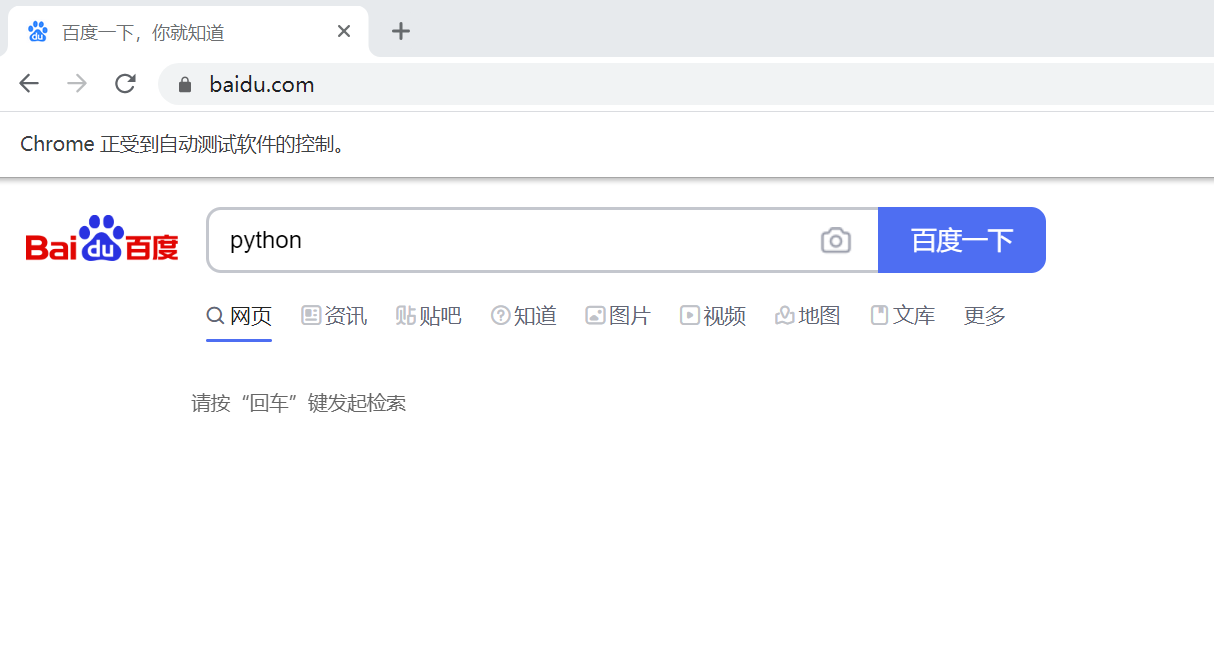
import time from selenium.webdriver import Chrome driver = Chrome() driver.get("http://www.baidu.com") #按id去定位元素 input_elem = driver.find_element_by_id("kw") time.sleep(2) #输入 input_elem.send_keys("python") time.sleep(2)
结果:先弹出下图一,休眠2s弹出下图二

三、selenium架构
我们使用Selenium实现自动化测试,主要需要3个东西
---1.测试脚本,可以是python,java编写的脚本程序(也可以叫做client端)
---2.浏览器驱动, 这个驱动是根据不同的浏览器开发的,不同的浏览器使用不同的webdriver驱动程序且需要对应相应的浏览器版本,比如:geckodriver.exe(chrome)
---3.浏览器,目前selenium支持市面上大多数浏览器,如:火狐,谷歌,IE等
自动化驱动浏览器
webdriver驱动在编程语言跟浏览器之间是桥梁的作用,提供了接口

①selenium发起请求使用什么?---urllib3
上面开始安装selenium的时候,有个依赖urllib3,即使用urllib3发送网络请求。(接口自动化也是依赖了urllib3,只是在urllib3的基础上又封装成request)
②如何证明webdriver提供了接口
直接打开webdriver.exe,弹出如下图:
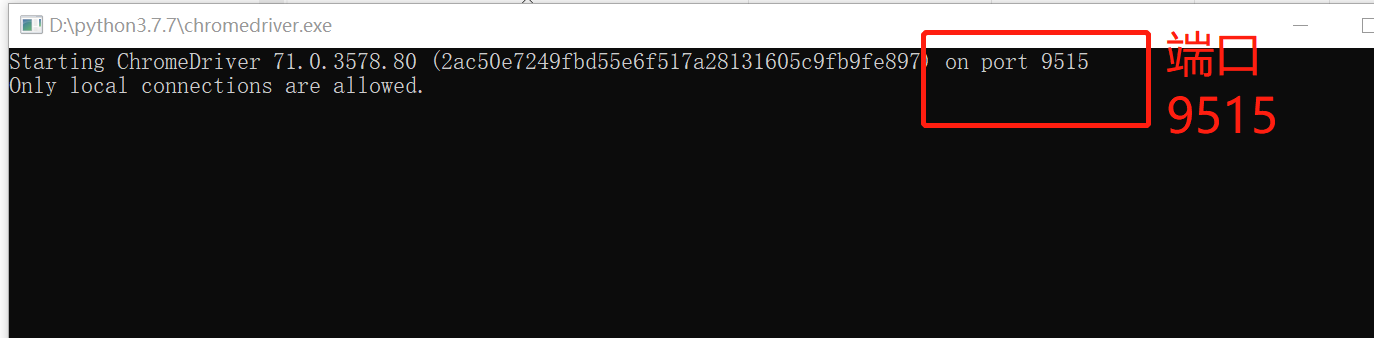
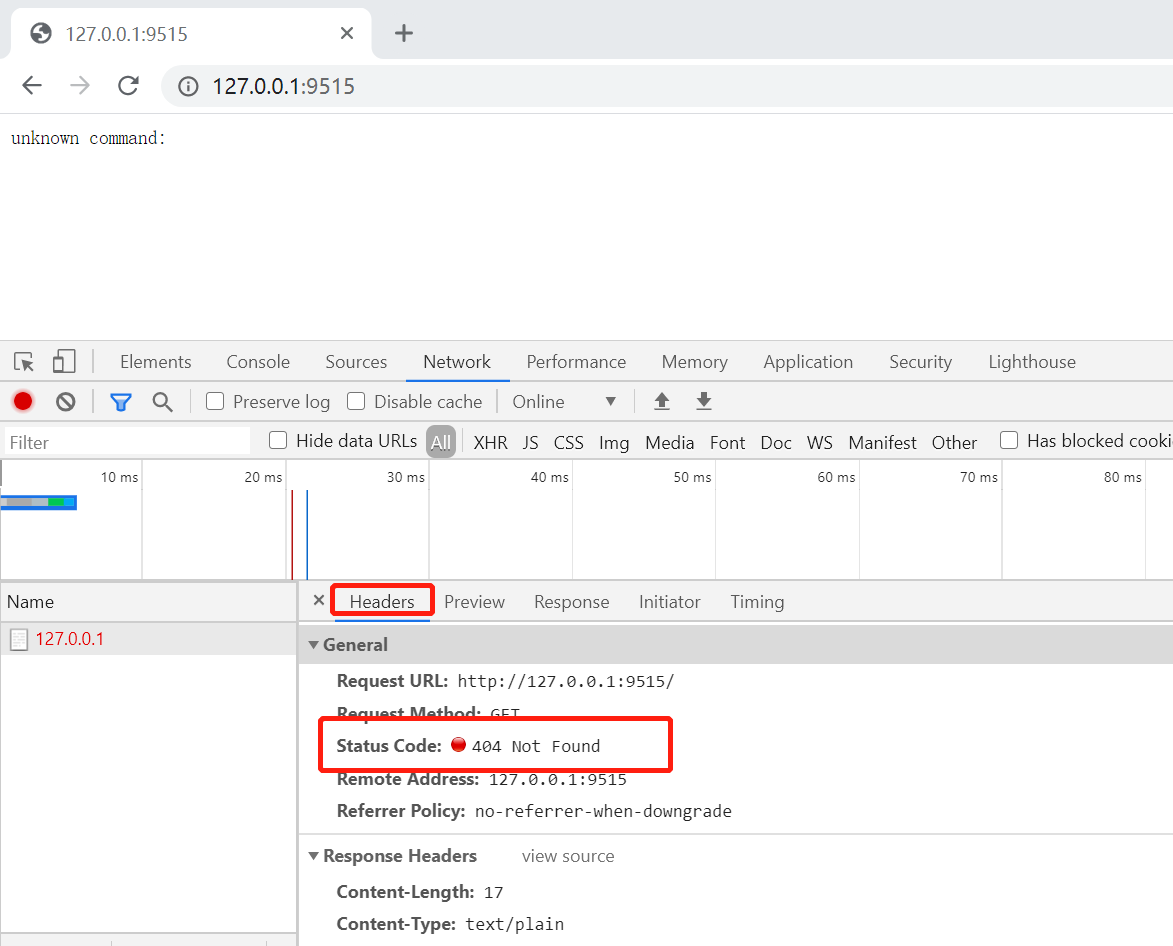
在浏览器本地访问9515端口
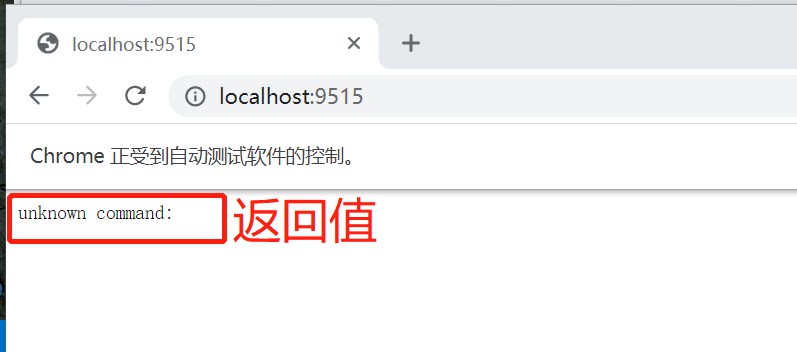
状态码404
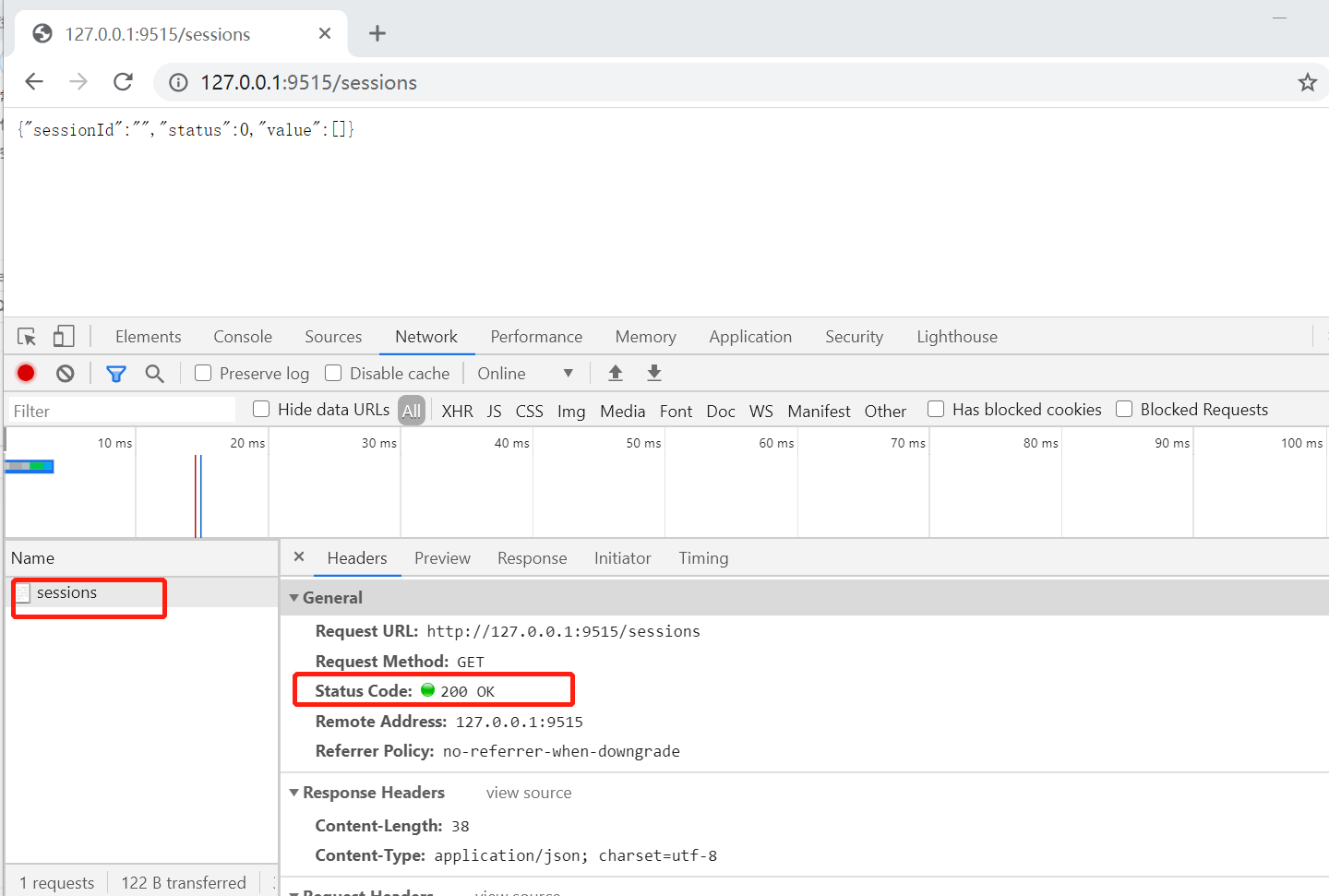
访问session,状态码是200,说明webdriver是可以提供接口的
如果把webdriver.exe关闭,那么就无法访问该端口了。可以自行尝试~~~~~~~~~~~~~
四、requests cookie管理
1.session:一个session,就表示开启一次浏览器的过程
2.request发起请求,也类似于“开启一次浏览器”
举例:访问登录、投资,两个接口
分2次会话:第一次登录的会话,是不会把状态(数据)转到第二个投资会话的,因为每开一次会话,都会有初始化过程,会清除所有的缓存数据。
1次会话:登录成功后 直接在成功后的页面 开始进行投资操作,会记录cookie的状态的。
♥request可以用session记录cookie(token不行,token不是浏览器自动处理的,是记不下来的),cookie是自动保存到客户端。
3.request基于cookie机制的
import requests s = requests.session() s.request("get",url="/login")#login成功后获取的cookie会自动保存到s中, s.request("get",url="/invest")#有cookie信息,可直接进行invest
现在主流的是token机制了。