目录
一、元素等待(70节44min)
1.强制等待
2.隐性等待
3.显性等待
二、三大切换
1.窗口切换
2.iframe切换
3.alert弹框切换
正文
一、元素等待
元素等待的3种方式:
1.强制等待:time.sleep
2.隐性等待
3.显性等待(重点)
灵魂一问:为什么要进行元素等待?
CPU的运行速度远远大于网页的页面加载速度,会导致定位不到元素,所以要进行元素等待。
背景实操:
from selenium import webdriver driver = webdriver.Chrome() driver.get("http://www.baidu.com") e = driver.find_element_by_id("kw") e.send_keys("python")
运行结果:在输入框中有输入python,但是并没有查询结果,因为没有点击“百度一下”

下面添加“百度一下”的点击操作
先定位百度一下:id=su

from selenium import webdriver driver = webdriver.Chrome() #打开百度 driver.get("http://www.baidu.com") #定位输入框,用i属性 e = driver.find_element_by_id("kw") #输入框中输入python e.send_keys("python") #定位 百度一下 e = driver.find_element_by_id("su") e.click()
在“百度一下”以后的页面中定位一个link_text的超链接文本:www.python.org/
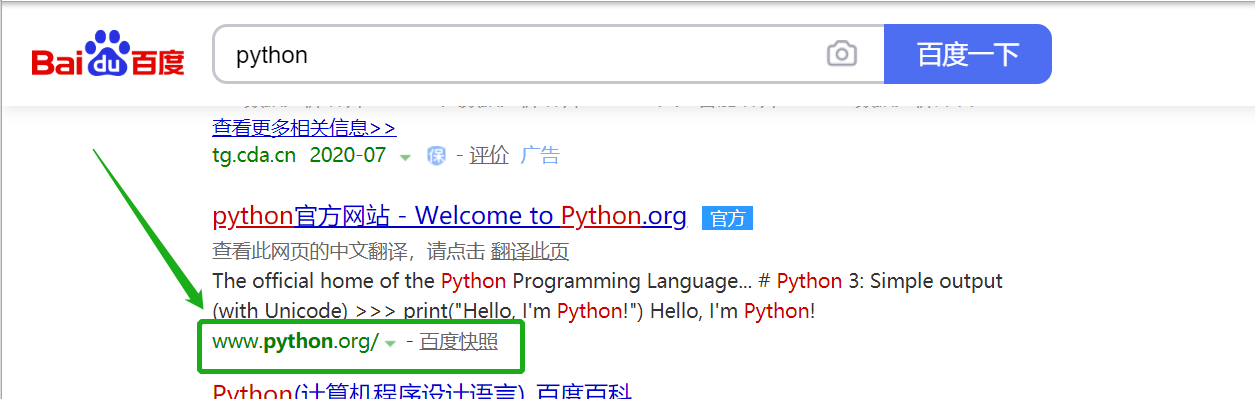
from selenium import webdriver driver = webdriver.Chrome() #打开百度 driver.get("http://www.baidu.com") #定位输入框,用i属性 e = driver.find_element_by_id("kw") #输入框中输入python e.send_keys("python") #定位 百度一下 e = driver.find_element_by_id("su") e.click() #定位 text
e = driver.find_element_by_link_text("www.python.org/")
运行结果:定位不到该元素

当进行“百度一下”的操作,有个网页加载的过程,页面渲染可能快,可能慢,(python的运行程序很快)所以进行text定位的时候,会出现定位不到的情况。所以:加入元素等待时间。
要等页面加载完成,才能执行e = driver.find_element_by_link_text("www.python.org/")
1.强制等待
上面的例子中加入强制等待时间(黄底代码)
import time from selenium import webdriver driver = webdriver.Chrome() #打开百度 driver.get("http://www.baidu.com") #定位输入框,用i属性 e = driver.find_element_by_id("kw") #输入框中输入python e.send_keys("python") #定位 百度一下 e = driver.find_element_by_id("su") e.click()
#强制等待 time.sleep(2) #定位 text e = driver.find_element_by_link_text("www.python.org/")
强制等待总结:
方法:time.sleep(),单位是秒
使用方法:time.sleep(X),等待X秒后,进行下一步操作。无论条件成立与否,都要等待到时间截至,才能进行下一步操作
缺点:不能准确把握需要等待的时间(有时操作还未完成,等待就结束了,导致报错;有时操作已经完成了,但等待时间还没有到,浪费时间),如果在用例中大量使用,会浪费不必 要的等待时间,影响测试用例的执行效率。-------时间不好控制(不够灵活)
优点:使用简单,可以在调试时使用。
智能等待:给定超时时间,在超时时间内,能够找到元素,就直接返回元素。如果在给你的超时时间内没有定位到元素,直接报错找不到元素。
举例:给定超时时间20s,在第5s的时候可以找到元素,就直接返回。超过20s没有找到,就直接报错找不到元素。
2.隐性等待-----全局作用域
打开浏览器后,设置隐性等待的超时时间:driver.implicitly_wait()。设置这一次,所有的元素查找都能够生效。比如,设置了隐性等待的超时时间为5s,查找第一个元素会等待5s,查找第二个也会等待5s,.。。。。。。。(超过超时时间找不到元素,报错,noSuchElementException)
from selenium import webdriver driver = webdriver.Chrome() #打开百度 driver.get("http://www.baidu.com") driver.implicitly_wait(2) #定位输入框,用i属性 e = driver.find_element_by_id("kw") #输入框中输入python e.send_keys("python") #定位 百度一下 e = driver.find_element_by_id("su") e.click() #定位 text e = driver.find_element_by_link_text("www.python.org/")
隐性等待总结:
隐形等待:只能等待元素加载,查找元素是否存在。------只能等待元素被查找到。
全局作用域:会话期间全局设置一次,所有元素查询都通用
使用方法:设置超时时间:driver.implicitly_wait(X),在X时间内,页面加载完成,进行下一步操作。超过超时时间,报NoSuchElementException
设置了一个最长等待时间,如果在规定时间内网页加载完成,则执行下一步,否则一直等到时间结束,然后执行下一步操作。
缺点:使用隐式等待,程序会一直等待整个页面加载完成,才会执行下一步操作;只能等待元素被查到,其他的等待,无法使用。----------不够灵活
优点:隐性等待对整个driver的周期都起作用,所以只要设置一次即可。
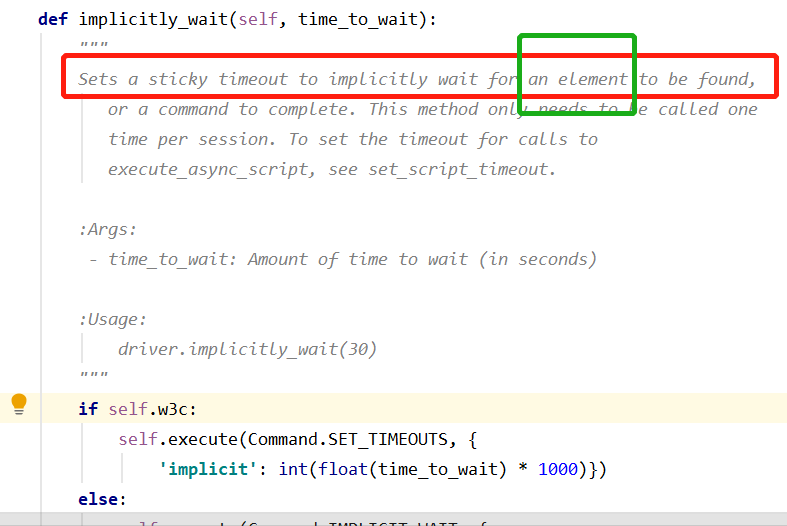
来看下 implicitly_wait()函数的源码:只能等待一个元素,其他的它等不了。---如果要去等元素被点击、元素可见、等待窗口被打开等等,隐性等待就不起作用了。
举例:一个元素能够被找到,不一定该元素能够点击。
3.显性等待 (71节 13min)-----每次等待都要单独设置,这一点同强制等待一样
显性等待,就是解决隐性等待解决不了的问题。
---等待某个元素被点击
---等待某个元素可见
---等待某个窗口被打开
显性等待的步骤
①设置定时器wait
wait = WebDriverWait()
WebDriverWait是selenium.webdriver.support.wait中的一个类
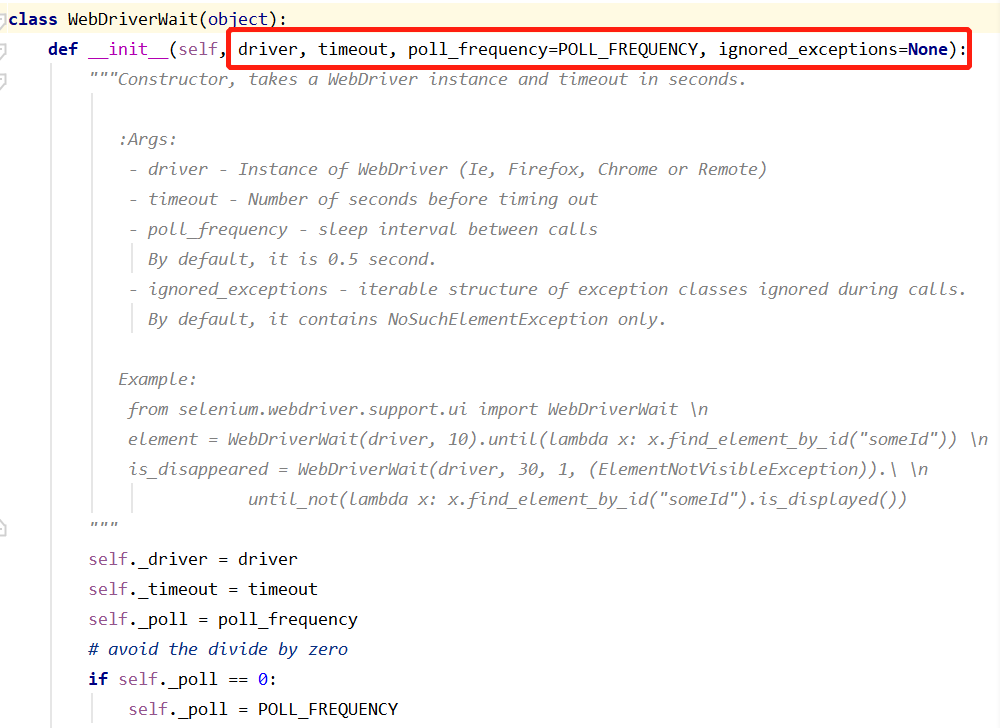
下面看下WebDriverWait类的源码:
传入的参数有driver(浏览器对象)、timeout(超时时间)、poll_frequency(轮询时间,每隔多久查询一次,比如设置1s,每隔1s查询一次,第1s查询,查到就返回,查不到等待下一次即第2s再查询一次,以此类推)
②设置满足的条件:wait.until()
until()中设置一个预期条件:expected_conditions <------------(from selenium.webdriver.support import expected_conditions)
expected_conditions下,封装的条件很多,下面介绍几个常用的条件:
1).等待元素出现:presence_of_element_located
等待元素出现,到底等待那个元素出现呢???----传入locator参数
presence_of_element_located()方法的源码:
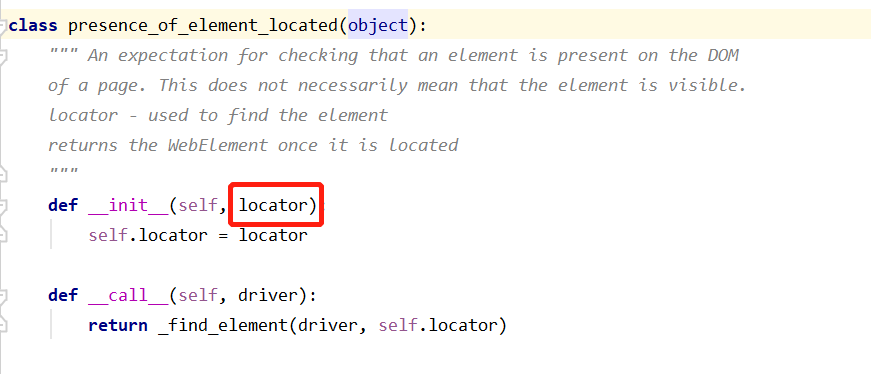
locator是个元组,元组里面是定位元素的方式,加表达式
locator提前写好:locator = ("xpath",'//*[text() = "www.python.org/"]')
完整语句:
wait.until(expected_conditions.presence_of_element_located(locator=("xpath",'//*[text()= "www.python.org/"]')))#locator是个元组
代码:
"""显性等待""" from selenium import webdriver from selenium.webdriver.support.wait import WebDriverWait from selenium.webdriver.support import expected_conditions #初始化一个浏览器对象:driver driver = webdriver.Chrome() #打开浏览器 driver.get("http://www.baidu.com") #定位百度输入框 e = driver.find_element_by_id("kw") e.send_keys("柠檬班") #定位百度一下,查询python driver.find_element_by_id("su").click() #设置显性等待时间wait wait = WebDriverWait(driver,20,poll_frequency=0.5)#poll_frequency的默认值就是0.5 #设置满足的条件 locator = ('xpath','//*[text() = "lemon.ke.qq.com/"]') elem = wait.until(expected_conditions.presence_of_element_located(locator=locator))#locator是个元组 print(elem.text) #结果打印:lemon.ke.qq.com/
2)元素是否可见:visibility_of_element_located(locator = locator)
3)元素是否被点击:element_to_be_clickable(locator=locator)
什么场景用什么方式?
需要点击某个元素:用element_to_be_clickable
需要查看某个元素:优先选用visibility_of_element_located
元素可见用不了,再换用presence_of_element_located
显性等待方法----封装
def wait_element_clikable(locator,driver,timeout = 20,poll = 0.5): """等待元素被点击""" wait = WebDriverWait(driver, timeout=timeout, poll_frequency=poll) elem = wait.until(expected_conditions.element_to_be_clickable(locator=locator)) return elem def wait_elemet_presence(locator,driver,timeout = 20,poll = 0.5): """等待元素出现""" wait = WebDriverWait(driver, timeout=timeout, poll_frequency=poll) elem = wait.until(expected_conditions.presence_of_element_located(locator=locator)) return elem def wait_elemet_visiable(locator,driver,timeout = 20,poll = 0.5): """等待元素可见""" wait = WebDriverWait(driver, timeout=timeout, poll_frequency=poll) elem = wait.until(expected_conditions.visibility_of_element_located(locator=locator)) return elem
显性等待如果还是找不到元素怎么办???----报错:TimeoutException
面试题:等待方式的选择
1.优先:隐性等待:全局设置,等待查找元素
2.再:显性等待:等待元素可以被点击,可见(如果隐性的等待可以找到元素,就不需要再进行显性等待)
3.最后:强制等待:上面2个等待都用不了,就用强制等待;用在多个系统交互的地方,就要用强制等待。
总结:
1.元素等待
首先用find_element()进行查找,看看是不是要进行元素等待。(有些元素不需要动态加载的,是不用等待的),如果找不到,用隐性等待。隐性等待找不到,换用现性等待;
现性等待找不到的话,要记得切换条件(presence、visible、clickable);还是找不到再用强制等待。
2.元素定位不到的原因有哪些?nosuchelement
①检查 元素定位的方式是否正确
②没有加元素等待 (调试的时候直接用强制等待,效果比较明显。’具体的业务逻辑按照上面的方式)
③检查 有没有在这个页面上:有没有在这个窗口上;是不是在iframe中
二、三大切换 --71节41min
为什么需要切换窗口?---因为selenium不会自动进行页面的跳转动作
举例:如下在百度页面定位的超链接文本lemon.ke.qq.com/,点击进入该页面,打印出来的current_url是百度页面的url,不是跳转后的url
from selenium import webdriver from selenium.webdriver.support.wait import WebDriverWait from selenium.webdriver.support import expected_conditions #初始化浏览器对象 driver = webdriver.Chrome() #打开百度 driver.get("http://www.baidu.com") #定位百度输入框input elem = driver.find_element_by_id("kw") elem.send_keys("柠檬班") #定位“百度一下” elem=driver.find_element_by_id("su") elem.click() ####定位到查链接文本:图片 #先进行等待--这里用显性等待 #设置定时器wait wait = WebDriverWait(driver,timeout=5,poll_frequency=0.5) #设置满足的条件 locator= ('xpath','//*[text()="lemon.ke.qq.com/"]') elem = wait.until(expected_conditions.element_to_be_clickable(locator=locator)) elem.click() print(driver.current_url)
结果如下:(不是lemon.ke.qq.com)
页面切换后,才能进行新页面的元素定位。
1.窗口切换
1)窗口切换的函数:driver.switch_to.window(参数)
参数就是窗口句柄:window_handle
首先获取所有的窗口句柄:driver.window_handles
web自动化测试中,常用的就是切换到最新跳转的页面,即driver.window_handles[-1]
代码:
from selenium import webdriver from selenium.webdriver.support.wait import WebDriverWait from selenium.webdriver.support import expected_conditions #初始化浏览器对象 driver = webdriver.Chrome() #打开百度 driver.get("http://www.baidu.com") #定位百度输入框input elem = driver.find_element_by_id("kw") elem.send_keys("柠檬班") #定位“百度一下” elem=driver.find_element_by_id("su") elem.click() ####定位到查链接文本:图片 #先进行等待--这里用显性等待 #设置定时器wait wait = WebDriverWait(driver,timeout=5,poll_frequency=0.5) #设置满足的条件 locator= ('xpath','//*[text()="lemon.ke.qq.com/"]') elem = wait.until(expected_conditions.element_to_be_clickable(locator=locator)) elem.click() print(driver.current_url) #窗口切换 #获取所有的窗口句柄 print(driver.window_handles) driver.switch_to.window(driver.window_handles[-1]) print(driver.current_url)
结果:

2.iframe切换 ---71节50min
1)如何确认当前页面中有没有iframe?
-------F12,看当前页面下面的bar,是否有2个html

如果页面中有iframe,定位元素是定位不到的。必须进行iframe切换。
语法:driver.switch_to.frame()
首先看下frame()的源码:

2). iframe切换有3中方式:
1.通过iframe的name属性进行定位切换:driver.switch_to.frame('frame_name') <-----------提供name属性的情况下
2.通过iframe的索引进行切换:driver.switch_to.frame(1)---0表示第一个,1表示第二个 (这个方法基本不用)
3.通过查询所有iframe元素,再进行索引(返回的是个webelement对象):driver.switch_to.frame(driver.find_elements_by_tag_name("iframe")[0]) <-------没有name属性的情况下
实操:
首先:自己写个带有iframe的页面,如下,iframe是百度首页
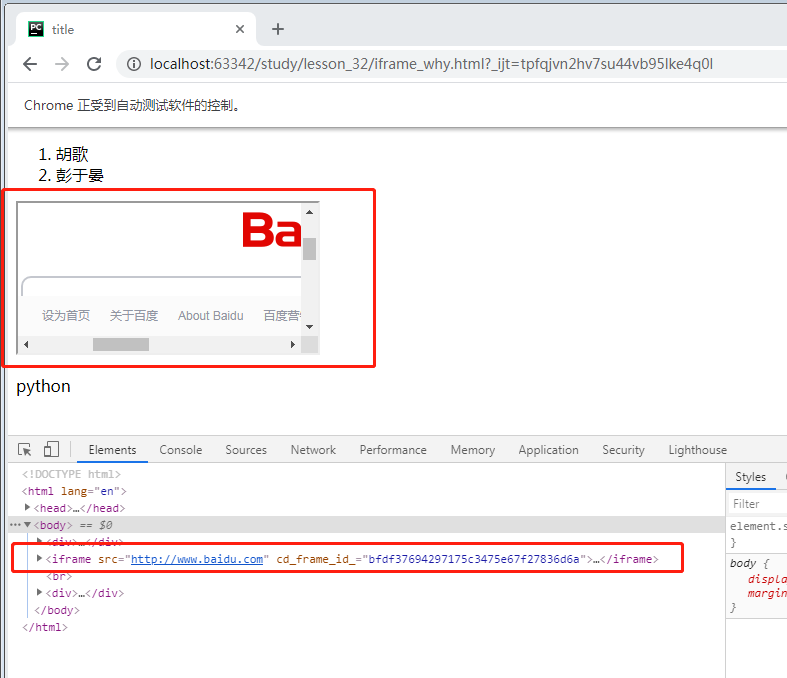
要定位iframe中的百度input输入框,就要进行iframe切换。代码如下:
from selenium import webdriver #初始化driver浏览器对象 driver = webdriver.Chrome() #访问有iframe的页面 driver.get("http://localhost:63342/study/lesson_32/iframe_why.html?_ijt=tpfqjvn2hv7su44vb95lke4q0l") #带有iframe,进行定位 ##首先找到要切换的iframe ----通过xpath找到iframe frame_elem = driver.find_element_by_xpath('//iframe[@src]') ##进行iframe切换 driver.switch_to.frame(frame_elem) #定位返回的事webelement对象 elem=driver.find_element_by_id("kw") print(elem)
结果:
注:上面的get中的url,每次要重新将写的HTML网页重新打开,用最新的url地址。
72节
3)要定位主页面的元素-------------------已经在iframe中,怎么定位iframe外的页面的元素?
语法:driver.switch_to.default_content()
带有iframe网页的HTML:
<!DOCTYPE html> <html lang="en"> <head> <meta charset="UTF-8"> <title>title</title> </head> <body> <div> <ol> <li>胡歌</li> <li>彭于晏</li> </ol> </div> <iframe src="http://www.baidu.com"></iframe><br> <div> <p id="hello">python</p> </div> </body> </html>
from selenium import webdriver #初始化driver浏览器对象 driver = webdriver.Chrome() #访问有iframe的页面 driver.get("http://localhost:63342/study/lesson_32/iframe_why.html?_ijt=fkgd5gchk67oah046kkqr8vats") #带有iframe,进行定位 ##首先找到要切换的iframe ----通过xpath找到iframe frame_elem = driver.find_element_by_xpath('//iframe[@src]') ##进行iframe切换 driver.switch_to.frame(frame_elem) #定位返回的事webelement对象 elem=driver.find_element_by_id("kw") print(elem) #定位主页面的元素 ##先切换回主页面 driver.switch_to.default_content() elem = driver.find_element_by_id("hello") print(elem)
4)如果主页面中有一个iframe,iframe中还套有iframe,怎么办?
先通过xpath找第一次的iframe,再通过xpath找第二层iframe,以此类推。。。。。。。。。。。
5)在多层iframe中,如何退回到主页面?
通过parent_frame()一层一层退出来。
语法:switch_to.parent_frame()
※特殊情况:
iframe等待:不能用隐性等待(因为隐性等待只能等元素,等待了iframe的元素,但是不能等待iframe这个页面)
所以iframe基本上都是用显性等待。
代码实现:
frame_to_be_available_and_switch_to_it:直到等待有效frame,再切换。可以实现2步操作的类(在第一个轮循时间内没有等待到,再进入下一个轮循时间)
等待不到,报NoSuchFrameException
from selenium import webdriver #初始化driver浏览器对象 from selenium.webdriver.support.wait import WebDriverWait from selenium.webdriver.support import expected_conditions driver = webdriver.Chrome() #访问有iframe的页面 driver.get("http://localhost:63342/study/lesson_32/iframe_why.html?_ijt=elih8hfpjrq3j99ucucuhu5cod") ##首先找到要切换的iframe ----通过xpath找到iframe frame_elem = driver.find_element_by_xpath('//iframe[@src]')
#iframe切换结合显性等待 WebDriverWait(driver,timeout=20,poll_frequency=0.5).until( expected_conditions.frame_to_be_available_and_switch_to_it(frame_elem)) #frame中定位id elem=driver.find_element_by_id("kw") print(elem) #定位主页面的元素 ##先切换回主页面 driver.switch_to.default_content() elem = driver.find_element_by_id("hello") print(elem)
附上frame_to_be_available_and_switch_to_it类的源码:
class frame_to_be_available_and_switch_to_it(object): """ An expectation for checking whether the given frame is available to switch to. If the frame is available it switches the given driver to the specified frame. """ def __init__(self, locator): self.frame_locator = locator def __call__(self, driver): try: if isinstance(self.frame_locator, tuple): driver.switch_to.frame(_find_element(driver, self.frame_locator)) else: driver.switch_to.frame(self.frame_locator) return True except NoSuchFrameException: return False
3.alert弹框切换
先写个带有alert弹窗的html
<!DOCTYPE html> <html lang="en"> <head> <meta charset="UTF-8"> <title>alert</title> </head> <body> <p>selenium python autotest</p> <p id="leain" onclick="alertMe()"> learn python</p> <script> function alertMe(){ alert("this is a alert window!") } </script> </body> </html>
页面显示如下:
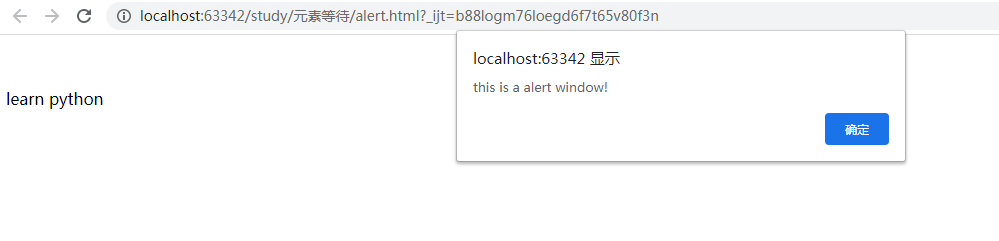
出现弹框alert以后,就无法对主页面进行元素定位(主页面被alert遮盖,无法操作。)
所以在出现弹框后,要对主页面进行元素定位,必须先将alert关闭---》点击alert弹窗的【确定】按钮,关闭弹窗。
(1).语法:
①切换到alert弹框,alert是属性(源码的方法上加了@property)
②alert中的确定按钮,alert_elem.accept()
取消按钮:alert_elem.dismiss()
代码实现:
from selenium import webdriver #初始化driver浏览器对象 driver = webdriver.Chrome() driver.get("http://localhost:63342/study/%E5%85%83%E7%B4%A0%E7%AD%89%E5%BE%85/alert.html?_ijt=pbds0nqdgd9ighds0bdgdfeo8p") #id 定位元素learn python,并点击 driver.find_element_by_id("learn").click() #切换到alert alert_elem = driver.switch_to.alert #点击确定 alert_elem.accept()
(2)alert等待的条件----alert_is_present()
alert_is_present():不需要传参数
源码如下,__init__(self)没有参数需要传递,直接调用call方法
class alert_is_present(object): """ Expect an alert to be present.""" def __init__(self): pass def __call__(self, driver): try: alert = driver.switch_to.alert return alert except NoAlertPresentException: return False
现性等待后切换到alert页面,代码如下
from selenium import webdriver from selenium.webdriver.support.wait import WebDriverWait from selenium.webdriver.support import expected_conditions #初始化driver浏览器对象 driver = webdriver.Chrome() driver.get("http://localhost:63342/study/%E5%85%83%E7%B4%A0%E7%AD%89%E5%BE%85/alert.html?_ijt=t00ugtfhr0mvvdj7017ec14i66") #id 定位元素learn python,并点击 driver.find_element_by_id("learn").click() # #切换到alert # alert_elem = driver.switch_to.alert #显性等待alert并切换 alert_elem = WebDriverWait(driver,timeout=20,poll_frequency=0.5).until(expected_conditions.alert_is_present()) #点击确定 alert_elem.accept()
总结:
1.窗口切换,iframe切换需要加参数,alert切换不需要加参数,的原因?
一个页面只可能有一个alert,但是iframe可能存在多个。