base64编码原理:
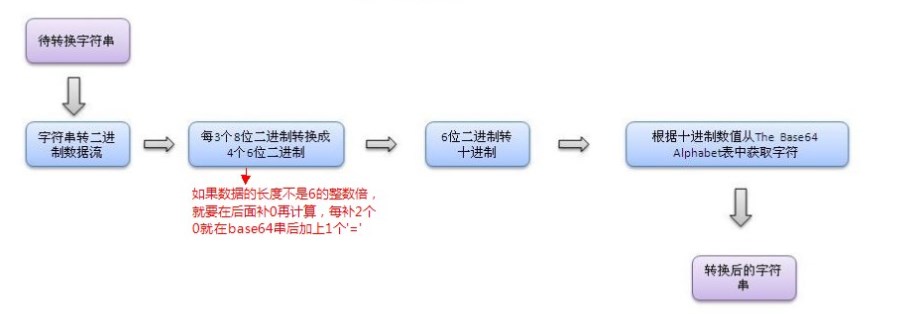
例如:


实例一:
#-*- coding: UTF-8 -*- __author__ = '007' __date__ = '2015/12/23' import base64 code = "aGV5LOatpOWkhOWtmOWcqGpvb21sYea8j+a0nu+8jOivt+WPiuaXtuiBlOezuyB4eHh4eHhAMTI2LmNvbSDkv67lpI3mraTmvI/mtJ4=" print type(code) cc = base64.decodestring(code) print cc u = u'hey,此处存在joomla漏洞,请及时联系 xxxxxx@126.com 修复此漏洞' print type(u) d = u.encode('utf8') print type(d) dd = base64.encodestring(d) print dd
运行结果:
<type 'str'> hey,此处存在joomla漏洞,请及时联系 xxxxxx@126.com 修复此漏洞 <type 'unicode'> <type 'str'> aGV5LOatpOWkhOWtmOWcqGpvb21sYea8j+a0nu+8jOivt+WPiuaXtuiBlOezuyB4eHh4eHhAMTI2LmNvbSDkv67lpI3mraTmvI/mtJ4=
实例二:
#-*- coding: UTF-8 -*- __author__ = '007' __date__ = '2016/2/15' import base64 #对字符串进行base64编码 def str2base64(): str_encode = raw_input("请输入字符串:") en = base64.encodestring(str_encode) print en #对字符串进行base64解码 def base64tostr(): str_decode = raw_input("请输入base64串:") de = base64.decodestring(str_decode) print de #对url字符串进行base64编码 def url2base64(): url_encode = raw_input("请输入URL字符串:") en = base64.urlsafe_b64encode(url_encode) print en #对url字符串进行base64解码 def base64tourl(): url_decode = raw_input("请输入url的base64串:") de = base64.urlsafe_b64decode(url_decode) print de #对文件里面的字符串进行base64编码 def file_base64_en(): f1 = raw_input("请输入您要读取的文件:") f2 = raw_input("请输入您要写入的文件:") rf = open(f1,'r') lines = rf.readlines() wf = open(f2,'w') for line in lines: word = line.strip() en = base64.encodestring(word) #print en wf.write(word+"的base64编码结果是:"+en) #wf.write(" ") rf.close() wf.close() #对文件里面的字符串进行base64解码 def file_base64_de(): f1 = raw_input("请输入您要读取的文件:") f2 = raw_input("请输入您要写入的文件:") rf = open(f1,'r') lines = rf.readlines() wf = open(f2,'w') for line in lines: de = base64.decodestring(line) #print de wf.write(line+"的base64解码结果是:"+de) wf.write(" ") rf.close() wf.close() def main(): print u"a.字符串" print u"b.url字符串" print u"c.读取文件操作" ch = raw_input("请选择操作数据类型:") if ch == "a": print u"1.base64编码" print u"2.base64解码" choice = raw_input("请选择编码或解码:") if choice == "1": str2base64() elif choice == "2": base64tostr() else: print u"您的选择不是合理的编码或解码!" elif ch == "b": print u"1.base64编码" print u"2.base64解码" choice = raw_input("请选择编码或解码:") if choice == "1": url2base64() elif choice == "2": base64tourl() else: print u"您的选择不是合理的编码或解码!" elif ch == "c": print u"1.base64编码" print u"2.base64解码" choice = raw_input("请选择编码或解码:") if choice == "1": file_base64_en() elif choice == "2": file_base64_de() else: print u"您的选择不是合理的编码或解码!" else: print u"未找到您所需要编码或解码的数据类型!" if __name__ == "__main__": main()