前端--对前端的认识
一个网页的构成:
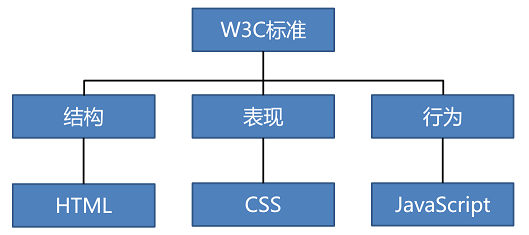
Html用于描述页面的结构
Css用于控制页面中元素的样式
JavaScript用于响应用户操作
html
超文本标记语言
第一个demo:
<!DOCTYPE html> <html> <head> <title>我是小帅哥</title> </head> <body> <H1>我是大帅哥</H1> </body> </html>
前端-- 注释
<!-- 注释内容 -->
注释中的内容不会在页面中显示,但是会在源码中显示,我们可以通过注释来说明网页的代码。
也可以通过注释隐藏一些页面中不想显示的内容。
<!-- html根标签,一个页面中有且只有一个根标签,网页中的所有内容都应该写在html根标签中 --> <html> <!-- head标签,该标签中的内容,不会在网页中直接显示,它用来帮助浏览器解析页面的 --> <head> <!-- title网页的标题标签,默认会显示在浏览器的标题栏中 搜索引擎在检索页面时,会首先检索title标签中的内容 它是网页中对于搜索引擎来说最重要的内容,会影响到网页在搜索引擎中的排名 --> <title>网页的标题</title> </head> <!-- body标签用来设置网页的主体内容,网页中所有可见的内容,都应该在body中编写 --> <body> <!-- 在这个结构中,可以来编写HTML的注释 注释中的内容,不会在页面中显示,但是可以在源码中查看 我们可以通过编写注释来对代码进行描述,从而帮助其他的开发人员工作 一定要养成良好的编写注释的习惯,但是注释一定要简单明了 --> <!-- 属性: 可以通过属性来设置标签如果处理标签中的内容 可以在开始标签中添加属性 属性需要写在开始标签中,实际上就是一个名值对的结构 属性名 = "属性值",一个标签中可以同时设置多个属性,属性之间需要使用空格隔开 --> <h1>这是我的<font color="green" size="7">第二个</font>网页</h1> </body> </html>
<font></font>用来设置字体,color属性用来设置颜色,size用来设置字体大小
效果:

w3c上面的标签列表,来自http://www.w3school.com.cn/tags/index.asp:
| 标签 | 描述 |
|---|---|
| <!--...--> | 定义注释。 |
| <!DOCTYPE> | 定义文档类型。 |
| <a> | 定义锚。 |
| <abbr> | 定义缩写。 |
| <acronym> | 定义只取首字母的缩写。 |
| <address> | 定义文档作者或拥有者的联系信息。 |
| <applet> | 不赞成使用。定义嵌入的 applet。 |
| <area> | 定义图像映射内部的区域。 |
| <article> | 定义文章。 |
| <aside> | 定义页面内容之外的内容。 |
| <audio> | 定义声音内容。 |
| <b> | 定义粗体字。 |
| <base> | 定义页面中所有链接的默认地址或默认目标。 |
| <basefont> | 不赞成使用。定义页面中文本的默认字体、颜色或尺寸。 |
| <bdi> | 定义文本的文本方向,使其脱离其周围文本的方向设置。 |
| <bdo> | 定义文字方向。 |
| <big> | 定义大号文本。 |
| <blockquote> | 定义长的引用。 |
| <body> | 定义文档的主体。 |
| <br> | 定义简单的折行。 |
| <button> | 定义按钮 (push button)。 |
| <canvas> | 定义图形。 |
| <caption> | 定义表格标题。 |
| <center> | 不赞成使用。定义居中文本。 |
| <cite> | 定义引用(citation)。 |
| <code> | 定义计算机代码文本。 |
| <col> | 定义表格中一个或多个列的属性值。 |
| <colgroup> | 定义表格中供格式化的列组。 |
| <command> | 定义命令按钮。 |
| <datalist> | 定义下拉列表。 |
| <dd> | 定义定义列表中项目的描述。 |
| <del> | 定义被删除文本。 |
| <details> | 定义元素的细节。 |
| <dir> | 不赞成使用。定义目录列表。 |
| <div> | 定义文档中的节。 |
| <dfn> | 定义定义项目。 |
| <dialog> | 定义对话框或窗口。 |
| <dl> | 定义定义列表。 |
| <dt> | 定义定义列表中的项目。 |
| <em> | 定义强调文本。 |
| <embed> | 定义外部交互内容或插件。 |
| <fieldset> | 定义围绕表单中元素的边框。 |
| <figcaption> | 定义 figure 元素的标题。 |
| <figure> | 定义媒介内容的分组,以及它们的标题。 |
| <font> | 不赞成使用。定义文字的字体、尺寸和颜色。 |
| <footer> | 定义 section 或 page 的页脚。 |
| <form> | 定义供用户输入的 HTML 表单。 |
| <frame> | 定义框架集的窗口或框架。 |
| <frameset> | 定义框架集。 |
| <h1> to <h6> | 定义 HTML 标题。 |
| <head> | 定义关于文档的信息。 |
| <header> | 定义 section 或 page 的页眉。 |
| <hr> | 定义水平线。 |
| <html> | 定义 HTML 文档。 |
| <i> | 定义斜体字。 |
| <iframe> | 定义内联框架。 |
| <img> | 定义图像。 |
| <input> | 定义输入控件。 |
| <ins> | 定义被插入文本。 |
| <isindex> | 不赞成使用。定义与文档相关的可搜索索引。 |
| <kbd> | 定义键盘文本。 |
| <keygen> | 定义生成密钥。 |
| <label> | 定义 input 元素的标注。 |
| <legend> | 定义 fieldset 元素的标题。 |
| <li> | 定义列表的项目。 |
| <link> | 定义文档与外部资源的关系。 |
| <map> | 定义图像映射。 |
| <mark> | 定义有记号的文本。 |
| <menu> | 定义命令的列表或菜单。 |
| <menuitem> | 定义用户可以从弹出菜单调用的命令/菜单项目。 |
| <meta> | 定义关于 HTML 文档的元信息。 |
| <meter> | 定义预定义范围内的度量。 |
| <nav> | 定义导航链接。 |
| <noframes> | 定义针对不支持框架的用户的替代内容。 |
| <noscript> | 定义针对不支持客户端脚本的用户的替代内容。 |
| <object> | 定义内嵌对象。 |
| <ol> | 定义有序列表。 |
| <optgroup> | 定义选择列表中相关选项的组合。 |
| <option> | 定义选择列表中的选项。 |
| <output> | 定义输出的一些类型。 |
| <p> | 定义段落。 |
| <param> | 定义对象的参数。 |
| <pre> | 定义预格式文本。 |
| <progress> | 定义任何类型的任务的进度。 |
| <q> | 定义短的引用。 |
| <rp> | 定义若浏览器不支持 ruby 元素显示的内容。 |
| <rt> | 定义 ruby 注释的解释。 |
| <ruby> | 定义 ruby 注释。 |
| <s> | 不赞成使用。定义加删除线的文本。 |
| <samp> | 定义计算机代码样本。 |
| <script> | 定义客户端脚本。 |
| <section> | 定义 section。 |
| <select> | 定义选择列表(下拉列表)。 |
| <small> | 定义小号文本。 |
| <source> | 定义媒介源。 |
| <span> | 定义文档中的节。 |
| <strike> | 不赞成使用。定义加删除线文本。 |
| <strong> | 定义强调文本。 |
| <style> | 定义文档的样式信息。 |
| <sub> | 定义下标文本。 |
| <summary> | 为 <details> 元素定义可见的标题。 |
| <sup> | 定义上标文本。 |
| <table> | 定义表格。 |
| <tbody> | 定义表格中的主体内容。 |
| <td> | 定义表格中的单元。 |
| <textarea> | 定义多行的文本输入控件。 |
| <tfoot> | 定义表格中的表注内容(脚注)。 |
| <th> | 定义表格中的表头单元格。 |
| <thead> | 定义表格中的表头内容。 |
| <time> | 定义日期/时间。 |
| <title> | 定义文档的标题。 |
| <tr> | 定义表格中的行。 |
| <track> | 定义用在媒体播放器中的文本轨道。 |
| <tt> | 定义打字机文本。 |
| <u> | 不赞成使用。定义下划线文本。 |
| <ul> | 定义无序列表。 |
| <var> | 定义文本的变量部分。 |
| <video> | 定义视频。 |
| <wbr> | 定义可能的换行符。 |
| <xmp> | 不赞成使用。定义预格式文本。 |
如何让浏览器识别到底是html4还是xhtml还是html5?
利用文档声明:<!doctype html>
主要作用:
- 用来标识当前页面的html的版本;
- 该声明用来告诉浏览器,当前的页面是使用HTML5的标准编写的。
doctype
HTML总共有那么多的版本,而且这其中至少有三个版本在广泛使用,那么浏览器怎么知道我们在使用哪个版本呢?
为了让浏览器知道我们使用的HTML版本我们还需要在网页的最上边添加一个doctype声明,来告诉浏览器网页的版本。
html4
1、过渡版
<!DOCTYPE HTML PUBLIC "-//W3C//DTD HTML 4.01 Transitional//EN" "http://www.w3.org/TR/html4/loose.dtd">
2、严格版
<!DOCTYPE HTML PUBLIC "-//W3C//DTD HTML 4.01//EN" "http://www.w3.org/TR/html4/strict.dtd">
3、框架集
<!DOCTYPE HTML PUBLIC "-//W3C//DTD HTML 4.01 Frameset//EN" "http://www.w3.org/TR/html4/frameset.dtd">
xhtml1.0
过渡版
<!DOCTYPE html PUBLIC "-//W3C//DTD XHTML 1.0 Transitional//EN" " http://www.w3.org/TR/xhtml1/DTD/xhtml1-transitional.dtd">
严格版
<!DOCTYPE html PUBLIC "-//W3C//DTD XHTML 1.0 Strict//EN" "http://www.w3.org/TR/xhtml1/DTD/xhtml1-strict.dtd">
框架集
<!DOCTYPE html PUBLIC "-//W3C//DTD XHTML 1.0 Frameset//EN" "http://www.w3.org/TR/xhtml1/DTD/xhtml1-frameset.dtd">
Html5
<!DOCTYPE html>
怪异模式
为了兼容一些旧的页面,浏览器中设置了
两种解析模式:
– 标准模式(Standards Mode)
– 怪异模式(Quirks Mode)
怪异模式解析网页时会产生一些不可预期的行为,所以我们应该避免怪异模式的出现。
避免的最好方式就是在页面中编写正确的doctype。
进制
几进制就是满几进一
二进制:
0 1
例如:10 11 100 101 110 111
十进制:
0 1 2 3 4 5 6 7 8 9
例如:10 11 12 13 14 。。。
十六进制:
满16进1
0 1 2 3 4 5 6 7 8 9 a b c d e f
a b c d e f分别表示10,11,12,13,14,15
例如:10 11 12 ... 19 1a 1b 1c 1d 1e 1f
16进制由于是满16进1,所以必须设置几个特殊的字符来表示10 11 12 13 14 15
八进制:
满8进1
0 1 2 3 4 5 6 7
例如:10 11 12 13 14 15 16 17 20 21 22
乱码
产生乱码的根本原因是,编码和解码采用的字符集不同。
计算机是一个非常笨的机器,它只认识两个东西 0 1。在计算机中保存的任何内容,最终都需要转换为0 1这种二进制编码来保存,包括网页中的内容。
比如:中国,在计算机底层,可以能需要转换为 1010001001010101011010。
在读取内容时,需要将二进制编码,在转换为正确的内容。
编码:依据一定的规则,将字符转换为二进制编码的过程。
解码:依据一定的规则,将二进制编码转换为字符的过程。
常见字符集:
ASCII
ISO-8859-1
GBK
GB2312:中文系统的默认编码。
UTF-8:万国码,支持地球上所有的文字。
ANSI:自动以系统的默认编码来保存文件。
告诉浏览器网页所使用的编码字符集,通过meta来进行设置,避免乱码问题的产生。
meta标签用来设置网页的一些元数据,比如网页的字符集,关键字,简介,
<!doctype html> <html> <head> <!-- 需要来告诉浏览器,网页所采用的编码字符集 meta标签用来设置网页的一些元数据,比如网页的字符集,关键字、简介 meta是一个自结束标签,编写一个自结束标签时,可以在开始标签中添加 一个/ --> <meta charset="utf-8"> <title>网页的标题</title> </head> <body> <h1>这是一个非常漂亮的网页</h1> </body> </html>
常用标签
内容标题标签
h1~h6
-在HTML中,一共有六级标题标签
h1 ~ h6
在显示效果上h1最大,h6最小,但是文字的大小我们并不关心
使用HTML标签时,关心的是标签的语义,我们使用的标签都是语义化标签
6级标题中,h1的最重要,表示一个网页中的主要内容,h2 ~ h6重要性依次降低
对于搜索引擎来说,h1的重要性仅次于title,搜索引擎检索完title,会立即查看h1中的内容
h1标签非常重要,它会影响到页面在搜索引擎中的排名,页面只能写一个h1
一般页面中标题标签只使用h1 h2 h3,h3以后的基本不使用
<!doctype html> <html> <head> <!-- 需要来告诉浏览器,网页所采用的编码字符集 meta标签用来设置网页的一些元数据,比如网页的字符集,关键字、简介 meta是一个自结束标签,编写一个自结束标签时,可以在开始标签中添加 一个/ --> <meta charset="utf-8"> <title>网页的标题</title> </head> <body> <h1>这是一个非常漂亮的网页</h1> <h2>这是一个非常漂亮的网页</h2> <h3>这是一个非常漂亮的网页</h3> <h4>这是一个非常漂亮的网页</h4> <h5>这是一个非常漂亮的网页</h5> <h6>这是一个非常漂亮的网页</h6> </body> </html>
效果:

段落标签:
段落标签,段落标签用于表示内容中的一个自然段
使用p标签来表示一个段落
p标签中的文字,默认会独占一行,并且段与段之间会有一个间距
<!doctype html> <html> <head> <!-- 需要来告诉浏览器,网页所采用的编码字符集 meta标签用来设置网页的一些元数据,比如网页的字符集,关键字、简介 meta是一个自结束标签,编写一个自结束标签时,可以在开始标签中添加 一个/ --> <meta charset="utf-8" /> <title>网页的标题</title> </head> <body> <h1>这是一个非常漂亮的网页</h1> <p>段落标签1</p> <p>段落标签2</p> </body> </html>
效果:

自结束标签br
在HTML中,字符之间写再多的空格,浏览器也会当成一个空格解析,
换行也会当成一个空格解析。
在页面中可以使用br标签来表示一个换行,br标签是一个自结束标签
<!doctype html> <html> <head> <!-- 需要来告诉浏览器,网页所采用的编码字符集 meta标签用来设置网页的一些元数据,比如网页的字符集,关键字、简介 meta是一个自结束标签,编写一个自结束标签时,可以在开始标签中添加 一个/ --> <meta charset="utf-8" /> <title>网页的标题</title> </head> <body> <h1>这是一个非常漂亮的网页</h1> <p> 张三,<br /> 李四,<br /> 赵雷,<br /> 王五。<br /> </p> </body> </html>
效果:

自结束标签hr
hr标签也是一个自结束标签,可以在页面中生成一条水平线
<!doctype html> <html> <head> <!-- 需要来告诉浏览器,网页所采用的编码字符集 meta标签用来设置网页的一些元数据,比如网页的字符集,关键字、简介 meta是一个自结束标签,编写一个自结束标签时,可以在开始标签中添加 一个/ --> <meta charset="utf-8" /> <title>网页的标题</title> </head> <body> <h1>这是一个非常漂亮的网页</h1> <hr></hr> <p> 张三,<br /> 李四,<br /> 赵雷,<br /> 王五。<br /> </p> </body> </html>
效果:

实体
在HTML中,一些如< >这种特殊字符是不能直接使用,
需要使用一些特殊的符号来表示这些特殊字符,这些特殊符号我们称为实体(转义字符串)
浏览器解析到实体时,会自动将实体转换为其对应的字符
实体的语法:
&实体的名字;
< <
> >
空格
版权符号 ©
html中实用的实体:
http://w3school.com.cn/html/html_entities.asp
<!doctype html> <html> <head> <meta charset="utf-8" /> <title>实体</title> </head> <body> <!-- 在HTML中,一些如< >这种特殊字符是不能直接使用, 需要使用一些特殊的符号来表示这些特殊字符,这些特殊符号我们称为实体(转义字符串) 浏览器解析到实体时,会自动将实体转换为其对应的字符 实体的语法: &实体的名字; < < > > 空格 版权符号 © --> a<b>c <p>©÷老王 爱琼琼</p> </body> </html>
| 显示结果 | 描述 | 实体名称 | 实体编号 |
|---|---|---|---|
| 空格 | |   | |
| < | 小于号 | < | < |
| > | 大于号 | > | > |
| & | 和号 | & | & |
| " | 引号 | " | " |
| ' | 撇号 | ' (IE不支持) | ' |
| ¢ | 分(cent) | ¢ | ¢ |
| £ | 镑(pound) | £ | £ |
| ¥ | 元(yen) | ¥ | ¥ |
| € | 欧元(euro) | € | € |
| § | 小节 | § | § |
| © | 版权(copyright) | © | © |
| ® | 注册商标 | ® | ® |
| ™ | 商标 | ™ | ™ |
| × | 乘号 | × | × |
| ÷ | 除号 | ÷ | ÷ |
效果:
