【软件工程实践 · 结队项目】 第二次作业
Part 0 · 简 要 目 录
-
Part 1 · 项 目 信 息
-
Part 2 · 数 据 生 成
-
Part 3 · 匹 配 算 法
-
Part 4 · 结 果 分 析
-
Part 5 · 结 对 规 范
-
Part 6 · 结 对 过 程、感 受
Part 1 · 项 目 信 息
开 发 人 员
开 发 人 员 一:郑浩晖 031502442
开 发 人 员 二:刘晨瑶 031502522
项 目 相 关
项 目 描 述:一个实现部门与学生智能匹配的小程序。
项 目 地 址:https://github.com/TheSkyFucker/DepartmentSelector
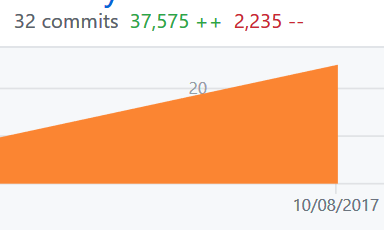
代 码 统 计:
- 核 心 代 码:2200行,去除自动生成文档后约1200行。
- 测 试 代 码:450行。
README 预 览:

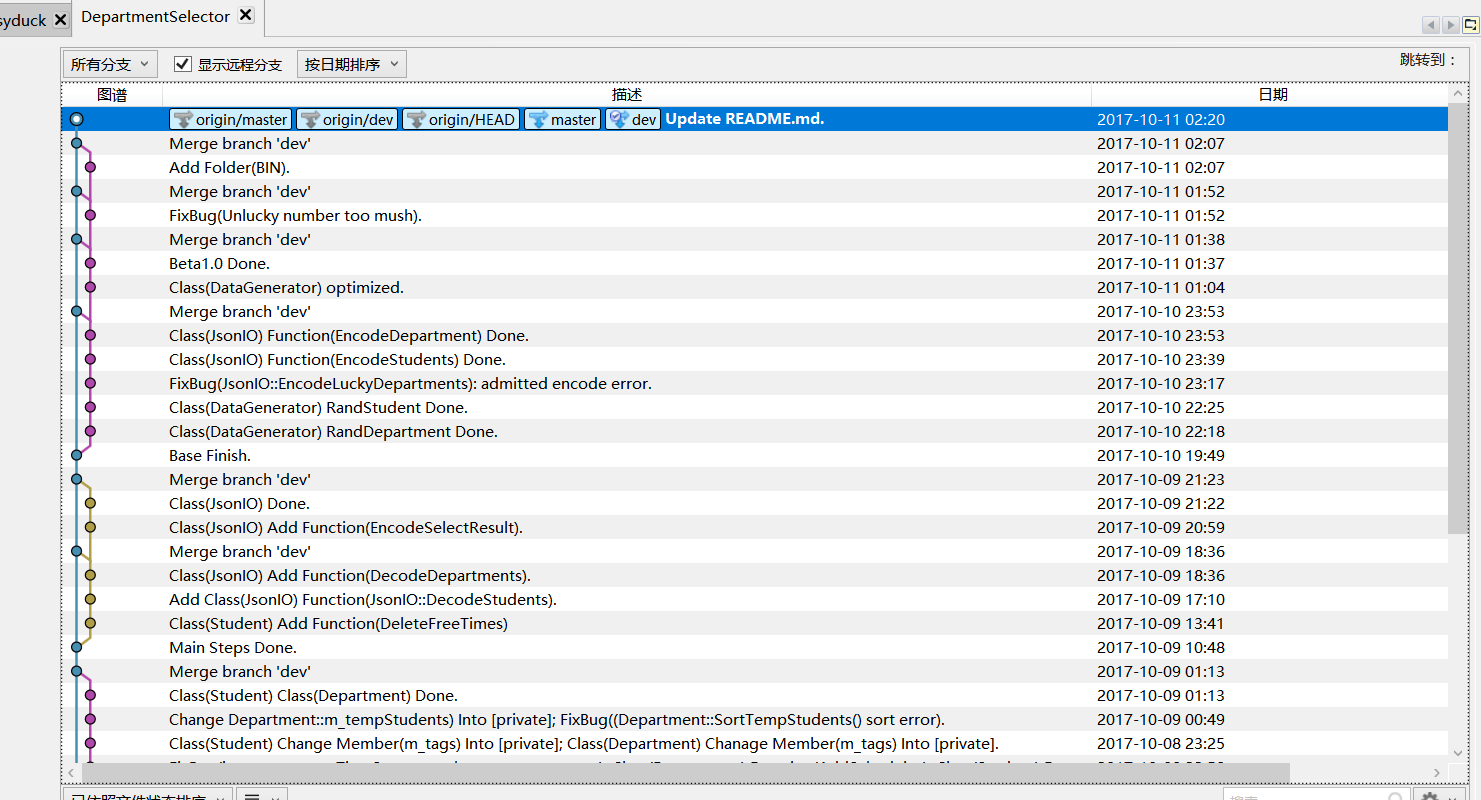
源 代 码 管 理:
Part 2 · 数 据 生 成
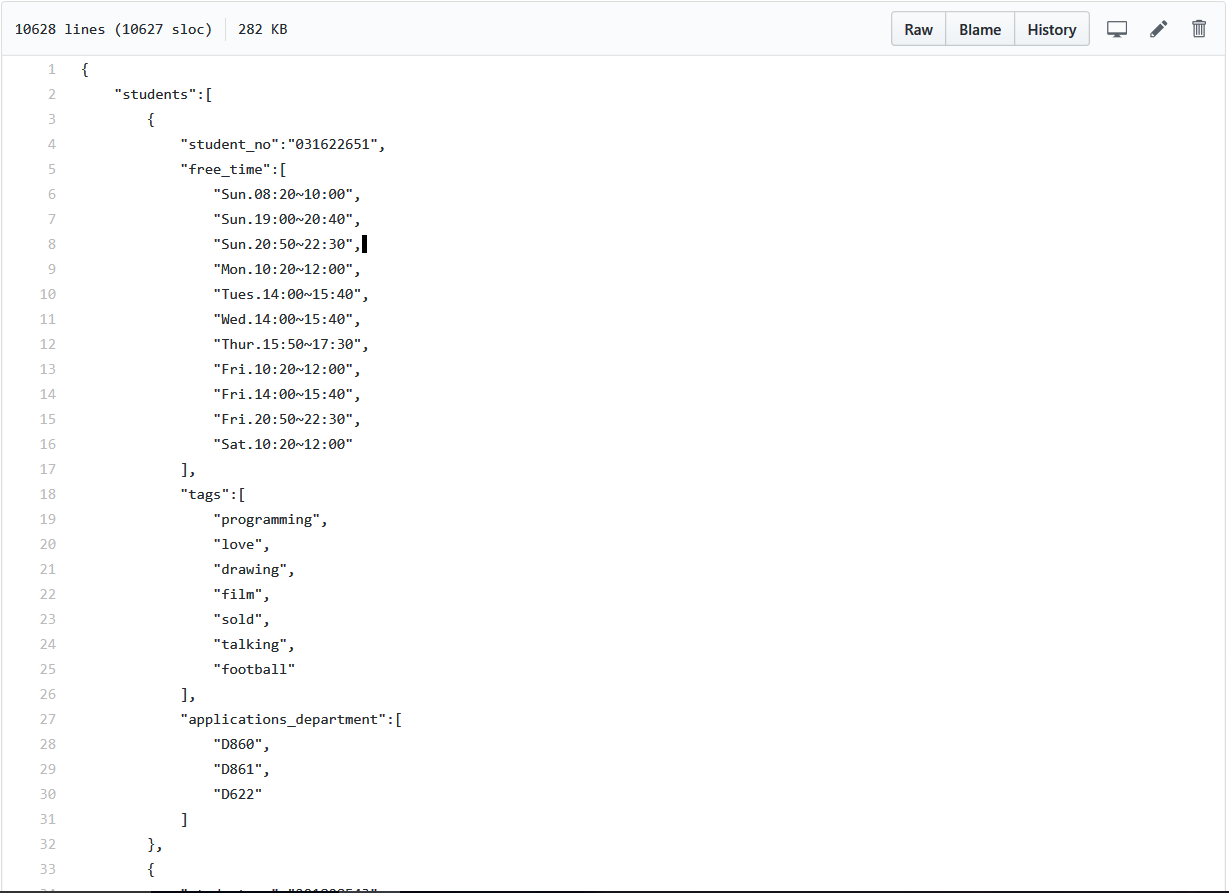
(0)最 终 数 据
数 据 文 件 地 址:传 送 链 接
最 终 数 据 预 览:
(1)输 入 信 息 整 理

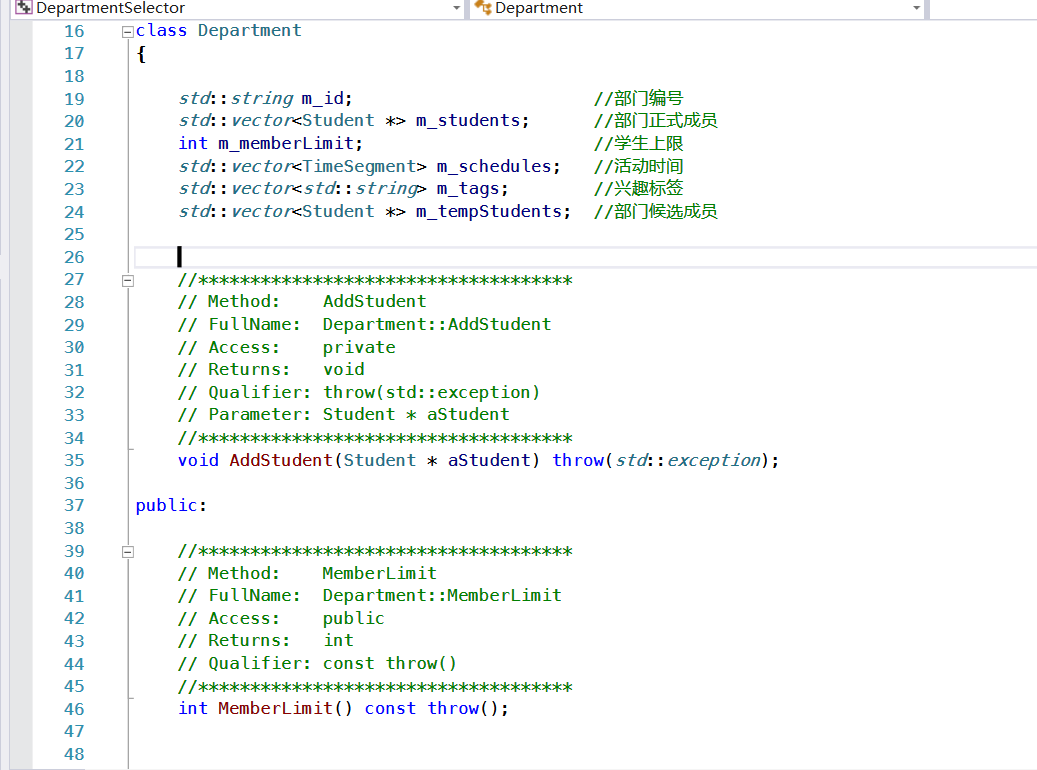
部 门 信 息 整 理 Department
| 参 数 | 类 型 | 范 围 | 简 述 |
|---|---|---|---|
department_no |
string |
[1, ?] |
部门编号(唯一) |
member_limit |
int |
[10, 15] |
学生上限 |
event_schedules |
string[] |
[2, ?] |
活动时间 |
tags |
string[] |
[2, ?] |
特点标签(必有) |
学 生 信 息 整 理 Student
| 参 数 | 类 型 | 范 围 | 简 述 |
|---|---|---|---|
student_no |
string |
[1, ?] |
学生编号(唯一) |
free_time |
string[] |
[2, ?] |
空闲时段 |
applications_department |
string[] |
[2, 5] |
部门意愿(优先级递减) |
tags |
string[] |
[2, ?] |
兴趣标签 |
(2)考 虑 因 素 整 理
学 生 部 分
模 仿 实 际 格 式 生 成 学 号:

按 课 切 割 的 空 闲 时 段 池:8:20 ~ 10:00, 8:20 ~ 10:00, 10:20 ~ 12:00, 14:00 ~ 15:40, 15:50 ~ 17:30, 19:00 ~ 20:40, 20:50 ~ 22:30
倾 向 时 间 不 冲 突 的 部 门:按照显示场景确实要优先考虑。
倾 向 标 签 更 匹 配 的 部 门:个体可能会有比较大的差异,但从普遍的角度来说这是趋势。
可 能 选 择 时 间 冲 突 部 门:即意愿强烈,故模拟学生时没有一棒打死,而是加上了一个负权,仍有被投志愿的可能。
部 门 部 分:
按 真 实 情 况 近 似 比 率:

活 动 时 间 具 有 波 动 性:长度以及开始时间等具有一定程度的波动。
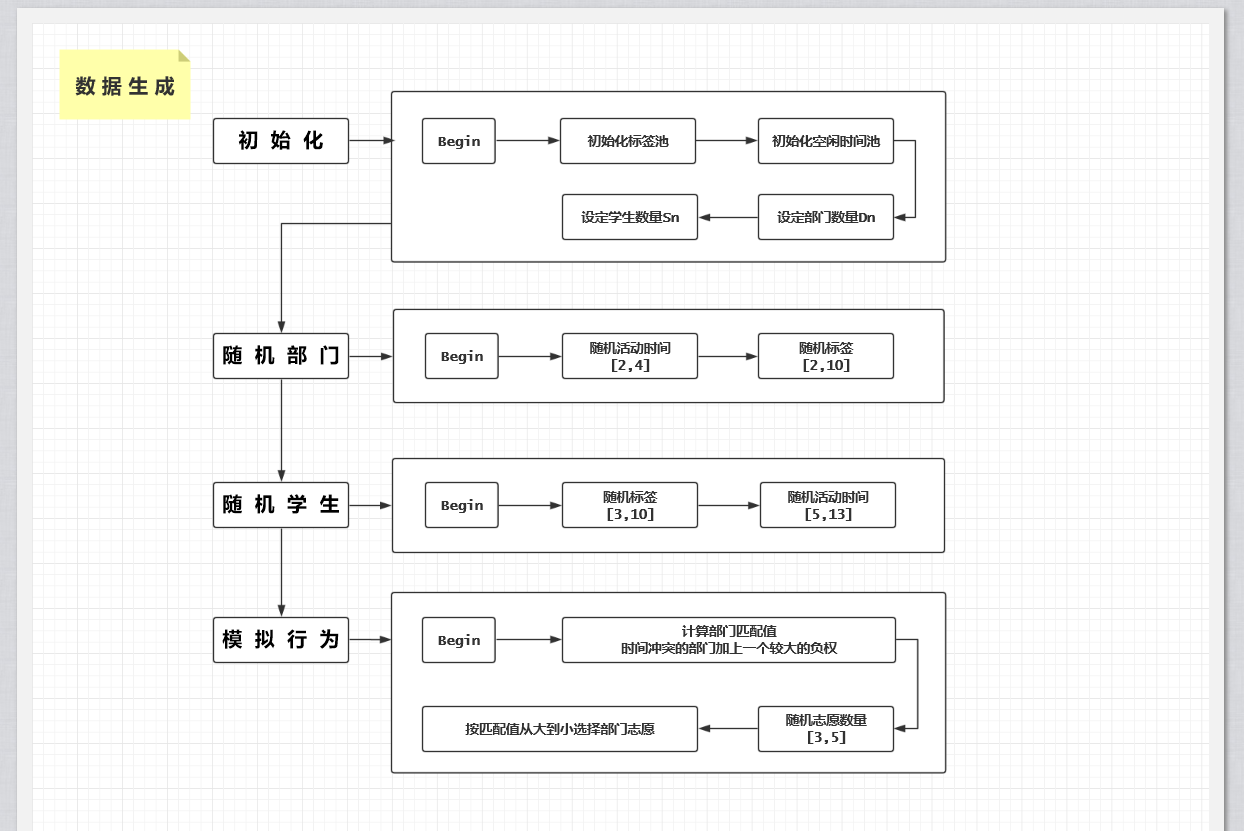
(3)生 成 流 程 设 计
Part 3 · 匹 配 算 法
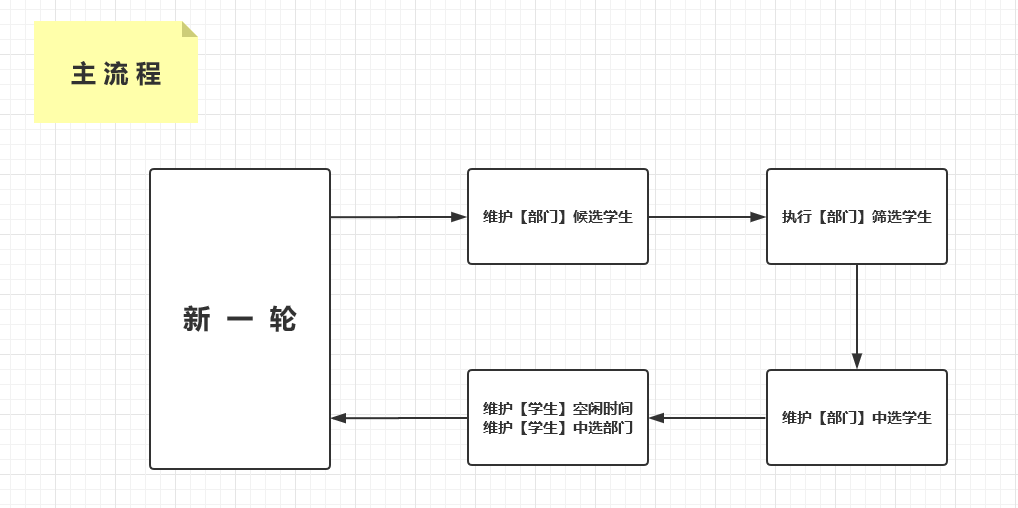
(0)总 览
算 法 概 括:“质 量 感 人(高), 数 量 也 感 人(低)”
总 架 构 图
(1)分 配 原 则(质 量 先 行)
第 一 原 则 · 时 间 没 有 冲 突
- “解 释”:如果和常规活动时间冲突,即便匹配了最后也会因多次旷活动而被淘汰;
第 二 原 则 · 学 生 意 愿 优 先
- “解 释”:即使最后是没中选的结果也不会让学生匹配到不在其意愿列表内的部门。
第 三 原 则 · 部 门 意 愿 优 先:
-
“解 释”:学生投递志愿后,具体匹配结果有部门主导。
-
“按 轮 次 先 投 显 得”:如果剩余人数不超过部门人数限制,则全部中选。
-
“同 轮 次 择 优 录 取”:当人数太多时,部门根据对每个候选学生的评定择优录取。
第 四 原 则 · 拉 低 富 裕 差 距:
-
“解 释”:分配中,已中选部门多的同学 相比 已中选部门少的同学,应有一定的劣势。
-
“中 得 越 多 越 难 继 续 中”:把中选部门数量作为学生评定的一个因素。
(2)学 生 评 定
核 心 公 式:"排 序 权 值" = "标 签 匹 配" X "中 选 价 值"
中 选 价 值:1 / ( 已中选部门数量 + 1 )
标 签 匹 配:该学生和该部门共有的标签数量。
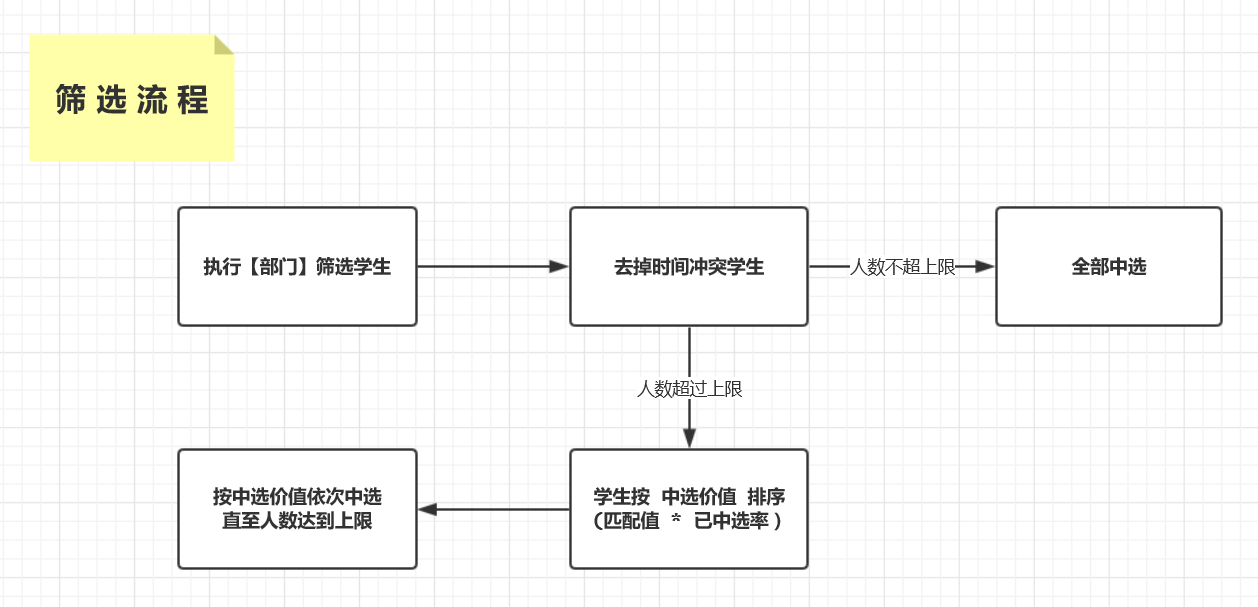
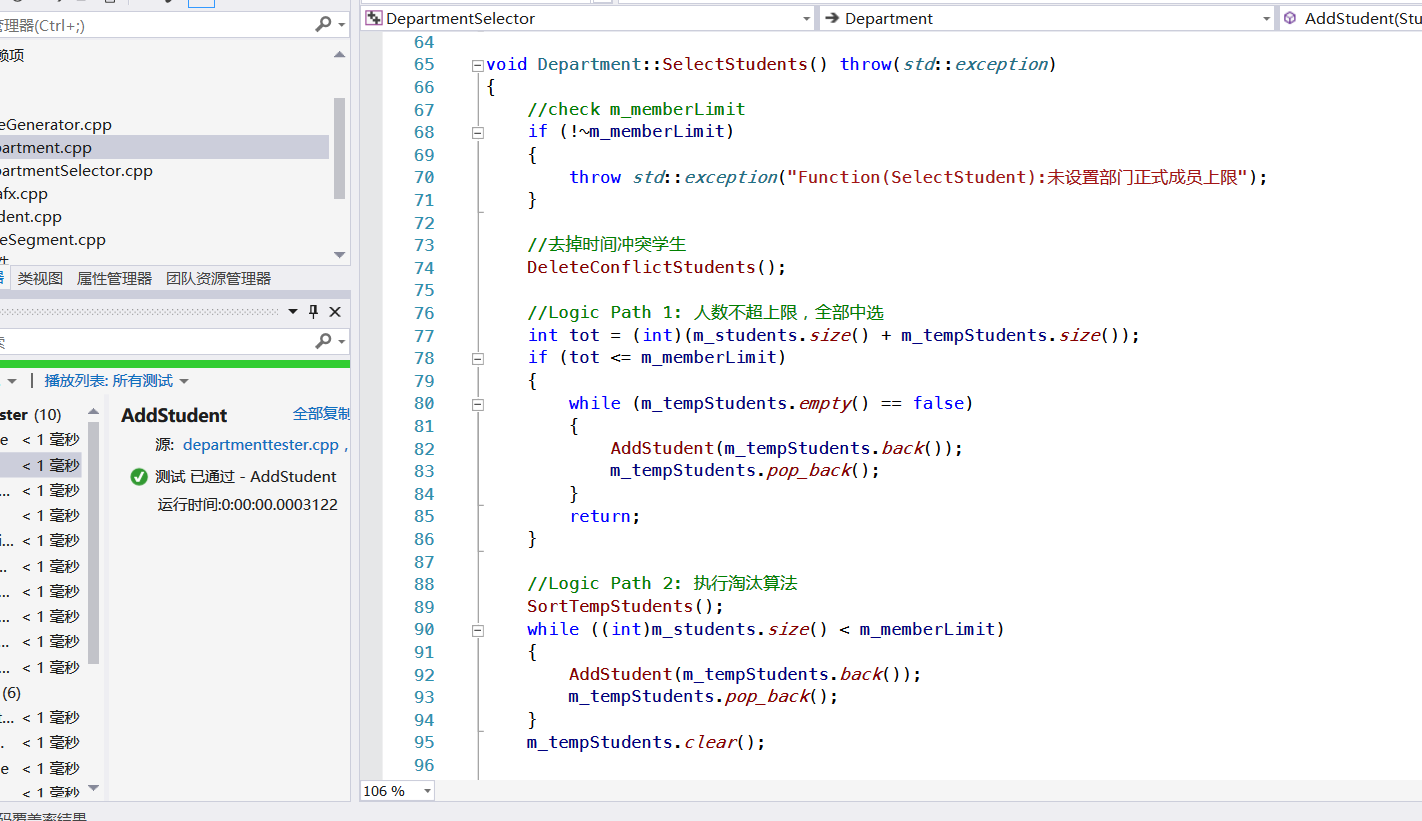
(3)淘 汰 算 法
一 轮 淘 汰 · 时 间 冲 突 的 学 生
二 轮 淘 汰 · 按 学 生 评 定 择 优
(4)特 殊 考 量
学 生 中 选 多 个 部 门
- “要 求”:部门之间的活动时间必须不冲突。
- “设 计”:会把 已中选的部门的活动时间 从每一轮 中选的学生的空闲时间 中扣除。

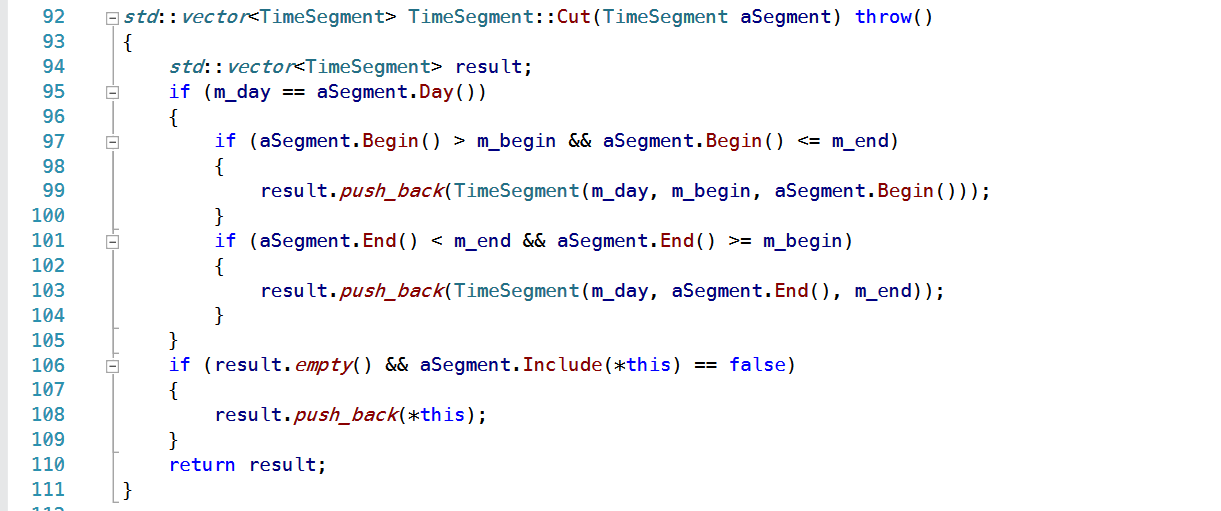
输 入 信 息 存 在 疏 忽
-
“要 求”:虽然约定好了 “时间段无交”,“标签不重复” 等原则,但由于数据并非共同开发的团队提供,作为外来的数据,我们讨论后觉得有理由也有必要做一定的处理。
-
“设 计”:私有化成员,在提供的对外接口完成 “自动合并有交时段”,“自动去重标签” 等。
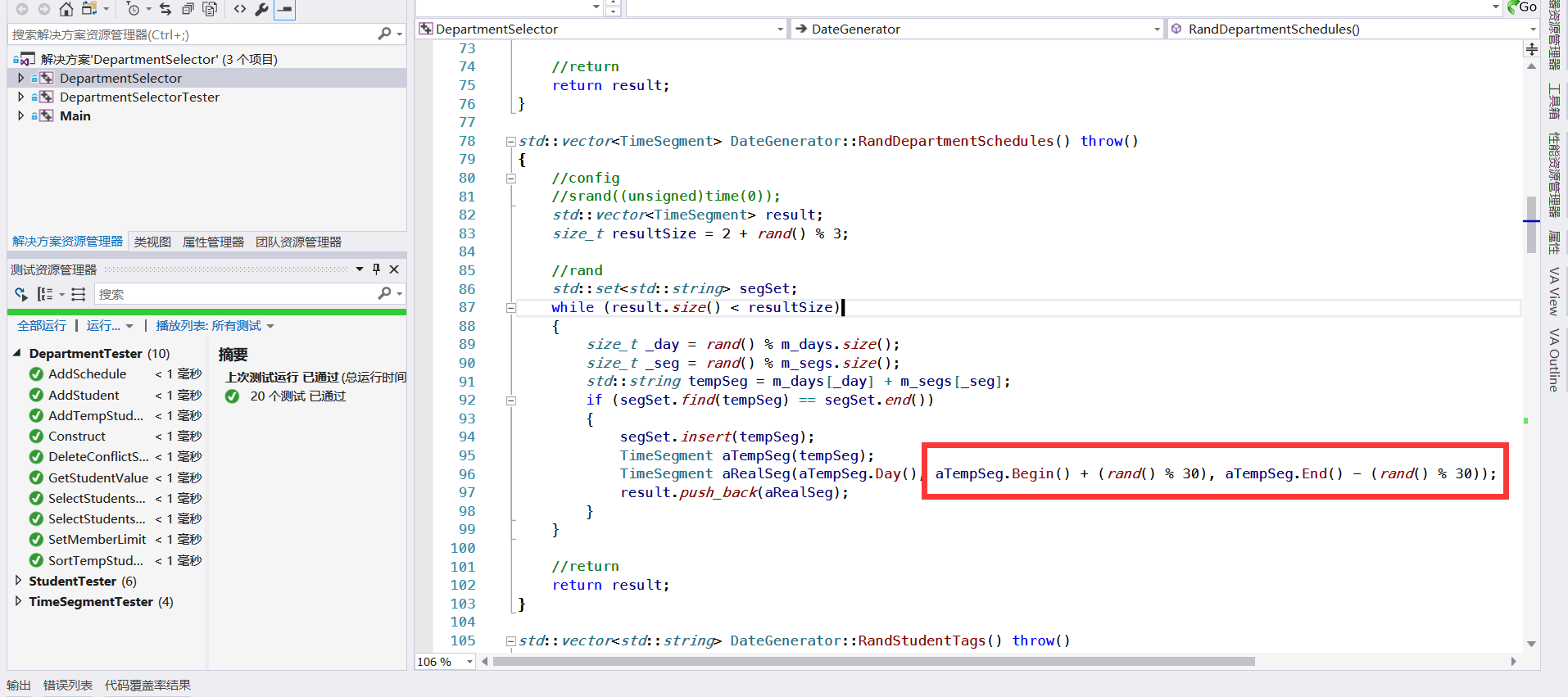
-
“示 例:自 动 合 并 空 闲 时 间 代 码”
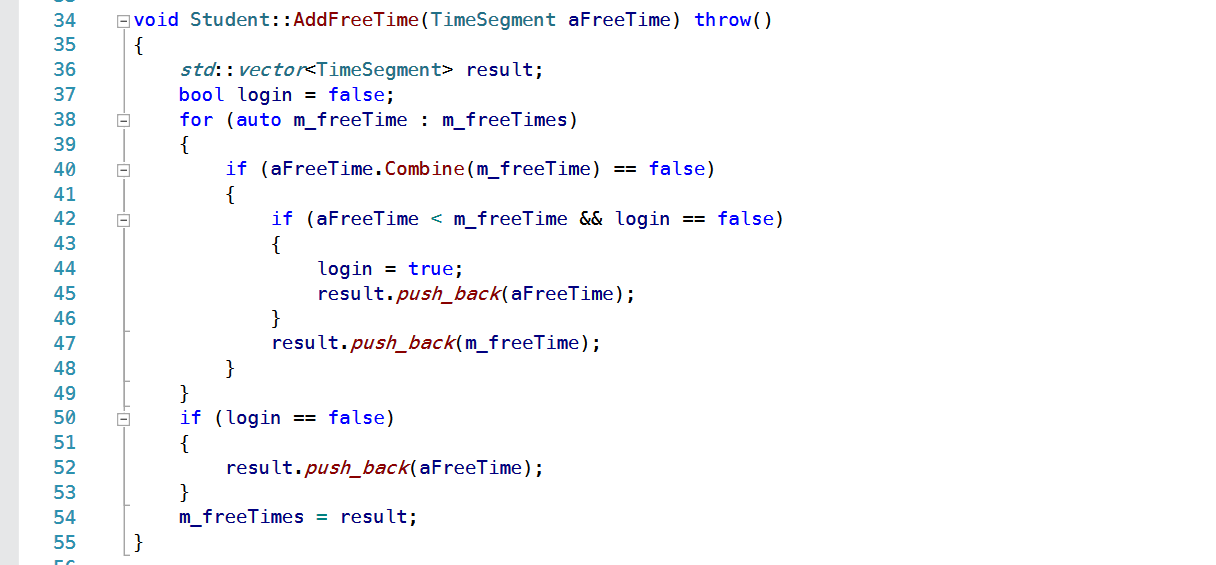
Part 4 · 结 果 分 析
(0)分 析 声 明
测 试 原 则 一:不测极端数据,所有学生空余时间、标签爆表然后全部中选,不具有测试意义。
测 试 原 则 二:不测小数据,小数据下生成算法波动大不稳定,不具有测试意义。
分 析 方 向 一:质量。
分 析 方 向 二:数量。
(1)学 生 中 选 率
结 果 不出所料的匹配率不高。
分 析 原 因 一:时间不冲突优先原则首当其冲,匹配率较低;
分 析 原 因 二:为了求质量,中选部门时,学生的空闲时间被部门活动时间压缩,再匹配率较低。
(2)部 门 中 选 率
结 果:相对理想,300学生20部门时,我们生成的数据没人的部门大概保持在 10% 左右。
(3)中 选 学 生 满 意 度
结 果:较好,符合预期。
原 因:因为我们的考量中时间不冲突占较大比重,且保证了 中选的多个部门时间不冲突,自然我们的分析中也会把时间不冲突的权重加大。
(4)波 动 来 源
分 析 原 因 一 · 标 签 池 的 大 小
-
分析加测试发现,标签池调大时如果测试数据量不变大,则算法效果会差不少。
-
因为标签匹配可能性降低,而和时间不冲突叠加在一起,出现没有部门适合的概率变大。
分 析 原 因 二 · 空 闲 时 段 池 的 大 小
- 理由同上一个一样,池子越大,出现适合的部门的概率会降低。
Part 5 · 结 对 规 范
(1)规 范 文 档
(2)部 分 规 范 示 例
“函 数 带 文 档”、“命 名 符 合 规 范”
“先 写 测 试 在 写 代 码”

“适 当 注 释”、“函 数 专 注 于 一 件 事”
Part 6 · 结 对 过 程、感 受
(1)结 对 过 程
阶 段 一 · 准 备:商定初次讨论时间,再次之前各自认真阅读作业需求,为讨论做准备工作。
阶 段 二 · 讨 论:围绕作业需求,提出自己的疑惑点、想法,确立项目核心算法的初步设想。
阶 段 三 · 设 计:共同设计架构图、流程图。
阶 段 四 · 实 现:国庆期间采取共享屏幕结对编程,边实现边讨论。
阶 段 五 · 测 试:生成一些数据进行测试、讨论和分析。
(2)结 对 感 受
提 高 效 率:
-
感觉效率提高了不少,即便再小心有时候还是会漏掉一些东西,然后过后才注意到,受到更大的影响。
-
结对中不少问题都是当即被对友发现,把损失降到了最低。
思 路 更 广:
-
个人总是容易陷入思维盲区,独自编程的状态总是会有一定的波动,然后或多或少的留下一些质量较差的代码。
-
两个人同时思考领航员时不时提出 “是否有必要性” 等等的设问,一步步朝更好的方向前进。
(3)结 对 建 议
先 写 测 试!:
-
结对中我们依旧是坚持贯彻 “先写测试”,虽然一开始可能会有写出来的东西没怎么被用上的感觉。
-
当项目快收尾时设计了一些改动,测试直接把改动造成的问题暴露了出来,快速的就能摸着单元测试找到那一块地方出现了问题,感觉非常的棒,瞬间会觉得哪怕只为了这一次也值了。
代 码 管 理!:
-
结对中每个小阶段的完成双方都有必要提醒一下对方进行一次
commit,做好源代码管理。 -
对整个整个项目的脉络的拿捏也会随着源码管理的进行而不断变得清晰。
End.