####
网址池的实现
对于比较大型的爬虫来说,URL管理的管理是个核心问题,管理不好,就可能重复下载,也可能遗漏下载。这里,我们设计一个URL Pool来管理URL。
这个URL Pool就是一个生产者-消费者模式:
和scrapy的设计是一样的,
1,爬虫从网址池那url去下载解析,
2,爬虫解析的新的url再往网址池里面放,
爬虫 ------ 网址池
他们是双向的,
####
网址池必须要具备3个功能
1,可以从池子里面拿出url,去让爬虫下载,
2,可以让爬虫,往这个池子里,添加新的url
3,池子内部,需要管理url的状态,
###
那么url的状态应该有几种,
1,已经爬取过的url,这种url就不能再爬了,需要去重,
2,下载失败多次了,无效的url,这种也不需要再去爬了,
3,正在被下载的url,这种是正在被爬虫的,
4,下载失败了,但是需要再次尝试的,这种就是增加了重试的机制,
###
前两个是永久状态,这种就不需要爬虫再管了,但是这种还是要存储起来,因为要做增量爬取,就设计到一个问题就是爬过的url不能再爬了,
所以需要存起来做去重,
比如爬取京东的商品,至少有几千万个url,需要怎么维护,这就是网址池的作用,
现在有一个很明显的问题,就是这一部分url,肯定是越来越大的,怎么存?
存mysql,这种mysql查找速度比较慢,
存redis,这种内存型的数据库,这种就是scrapy-redis这么做的,但是这种对内存的大小要求很高,几亿个url,你存在内存,占据是非常大的,
还有没有其他的方法,
我们这个URL Pool选用LevelDB来作为URL状态的永久存储。
LevelDB是Google开源的一个key-value数据库,速度非常快,同时自动压缩数据。我们用它先来实现一个UrlDB作为永久存储数据库。
level DB,是谷歌使用c++写的,windows使用会比较麻烦,倒是Linux是非常简单的,
###
urlDB的实现
import leveldb class UrlDB: '''Use LevelDB to store URLs what have been done(succeed or faile) ''' status_failure = b'0' status_success = b'1' def __init__(self, db_name): self.name = db_name + '.urldb' self.db = leveldb.LevelDB(self.name) def set_success(self, url): if isinstance(url, str): url = url.encode('utf8') try: self.db.Put(url, self.status_success) s = True except: s = False return s def set_failure(self, url): if isinstance(url, str): url = url.encode('utf8') try: self.db.Put(url, self.status_failure) s = True except: s = False return s def has(self, url): if isinstance(url, str): url = url.encode('utf8') try: attr = self.db.Get(url) return attr except: pass return False
####
主要是三个方法,
1,判断url是否已经存在了,这种是为了去重,避免重复的url进入这个网址池,
2,设置成功,这种就是爬虫爬完了,告诉网址池,这个爬完了不需要再爬了,
3,设置失败,这种就是爬失败了,为了后续要重试,
操作是很简单的,封装这个,就是为了替换对redis数据库的操作,
###
leveldb的使用 :
linux安装: pip install leveldb
leveldb的使用
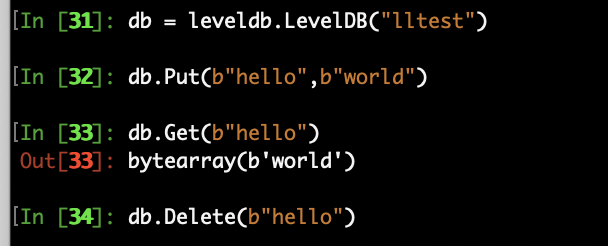
里面输入要新建数据库的名字,就会在当前的文件夹下面生成一个以这个名字命名的文件
然后就可以操作了,
注意存入的数据必须都是二进制的,
####
urlpool的实现
import pickle import leveldb import time import urllib.parse as urlparse class UrlPool: '''URL Pool for crawler to manage URLs ''' def __init__(self, pool_name): self.name = pool_name self.db = UrlDB(pool_name) self.waiting = {} # {host: set([urls]), } 按host分组,记录等待下载的URL self.pending = {} # {url: pended_time, } 记录已被取出(self.pop())但还未被更新状态(正在下载)的URL self.failure = {} # {url: times,} 记录失败的URL的次数 self.failure_threshold = 3 self.pending_threshold = 10 # pending的最大时间,过期要重新下载 self.waiting_count = 0 # self.waiting 字典里面的url的个数 self.max_hosts = ['', 0] # [host: url_count] 目前pool中url最多的host及其url数量 self.hub_pool = {} # {url: last_query_time, } 存放hub url self.hub_refresh_span = 0 self.load_cache() def __del__(self): self.dump_cache() def load_cache(self,): path = self.name + '.pkl' try: with open(path, 'rb') as f: self.waiting = pickle.load(f) cc = [len(v) for k, v in self.waiting.items()] print('saved pool loaded! urls:', sum(cc)) except: pass def dump_cache(self): path = self.name + '.pkl' try: with open(path, 'wb') as f: pickle.dump(self.waiting, f) print('self.waiting saved!') except: pass def set_hubs(self, urls, hub_refresh_span): self.hub_refresh_span = hub_refresh_span self.hub_pool = {} for url in urls: self.hub_pool[url] = 0 def set_status(self, url, status_code): if url in self.pending: self.pending.pop(url) if status_code == 200: self.db.set_success(url) return if status_code == 404: self.db.set_failure(url) return if url in self.failure: self.failure[url] += 1 if self.failure[url] > self.failure_threshold: self.db.set_failure(url) self.failure.pop(url) else: self.add(url) else: self.failure[url] = 1 self.add(url) def push_to_pool(self, url): host = urlparse.urlparse(url).netloc if not host or '.' not in host: print('try to push_to_pool with bad url:', url, ', len of ur:', len(url)) return False if host in self.waiting: if url in self.waiting[host]: return True self.waiting[host].add(url) if len(self.waiting[host]) > self.max_hosts[1]: self.max_hosts[1] = len(self.waiting[host]) self.max_hosts[0] = host else: self.waiting[host] = set([url]) self.waiting_count += 1 return True def add(self, url, always=False): if always: return self.push_to_pool(url) pended_time = self.pending.get(url, 0) if time.time() - pended_time < self.pending_threshold: print('being downloading:', url) return if self.db.has(url): return if pended_time: self.pending.pop(url) return self.push_to_pool(url) def addmany(self, urls, always=False): if isinstance(urls, str): print('urls is a str !!!!', urls) self.add(urls, always) else: for url in urls: self.add(url, always) def pop(self, count, hub_percent=50): print(' max of host:', self.max_hosts) # 取出的url有两种类型:hub=1, 普通=0 url_attr_url = 0 url_attr_hub = 1 # 1. 首先取出hub,保证获取hub里面的最新url. hubs = {} hub_count = count * hub_percent // 100 for hub in self.hub_pool: span = time.time() - self.hub_pool[hub] if span < self.hub_refresh_span: continue hubs[hub] = url_attr_hub # 1 means hub-url self.hub_pool[hub] = time.time() if len(hubs) >= hub_count: break # 2. 再取出普通url left_count = count - len(hubs) urls = {} for host in self.waiting: if not self.waiting[host]: continue url = self.waiting[host].pop() urls[url] = url_attr_url self.pending[url] = time.time() if self.max_hosts[0] == host: self.max_hosts[1] -= 1 if len(urls) >= left_count: break self.waiting_count -= len(urls) print('To pop:%s, hubs: %s, urls: %s, hosts:%s' % (count, len(hubs), len(urls), len(self.waiting))) urls.update(hubs) return urls def size(self,): return self.waiting_count def empty(self,): return self.waiting_count == 0
#####
这个网址池的实现,还是比较复杂的,
需要细细分析一下,
1,pickle的使用:
pickle这个库是把内存中的数据序列化到硬盘上面来,
比如可以把内存中的字典存储到硬盘,也可以把硬盘上存的字典,再放到内存,都是用这个pickle,
load_cache(self,): ----初始化的时候加载url
dump_cache(self): ---这是结束的时候使用的方法,就是把内存中的数据放到硬盘,
####
2,对url的管理,waiting,pending,failure
按照url的host进行分组 self.waiting = {} # {host: set([urls]), } 按host分组,记录等待下载的URL
是用来存放url的,它是一个字典(dict)结构,key是url的host,value是一个用来存储这个host的所有url的集合(set)。 为什么分组?防止并发的时候一次1000次都是同一个网站,这就是一个小小的攻击了, 但是如果是同样1000次,但是是不通的网站呢,就没有什么问题了,这就是分组的意义,
入池的时候,使用到了addmany, add, push_to_pull self.pending = {} # {url: pended_time, } 记录已被取出(self.pop())但还未被更新状态(正在下载)的URL 正在下载的url,
用来管理正在下载的url状态。它是一个字典结构,key是url,value是它被pop的时间戳。
当一个url被pop()时,就是它被下载的开始。当该url被set_status()时,就是下载结束的时刻。
如果一个url被add() 入pool时,发现它已经被pended的时间超过pending_threshold时,就可以再次入库等待被下载。否则,暂不入池。 失败的次数 self.failure = {} # {url: times,} 记录失败的URL的次数 self.failure_threshold = 3
是一个字典,key是url,value是失败的次数,超过failure_threshold就会被永久记录为失败,不再尝试下载。
self.hub_pool = {} # {url: last_query_time, } 存放hub url 是一个用来存储hub页面的字典,key是hub url,value是上次刷新该hub页面的时间.
hub页面,比如新浪新闻的首页,就是一个hub页面 新闻抓取最好的状态是什么,就是新浪发布一个新闻,我就能抓取到这个, hub页面就是上面有很多的url,就是hub页面,
#######
网址池的加入
def set_hubs(self, urls, hub_refresh_span): ---hub_refresh_span这个是定义的huburl下载的间隔 self.hub_refresh_span = hub_refresh_span self.hub_pool = {} ----是一个用来存储hub页面的字典,key是hub url,value是上次刷新该hub页面的时间. for url in urls: self.hub_pool[url] = 0 def push_to_pool(self, url): host = urlparse.urlparse(url).netloc if not host or '.' not in host: ---这是判断是不是一个正确的host print('try to push_to_pool with bad url:', url, ', len of ur:', len(url)) return False if host in self.waiting: if url in self.waiting[host]: return True self.waiting[host].add(url) if len(self.waiting[host]) > self.max_hosts[1]: ---这是更新最大的host, self.max_hosts[1] = len(self.waiting[host]) self.max_hosts[0] = host else: self.waiting[host] = set([url]) self.waiting_count += 1 return True def add(self, url, always=False): ---每次加的时候,当前时间-pending里的时间,小于我设置的间隔,说明这个还不能被再次拿出来,self.pending_threshold = 10 # pending的最大时间,过期要重新下载 ---每次加的时候,都去leveldb里面看看这个url有没有,如果有就不加入进来了,说明这个被下载成功,或者彻底失败了,就不管了,
---这样确保成功了就不会被再次下载了,彻底失败了也不会被下载了, ---如果有pendedtime,把这个url从pending里面去掉, if always: return self.push_to_pool(url) pended_time = self.pending.get(url, 0) if time.time() - pended_time < self.pending_threshold: print('being downloading:', url) return if self.db.has(url): return if pended_time: self.pending.pop(url) return self.push_to_pool(url) def addmany(self, urls, always=False): ---这个很简单,就是循环去加入 if isinstance(urls, str): print('urls is a str !!!!', urls) self.add(urls, always) else: for url in urls: self.add(url, always)
#####
网址池的取出
def pop(self, count, hub_percent=50): print(' max of host:', self.max_hosts) # 取出的url有两种类型:hub=1, 普通=0 url_attr_url = 0 url_attr_hub = 1 # 1. 首先取出hub,保证获取hub里面的最新url. hubs = {} hub_count = count * hub_percent // 100 for hub in self.hub_pool: span = time.time() - self.hub_pool[hub] ----这是计算时间是否是到了我设置的间隔了, if span < self.hub_refresh_span: continue hubs[hub] = url_attr_hub # 1 means hub-url self.hub_pool[hub] = time.time() ----这是覆盖这个hubrul被取出的时间, if len(hubs) >= hub_count: break # 2. 再取出普通url left_count = count - len(hubs) print("len(hubs)", left_count) urls = {} for host in self.waiting: ---这个取的时候是按照host取的 if not self.waiting[host]: continue url = self.waiting[host].pop() ----这是取出一个, urls[url] = url_attr_url ---这是放到url里面 self.pending[url] = time.time() ---这是更新pending,因为取出了是放到了pending中, if self.max_hosts[0] == host: self.max_hosts[1] -= 1 if len(urls) >= left_count: break self.waiting_count -= len(urls) print('To pop:%s, hubs: %s, urls: %s, hosts:%s' % (count, len(hubs), len(urls), len(self.waiting))) urls.update(hubs) return urls
这个urls的结构:{"huburl":1,"huburl":1,"url",0,}
网址池的成功和失败
set_status() 方法设置网址池中url的状态 def set_status(self, url, status_code): ----从pending中去掉,因为不管成功失败,都不用在pending里面了 if url in self.pending: self.pending.pop(url) if status_code == 200: self.db.set_success(url) return if status_code == 404: ----记住200和404都是永久的状态, 就永久踢出网址池了, self.db.set_failure(url) return if url in self.failure: ----这是其他失败状态的重试,这是在一次urlpool的过程,断了就要重新开始了, self.failure[url] += 1 if self.failure[url] > self.failure_threshold: self.db.set_failure(url) self.failure.pop(url) else: self.add(url) else: self.failure[url] = 1 self.add(url)
url分成了两类,一个huburl,一个普通的url
pop就是我一次拿出多少个url来,如果我并发就是1000,我就是一次拿出1000个url,机器比较弱,那就少拿,比如10个,hub页面占据50%
huburl是需要不断的拿的,所以有一个更新时间戳的过程,
######
数据库的设计
这个爬虫需要用到MySQL数据库,在开始写爬虫之前,我们要简单设计一下数据库的表结构: 1. 数据库设计 创建一个名为crawler的数据库,并创建爬虫需要的两个表: crawler_hub :此表用于存储hub页面的url +------------+------------------+------+-----+-------------------+----------------+ | Field | Type | Null | Key | Default | Extra | +------------+------------------+------+-----+-------------------+----------------+ | id | int(10) unsigned | NO | PRI | NULL | auto_increment | | url | varchar(64) | NO | UNI | NULL | | | created_at | timestamp | NO | | CURRENT_TIMESTAMP | | +------------+------------------+------+-----+-------------------+----------------+ 创建该表的语句就是: CREATE TABLE `crawler_hub` ( `id` int(10) unsigned NOT NULL AUTO_INCREMENT, `url` varchar(64) NOT NULL, `created_at` timestamp NOT NULL DEFAULT CURRENT_TIMESTAMP, PRIMARY KEY (`id`), UNIQUE KEY `url` (`url`) ) ENGINE=MyISAM DEFAULT CHARSET=utf8 对url字段建立唯一索引,可以防止重复插入相同的url。 crawler_html :此表存储html内容 html是大量的文本内容,压缩存储会大大减少磁盘使用量。这里,我们选用lzma压缩算法。表的结构如下: +------------+---------------------+------+-----+-------------------+----------------+ | Field | Type | Null | Key | Default | Extra | +------------+---------------------+------+-----+-------------------+----------------+ | id | bigint(20) unsigned | NO | PRI | NULL | auto_increment | | urlhash | bigint(20) unsigned | NO | UNI | NULL | | | url | varchar(512) | NO | | NULL | | | html_lzma | longblob | NO | | NULL | | | created_at | timestamp | YES | | CURRENT_TIMESTAMP | | +------------+---------------------+------+-----+-------------------+----------------+ 创建该表的语句为: CREATE TABLE `crawler_html` ( `id` bigint(20) unsigned NOT NULL AUTO_INCREMENT, `urlhash` bigint(20) unsigned NOT NULL COMMENT 'farmhash', `url` varchar(512) NOT NULL, `html_lzma` longblob NOT NULL, `created_at` timestamp NULL DEFAULT CURRENT_TIMESTAMP, PRIMARY KEY (`id`), UNIQUE KEY `urlhash` (`urlhash`) ) ENGINE=InnoDB DEFAULT CHARSET=utf8 该表中,我们存储了url的64位的farmhash,并对这个urlhash建立了唯一索引。id类型为无符号的bigint,也就是2的64次方,足够放下你能抓取的网页。 farmhash是Google开源的一个hash算法。64位的hash空间有2的64次方那么大,大到随意把url映射为一个64位无符号整数,也不会出现hash碰撞。老猿使用它多年也未发现hash碰撞的问题。 由于上传到pypi时,farmhash这个包名不能用,就以pyfarmhash上传到pypi上了,所以要安装farmhash的python包,应该是: pip install pyfarmhash (多谢评论的朋友反馈这个问题。) 数据库建立好后,我们就可以开始写爬虫的代码了。
process函数
def process(self, url, ishub): status, html, redirected_url = fn.downloader(url) self.urlpool.set_status(url, status) if redirected_url != url: self.urlpool.set_status(redirected_url, status) # 提取hub网页中的链接, 新闻网页中也有“相关新闻”的链接,按需提取 if status != 200: return if ishub: newlinks = fn.extract_links_re(redirected_url, html) goodlinks = self.filter_good(newlinks) print("%s/%s, goodlinks/newlinks" % (len(goodlinks), len(newlinks))) self.urlpool.addmany(goodlinks) else: self.save_to_db(redirected_url, html) 我传入一个新闻详情页,就可以直接保存到数据库了,有id,url,urlhash,html_lzma,createtime
###
filter_good函数
这个具体的实现过程,每一个任务都不一样,要根据任务的需要来过滤,
def filter_good(self, urls): --实现爬虫的时候,要注意你需要的链接,友好链接这样的,还有广告的链接,都不是我们要的链接, goodlinks = [] for url in urls: host = urlparse.urlparse(url).netloc if host in self.hub_hosts: goodlinks.append(url) return goodlinks
如何使用你的urlpool,还需要看你具体的业务这么使用这个网址池,
对url的去重问题,使用了hash算法,这个要学学,
注意这个urlpool里面还是实现了url的路径还有html都有的,
这个html是没有解析的,
如果是解析的话,使用另外的程序来解析的,就是放到另外的表了,
这个解析的使用多进程的方式,使用进程池的方式来,这个解析会涉及到cpu,如果是8核的,就是启动8个进程,
####
作业:还是新浪新闻,
多弄几个hub页面,然后把每一个hub页面里面的普通新闻url,都抓取下来,
把对应的页面url和页面的源代码存储到数据库里面去,
#####