###
异步io
io就是input,output,输入和输出,
读写硬盘,读写数据库的时候,就是输入输出,下载网页存入数据库的时候,就是io操作
以写数据为例,如果是阻塞型写入操作,进程要一直等待写结束返回才会进行后面的操作,但是如果你使用异步I/O,你可以将写请求发送到队列,然后就可以去做其他事情了,写操作会异步进行。
连接数据库,传输,下载,也是io操作,
一般软件系统的 I/O 通常指磁盘和网络,因为有等待的过程,所以会有性能的损耗,比较费时间,
cpu计算密集型和io密集型
而解析网页,提取url或者我们所需要的内容,或者解析xpath,正则表达式,这都是cpu运算的过程,这就是cpu密集型,
#####
具体的异步io和协程&asyncio的内容我写到了这个文章里面:https://www.cnblogs.com/andy0816/p/15040847.html
使用async 关键字来定义的函数,就是协程函数,
#####
异步io示例1:
import time import asyncio async def hi(msg, sec): print("enter hi() . {} @{}".format(msg, time.strftime("%H:%M:%S"))) # 到这个地方遇到了阻塞,就会第一个任务挂起,然后执行第二个任务,直到4个协程都执行起来,这个时候事件循环里面是有1个main,4个hi协程的, await asyncio.sleep(sec) print("{} @{}".format(msg, time.strftime("%H:%M:%S"))) return sec async def main(): print("begin @{}".format(time.strftime("%H:%M:%S"))) tasks = [] for i in range(1,5): # 这一步是创建task任务,并且都加入到事件循环中,里面是传入一个协程对象, t = asyncio.create_task(hi(i, i)) tasks.append(t) print("main asyncio sleeping") for t in tasks: # 这个await 是等待返回,一直要等待返回值之后,才会往下走,这个时候main协程是挂起的状态, r = await t print("r:", r) print("end at {}".format(time.strftime("%H:%M:%S"))) # 这个run,是创建事件循环,并且把main() 协程加入事件循环中,这个是一个主线程 asyncio.run(main())
####
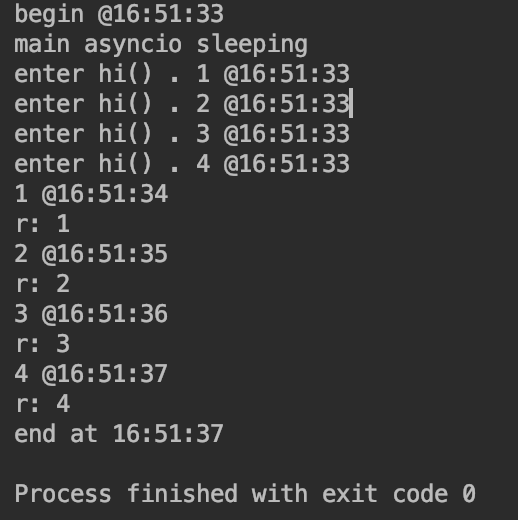
可以看到,四个协程任务,是同步起来的,从开始到结束只用了4秒
四个任务分别是使用了,1,2,3,4秒,
如果是同步的话,就是相加10秒,但是现在只用了4秒,起到了一个并发的效果,
####
异步io示例2:
import time import asyncio async def hi(msg, sec): print("enter hi() . {} @{}".format(msg, time.strftime("%H:%M:%S"))) # 到这个地方遇到了阻塞,就会第一个任务挂起,然后执行第二个任务,直到4个协程都执行起来,这个时候事件循环里面是有1个main,4个hi协程的, await asyncio.sleep(sec) print("{} @{}".format(msg, time.strftime("%H:%M:%S"))) return sec async def main(): print("begin @{}".format(time.strftime("%H:%M:%S"))) tasks = [] for i in range(1,5): # 这一步是创建task任务,并且都加入到事件循环中,里面是传入一个协程对象, t = asyncio.create_task(hi(i, i)) tasks.append(t) print("main asyncio sleeping") # for t in tasks: # # 这个await 是等待返回,一直要等待返回值之后,才会往下走,这个时候main协程是挂起的状态, # r = await t # print("r:", r) print("end at {}".format(time.strftime("%H:%M:%S"))) # 这个run,是创建事件循环,并且把main() 协程加入事件循环中,这个是一个主线程 asyncio.run(main())
####
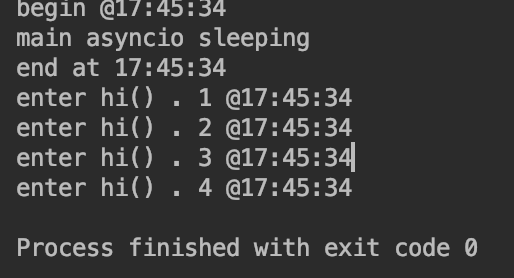
注释了for循环里面的await之后,发现main函数结束了之后,hi协程并没有结束,整个的协程就结束了,
整个的过程是:
先执行main,然后main执行之后马上去执行其他的协程,然后遇到阻塞之后,再去执行main,发现main已经结束了,所以整个的协程就结束了
所以main是主的,其他是子的,主的结束了,子的不管有没有结束都会结束,
####
异步io示例3:
import time import asyncio async def hi(msg, sec): print("enter hi() . {} @{}".format(msg, time.strftime("%H:%M:%S"))) # 到这个地方遇到了阻塞,就会第一个任务挂起,然后执行第二个任务,直到4个协程都执行起来,这个时候事件循环里面是有1个main,4个hi协程的, await asyncio.sleep(sec) print("{} @{}".format(msg, time.strftime("%H:%M:%S"))) return sec async def main(): print("begin @{}".format(time.strftime("%H:%M:%S"))) tasks = [] for i in range(1,5): # 这一步是创建task任务,并且都加入到事件循环中,里面是传入一个协程对象, t = asyncio.create_task(hi(i, i)) tasks.append(t) print("main asyncio sleeping") # 等待两秒 await asyncio.sleep(2) # for t in tasks: # # 这个await 是等待返回,一直要等待返回值之后,才会往下走,这个时候main协程是挂起的状态, # r = await t # print("r:", r) print("end at {}".format(time.strftime("%H:%M:%S"))) # 这个run,是创建事件循环,并且把main() 协程加入事件循环中,这个是一个主线程 asyncio.run(main())
####

执行的时候是按照先进先出的原则
所以是main先结束的,hi2是后结束的
###
异步io示例4:
import time import asyncio async def hi(msg, sec): print("enter hi() . {} @{}".format(msg, time.strftime("%H:%M:%S"))) # 到这个地方遇到了阻塞,就会第一个任务挂起,然后执行第二个任务,直到4个协程都执行起来,这个时候事件循环里面是有1个main,4个hi协程的, await asyncio.sleep(sec) print("{} @{}".format(msg, time.strftime("%H:%M:%S"))) return sec async def main(): print("begin @{}".format(time.strftime("%H:%M:%S"))) tasks = [] for i in range(1,5): # 这一步是创建task任务,并且都加入到事件循环中,里面是传入一个协程对象,创建了任务并没有执行任务,而是再await的时候才执行的 t = asyncio.create_task(hi(i, i)) # print("我看看创建了任务,是否执行了") await t tasks.append(t) print("main asyncio sleeping") # 等待两秒 # await asyncio.sleep(2) # for t in tasks: # # 这个await 是等待返回,一直要等待返回值之后,才会往下走,这个时候main协程是挂起的状态, # r = await t # print("r:", r) print("end at {}".format(time.strftime("%H:%M:%S"))) # 这个run,是创建事件循环,并且把main() 协程加入事件循环中,这个是一个主线程 asyncio.run(main())
####

这个时候就发现,如果在创建了之后就await,就相当于是同步的效果了
###
使用:
hi就可以变成一个download的函数,然后一次拿出100个url,生成100个task,然后开始下载,都下载完了,再结束,
这样你就理解了,
#####
实战案例
#!/usr/bin/env python3 # File: news-crawler-async.py # Author: veelion import traceback import time import asyncio import aiohttp import urllib.parse as urlparse import farmhash import lzma import uvloop asyncio.set_event_loop_policy(uvloop.EventLoopPolicy()) import sanicdb from urlpool import UrlPool import functions as fn import config class NewsCrawlerAsync: def __init__(self, name): self._workers = 0 self._workers_max = 30 self.logger = fn.init_file_logger(name+ '.log') self.urlpool = UrlPool(name) self.loop = asyncio.get_event_loop() self.session = aiohttp.ClientSession(loop=self.loop) self.db = sanicdb.SanicDB( config.db_host, config.db_db, config.db_user, config.db_password, loop=self.loop ) async def load_hubs(self,): sql = 'select url from crawler_hub' data = await self.db.query(sql) self.hub_hosts = set() hubs = [] for d in data: host = urlparse.urlparse(d['url']).netloc self.hub_hosts.add(host) hubs.append(d['url']) self.urlpool.set_hubs(hubs, 300) async def save_to_db(self, url, html): urlhash = farmhash.hash64(url) sql = 'select url from crawler_html where urlhash=%s' d = await self.db.get(sql, urlhash) if d: if d['url'] != url: msg = 'farmhash collision: %s <=> %s' % (url, d['url']) self.logger.error(msg) return True if isinstance(html, str): html = html.encode('utf8') html_lzma = lzma.compress(html) sql = ('insert into crawler_html(urlhash, url, html_lzma) ' 'values(%s, %s, %s)') good = False try: await self.db.execute(sql, urlhash, url, html_lzma) good = True except Exception as e: if e.args[0] == 1062: # Duplicate entry good = True pass else: traceback.print_exc() raise e return good def filter_good(self, urls): goodlinks = [] for url in urls: host = urlparse.urlparse(url).netloc if host in self.hub_hosts: goodlinks.append(url) return goodlinks async def process(self, url, ishub): status, html, redirected_url = await fn.fetch(self.session, url) self.urlpool.set_status(url, status) if redirected_url != url: self.urlpool.set_status(redirected_url, status) # 提取hub网页中的链接, 新闻网页中也有“相关新闻”的链接,按需提取 if status != 200: self._workers -= 1 return if ishub: newlinks = fn.extract_links_re(redirected_url, html) goodlinks = self.filter_good(newlinks) print("%s/%s, goodlinks/newlinks" % (len(goodlinks), len(newlinks))) self.urlpool.addmany(goodlinks) else: await self.save_to_db(redirected_url, html) self._workers -= 1 async def loop_crawl(self,): await self.load_hubs() last_rating_time = time.time() counter = 0 while 1: tasks = self.urlpool.pop(self._workers_max) if not tasks: print('no url to crawl, sleep') await asyncio.sleep(3) continue for url, ishub in tasks.items(): self._workers += 1 counter += 1 print('crawl:', url) asyncio.ensure_future(self.process(url, ishub)) gap = time.time() - last_rating_time if gap > 5: rate = counter / gap print(' loop_crawl() rate:%s, counter: %s, workers: %s' % (round(rate, 2), counter, self._workers)) last_rating_time = time.time() counter = 0 if self._workers > self._workers_max: print('====== got workers_max, sleep 3 sec to next worker =====') await asyncio.sleep(3) def run(self): try: self.loop.run_until_complete(self.loop_crawl()) except KeyboardInterrupt: print('stopped by yourself!') del self.urlpool pass if __name__ == '__main__': nc = NewsCrawlerAsync('yrx-async') nc.run()
#####
async def fetch(session, url, headers=None, timeout=9, binary=False): _headers = { 'User-Agent': ('Mozilla/5.0 (compatible; MSIE 9.0; ' 'Windows NT 6.1; Win64; x64; Trident/5.0)'), } if headers: _headers = headers try: async with session.get(url, headers=_headers, timeout=timeout) as response: status = response.status html = await response.read() if not binary: encoding = cchardet.detect(html)['encoding'] html = html.decode(encoding, errors='ignore') redirected_url = str(response.url) except Exception as e: msg = 'Failed download: {} | exception: {}, {}'.format(url, str(type(e)), str(e)) print(msg) html = '' status = 0 redirected_url = url return status, html, redirected_url
#####
解释:
1,aiohttp这个是相当于替代了requests的,requests是同步下载的, 具体的使用做了封装fetch函数,这个就是替换download函数的, 2,sanicdb,是对aiomysql的一个封装,是异步操作mysql的, 3,self._workers = 0 self._workers_max = 30 这两个比较重要,是生成的协程的个数,生成的协程不能太多了, 这个30,是定义了一次从网址池拿出多少的url,也是生成协程任务的数量, 为什么限制生成协程的个数,这个是cpu和带宽来决定的,因为协程越多,耗费的cpu越多,你写30,可能cpu占10%,但是你写300,可能cpu就达到来80%了 4,self.loop = asyncio.get_event_loop() self.session = aiohttp.ClientSession(loop=self.loop) 为什么还是使用get_event_loop创建事件循环,因为要把这个事件循环传给ClientSession, 而且连接数据库的时候也要传入事件循环, aiohttp为什么要这么用,我看我还是要学习学习 5,那些方法需要前面加async,那些不需要,一个原则就是:是否涉及到io,比如读数据库, 6,这个爬虫是一直在跑的,会不断的往urlpool里面加入url, 我对这个框架还是理解的不够,还是哪里有问题, 7,优雅的改正在运行的爬虫: 如果程序里面有参数经常改,就写到配置文件里面, 不然你改了程序就会断爬虫就不好了 隔一段时间加载一下配置文件就可以了 8,优雅的把爬虫停掉, 还是使用配置文件,把所有的任务都跑完了,就可以停止循环了,
####
####
####