####
scrapy模拟登陆1---使用cookie登陆
有些网站的cookie过期时间很长,比如一些小网站,
我们可以保存这个cookie,然后携带cookie登陆,
如果操作:
思考,这个start_urls是谁发起的?
这个是在爬虫继承的父类,spider里面,有一个start_requests,这个方法发起的请求,
我们的操作就是重写这个方法,
import scrapy import re class Spider3Spider(scrapy.Spider): name = 'spider3' allowed_domains = ['360doc.com'] start_urls = ['http://www.360doc.com/myfiles.aspx'] def start_requests(self): cookies = "XXX" # 复制自己的cookie cookies = {i.split("=")[0].strip(): i.split("=")[1].strip() for i in cookies.split(";")} # print(cookies) yield scrapy.Request( self.start_urls[0], callback=self.parse, cookies=cookies, ) def parse(self, response): result_list = re.findall(r'andylee0816', response.body.decode()) print(result_list) if __name__ == '__main__': from scrapy import cmdline cmdline.execute("scrapy crawl spider3 --nolog".split())
###

###
重点是要体会这种思想
这种方式的缺点,就是cookie会失效,
记住这种for循环的方式发起请求,这样每次都会携带cookie登陆了???
这种要测试一下,才能理解的更深刻,
####
scrapy模拟登陆2---使用post请求登陆

####
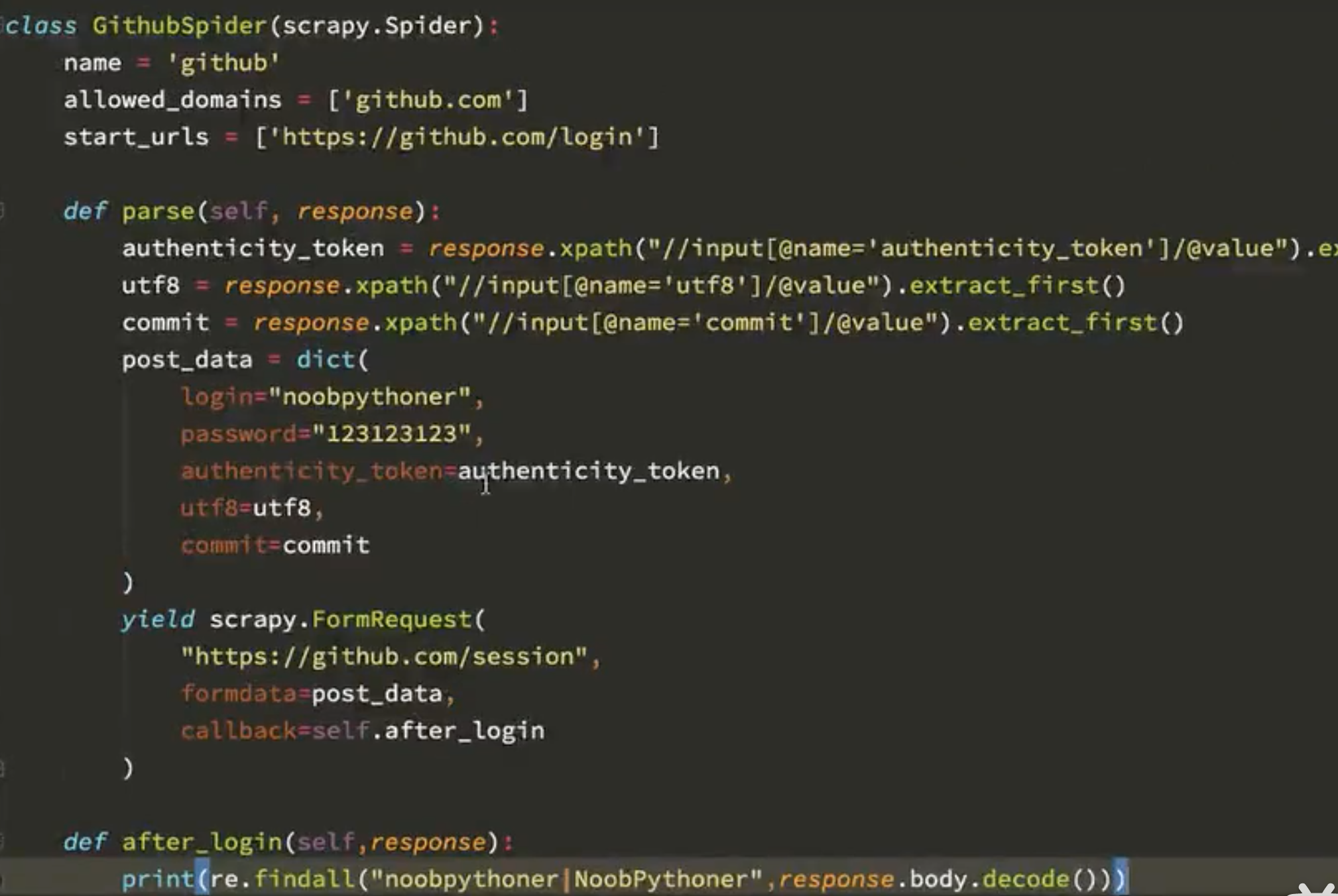
前面学过了,可以parse返回一个request,这里是一个formrequest,也就是带参数的请求,就是post请求,
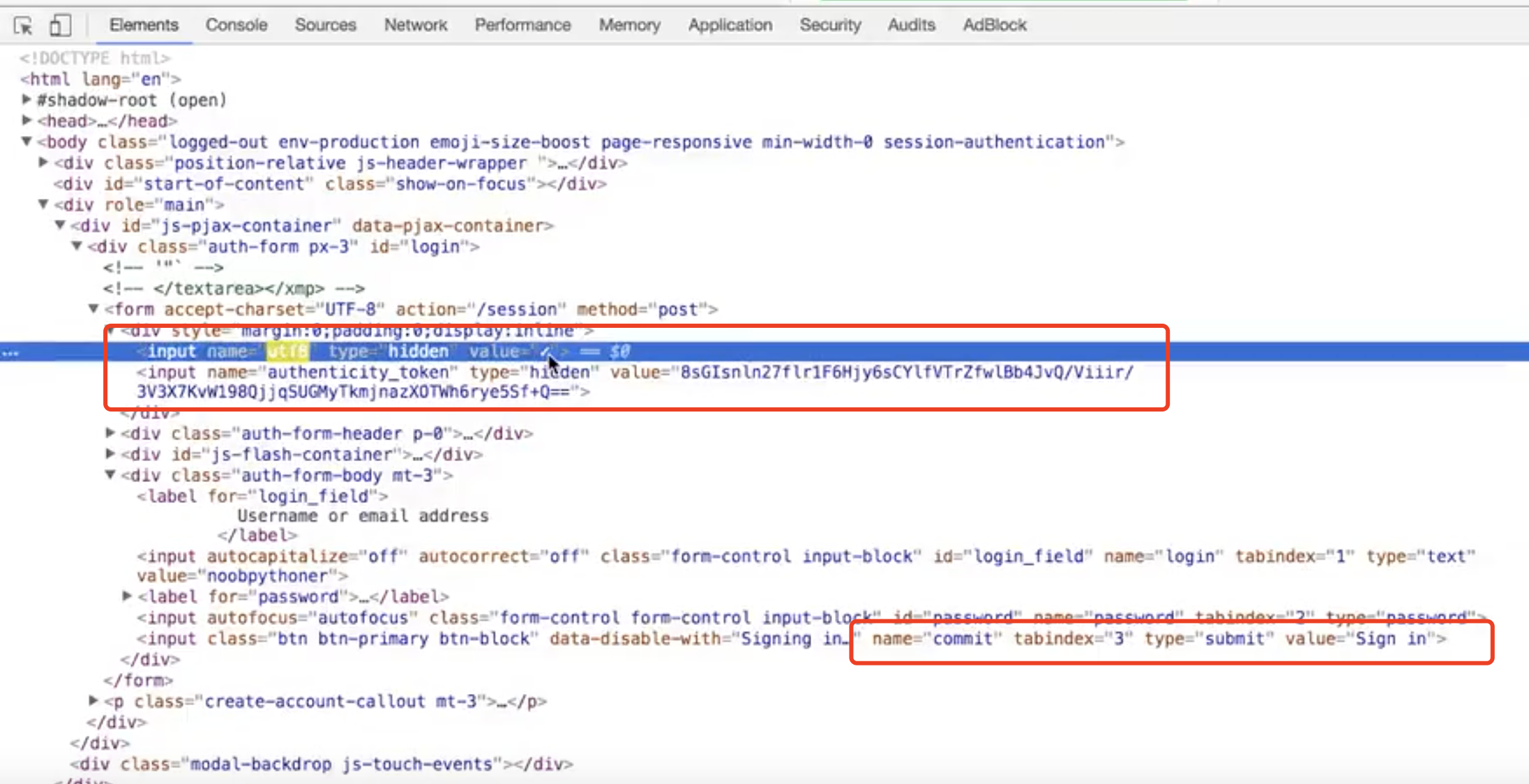
模拟登陆github,
注意这个formdata,有一个token是变化的,
这个在login这个url里面是有定义的,可以找到,
####
##
注意,组成的post数据,key不需要写引号,
这种就是使用post登陆,
####

###

###

###
这种方法是scrapy里面正统的登陆的方法,但是这个不是所有的网页都能行的,有一些网站登陆用这个方法就不行!!!
这个必须要知道,
但是你要体会这种登陆的思想,懂不,重要的是思想,
###
这个方法会自动去寻找form表达,我们只需要写用户名,密码就可以了,
但是如果有两个表单怎么办?
看看源码,可以定位具体的某一个表单,
但是这种只能用于没有验证的登陆,如果有验证其他的东西,就没有这么简单了,
如果密码post传递的时候加密了,就要找到js代码,看看怎么加密的,你加密之后传递就可以了,
####
上面的formrequest的登陆方式如果有验证码,就是无解的,
而使用cookie又是出现cookie失效的问题,
###
第三种方法,就是使用selenium登陆,这种才是好办法,
scrapy结合selenium模拟登陆----直接selenium拿到response返回
这种方法需要学习一下,这个算是一个通解,
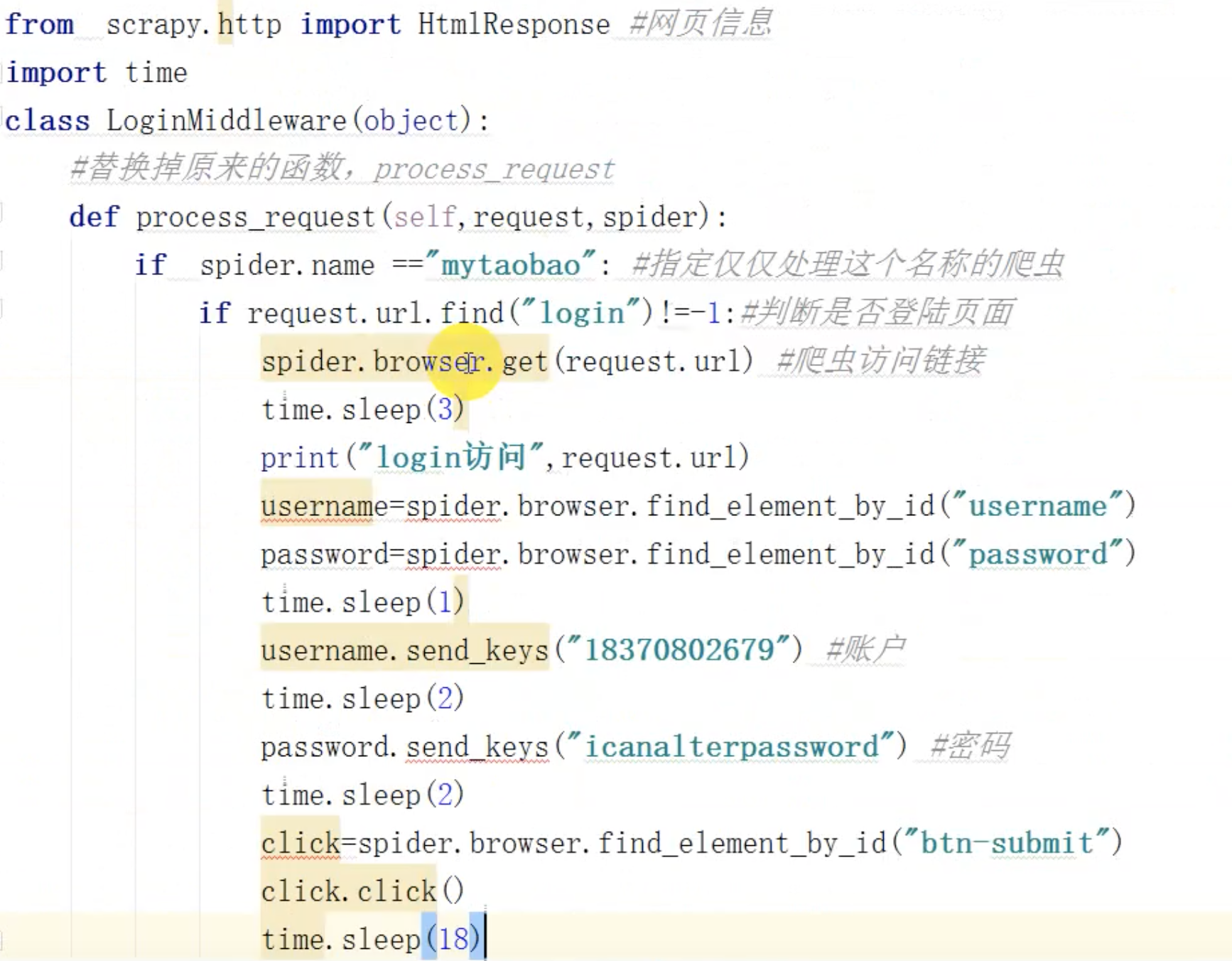
比如模拟登陆淘宝,



下载中间件:
所以这个selenium也是在下载中间件来做文章的,
处理了请求
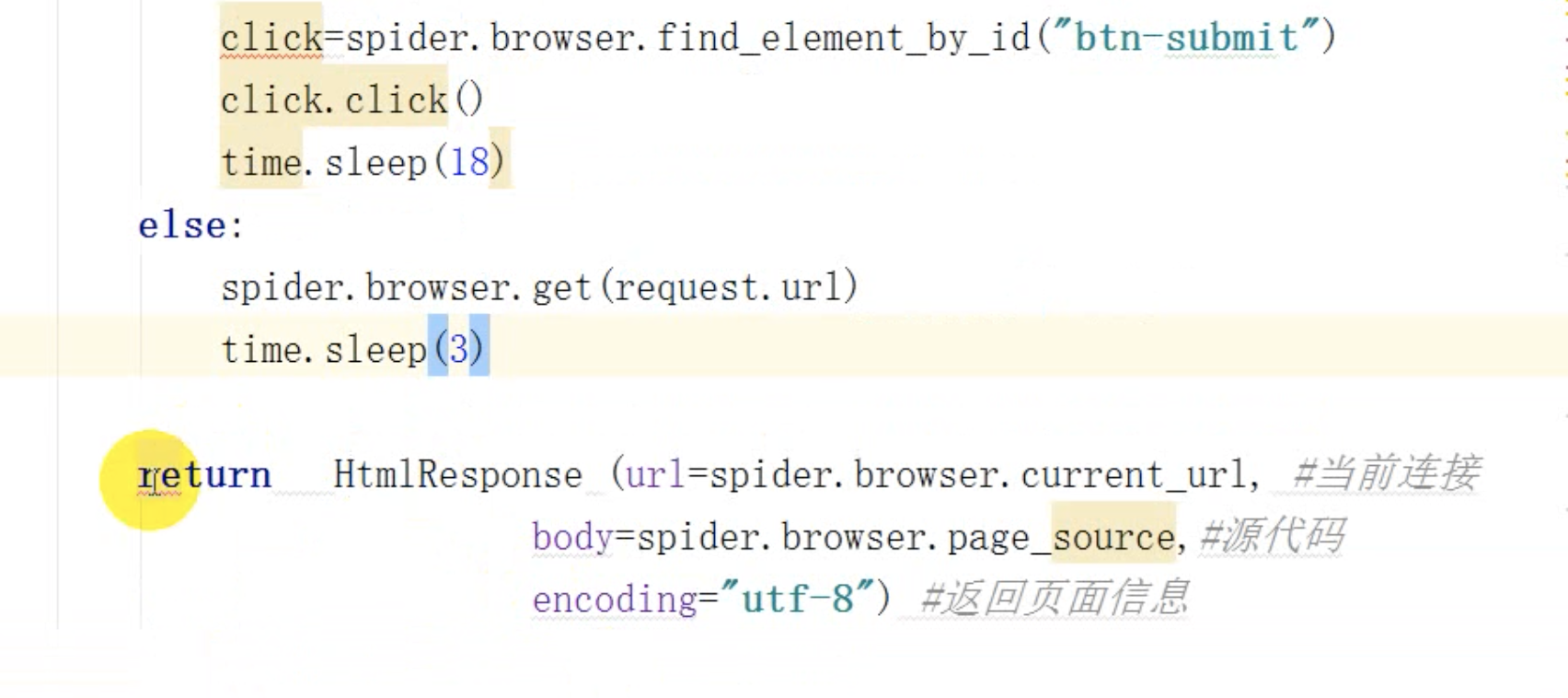
###
有关信号的知识,还是需要认识看一下,
这种登陆,还是强依赖selenium的,是否有办法,可以直接通过selenium拿到cookie,然后通过cookie登陆呢,
###
scrapy结合selenium模拟登陆----只使用selenium一次,拿到cookie之后,使用requests请求链接把response返回
爬虫

中间件
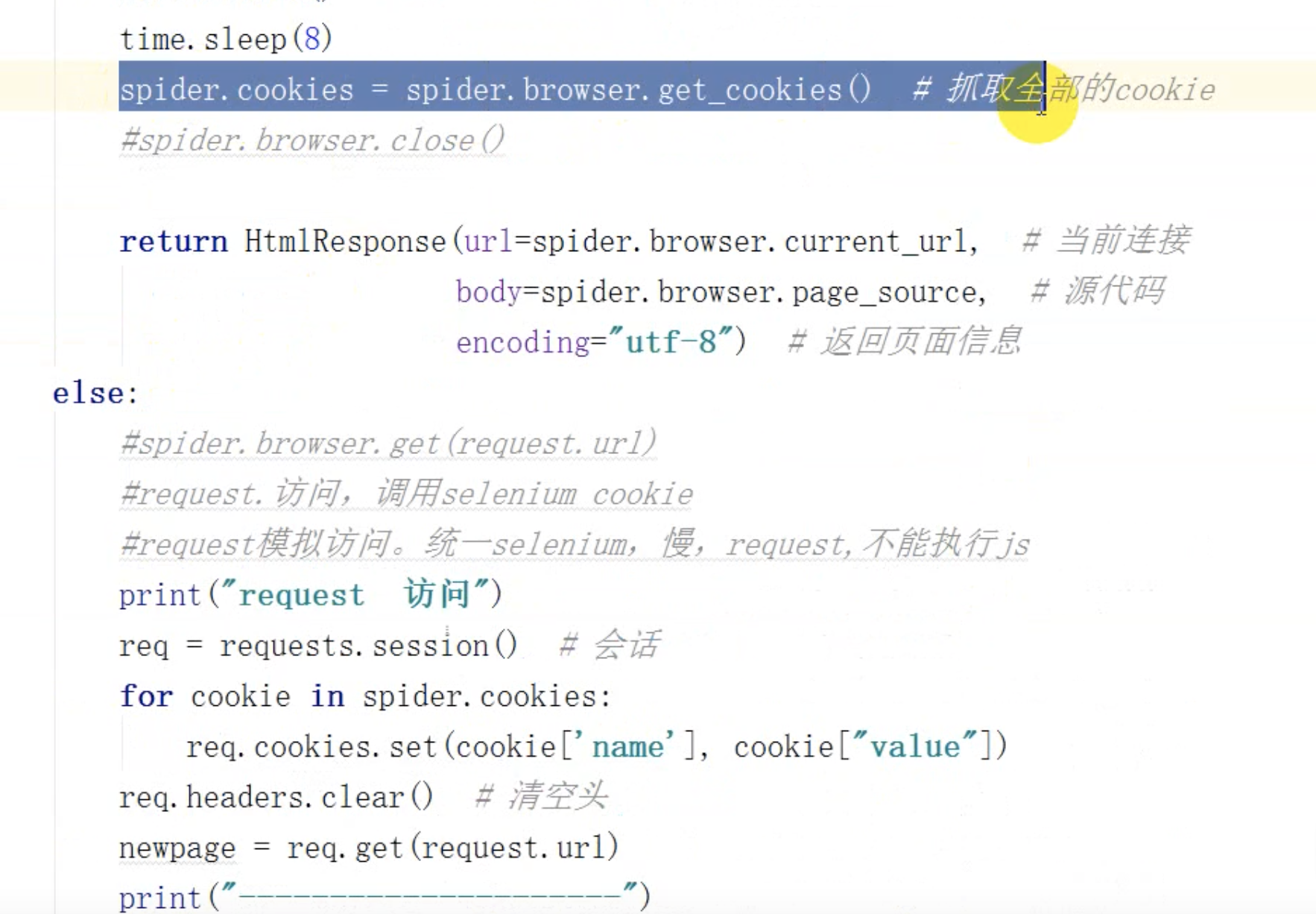

可见从上面的例子,可以看到,
我们可以通过selenium登陆,然后拿到cookie,然后通过requests携带cookie登陆,返回这个response,
那就厉害了,也就是说,每次爬虫处理的response,都是requests携带cookie请求过的,那这样就可以实现登陆了,
####
这种方式还有问题,是不是可以直接把cookie拿到,然后传递过scrapy呢,不要requests的参与,
也就是scrapy构造后续请求传递cookie的时候,都是把拿到的cookie携带访问的,
####
scrapy结合selenium模拟登陆----只使用selenium一次,拿到cookie之后,把cookie交给scrapy,后续都是scrapy的事情
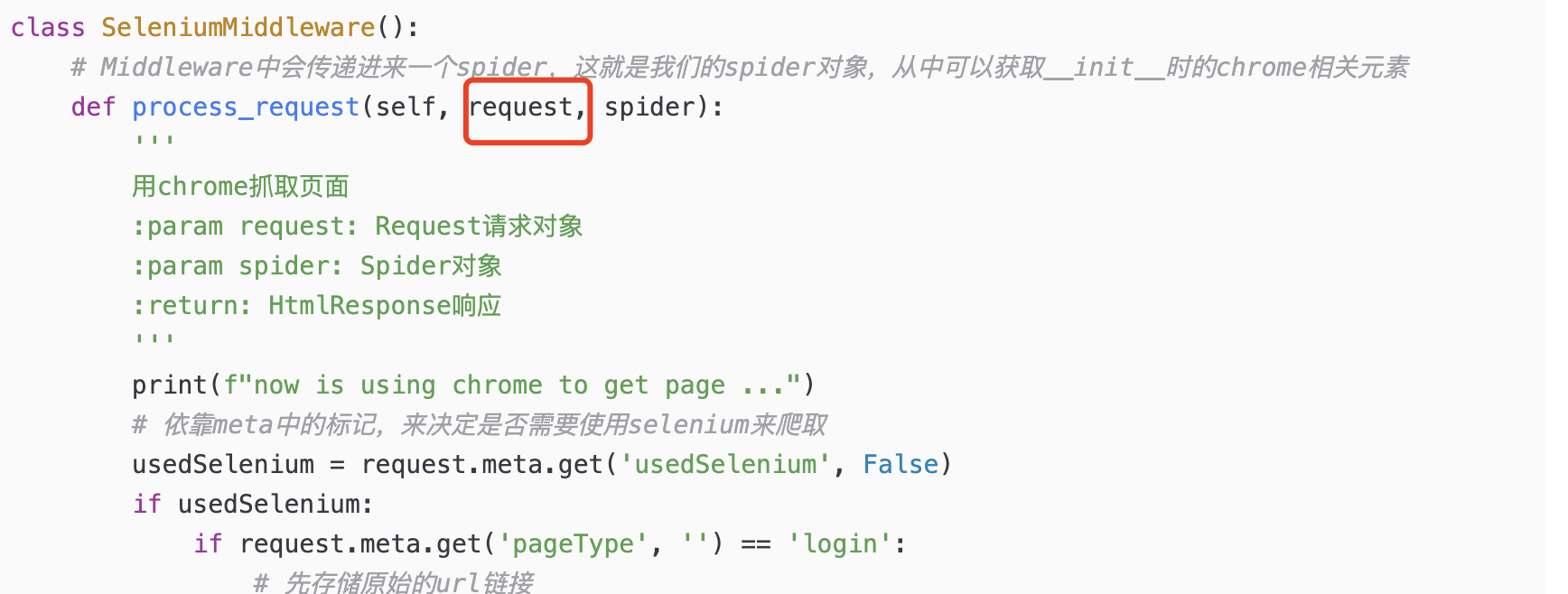
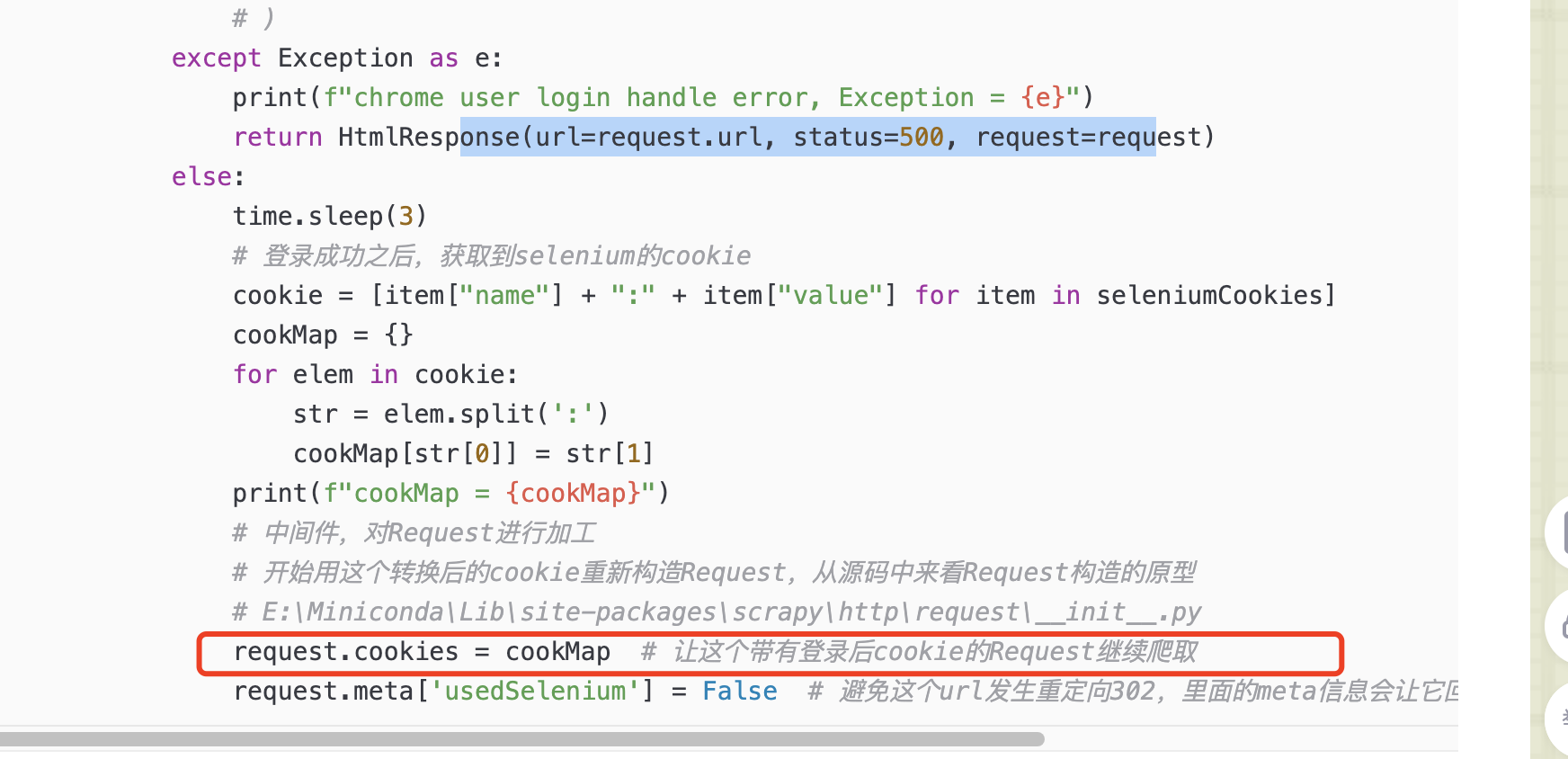
我们要知道,scrapy的cookie形态,和selenium的cookie形态是不一样的,前者是一个列表,里面一个字符串,而后者是一个里面,里面是字典格式的cookie,
所以这个应该放到哪里比较好,就是这个下载中间件的process_request里面,对请求进行处理,给他加上cookie,
######
######
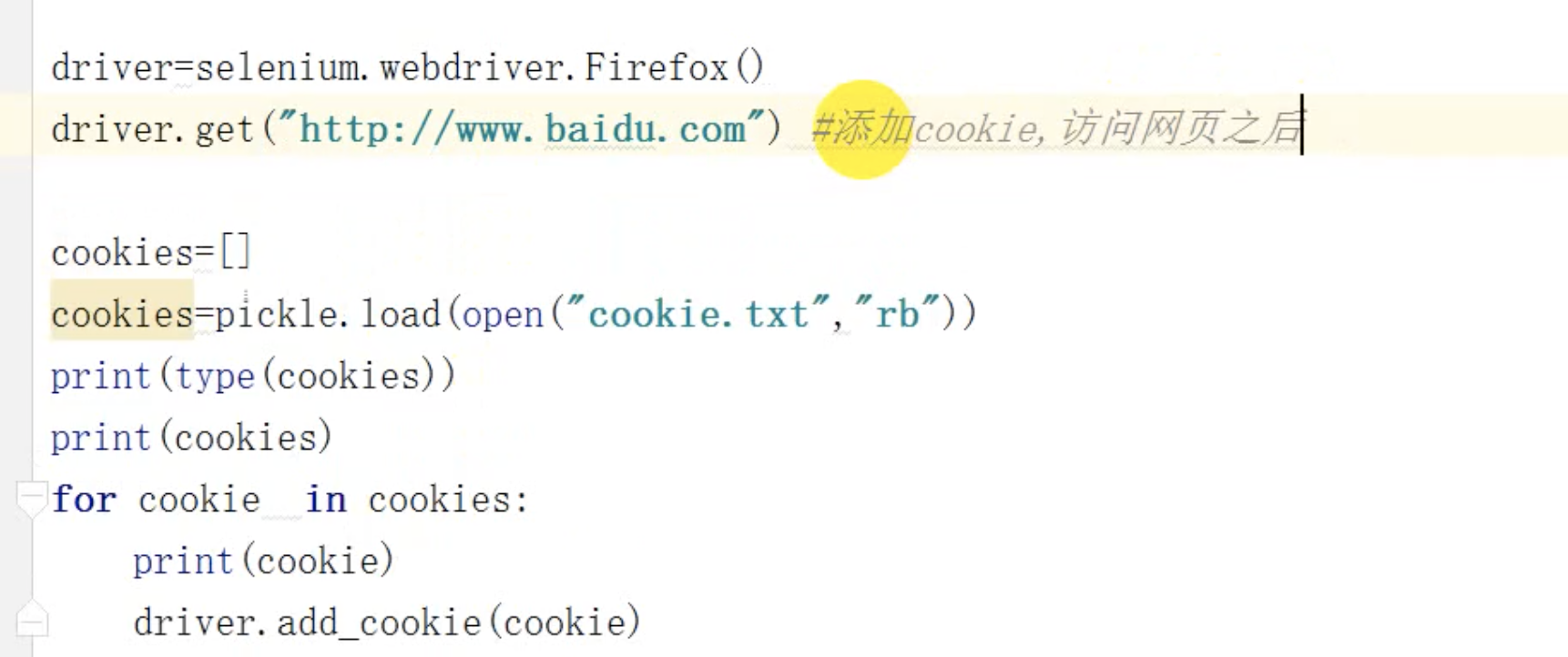
scrapy结合selenium模拟登陆----只使用selenium一次,拿到cookie之后,放到一个文件中,为了后续能在分布式中传递数据,
还可以把这个cookie放到文件中,然后通过文件来访问cookie,去登陆

####