####
使用scrapy-redis的意义
1,scrapy-redis源码在github上有,开源的
2,scrapy-redis是在scrapy基础上实现的,增加了功能,
第一个,requests去重,
第二个,爬虫持久化,
第三个,还有轻松实现分布式,scrapy-redis搞明白,这个是如何实现分布式的,
3,为什么要引入这个scrapy-redis?这是因为有实际的需求,
原生的scrapy,今天启动了,关闭了,明天再启动,昨天爬取的url,会再次爬取,这不是我们想要的,
我们想要的是今天爬过的url,下一次就不再爬取了,这就是增量式爬虫,
而且,如果我们再一个机器爬取,如果我们想要再另外一个机器再开启一个爬虫,原来的scrapy会重复爬取之前的url,这不是我们想要的,
我们想要的是大家同时爬取一个url池,不会重复爬取,可以多个爬虫协同工作,这就是分布式爬虫,
###
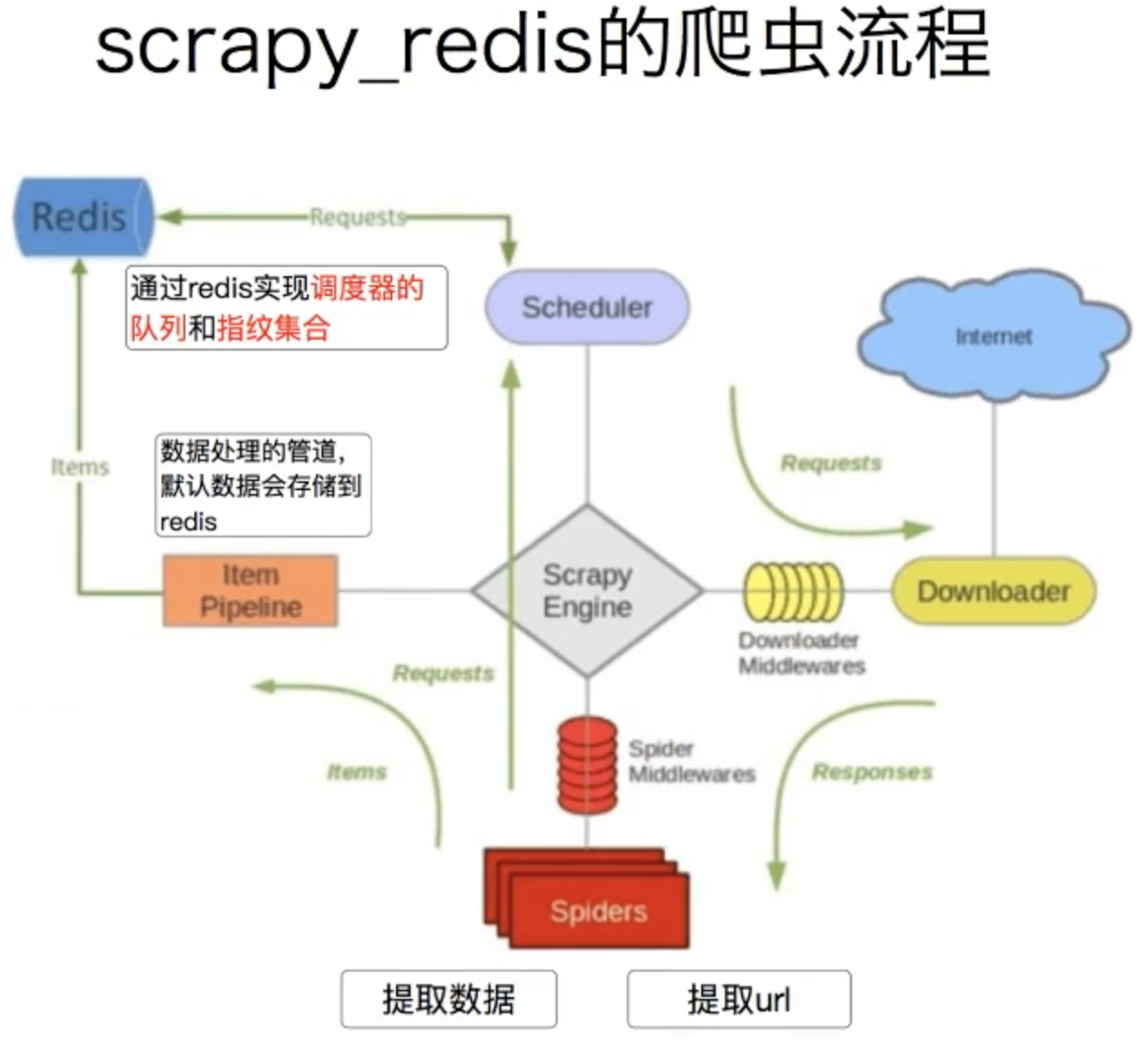
调度器会和redis相连,这是最重要的,这样我们是只有一个url维护的地方,
这个Redis做了两个事情,
1是维护request,这是待爬取的request,
2是指纹集合,这是为了保存爬取过的request的指纹,
至于pipeline和redis相连,我们原来的scrapy也可以实现,
也就是实际scrapy-redis也帮助我们把数据保存到了redis,但是实际这个我们可以注释掉,不使用这个功能
关键是前两个事情,
###
使用scrapy-redis的准备工作
1,安装redis数据库,教程网上都有,
2,启动redis服务端,redis-server
3,启动redis客户端,redis-cli,验证是否能登陆redis,
4,安装scrapy-redis,pip install scrapy-redis
####
如何使用scrapy-redis
主要是在配置当中添加scrapy-redis的配置,
###################################################### ##############下面是Scrapy-Redis相关配置################ ###################################################### # 指定Redis的主机名和端口 REDIS_HOST = 'localhost' REDIS_PORT = 6379 # 调度器启用Redis存储Requests队列 SCHEDULER = "scrapy_redis.scheduler.Scheduler" # 确保所有的爬虫实例使用Redis进行重复过滤 DUPEFILTER_CLASS = "scrapy_redis.dupefilter.RFPDupeFilter" # 将Requests队列持久化到Redis,可支持暂停或重启爬虫 SCHEDULER_PERSIST = True # Requests的调度策略,默认优先级队列 SCHEDULER_QUEUE_CLASS = 'scrapy_redis.queue.PriorityQueue' # 将爬取到的items保存到Redis 以便进行后续处理 # Configure item pipelines # See https://docs.scrapy.org/en/latest/topics/item-pipeline.html ITEM_PIPELINES = { 'scrapy_demo1.pipelines.ScrapyDemo1Pipeline': 300, 'scrapy_demo1.pipelines.MyspiderPipeline1': 301, 'scrapy_redis.pipelines.RedisPipeline': 302 }
#####
运行爬虫,观察生成的redis数据
看redis的变化
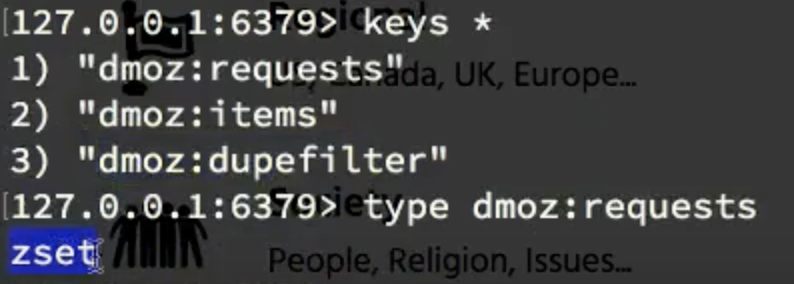
第一个request,是保存的待爬取request对象,这是一个有序集合类型,zset
redis不支持保存对象,他是怎么存的,他是对request做了序列化操作,然后拿出来之后又反序列化,
第二个,items,这是一个列表,list,
这是抓取到的内容,这个就是保存的定义的内容,
这个地方我们并没有保存到redis,为什么在这里,是通过setting里面的redispipeline保存的,
关闭redispipeline,可以发现item已经不变化了,说明刚刚我们关闭的Redis就是做了保存到redis的事情,
这个pipeline,我们可以注释掉,不使用redis保存, 我们可以保存到数据库,或者其他地方,
第三个dupefilter,这个是保存的已经抓取过的request的指纹,这是一个集合,set
####
scrapy-redis源码分析
scrapy-redis是怎么实现的这个request的存储,以及request的指纹去重的呢?
看看源码
先看redispipeline,
这个类做的事情,就是把数据保存到了redis,这个不难,自己也能写,

###
然后看dupefilter类
这个就是把已经爬取的request做了指纹处理保存,下次来的时候就去看看有没有这个request指纹,如果有就说明爬过了就不爬了,从而实现去重,
所以怎么生成指纹的,就是使用的hashlib.sha1来生成的

###
然后看看调度器scheduler,
会读取setting里面的一个是否持久化的字段,如果是TRUE,就存储,如果不存,关闭的时候,就全都清除
SCHEDULER_PERSIST = True
还有就是如何入队的,
1,如果指纹已经存在了,肯定不会是入队的,
2,如果是一个全新的url,肯定是入队的,
3,dont_filter,是ture,就是说不管有没有请求过,统统都去请求,这个也是入队,什么时候用这个,就是那些页面会变化的会更新的,就是每次都去爬

####
用scrapy-redis实现分布式爬虫,redisspider
实战京东爬虫

####
思路和爬取苏宁图书一样的,
就是先获取大分类,然后获取小分类,
然后获取列表页,然后翻页
然后获取详情页,
整个的过程,需要对scrapy的使用非常的熟练,还要对xpath,re,等模块的使用非常的熟悉,
这个就要多写,多练,
###
用scrapy-redis实现分布式爬虫,redisspider
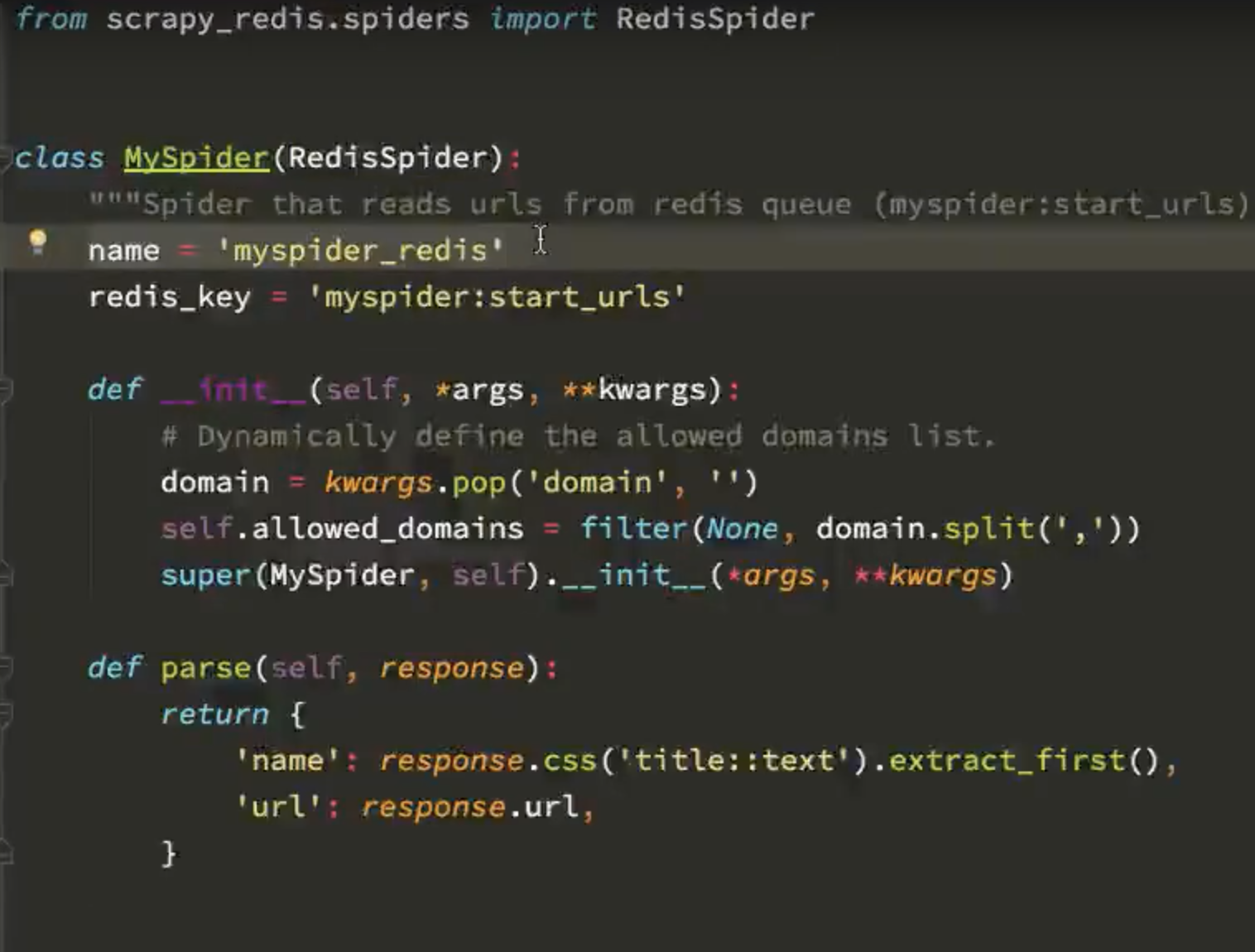
第一个不同,父类不同了,使用了redisspider
第二个不同,使用了一个rediskey,来存储待爬取的redis对象,没有starturl地址了, 因为这个代码要放到不同的电脑执行的,如果写在代码里,每个机器运行,都会抓取这个url就重复了,
注意,这个starturl需要单独在redis里面添加一下,
所有的机器,都从redis这个队列里面取值,取得时候使用的pop这样的方法,取到就删除,
也就是一个url只会有一个机器能获取到,
其他的都一样,
这样就可以实现分布式爬虫了,
一个电脑可以发送100个请求,10个电脑就可以发送1000个请求了,这是因为使用了redisspider, 所以实现了分布式爬虫,
另外多个电脑实现这个分布式爬虫,一定要连接一个共同的redis,所有的电脑只从这一个requests的取,这样就是一个公共的url库,然后有很多的小爬虫,
###
案例,当当网爬虫,
# -*- coding: utf-8 -*- import scrapy from scrapy_redis.spiders import RedisSpider from copy import deepcopy import urllib class DangdangSpider(RedisSpider): name = 'dangdang' allowed_domains = ['dangdang.com'] # start_urls = ['http://book.dangdang.com/']# 不在写start_url地址,如果写了就会重复每台电脑就会重复爬取该地址 # 在redis中 先存start_url 地址 :lpush dangdang http://book.dangdang.com/ redis_key = "dangdang" def parse(self, response): #大分类分组 div_list = response.xpath("//div[@class='con flq_body']/div") for div in div_list: item = {} item["b_cate"] = div.xpath("./dl/dt//text()").extract() item["b_cate"] = [i.strip() for i in item["b_cate"] if len(i.strip())>0] #中间分类分组 dl_list = div.xpath("./div//dl[@class='inner_dl']") for dl in dl_list: item["m_cate"] = dl.xpath("./dt//text()").extract() item["m_cate"] = [i.strip() for i in item["m_cate"] if len(i.strip())>0][0] #小分类分组 a_list = dl.xpath("./dd/a") for a in a_list: item["s_href"] = a.xpath("./@href").extract_first() item["s_cate"] = a.xpath("./text()").extract_first() if item["s_href"] is not None: yield scrapy.Request( item["s_href"], callback=self.parse_book_list, meta = {"item":deepcopy(item)} ) def parse_book_list(self,response): item = response.meta["item"] li_list = response.xpath("//ul[@class='bigimg']/li") for li in li_list: item["book_img"] = li.xpath("./a[@class='pic']/img/@src").extract_first() if item["book_img"] == "images/model/guan/url_none.png": item["book_img"] = li.xpath("./a[@class='pic']/img/@data-original").extract_first() item["book_name"] = li.xpath("./p[@class='name']/a/@title").extract_first() item["book_desc"] = li.xpath("./p[@class='detail']/text()").extract_first() item["book_price"] = li.xpath(".//span[@class='search_now_price']/text()").extract_first() item["book_author"] = li.xpath("./p[@class='search_book_author']/span[1]/a/text()").extract() item["book_publish_date"] = li.xpath("./p[@class='search_book_author']/span[2]/text()").extract_first() item["book_press"] = li.xpath("./p[@class='search_book_author']/span[3]/a/text()").extract_first() print(item) #下一页 next_url = response.xpath("//li[@class='next']/a/@href").extract_first() if next_url is not None: next_url = urllib.parse.urljoin(response.url,next_url) yield scrapy.Request( next_url, callback=self.parse_book_list, meta = {"item":item} )
#####
###
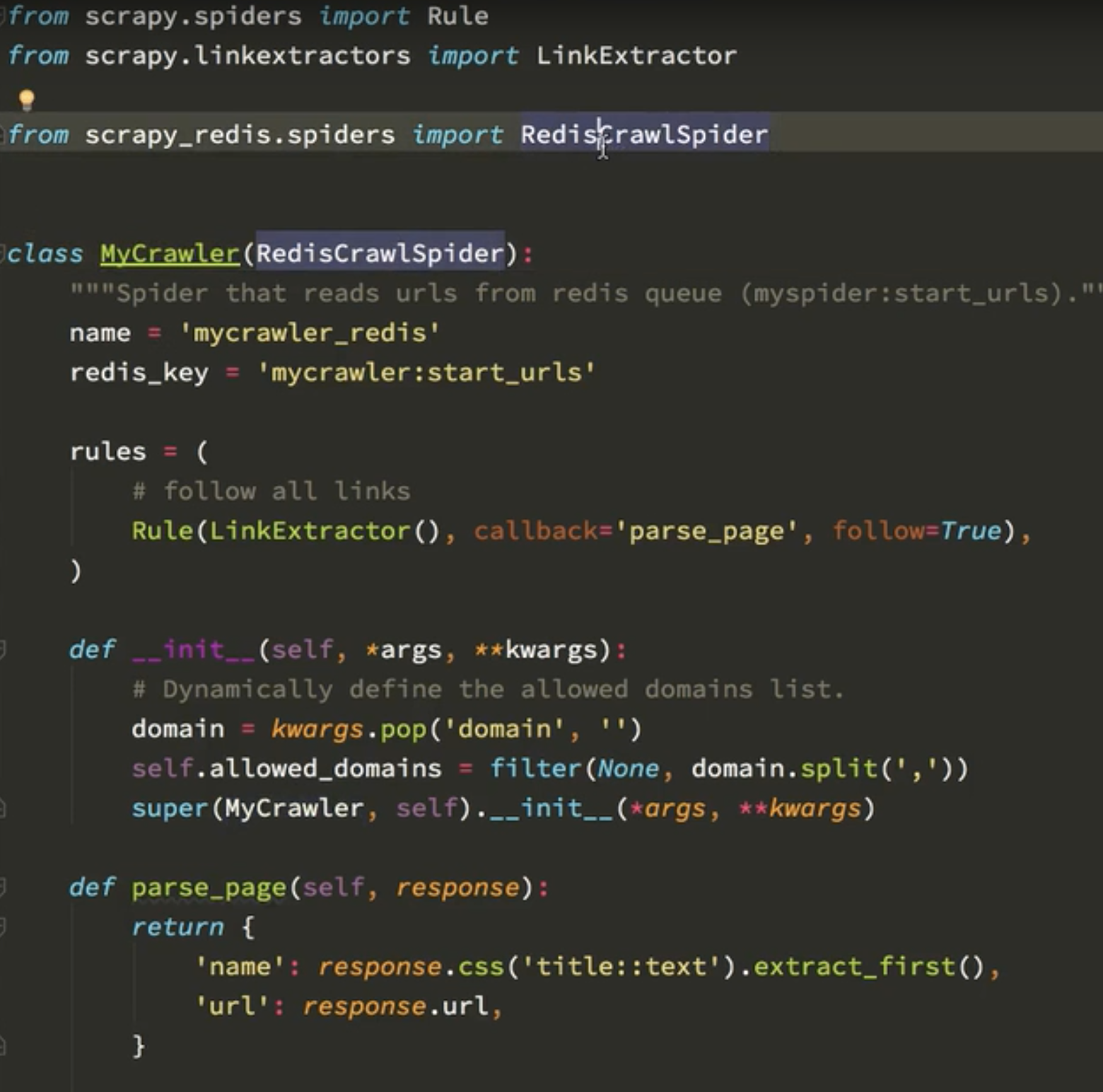
还有一个爬虫rediscrowlspider
###
可以使用rule,里面的xpath提取连接,因为只需要写到ul,一级,就可以把这个下面所有的url都提取出来了 ,
# -*- coding: utf-8 -*- import scrapy from scrapy.linkextractors import LinkExtractor from scrapy.spiders import CrawlSpider, Rule from scrapy_redis.spiders import RedisCrawlSpider import re class AmazonSpider(RedisCrawlSpider): name = 'amazon' allowed_domains = ['amazon.cn'] # start_urls = ['https://www.amazon.cn/%E5%9B%BE%E4%B9%A6/b/ref=sd_allcat_books_l1?ie=UTF8&node=658390051'] redis_key = "amazon" rules = ( #匹配大分类的url地址和小分类的url Rule(LinkExtractor(restrict_xpaths=("//div[@class='categoryRefinementsSection']/ul/li",)), follow=True), #匹配图书的url地址 Rule(LinkExtractor(restrict_xpaths=("//div[@id='mainResults']/ul/li//h2/..",)),callback="parse_book_detail"), #列表页翻页 Rule(LinkExtractor(restrict_xpaths=("//div[@id='pagn']",)),follow=True), ) def parse_book_detail(self,response): # with open(response.url.split("/")[-1]+".html","w",encoding="utf-8") as f: # f.write(response.body.decode()) item = {} item["book_title"] = response.xpath("//span[@id='productTitle']/text()").extract_first() item["book_publish_date"] = response.xpath("//h1[@id='title']/span[last()]/text()").extract_first() item["book_author"] = response.xpath("//div[@id='byline']/span/a/text()").extract() # item["book_img"] = response.xpath("//div[@id='img-canvas']/img/@src").extract_first() item["book_price"] = response.xpath("//div[@id='soldByThirdParty']/span[2]/text()").extract_first() item["book_cate"] = response.xpath("//div[@id='wayfinding-breadcrumbs_feature_div']/ul/li[not(@class)]/span/a/text()").extract() item["book_cate"] = [i.strip() for i in item["book_cate"]] item["book_url"] = response.url item["book_press"] = response.xpath("//b[text()='出版社:']/../text()").extract_first() # item["book_desc"] = re.findall(r'<noscript>.*?<div>(.*?)</div>.*?</noscript>',response.body.decode(),re.S) # item["book_desc"] = response.xpath("//noscript/div/text()").extract() # item["book_desc"] = [i.strip() for i in item["book_desc"] if len(i.strip())>0 and i!='海报:'] # item["book_desc"] = item["book_desc"][0].split("<br>",1)[0] if len(item["book_desc"])>0 else None print(item)
###
可以使用pycharm的一个工具,发布代码到服务器,
可以使用crontab,定时执行爬虫,
####
scrapy-redis优缺点
Slaver端从Master端拿任务(Request/url/ID)进行数据抓取,在抓取数据的同时也生成新任务,并将任务抛给Master。Master端只有一个Redis数据库,负责对Slaver提交的任务进行去重、加入待爬队列。
优点:scrapy-redis默认使用的就是这种策略,我们实现起来很简单,因为任务调度等工作scrapy-redis都已经帮我们做好了,我们只需要继承RedisSpider、指定redis_key就行了。
缺点:scrapy-redis调度的任务是Request对象,里面信息量比较大(不仅包含url,还有callback函数、headers等信息),导致的结果就是会降低爬虫速度、而且会占用Redis大量的存储空间。当然我们可以重写方法实现调度url。
####