###
安卓逆向,写代码的难度是比较小的,
难度大,是因为要分析原理,比如frida脱壳,这个其实代码很简单,十几行代码就好了,但是要懂得原理才可以,
###
之前使用的工具脱壳的
就是Xposed的一个工具组件,
现在我们使用frida 来开发脱壳,
毕竟作为开发,还是需要了解这个的,
###
脱壳要懂得原理,这个难度比较大,
真正写代码是非常简单的,几十行代码就搞定了,
###
使用frida脱壳的原理,
还是壳加载源app到内存之后,从内存中取出这个源app的代码,然后使用frida把这个保存到本地,就实现了脱壳了
###

###
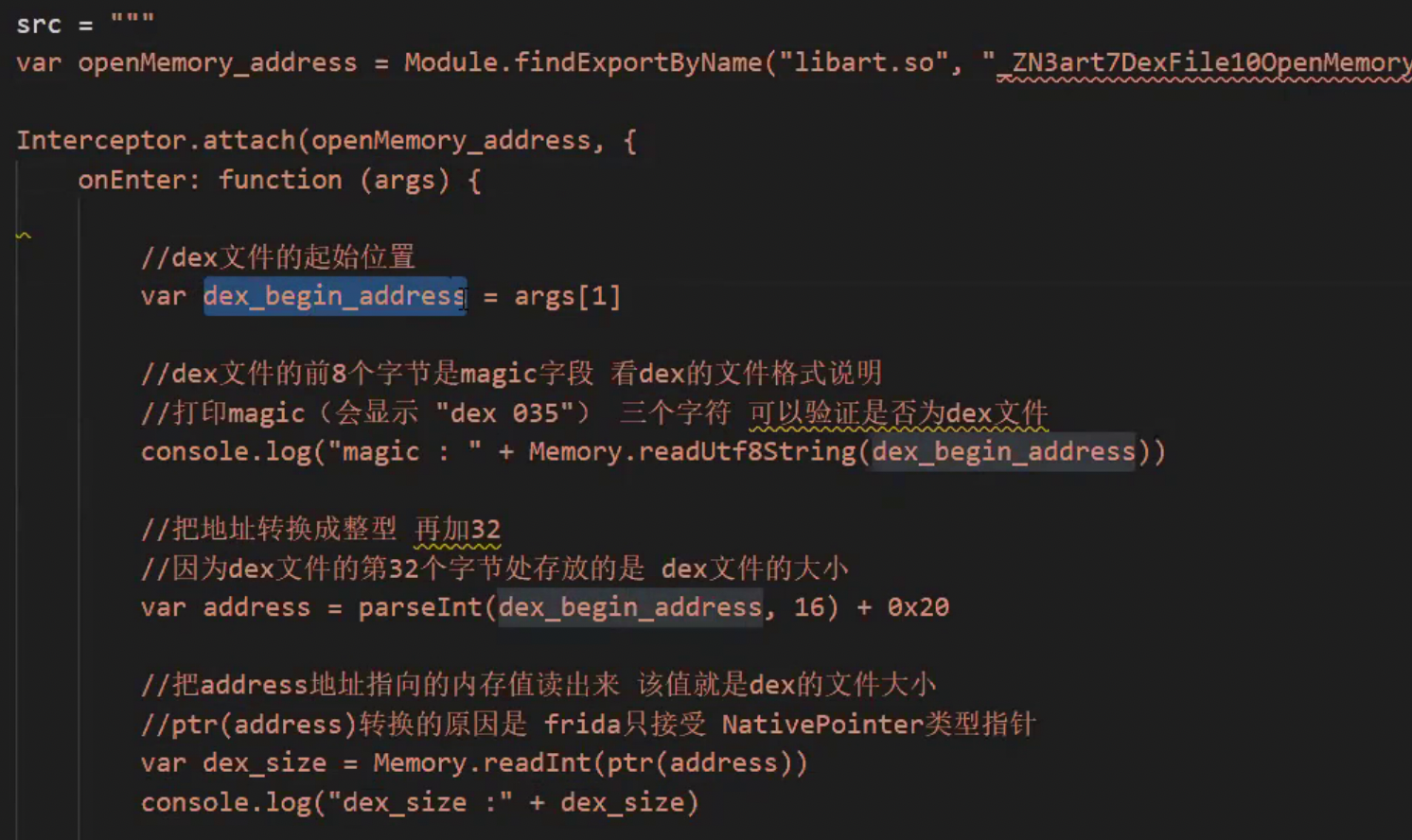
本质还是需要需要懂这个dex文件的格式,里面做了什么,是怎么保存的,
里面有一个重要的属性,就是dex的数据具体有多大字节,这就是文件的长度,所以我们操作内存的依据就是这个,

我们读取内存里面的dex数据的时候,就是从32个字节往后,一直加dex的文件大小,这就是dex文件我们要读取的起始位置,
###
内存的概念,
因为我们是从内存取值,所以还是需要知道这个内存怎么回事
比如一个4G的内存,可能是分成了1万份,每一份都是有一个id的,
###
怎么确定hook的点,
我们要知道dex加载的时候经过了很多的流程,我们怎么知道在哪一个流程去取内存呢?
第一个方法,就是你对安卓原理很通,熟悉代码逻辑,但是这个很难,真正做安卓app开发的,也未必搞得清楚,因为他们只是调用相关的api,做应用层的开发,对底层可能也不太清楚
第二个方法,我们通过查资料,了解dex加载的流程,我们就是这种人,
可能dex加载要经过10个方法,我们每一个做hook,看哪一个方法之后可以把内存dump出来,
经过测试是这个openmemory的方法之后,会把dex加载到内存,所以我们hook这个函数,

这个方法再libart.so这个里面
我们可以使用ida工具,打开这个库,查看这个方法的导出方法名,然后就知道了我们要hook这个方法,
###
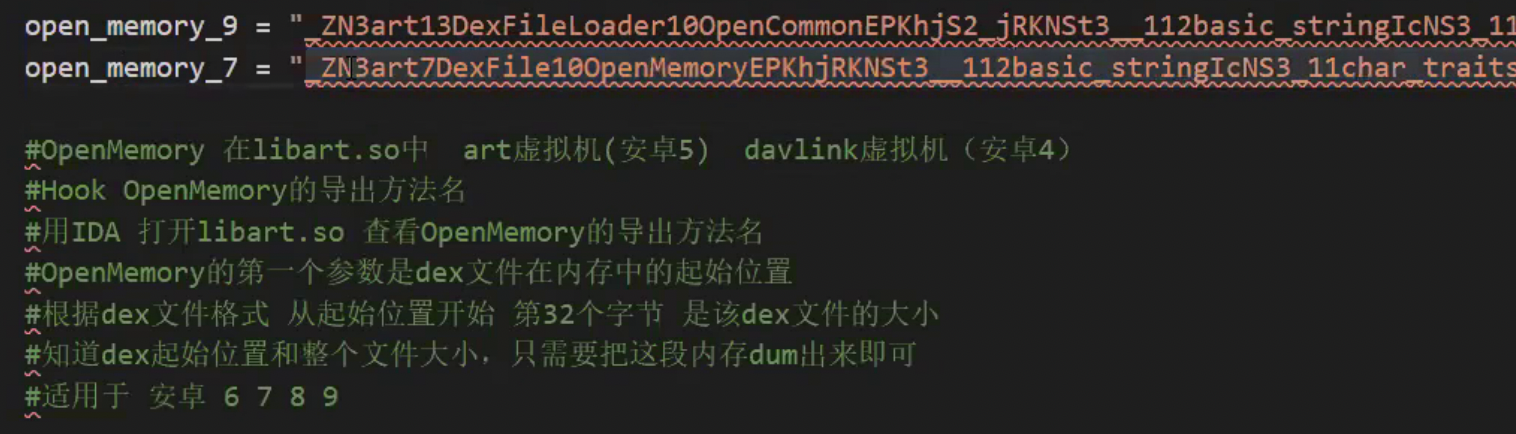
一个9,一个7是什么,是因为在安卓9和安卓7,是不同的名字,
###
####

###
难点,是找到hook的点,
###
你能开发出来这个脱壳程序,在爬虫领域就是比较牛逼的了,
但是这个没有这么容易,大部分的app不是这么简单的,还做了混淆等其他的限制,没有办法只是使用frida就能脱壳,
####