HDFS2.0之HA
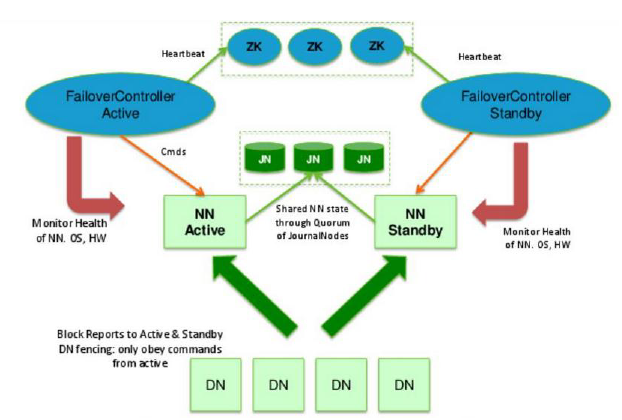
主备NameNode:
1、主NameNode对外提供服务,备NameNode同步主NameNode元数据,以待切换;
2、主NameNode的信息发生变化后,会将信息写到共享数据存储系统中让备NameNode合并到自己的内存中;
3、所有DataNode同时向两个NameNode发送心跳信息(块信息);
两种切换方式:
1、手动切换:通过命令实现主备之间的切换,可以用于HDFS升级等场合;
2、自动切换:基于Zookeeper实现;
Zookeeper Failover Controller:向Zookeeper注册NameNode并监控NameNode健康状态,当NM挂掉后,ZKFC为NameNode竞争锁,获得锁的NameNode变成active;
多种共享数据存储系统可供选择
1、NFS
2、多个Journal Node构成集群(推荐)
基本原理,数据同时写入所有的JN,多数写入成功,则认为写成功;
一般配置奇数个JN,JN越多,容错性越好;比如有3个JN,只要两个写成功,则数据写成功,最多允许一个JN挂掉;
3、Bookeeper
相对于hadoop1.x中多了备NameNode,JournalNode(存储共享数据),ZKFC&ZK(主备NN切换)
HDFS2.0之Federation
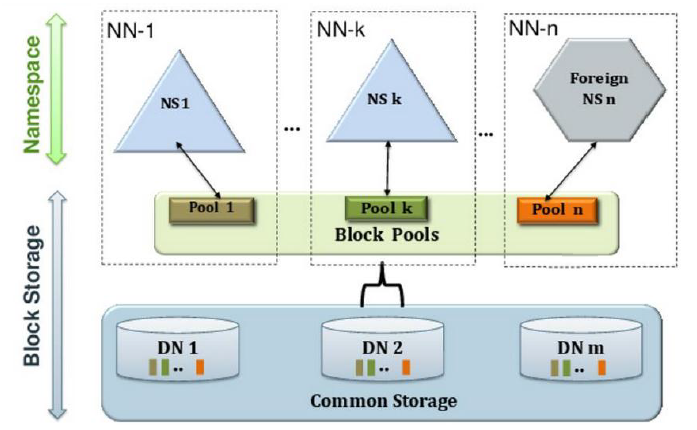
多个NN同时对外提供服务,每个NN分管一部分目录,多个NN共享底层DN存储;
此时每个NN都还是存在单点故障问题的,故还需要给Federation节点配置一个备用NN;
所有整个HADOOP2集群中可能存在的NN有:多个NN以及每个NN对应的备NN
带来的好处:单个NN内存和并发压力减小,NN彼此隔离,互不影响;
常见应用方法:
为不同业务创建不同NN,防止相互影响;(一个NN给开发用,一个NN测试用)
为不同需求创建不同NN,比如测试用的NN,生产用的NN;
HDFS2.0之其他实现机制(与1.0版本基本一致)
1、文件放置策略
文件被切成若干个block,存放在不同节点上;
切分过程对用户透明;
2、文件容错策略
基于副本的容错机制;
流水线复制;
3、副本放置策略
一个节点(1个rack)+ 两个节点(另1个rack)
4、......