WAL(Write-Ahead Logging)是数据库系统中保障原子性和持久性的技术,通过使用WAL可以将数据的随机写入变为顺序写入,可以提高数据写入的性能。在hbase中写入数据时,会将数据写入内存同时写wal日志,为防止日志丢失,日志是写在hdfs上的。
默认是每个RegionServer有1个WAL,在HBase1.0开始支持多个WALHBASE-5699,这样可以提高写入的吞吐量。配置参数为hbase.wal.provider=multiwal,支持的值还有defaultProvider和filesystem(这2个是同样的实现)。
WAL的持久化的级别有如下几种:
- SKIP_WAL:不写wal日志,这种可以较大提高写入的性能,但是会存在数据丢失的危险,只有在大批量写入的时候才使用(出错了可以重新运行),其他情况不建议使用。
- ASYNC_WAL:异步写入
- SYNC_WAL:同步写入wal日志文件,保证数据写入了DataNode节点。
- FSYNC_WAL: 目前不支持了,表现是与SYNC_WAL是一致的
- USE_DEFAULT: 如果没有指定持久化级别,则默认为USE_DEFAULT, 这个为使用HBase全局默认级别(SYNC_WAL)
wal写入
先看看wal写入中的几个主要的类
1. WALKey:wal日志的key,包括regionName:日志所属的region
tablename:日志所属的表,writeTime:日志写入时间,clusterIds:cluster的id,在数据复制的时候会用到。
2.WALEdit:在hbase的事务日志中记录一系列的修改的一条事务日志。另外WALEdit实现了Writable接口,可用于序列化处理。
3. FSHLog: WAL的实现类,负责将数据写入文件系统
在每个wal的写入这里使用的是多生产者单消费者的模式,这里使用到了disruptor框架,将WALKey和WALEdit信息封装为FSWALEntry,然后通过RingBufferTruck放入RingBuffer中。接下来看hlog的写入流程,分为以下3步:
- 日志写入缓存:由rpcHandler将日志信息写入缓存ringBuffer.
- 缓存数据写入文件系统:每个FSHLog有一个线程负责将数据写入文件系统(HDFS)
- 数据同步:如果操作的持久化级别为(SYNC_WAL或者USE_DEFAULT 则需进行数据同步处理
下面来详细说明一下各类线程是如何配合来实现这几步操作的,
- rpcHandler线程负责将日志信息(FSWALEntry)写入缓存RingBbuffer,在操作日志写完后,rpcHandler会调用wal的sync方法,进行数据同步,其实际处理为写入一个SyncFuture到RingBuffer,然后blocking一直到syncFuture处理完成。
- wal线程从缓存RingBuffer中取数据,如果为日志(FSWALEntry)就调用Writer将数据写入文件系统,如果为SyncFuture,则由专门的同步线程来进行同步处理。
整体处理流程图如下:
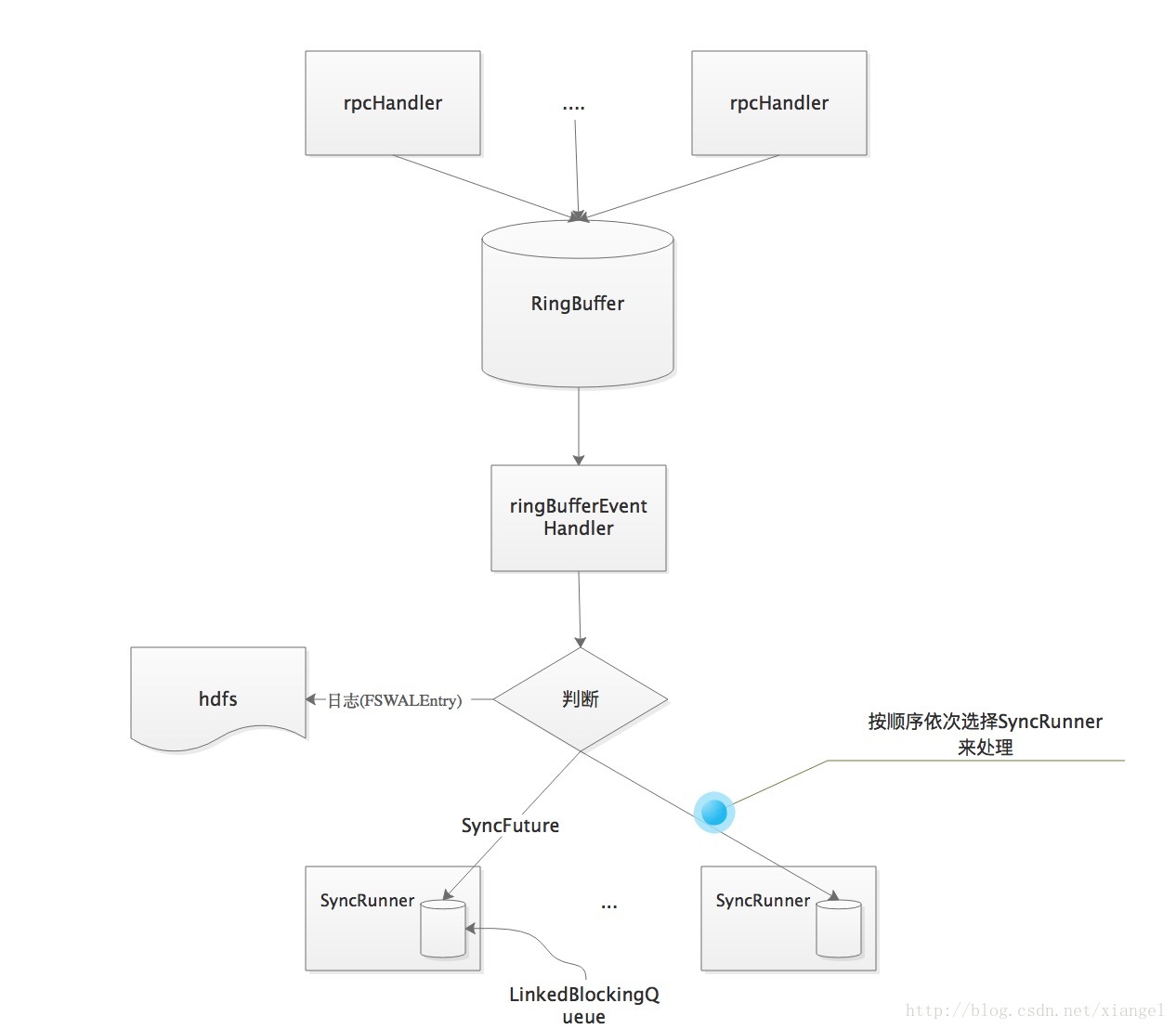
HLog的写入
wal写入文件系统是通过Writer来写入的,其实际类为ProtobufLogWriter,使用的是Protobuf的格式持久化处理。使用Protobuf格式有如下优势:
- 性能较高
- 结构更加紧凑,节省空间
-
方便扩展以及支持其他语言,通过其他语言来解析日志。
写入的日志中是按WALKey和WALEdit来依次存储的(具体内容见前面WALKey和WALEdit类的说明),另外还将WALKey和WALEdit分别进行了压缩处理。
wal同步过程
每个wal中有一个RingBufferEventHandler对象,其中用数组管理着多个SyncRunner线程(由参数hbase.regionserver.hlog.syncer.count配置,默认5)来进行同步处理,每个SyncRunner对象里面有一个LinkedBlockingQueue(syncFutures,大小为参数{hbase.regionserver.handler.count默认值200}*3
另外这里的SyncFuture是每个rpcHandler线程拥有一个,由wal中的private final Map
class RingBufferEventHandler implements EventHandler<RingBufferTruck>, LifecycleAware {
private final SyncRunner [] syncRunners;
private final SyncFuture [] syncFutures;
...
}
private class SyncRunner extends HasThread {
private volatile long sequence;
// Keep around last exception thrown. Clear on successful sync.
private final BlockingQueue<SyncFuture> syncFutures;
...
}这里在处理ringBuffer中的syncFuture时,不是每有一个就提交到syncRunner处理,而是按批来处理的,这里的批分2种情况:
- 从ringBuffer中取到的一批数据(为提高效率,在disruptor框架中是按批从ringBuffer中取数据的,具体的请看disruptor的相关文档),如果这批数据中的syncFuture个数<{hbase.regionserver.handler.count默认值200},则按一批处理
- 如果这一批数据中的syncFuture个数>={hbase.regionserver.handler.count默认值200}个数,则按{hbase.regionserver.handler.count默认值200}分批处理。
如果达到了批大小,就从syncRunner数组中顺序选择下一个SyncRunner,将这批数据插入该SyncRunner的BlockingQueue中。最后由SyncRunner线程进行hdfs文件同步处理。为保证数据的不丢失,rpc请求需要保证wal日志写入成功后才能返回,这里HBase做了一系列的优化处理的操作。
wal滚动
通过wal日志切换,这样可以避免产生单独的过大的wal日志文件,这样可以方便后续的日志清理(可以将过期日志文件直接删除)另外如果需要使用日志进行恢复时,也可以同时解析多个小的日志文件,缩短恢复所需时间。
wal触发切换的场景有如下几种:
- SyncRunner线程在处理日志同步后,如果有异常发生,就会调用requestLogRoll发起日志滚动请求
- SyncRunner线程在处理日志同步后, 检查当前在写的wal的日志大小是否超过配置{hbase.regionserver.hlog.blocksize默认为hdfs目录块大小}*{hbase.regionserver.logroll.multiplier默认0.95},超过后同样调用requestLogRoll发起日志滚动请求
- 每个RegionServer有一个LogRoller线程会定期滚动日志,滚动周期由参数{hbase.regionserver.logroll.period默认值1个小时}控制
这里前面2种场景调用requestLogRoll发起日志滚动请求,最终也是通过LogRoller来执行日志滚动的操作。
wal失效
当memstore中的数据刷新到hdfs后,那对应的wal日志就不需要了,FSHLog中有记录当前memstore中各region对应的最老的sequenceId,如果一个日志中的各个region的操作的最新的sequenceId均小于wal中记录的各个需刷新的region的最老sequenceId,说明该日志文件就不需要了,于是就会将该日志文件从./WALs目录移动到./oldWALs目录。这块是在前面日志滚动完成后调用cleanOldLogs来处理的。
wal删除
由于wal日志还会用于跨集群的同步处理,所以wal日志失效后并不会立即删除,而是移动到oldWALs目录。由HMaster中的LogCleaner这个Chore线程来负责wal日志的删除,在LogCleaner内部通过参数{hbase.master.logcleaner.plugins}以插件的方式来筛选出可以删除的日志文件。目前配置的插件有ReplicationLogCleaner、SnapshotLogCleaner和TimeToLiveLogCleaner
- TimeToLiveLogCleaner: 日志文件最后修改时间在配置参数{hbase.master.logcleaner.ttl默认600秒}之前的可以删除
- ReplicationLogCleaner:如果有跨集群数据同步的需求,通过该Cleaner来保证那些在同步中的日志不被删除
- SnapshotLogCleaner: 被表的snapshot使用到了的wal不被删除
总结
在本篇中对HBase中wal日志的整个周期进行了叙述,能对wal的处理过程有了整体的了解,后续在单独说说WAL日志的恢复的内容。
参考资料:
1. http://hbasefly.com/2016/03/23/hbase_writer/
2. http://hbasefly.com/2016/10/29/hbase-regionserver-recovering/
转:https://blog.csdn.net/xiangel/article/details/54424900