scrapyd 安装 https://cuiqingcai.com/5445.html
发布 到 scrapyd https://cuiqingcai.com/8491.html
pip install scrapyd
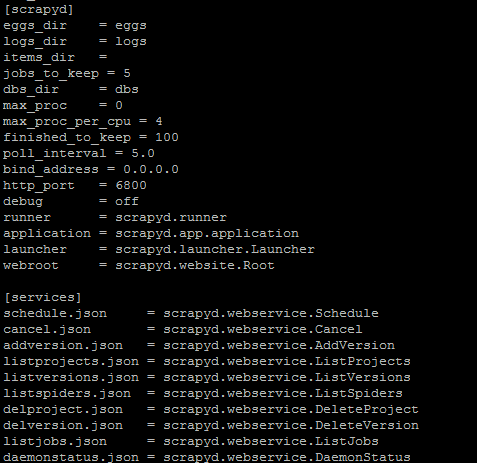
[scrapyd] eggs_dir = eggs logs_dir = logs items_dir = jobs_to_keep = 5 dbs_dir = dbs max_proc = 0 max_proc_per_cpu = 10 finished_to_keep = 100 poll_interval = 5.0 bind_address = 0.0.0.0 http_port = 6800 debug = off runner = scrapyd.runner application = scrapyd.app.application launcher = scrapyd.launcher.Launcher webroot = scrapyd.website.Root [services] schedule.json = scrapyd.webservice.Schedule cancel.json = scrapyd.webservice.Cancel addversion.json = scrapyd.webservice.AddVersion listprojects.json = scrapyd.webservice.ListProjects listversions.json = scrapyd.webservice.ListVersions listspiders.json = scrapyd.webservice.ListSpiders delproject.json = scrapyd.webservice.DeleteProject delversion.json = scrapyd.webservice.DeleteVersion listjobs.json = scrapyd.webservice.ListJobs daemonstatus.json = scrapyd.webservice.DaemonStatus
- max_proc_per_cpu = 10,原本是 4,即 CPU 单核最多运行 4 个 Scrapy 任务,也就是说 1 核的主机最多同时只能运行 4 个 Scrapy 任务,在这里设置上限为 10,也可以自行设置。
bind_address = 0.0.0.0,原本是 127.0.0.1,不能公开访问,在这里修改为 0.0.0.0 即可解除此限制
执行命令启动scrapyd
当我执行完命令后报错,说是找不到命令:

那是因为我系统上python2与3并存,所以找不到,这时应该做软连接:
我的python3路径: /usr/local/python3
制作软连接: ln -s /usr/local/python3/bin/scrapyd /usr/bin/scrapyd
--制作软连接: ln -s /usr/local/python3/bin/scrapy /usr/bin/scrapy
部署到 scrapyd
https://cuiqingcai.com/8491.html
scrapyd-deploy
- 客户端安装部署:
- 打开爬虫项目scrapy.cfg
- 【deploy】去掉url注释(url前# 去掉)
- 【settings】将deploy的url复制一份到setting中
python scrapyd-deploy -l来查看 爬虫 的配置情况
python scrapyd-deploy -L mingzi 查看名为mingzi 的target下可用的爬虫项目
python scrapy-deploy mingzi -p toolspider 将mingzi 中的toolspider项目部署到scrapyd服务端
总结一下:
http://127.0.0.1:6800/listprojects.json
6、启动服务器上某一爬虫(必须是已发布到服务器的爬虫)
http://localhost:6800/schedule.json (post方式,data={"project":myproject,"spider":myspider})
这里可以看到,有删除爬虫的APi,有启动爬虫的API,独独没有发布爬虫的API,为什么呢?
因为发布爬虫需要使用另一个专用工具Scrapyd-client。
https://www.cnblogs.com/wangqinkuan/p/9990652.html
------------恢复内容结束------------