pandas提供了一些用于将表格型数据读取为DataFrame对象的函数,其中read_csv和read_table这两个使用最多。
#导包
import pandas as pd from pandas import DataFrame,Series import numpy as np
一 文件操作
1.1 读取文件
- 文件数据

- 读取代码
df = pd.read_csv('./data-07/type-.txt',sep='-',header=None) # sep:分隔符 # header:None首行不作为列索引
- 效果展示
1.2 写入文件
#写入excel文件 :df.to_excel('name.xlsx') pd.excel('./eee.xls')
二 数据库mysql 操作(pymysql)
2.1 读取数据库
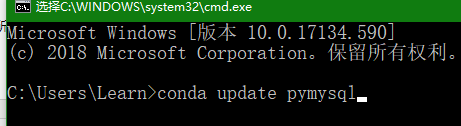
(1)更新pymysql
在cmd中利用conda命令输入:conda update 库名,例如conda update pymysql,并回车,如下图所示
推荐文章:
库更新及jupyter-notebook默认目录更改方法:https://blog.csdn.net/zenghaitao0128/article/details/78241146
(2) 导包
import pandas as pd import pymysql import sys from sqlalchemy import create_engine
(3) 创建conn管道
#连接数据库,获取连接对象 conn = create_engine('mysql+pymysql://root:123@localhost:3306/day02?charset=utf8')
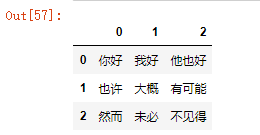
(4) 展示数据库中的数据
sql='select *from student;' #书写mysql语句 #读取库表中的数据值 df=pd.read_sql(sql,conn) df

conn创建参数详解
import pandas as pd from sqlalchemy import create_engine ##将数据写入mysql的数据库,但需要先通过sqlalchemy.create_engine建立连接,且字符编码设置为utf8,否则有些latin字符不能处理 conn = create_engine('mysql+mysqldb://root:password@localhost:3306/databasename?charset=utf8') pd.io.sql.to_sql(thedataframe,'tablename', conn, schema='databasename', if_exists='append')
参数解释: 第一个参数thedataframe是需要导入的pd dataframe, 第二个参数tablename是将导入的数据库中的表名 第三个参数conn是启动数据库的接口,pd 1.9以后的版本,除了sqllite,均需要通过sqlalchemy来设置 第四个参数databasename是将导入的数据库名字 第五个参数if_exists='append'的意思是,如果表tablename存在,则将数据添加到这个表的后面 sqlalchemy.create_engine是数据库引擎 ('mysql+mysqldb://root:password@localhost:3306/databasename?charset=utf8')的解释 mysql是要用的数据库 mysqldb是需要用的接口程序 root是数据库账户 password是数据库密码 localhost是数据库所在服务器的地址,这里是本机 3306是mysql占用的端口 elonuse是数据库的名字 charset=utf8是设置数据库的编码方式,这样可以防止latin字符不识别而报错
原文:https://blog.csdn.net/biboshouyu/article/details/54139641
2.2 DadaFrame数据写入数据库
yconnect = create_engine('mysql+pymysql://root:123@localhost:3306/day02?charset=utf8') #将一个df中的数据值写入存储到 df=DataFrame(data=np.random.randint(0,100,size=(2,3))) df df.to_sql('text',con=yconnect,if_exists='replace')