程序中都是以流的形式进行数据的传输和保存,在java.io包中数据流操作的两大类是字节流和字符流。
1. 字节流
InputStream和OutputStream是所有表示字节流的类的父类,它们都是抽象类,不能实例化。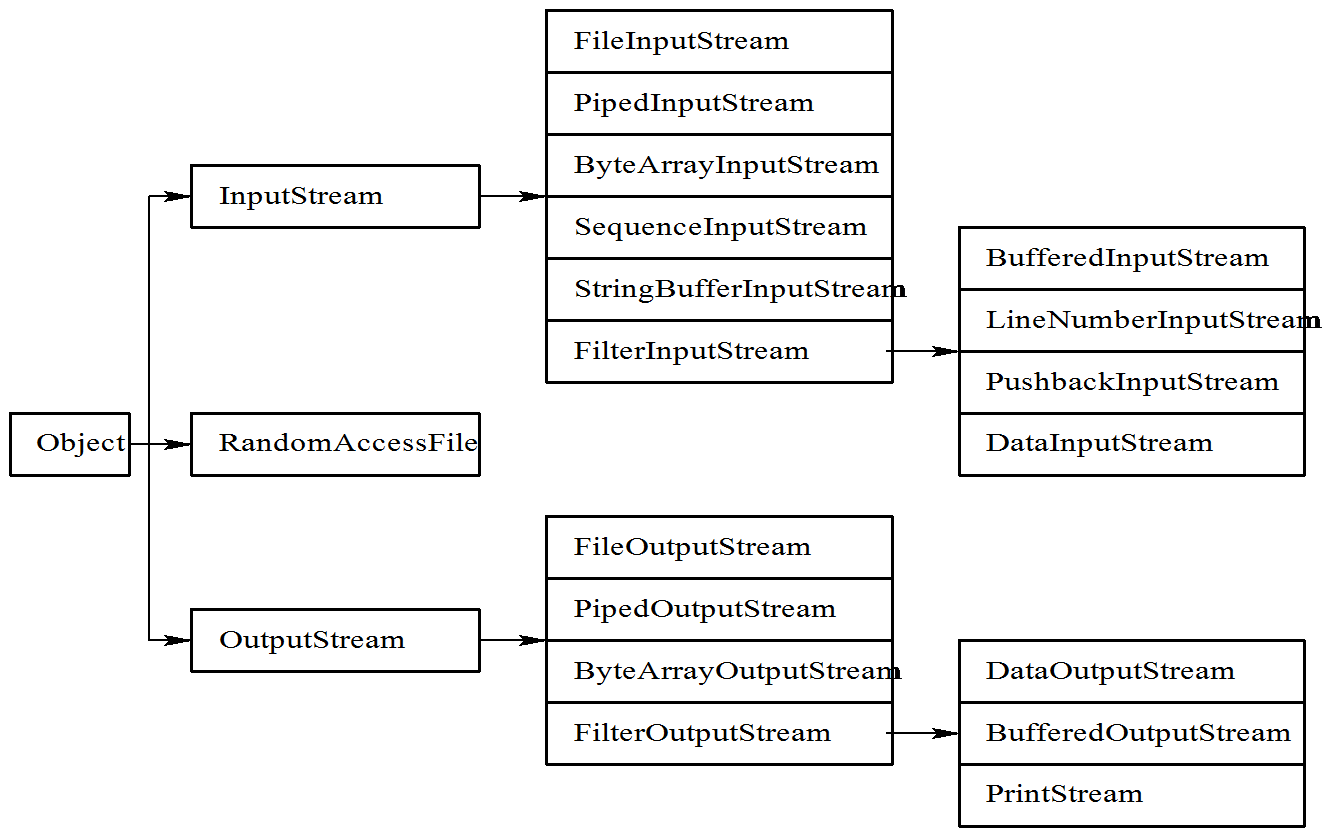
InputStream抽象类方法:
public int read(byte b[]){ return read(b, 0, b.length); } ->从输入流读取数据字节到缓冲区数组b中,并返回实际读取的字节数。
public int read(byte b[], int off, int len) -> 循环调用read(), 从输入流中读取最多 len 个字节。
public abstract int read(); -> 从输入流读取下一个数据字节,返回int类型值。如果已到达流末尾则返回-1。
public long skip(long n)
public int available() throws IOException {return 0;}
public void close() throws IOException {}
public boolean markSupported() {return false;}
public synchronized void mark(int readlimit) {}
public synchronized void reset() throws IOException { throw new IOException("mark/reset not supported"); }
OutputStream抽象类方法:
public void write(byte b[]) {write(b, 0, b.length);} -> 函数体中调用 write(b, 0, b.length);
public void write(byte b[], int off, int len) -> 函数体中循环进行单个字符写操作 write(b[off + i]);
public abstract void write(int b);
public void flush() {} -> 刷新此输出流并强制写出所有缓冲的输出字节。
public void close() {}
public class IOStreamTest { public static final int BUFFERED_SIZE = 1024; public static void main(String[] args) throws IOException { testFileStream(); testBufferedStream(); } public static void testFileStream() throws IOException { FileInputStream fis = new FileInputStream(new File("C://in.txt")); FileOutputStream fos = new FileOutputStream(new File("C://out.txt")); byte[] buffer = new byte[BUFFERED_SIZE]; while(true) { if(fis.available() < BUFFERED_SIZE) { int remain = -1; while((remain = fis.read()) != -1) // 单个字符的读写操作 fos.write(remain); break; } else { fis.read(buffer); // 使用缓冲区进行读写操作 fos.write(buffer); } } fis.close(); fos.close(); } public static void testBufferedStream() throws IOException { BufferedInputStream bis = new BufferedInputStream(new FileInputStream("C:\in.txt")); BufferedOutputStream bos = new BufferedOutputStream(new FileOutputStream("C:" + File.separator +"outb.txt")); byte[] buffer = new byte[BUFFERED_SIZE]; while(bis.read(buffer) != -1) bos.write(buffer); bos.flush(); // 将输入流缓冲区中的数据全部写出 bis.close(); bos.close(); } }
2. 字符流
Java中的字符流处理的最基本单位是Unicode码元(大小2字节),一个Unicode代码单元的范围是0x0000~0xFFFF。在以上范围内的每个数字都与一个字符相对应,Java中的String类型默认就把字符以Unicode规则编码后存储在内存中。然而与存储在内存中不同,存储在磁盘上的数据通常有着各种各样的编码方式。使用不同的编码方式,相同的字符会有不同的二进制表示。实际上字符流是这样工作的:
- 输出字符流:把要写入文件的字符序列(实际上是Unicode码元序列)转为指定编码方式下的字节序列,所以它会使用内存缓冲区来存放转换后得到的字节序列,等待都转换完毕再一同写入磁盘文件中。然后再写入到文件中;
- 输入字符流:把要读取的字节序列按指定编码方式解码为相应字符序列(实际上是Unicode码元序列从)从而可以存在内存中。
public class IOStreamTest { public static final int BUFFERED_SIZE = 1024; public static void main(String[] args) throws IOException { FileReader fr = new FileReader(new File("C://in.txt")); FileWriter fw = new FileWriter(new File("C://out.txt")); char[] buffer = new char[BUFFERED_SIZE]; while(fr.read(buffer) != -1) fw.write(buffer); fr.close(); fw.close(); } }
字节流和字符流的区别:
字符流只能处理文本数据,而字节流既可以操作文本文件,也可以操作非文本文件(二进制文件如图片、视频等); 字节流默认不使用缓冲区;字符流使用缓冲区。