一、工作原理:
按行读取文件内容,对读取的内容按字段分割,形成若干字段,然后输出各字段的值
awk认为文件都是结构化的,也就是说都是由单词和各种空白字符组成的,
这里的“空白字符”包括空格、Tab,以及连续的空格和Tab等。
每个非空白的部分叫做“域”,从左到右依次是第一个域、第二个域,等等。 $1、$2分别用于表示域,$0则表示全部域。
eg:
新建一个文本文件,输入以下内容
john.wang male 20 220000 lucy.zhang female 18 455525 jack.chen male 15 55555566 lily.gong female 15 56556653
下面我们开始打印指定域
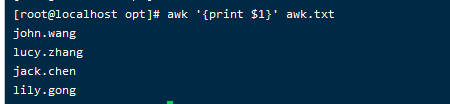
非空白第一个域是姓名部分
二、常用参数变量
2.1 指定打印分隔符
默认情况下awk是以空格为分隔符的,如果想要修改可以通过-F参数进行指定
我们以 . 为分隔符进行分隔
awk -F . '{print $1}' awk.txt
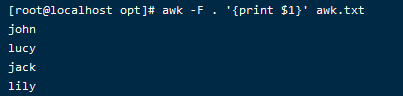
-F 参数后面加分隔符号,不需要用引号引用分隔符号
2.2 内部变量NF
NF变量可以获取文件的列数,注意是每行的列数
我们给最后一行新增一列
lily.gong female 15 56556653 4551
awk '{print NF}' awk.txt
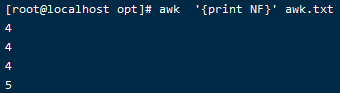
最后一行为5列,其他行都是4列,随着分隔符号的不同,打印出的列数可能是不同的
2.3 打印固定域
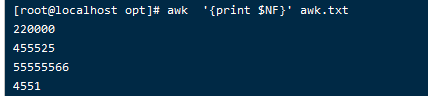
通过内部变量可以获取到每行的列数,如果在NF前加$就是打印最后一行
如果是倒数第一行就是 $(NF-1)
2.4 截取字符串
可以使用substr()函数对指定域截取字符串
substr用法
substr(指定域,开始位置,结束位置)
结束位置可以为空,这样默认输出该域的最后一个字符的内容
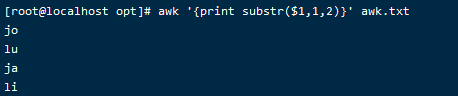
awk '{print substr($1,1,2)}' awk.txt
输出第一域的1到2的位置
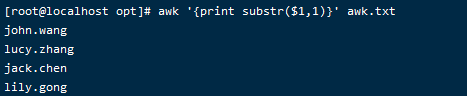
awk '{print substr($1,1)}' awk.txt
输出第一域的1到结尾的部分
2.5 确定字符串的长度
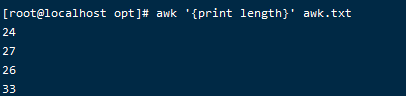
awk '{print length}' awk.txt
可以查看总长度
2.6 使用awk求列和
awk 'BEGIN{total=0} {total+=$3} END{print total}' awk.txt
对第三列的年龄进行求和
执行前先BEGIN 定义变量和初始值
执行变量加第三域
执行结束后END 打印结果