Focal Loss for Dense Object Detection
Intro
这又是一篇与何凯明大神有关的作品,文章主要解决了one-stage网络识别率普遍低于two-stage网络的问题,其指出其根本原因是样本类别不均衡导致,一针见血,通过改变传统的loss(CE)变为focal loss,瞬间提升了one-stage网络的准确率。与此同时,为了测试该loss对网络改进的影响,文章还特地设计了一个网络,retina net,证明了其想法。
Problems
- 为啥one-stage网络的准确率普遍会低于two-stage呢?
文章指出,one-stage网络是在训练阶段,极度不平衡的类别数量导致准确率下降,一张图片里box为目标类别的样本就那么点,而是背景没有目标的样本却远远高于目标样本,这导致分类为背景的样本数目占据样本数目极大部分,因此,这种不平衡导致了模型会把更多的重心放在背景样本的学习上去。常规的做法可以是负样本挖掘,来维持正负样本1:3的比例,这似乎起到了点作用。但是,本文的做法是改变原有的loss,提出新的loss来解决。由于容易被分类的负样本的数量非常庞大,所以这些样本就会左右梯度的方向,继而使得模型更专注于分负样本而非具体的类别。
- 为啥two-stage的准确率不会受到样本类别不均衡的影响呢?
因为two-stage网络一般会经历类似rpn网络,第一个网络已经滤去了大多数背景样本,在第二个网络里负样本的数量大量减少,因此对分类的影响也会减少。但two-stage网络仍然有大量负样本,只是不均衡程度减轻了,所以,这是识别准确率不高的根本原因在于样本类别是否均衡。
Loss

下面给一张图,来说明下作者到底是怎么想的。对于普通的ce loss,由于负样本数量巨大,正样本很少,所以负样本被错分为正样本的的loss会占据loss的主导。那么好的做法就是,尽量减少负样本loss所占的比例,或者增大正样本被错分为负样本的loss所占的比例。于是本文的想法大致就成型了。
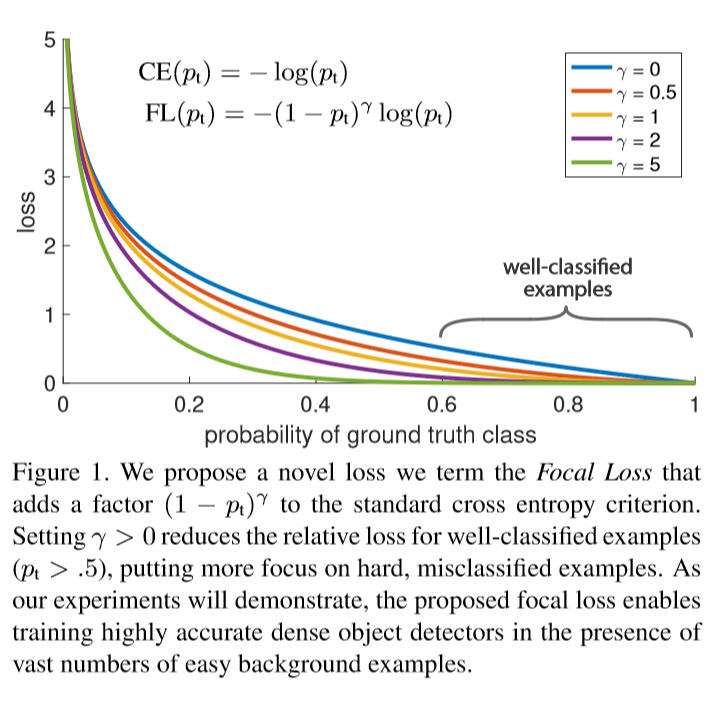
首先要让正负样本所占的比例均衡,没有使用负样本挖掘等手段,本文直接在ce loss前面乘以一个参数α,这样可以方便控制正负样本loss所占的比例,即如果gt为1也就是正样本,那么下式表示的就是正样本被错分为负样本的loss,我们乘以alpha用于调整这个loss的大小,显然应该放大这个loss:
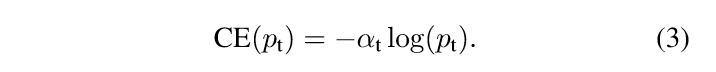
然而,尽管这样做可以做可以起到一些作用,如果分类的结果接近正确,比如正样本以0.9的概率被分为正样本,但是0.9和1之间也是有loss的,这部分loss也会因为前面乘了一个alpha被放大,这其实是我们不希望看到的,因为这一部分已经被分的足够好了,尽管乘了alpha,但预测为0.4的正样本和预测为0.6的正样本的loss相差是不大的,我们希望把这个差距拉开,希望看到的是,被分类的足够好的样本loss不需要太大的alpha权重,而被错分严重的,比如预测概率小于0.5的正样本,我们需要将他的loss放大,错分越严重loss应该被放大的越多,因此可以用下面的指数函数来实现:

由上面的图可以看出,当γ为5的时候,预测概率小于0.5的正样本因为前面乘了个指数的关系可以将loss放到很大,而大于0.5的分类的很好的正样本的loss会乘一个接近0的东西,这就很符合我们的要求。
然后,最终的loss长这个样子:

Trick
类别不平衡问题在训练最开始阶段会导致训练不是很稳定,这是因为我们一般初始化参数的时候都会认为参数其结果服从一个先验分布,一般我们就认为是正太分布,对于分类的最后一层,我们的初始化就是让每个类别的概率都相等,这样做的结果是在反向过程中会使得训练初期训练不稳定,因为负样本非常多,你让各种类别概率相等之后显然是增加了负样本分错的数目,也就是增加了负样本在训练时候的loss,所以好的做法是让最后一层的分布符合正样本相对负样本的分布,这样做能够保证训练初期的稳定性。
RetinaNet Detector
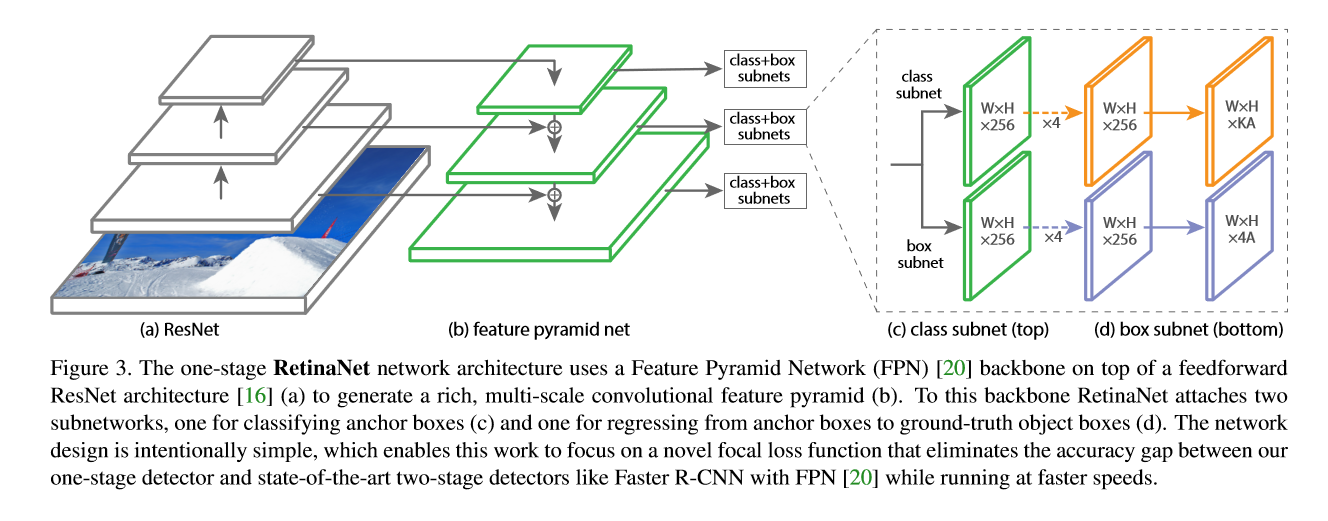
retinanet的网络结构是在FPN的每个特征层后面接两个子网络,分别是classification subnet 和 bbox regression subnet。
前者是先用四次C个3*3的卷积核卷积+relu激活,然后用KA个3*3的卷积核卷积,用sigmoid来激活最后一层,对每个特征层进行类别预测。KA是K种类别A个anchor的预测结果,实验中设置C = 256。
后者也差不多,也是接一个FCN(不含全连接的全卷积),最后预测的是4*A个量,这个与faster rcnn中的类似。
与RPN相比的话,retinanet并没有共享预测类别的网络权重和回归网络的权重,因为作者说他们这样不共享网络权重最终得到的准确率远比调整超参效果要好。
网络结构如图:
OHEM
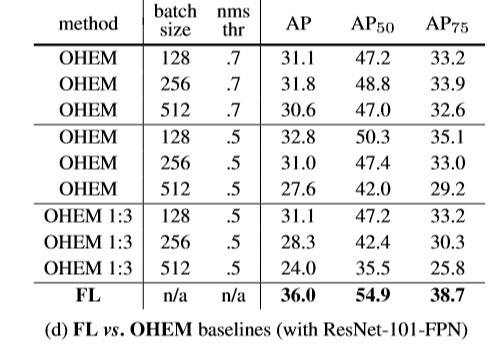
(Online Hard Example Mining)OHEM是来帮助two-stage网路训练的方法,OHEM作用是在NMS之前,先将各个样本的loss排序,只留下loss较大的样本继续NMS,这样做也可以更加专注于错分样本的训练,但是其也有缺点,其直接扔掉了简单样本,显然会导致简单样本的训练出现问题。作者通过实验说明了FL比OHEM更加有效。
Code
'''
@Descripttion: This is Aoru Xue's demo, which is only for reference.
@version:
@Author: Aoru Xue
@Date: 2018-12-26 08:04:34
@LastEditors : Aoru Xue
@LastEditTime : 2018-12-26 08:16:09
'''
import torch
import torch.nn as nn
class FocalLoss(nn.Module):
def __init__(self,gamma = 0.5):
super(FocalLoss, self).__init__()
self.gamma = gamma
def forward(self,x,y):# (b,len) (b,1)
'''
FL = -(1-pt)**gamma * log(pt) if gt == 1
= -pt**gamma * log(1-pt) if gt == 0
利用乘法省去if
'''
pt = torch.sigmoid(x).view(-1,)
losses = -(1 - pt)**self.gamma * torch.log(pt) * y - pt**self.gamma * torch.log(1-pt) * (1-y)
return torch.sum(losses)
if __name__ == '__main__':
focal_loss = FocalLoss()
x = torch.Tensor([[0.1,0.5,0.7,0.8]])
y = torch.LongTensor([[1,0,1,0]])
loss = focal_loss(x,y)
print(loss)