CapsuleNet
前言
找了很多资料,终于把整个流程搞懂了,其实要懂这个运算并不难,难的对我来说是怎么用代码实现,也找了github上的一些代码来看,对我来说都有点冗长,变量分布太远导致我脑袋炸了,所以我就在B站找视频看看有没有代码讲解,算是不负苦心吧,终于把实现部分解决了。
不写论文解读,因为原文实在太难读了,这个老外的英文我基本上每看一句都要取查翻译,很难受,而且网上的教程、解析非常非常之多,所以我留个代码,以后看一下就能想起来了。
Capsule是干什么的
capsule是换了一种神经元的表达方式,原来每个神经元我们是用一个scalar来表示的,现在在capsule中我们中vector来表示一个神经元。这样做的好处是可以多维度描述一个神经元,而在capsue中,我们用vector的模长来表示概率,其他每个维度可以表征神经元的属性。比如某个维度表征特征的朝向,当特征朝向改变时,神经元的模长并没有改变,而是该维度的值改变了,这是一个很好的理解。
这部分网上资料简直太多了,上面说的只是我个人的见解,可以看看别人的版本。
Capsule代码怎么写
网络的结构图还是得贴一张
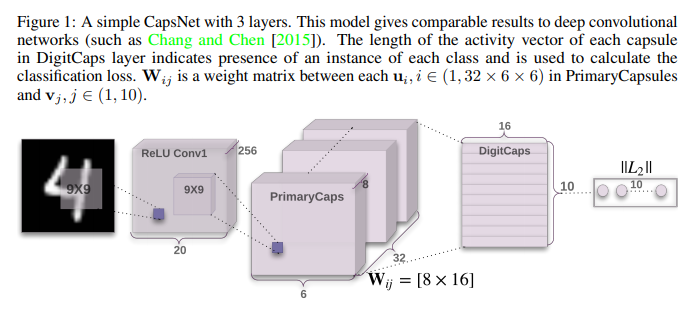
整体网络分三层,第一层卷积层,将(3,28,28)的输入映射到(256,20,20),第二层称为primary_caps,拿32个filter分8次卷积,得到(32,6,6,8)的输出,然后reshape成(1152,1,8)这里就是为了后面vector in vector out做准备了。
这里表达的意思就是有1152个capsule,每个capsule里有1个8维的vector,老有意思了。
然后就是后面digit_caps层了,我们目标vector应该是(10,1,16),输入是(1152,1,8),所以我们在这里思考作者是如何得到这样的映射关系的。

利用动态路由算法,我们成功得到的v。
好,结束。重建的代码我就不写了。
附上总代码:
import torch
import torch.nn as nn
from torchsummary import summary
from torch.autograd import Variable
class CapsuleLayer(nn.Module):
def __init__(self,routing = False):
super(CapsuleLayer,self).__init__()
self.routing = routing
def create_conv(unit_idx):
conv_unit = nn.Conv2d(256,32,kernel_size = 9,stride = 2)
self.add_module("conv_unit_{}".format(unit_idx),conv_unit)
return conv_unit
self.conv_units = [create_conv(i) for i in range(8)]
self.w = Variable(torch.randn(1,1152,10,16))
self.fc = nn.Linear(8,16)
def forward(self,x):
if self.routing:
return self.use_routing(x)
else:
return self.no_routing(x)
@staticmethod
def squash(x):
f = torch.sum(x**2,dim =2,keepdim = True)
return f / (1 + f) / (x / torch.sqrt(f))
def use_routing(self,x):# (-1,8,32*6*6)
x = x.transpose(1,2).view(-1,32*6*6,1,8)
x = self.fc(x)
w = torch.cat([self.w] * x.size(0), dim = 0)
u = w * x # (b,1152,10,8)
b = Variable(torch.zeros(x.size(0),x.size(1),10,1,1))
for iter in range(3):
c = torch.softmax(u,dim = -1)
s = torch.sum(c,dim = 1,keepdim = True)
v = self.squash(s).view(-1,1,10,16,1)
b = b + u.view(x.size(0),1152,10,1,16) @ v.view(x.size(0),1,10,16,1)
return v.view(x.size(0),10,16)
def no_routing(self,x):
u = [self.conv_units[i](x) for i in range(8)]
# every u (-1,32,6,6)
# (-1,8,32,6,6)
u = torch.stack(u,dim =1)
u = u.view(-1,8,32*6*6)
return self.squash(u)
class CapsuleNet(nn.Module):
def __init__(self):
super(CapsuleNet,self).__init__()
self.conv = nn.Sequential(
nn.Conv2d(1,256,kernel_size = 9,stride = 1),
nn.ReLU()
)
self.pri_caps = CapsuleLayer()
self.digit_caps = CapsuleLayer(routing = True)
def forward(self,x):
x = self.conv(x) # (-1,256,20,20)
x = self.pri_caps(x)
x = self.digit_caps(x)
return x
if __name__ == "__main__":
x = torch.randn(2,1,28,28)
net = CapsuleNet()
y = net(x)
print(y.size())