Making Convolutional Networks Shift-Invariant Again
Intro
本文提出解决CNN平移不变性丧失的方法,之前说了CNN中的downsample过程由于不满足采样定理,所以没法确保平移不变性。信号处理里面解决这样的问题是利用增大采样频率或者用抗混叠方法,前者在图像处理里面设置stride 1就可实现,但stride 1已经是极限,本文着重于后者,使用抗混叠使得CNN重新具有平移不变性。
混叠是在采样频率不满足采样定理时出现的一种现象,抗混叠通过抗混叠滤波器消除混叠,即先用低通滤波器处理,然后再去采样,这样可以消除高频信号造成的不满足采样定理的情况。那么在图像处理里,理论上avg pooling就可以减小高频影响,但是有相关研究表明max-pooling在结果上要优于avg pooling(不考虑平移不变性只考虑分类等结果),但是max-pooling是不满足采样定理的,这就很尴尬。
Methods
先解释两个概念
平移不变性:指的是输入平移一定距离,最终的结果不变,分类里面就是分类的概率结果是不变的。
平移同变形:指的是输入平移一定距离,其对应的feature也做同样的平移。
本文主要是针对特征的平移同变性去解决问题,而实际上实现了特征的平移同变形,后面接的是fc层,最后一层的平移不变性是等价于平移同变性的,所以实现了特征的平移同变性就是实现了整个网络输出的平移不变性。例如,vgg网络的最后两层是fc层和softmax,显然fc层的spatial dim只有唯一一个元素(高维向量),所以平移不变性和平移等变性在这一层是等价的。
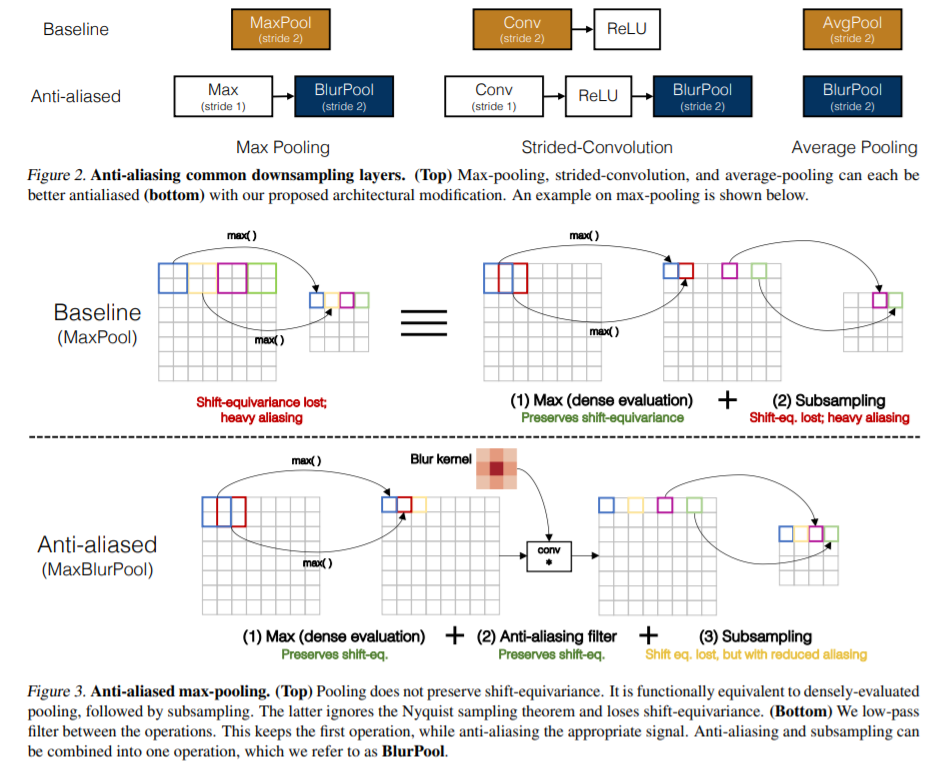
作者认为,max-pooling的过程可以分为两个过程,max操作和采样操作,其中max操作是平移等变的,因为max操作是利用滑动窗口实现的(stride 1),然后进行最大采样,就实现了下采样,而在采样过程中保留了高频部分(采样频率又相对较低),所以会导致不满足采样定理。为了使max-pooling满足采样定理,对采样之前的信号用低通滤波处理,即可实现混叠。低通滤波加上采样操作,作者成为BlurPool。
对于stride 2 conv,同样地,卷积过程其实也分为两个过程,对采样前的信号低通滤波处理即可:conv(stride k)-relu替换为conv(stride 1)-relu-BlurPool(k)。avg pooling同理。
操作如图所示。
Coding
import torch
import torch.nn as nn
import torch.nn.functional as F
import numpy as np
class Downsample(nn.Module):
def __init__(self, pad_type='reflect', filt_size=3, stride=2, channels=None, pad_off=0):
super(Downsample, self).__init__()
self.filt_size = filt_size
self.pad_off = pad_off
self.pad_sizes = [int(1.*(filt_size-1)/2), int(np.ceil(1.*(filt_size-1)/2)), int(1.*(filt_size-1)/2), int(np.ceil(1.*(filt_size-1)/2))]
self.pad_sizes = [pad_size+pad_off for pad_size in self.pad_sizes]
self.stride = stride
self.off = int((self.stride-1)/2.)
self.channels = channels
if(self.filt_size==1):
a = np.array([1.,])
elif(self.filt_size==2):
a = np.array([1., 1.])
elif(self.filt_size==3):
a = np.array([1., 2., 1.])
elif(self.filt_size==4):
a = np.array([1., 3., 3., 1.])
elif(self.filt_size==5):
a = np.array([1., 4., 6., 4., 1.])
elif(self.filt_size==6):
a = np.array([1., 5., 10., 10., 5., 1.])
elif(self.filt_size==7):
a = np.array([1., 6., 15., 20., 15., 6., 1.])
filt = torch.Tensor(a[:,None]*a[None,:])
filt = filt/torch.sum(filt)
self.register_buffer('filt', filt[None,None,:,:].repeat((self.channels,1,1,1)))
self.pad = get_pad_layer(pad_type)(self.pad_sizes)
def forward(self, inp):
if(self.filt_size==1):
if(self.pad_off==0):
return inp[:,:,::self.stride,::self.stride]
else:
return self.pad(inp)[:,:,::self.stride,::self.stride]
else:
return F.conv2d(self.pad(inp), self.filt, stride=self.stride, groups=inp.shape[1])
class AntialiasNet(nn.Module):
def __init__(self,num_classes = 10):
super(AntialiasNet,self).__init__()
self.net = nn.Sequential(
nn.Conv2d(1,32,3,stride = 1),
nn.BatchNorm2d(32),
nn.ReLU(inplace = True),
nn.Conv2d(32,64,3,stride = 1),
nn.BatchNorm2d(64),
nn.ReLU(inplace = True),
Downsample(channels = 64),
nn.Conv2d(64,128,3,stride = 1),
nn.BatchNorm2d(128),
nn.ReLU(inplace = True),
nn.Conv2d(128,256,3,stride = 1),
nn.BatchNorm2d(256),
nn.ReLU(inplace = True),
Downsample(channels = 256),
)
self.avg_pool = nn.AdaptiveAvgPool2d((7,7))
self.classifier = nn.Sequential(
nn.Linear(256 * 7 * 7, 4096),
nn.ReLU(True),
nn.Dropout(),
nn.Linear(4096, 4096),
nn.ReLU(True),
nn.Dropout(),
nn.Linear(4096, num_classes),
)
def forward(self,x):
return self.classifier(self.avg_pool(self.net(x)).view(-1,256*7*7))
def get_pad_layer(pad_type):
if(pad_type in ['refl','reflect']):
PadLayer = nn.ReflectionPad2d
elif(pad_type in ['repl','replicate']):
PadLayer = nn.ReplicationPad2d
elif(pad_type=='zero'):
PadLayer = nn.ZeroPad2d
else:
print('Pad type [%s] not recognized'%pad_type)
return PadLayer
if __name__ == "__main__":
x = torch.randn(3,1,28,28)
net = AntialiasNet()
print(net(x))