Linux 是一种动态系统,能够适应不断变化的计算需求。linux 计算需求的表现是以进程的通用抽象为中心的。进程可以是短期的(从命令行执行的一个命令),也可以是长期的(一种网络服务)。因此,对进程及其调度进行一般管理就显得极为重要。
在用户空间,进程是由进程标识符(PID)表示的。从用户的角度来看,一个 PID 是一个数字值,可惟一标识一个进程。一个 PID 在进程的整个生命期间不会更改,但 PID 可以在进程销毁后被重新使用,所以对它们进行缓存并不见得总是理想的。在用户空间,创建进程可以采用几种方式。可以执行一个程序(这会导致新进程的创建),也可以在程序内,调用一个fork或exec系统调用。fork调用会导致创建一个子进程,而exec调用则会用新程序代替当前进程上下文。这里将对这几种方法进行讨论以便您能很好地理解它们的工作原理。
这里将按照下面的顺序展开对进程的介绍,首先展示进程的内核表示以及它们是如何在内核内被管理的,然后来看看进程创建和调度的各种方式(在一个或多个处理器上),最后介绍进程的销毁。内核的版本为2.6.32.45。
1. 进程描述符
在 Linux 内核内,进程是由相当大的一个称为 task_struct 的结构表示的。此结构包含所有表示此进程所必需的数据,此外,还包含了大量的其他数据用来统计(accounting)和维护与其他进程的关系(如父和子)。task_struct 位于 ./linux/include/linux/sched.h(注意./linux/指向内核源代码树)。下面是task_struct结构:
在task_struct结构中,可以看到几个预料之中的项,比如执行的状态、堆栈、一组标志、父进程、执行的线程(可以有很多)以及开放文件。state 变量是一些表明任务状态的比特位。最常见的状态有:TASK_RUNNING 表示进程正在运行,或是排在运行队列中正要运行;TASK_INTERRUPTIBLE 表示进程正在休眠、TASK_UNINTERRUPTIBLE表示进程正在休眠但不能叫醒;TASK_STOPPED 表示进程停止等等。这些标志的完整列表可以在 ./linux/include/linux/sched.h 内找到。
flags 定义了很多指示符,表明进程是否正在被创建(PF_STARTING)或退出(PF_EXITING),或是进程当前是否在分配内存(PF_MEMALLOC)。可执行程序的名称(不包含路径)占用 comm(命令)字段。每个进程都会被赋予优先级(称为 static_prio),但进程的实际优先级是基于加载以及其他几个因素动态决定的。优先级值越低,实际的优先级越高。tasks字段提供了链接列表的能力。它包含一个 prev 指针(指向前一个任务)和一个 next 指针(指向下一个任务)。
进程的地址空间由mm 和 active_mm 字段表示。mm代表的是进程的内存描述符,而 active_mm 则是前一个进程的内存描述符(为改进上下文切换时间的一种优化)。thread_struct thread结构则用来标识进程的存储状态,此元素依赖于Linux在其上运行的特定架构。例如对于x86架构,在./linux/arch/x86/include/asm/processor.h的thread_struct结构中可以找到该进程自执行上下文切换后的存储(硬件注册表、程序计数器等)。代码如下:
1 struct thread_struct { 2 /* Cached TLS descriptors: */ 3 struct desc_struct tls_array[GDT_ENTRY_TLS_ENTRIES]; 4 unsigned long sp0; 5 unsigned long sp; 6 #ifdef CONFIG_X86_32 7 unsigned long sysenter_cs; 8 #else 9 unsigned long usersp; /* Copy from PDA */ 10 unsigned short es; 11 unsigned short ds; 12 unsigned short fsindex; 13 unsigned short gsindex; 14 #endif 15 #ifdef CONFIG_X86_32 16 unsigned long ip; 17 #endif 18 /* … */ 19 #ifdef CONFIG_X86_32 20 /* Virtual 86 mode info */ 21 struct vm86_struct __user *vm86_info; 22 unsigned long screen_bitmap; 23 unsigned long v86flags; 24 unsigned long v86mask; 25 unsigned long saved_sp0; 26 unsigned int saved_fs; 27 unsigned int saved_gs; 28 #endif 29 /* IO permissions: */ 30 unsigned long *io_bitmap_ptr; 31 unsigned long iopl; 32 /* Max allowed port in the bitmap, in bytes: */ 33 unsigned io_bitmap_max; 34 /* MSR_IA32_DEBUGCTLMSR value to switch in if TIF_DEBUGCTLMSR is set. */ 35 unsigned long debugctlmsr; 36 /* Debug Store context; see asm/ds.h */ 37 struct ds_context *ds_ctx; 38 };
2. 进程管理
在很多情况下,进程都是动态创建并由一个动态分配的 task_struct 表示。一个例外是init 进程本身,它总是存在并由一个静态分配的task_struct表示,参看./linux/arch/x86/kernel/init_task.c,代码如下:
static struct signal_struct init_signals = INIT_SIGNALS(init_signals); static struct sighand_struct init_sighand = INIT_SIGHAND(init_sighand); /* * 初始化线程结构 */ union thread_union init_thread_union __init_task_data = { INIT_THREAD_INFO(init_task) }; /* * 初始化init进程的结构。所有其他进程的结构将由fork.c中的slabs来分配 */ struct task_struct init_task = INIT_TASK(init_task); EXPORT_SYMBOL(init_task); /* * per-CPU TSS segments. */ DEFINE_PER_CPU_SHARED_ALIGNED(struct tss_struct, init_tss) = INIT_TSS;
注意进程虽然都是动态分配的,但还是需要考虑最大进程数。在内核内最大进程数是由一个称为max_threads的符号表示的,它可以在 ./linux/kernel/fork.c 内找到。可以通过/proc/sys/kernel/threads-max 的 proc 文件系统从用户空间更改此值。
Linux 内所有进程的分配有两种方式。第一种方式是通过一个哈希表,由PID 值进行哈希计算得到;第二种方式是通过双链循环表。循环表非常适合于对任务列表进行迭代。由于列表是循环的,没有头或尾;但是由于 init_task 总是存在,所以可以将其用作继续向前迭代的一个锚点。让我们来看一个遍历当前任务集的例子。任务列表无法从用户空间访问,但该问题很容易解决,方法是以模块形式向内核内插入代码。下面给出一个很简单的程序,它会迭代任务列表并会提供有关每个任务的少量信息(name、pid和 parent 名)。注意,在这里,此模块使用 printk 来发出结果。要查看具体的结果,可以通过 cat 实用工具(或实时的 tail -f/var/log/messages)查看 /var/log/messages 文件。next_task函数是 sched.h 内的一个宏,它简化了任务列表的迭代(返回下一个任务的 task_struct 引用)。如下:
#define next_task(p) list_entry_rcu((p)->tasks.next, struct task_struct, tasks) // 查询任务列表信息的简单内核模块: #include <linux/kernel.h> #include <linux/module.h> #include <linux/sched.h> int init_module(void) { /* Set up the anchor point */ struct task_struct *task=&init_task; /* Walk through the task list, until we hit the init_task again */ do { printk(KERN_INFO ”=== %s [%d] parent %s ”, task->comm,task->pid,task->parent->comm); } while((task=next_task(task))!=&init_task); printk(KERN_INFO ”Current task is %s [%d] ”, current->comm,current->pid); return 0; } void cleanup_module(void) { return; }
编译此模块的Makefile文件如下:
obj-m += procsview.o
KDIR := /lib/modules/$(shell uname -r)/build
PWD := $(shell pwd)
default:
$(MAKE) -C $(KDIR) SUBDIRS=$(PWD) modules
在编译后,可以用insmod procsview.ko 插入模块对象,也可以用 rmmod procsview 删除它。插入后,/var/log/messages可显示输出,如下所示。从中可以看到,这里有一个空闲任务(称为 swapper)和init 任务(pid 1)。
Dec 28 23:18:16 ubuntu kernel: [12128.910863]=== swapper [0] parent swapper
Dec 28 23:18:16 ubuntu kernel: [12128.910934]=== init [1] parent swapper
Dec 28 23:18:16 ubuntu kernel: [12128.910945]=== kthreadd [2] parent swapper
Dec 28 23:18:16 ubuntu kernel: [12128.910953]=== migration/0 [3] parent kthreadd
……
Dec 28 23:24:12 ubuntu kernel: [12485.295015]Current task is insmod [6051]
Linux 维护一个称为current的宏,标识当前正在运行的进程(类型是 task_struct)。模块尾部的那行prink用于输出当前进程的运行命令及进程号。注意到当前的任务是 insmod,这是因为 init_module 函数是在insmod 命令执行的上下文运行的。current 符号实际指的是一个函数(get_current),可在一个与 arch 有关的头部中找到它。比如 ./linux/arch/x86/include/asm/current.h,如下:
#include <linux/compiler.h> #include <asm/percpu.h> #ifndef __ASSEMBLY__ struct task_struct; DECLARE_PER_CPU(struct task_struct *, current_task); static __always_inline struct task_struct *get_current(void) { return percpu_read_stable(current_task); } #define current get_current() #endif /* __ASSEMBLY__ */ #endif /* _ASM_X86_CURRENT_H */
3. 进程创建
用户空间内可以通过执行一个程序、或者在程序内调用fork(或exec)系统调用来创建进程,fork调用会导致创建一个子进程,而exec调用则会用新程序代替当前进程上下文。一个新进程的诞生还可以分别通过vfork()和clone()。fork、vfork和clone三个用户态函数均由libc库提供,它们分别会调用Linux内核提供的同名系统调用fork,vfork和clone。下面以fork系统调用为例来介绍。
传统的创建一个新进程的方式是子进程拷贝父进程所有资源,这无疑使得进程的创建效率低,因为子进程需要拷贝父进程的整个地址空间。更糟糕的是,如果子进程创建后又立马去执行exec族函数,那么刚刚才从父进程那里拷贝的地址空间又要被清除以便装入新的进程映像。为了解决这个问题,内核中提供了上述三种不同的系统调用。
(1)内核采用写时复制技术对传统的fork函数进行了下面的优化。即子进程创建后,父子以只读的方式共享父进程的资源(并不包括父进程的页表项)。当子进程需要修改进程地址空间的某一页时,才为子进程复制该页。采用这样的技术可以避免对父进程中某些数据不必要的复制。
(2)使用vfork函数创建的子进程会完全共享父进程的地址空间,甚至是父进程的页表项。父子进程任意一方对任何数据的修改使得另一方都可以感知到。为了使得双方不受这种影响,vfork函数创建了子进程后,父进程便被阻塞直至子进程调用了exec()或exit()。由于现在fork函数引入了写时复制技术,在不考虑复制父进程页表项的情况下,vfork函数几乎不会被使用。
(3)clone函数创建子进程时灵活度比较大,因为它可以通过传递不同的clone标志参数来选择性的复制父进程的资源。
大部分系统调用对应的例程都被命名为 sys_* 并提供某些初始功能以实现调用(例如错误检查或用户空间的行为),实际的工作常常会委派给另外一个名为 do_* 的函数。
在./linux/include/asm-generic/unistd.h中记录了所有的系统调用号及名称。注意fork实现与体系结构相关,对32位的x86系统会使用./linux/arch/x86/include/asm/unistd_32.h中的定义,fork系统调用编号为2。fork系统调用在unistd.h中的宏关联如下:
#define __NR_fork 1079 #ifdef CONFIG_MMU __SYSCALL(__NR_fork, sys_fork) #else __SYSCALL(__NR_fork, sys_ni_syscall) #endif
在unistd_32.h中的调用号关联为: #define __NR_fork 2
在很多情况下,用户空间任务和内核任务的底层机制是一致的。系统调用fork、vfork和clone在内核中对应的服务例程分别为sys_fork(),sys_vfork()和sys_clone()。它们最终都会依赖于一个名为do_fork 的函数来创建新进程。例如在创建内核线程时,内核会调用一个名为 kernel_thread 的函数(对32位系统
参见./linux/arch/x86/kernel/process_32.c,注意process.c是包含32/64bit都适用的代码,process_32.c
是特定于32位架构,process_64.c是特定于64位架构),此函数执行某些初始化后会调用 do_fork。创
建用户空间进程的情况与此类似。在用户空间,一个程序会调用fork,通过int $0x80之类的软中断会导致
对名为sys_fork的内核函数的系统调用(参见 ./linux/arch/x86/kernel/process_32.c),如下:
int sys_fork(struct pt_regs *regs) { return do_fork(SIGCHLD, regs->sp, regs, 0, NULL, NULL); }
最终都是直接调用do_fork。进程创建的函数层次结构如下图:

图1 进程创建的函数层次结构
从图中可以看到 do_fork 是进程创建的基础。可以在 ./linux/kernel/fork.c 内找到 do_fork 函数(以及合作函数 copy_process)。
当用户态的进程调用一个系统调用时,CPU切换到内核态并开始执行一个内核函数。在X86体系中,可以通过两种不同的方式进入系统调用:执行int 0×80汇编命令和执行sysenter汇编命令。后者是Intel在PentiumII中引入的指令,内核从2.6版本开始支持这条命令。这里将集中讨论以int0×80汇编命令和执行sysenter汇编命令。后者是Intel在PentiumII中引入的指令,内核从2.6版本开始支持这条命令。这里将集中讨论以int0×80方式进入系统调用的过程。
通过int 0×80方式调用系统调用实际上是用户进程产生一个中断向量号为0×80的软中断。当用户态fork()调用发生时,用户态进程会保存调用号以及参数,然后发出int0×80方式调用系统调用实际上是用户进程产生一个中断向量号为0×80的软中断。当用户态fork()调用发生时,用户态进程会保存调用号以及参数,然后发出int0×80指令,陷入0x80中断。CPU将从用户态切换到内核态并开始执行system_call()。这个函数是通过汇编命令来实现的,它是0×80号软中断对应的中断处理程序。对于所有系统调用来说,它们都必须先进入system_call(),也就是所谓的系统调用处理程序。再通过系统调用号跳转到具体的系统调用服务例程处。32位x86系统的系统调用处理程序在./linux/arch/x86/kernel/entry_32.S中,代码如下:
.macro SAVE_ALL cld PUSH_GS pushl %fs CFI_ADJUST_CFA_OFFSET 4 /*CFI_REL_OFFSET fs, 0;*/ pushl %es CFI_ADJUST_CFA_OFFSET 4 /*CFI_REL_OFFSET es, 0;*/ pushl %ds CFI_ADJUST_CFA_OFFSET 4 /*CFI_REL_OFFSET ds, 0;*/ pushl %eax CFI_ADJUST_CFA_OFFSET 4 CFI_REL_OFFSET eax, 0 pushl %ebp CFI_ADJUST_CFA_OFFSET 4 CFI_REL_OFFSET ebp, 0 pushl %edi CFI_ADJUST_CFA_OFFSET 4 CFI_REL_OFFSET edi, 0 pushl %esi CFI_ADJUST_CFA_OFFSET 4 CFI_REL_OFFSET esi, 0 pushl %edx CFI_ADJUST_CFA_OFFSET 4 CFI_REL_OFFSET edx, 0 pushl %ecx CFI_ADJUST_CFA_OFFSET 4 CFI_REL_OFFSET ecx, 0 pushl %ebx CFI_ADJUST_CFA_OFFSET 4 CFI_REL_OFFSET ebx, 0 movl $(__USER_DS), %edx movl %edx, %ds movl %edx, %es movl $(__KERNEL_PERCPU), %edx movl %edx, %fs SET_KERNEL_GS %edx .endm /* ... */ ENTRY(system_call) RING0_INT_FRAME # 无论如何不能进入用户空间 pushl %eax # 将保存的系统调用编号压入栈中 CFI_ADJUST_CFA_OFFSET 4 SAVE_ALL GET_THREAD_INFO(%ebp) # 检测进程是否被跟踪 testl $_TIF_WORK_SYSCALL_ENTRY,TI_flags(%ebp) jnz syscall_trace_entry cmpl $(nr_syscalls), %eax jae syscall_badsys syscall_call: call *sys_call_table(,%eax,4) # 跳入对应服务例程 movl %eax,PT_EAX(%esp) # 保存进程的返回值 syscall_exit: LOCKDEP_SYS_EXIT DISABLE_INTERRUPTS(CLBR_ANY) # 不要忘了在中断返回前关闭中断 TRACE_IRQS_OFF movl TI_flags(%ebp), %ecx testl $_TIF_ALLWORK_MASK, %ecx # current->work jne syscall_exit_work restore_all: TRACE_IRQS_IRET restore_all_notrace: movl PT_EFLAGS(%esp), %eax # mix EFLAGS, SS and CS # Warning: PT_OLDSS(%esp) contains the wrong/random values if we # are returning to the kernel. # See comments in process.c:copy_thread() for details. movb PT_OLDSS(%esp), %ah movb PT_CS(%esp), %al andl $(X86_EFLAGS_VM | (SEGMENT_TI_MASK << 8) | SEGMENT_RPL_MASK), %eax cmpl $((SEGMENT_LDT << 8) | USER_RPL), %eax CFI_REMEMBER_STATE je ldt_ss # returning to user-space with LDT SS restore_nocheck: RESTORE_REGS 4 # skip orig_eax/error_code CFI_ADJUST_CFA_OFFSET -4 irq_return: INTERRUPT_RETURN .section .fixup,"ax"
分析:
(1)在system_call函数执行之前,CPU控制单元已经将eflags、cs、eip、ss和esp寄存器的值自动保存到该进程对应的内核栈中。随之,在 system_call内部首先将存储在eax寄存器中的系统调用号压入栈中。接着执行SAVE_ALL宏。该宏在栈中保存接下来的系统调用可能要用到的所有CPU寄存器。
(2)通过GET_THREAD_INFO宏获得当前进程的thread_inof结构的地址;再检测当前进程是否被其他进程所跟踪(例如调试一个程序时,被调试的程序就处于被跟踪状态),也就是thread_info结构中flag字段的_TIF_ALLWORK_MASK被置1。如果发生被跟踪的情况则转向syscall_trace_entry标记的处理命令处。
(3)对用户态进程传递过来的系统调用号的合法性进行检查。如果不合法则跳入到syscall_badsys标记的命令处。
(4)如果系统调用好合法,则根据系统调用号查找./linux/arch/x86/kernel/syscall_table_32.S中的系统调用表sys_call_table,找到相应的函数入口点,跳入sys_fork这个服务例程当中。由于 sys_call_table表的表项占4字节,因此获得服务例程指针的具体方法是将由eax保存的系统调用号乘以4再与sys_call_table表的基址相加。syscall_table_32.S中的代码如下:
ENTRY(sys_call_table) .long sys_restart_syscall /* 0 - old "setup()" system call, used for restarting */ .long sys_exit .long ptregs_fork .long sys_read .long sys_write .long sys_open /* 5 */ .long sys_close /* ... */
sys_call_table是系统调用多路分解表,使用 eax 中提供的索引来确定要调用该表中的哪个系统调用。
(5)当系统调用服务例程结束时,从eax寄存器中获得当前进程的的返回值,并把这个返回值存放在曾保存用户态eax寄存器值的那个栈单元的位置上。这样,用户态进程就可以在eax寄存器中找到系统调用的返回码。
经过的调用链为fork()—>int$0×80软中断—>ENTRY(system_call)—>ENTRY(sys_call_table)—>sys_fork()—>do_fork()。实际上fork、vfork和clone三个系统调最终都是调用do_fork()。只不过在调用时所传递的参数有所不同,而参数的不同正好导致了子进程与父进程之间对资源的共享程度不同。因此,分析do_fork()成为我们的首要任务。在进入do_fork函数进行分析之前,很有必要了解一下它的参数。
clone_flags:该标志位的4个字节分为两部分。最低的一个字节为子进程结束时发送给父进程的信号代码,通常为SIGCHLD;剩余的三个字节则是各种clone标志的组合(本文所涉及的标志含义详见下表),也就是若干个标志之间的或运算。通过 clone标志可以有选择的对父进程的资源进行复制。本文所涉及到的clone标志详见下表。
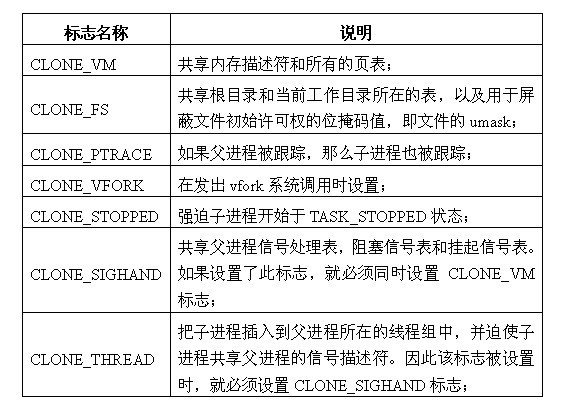
表1 clone标志含义
stack_start:子进程用户态堆栈的地址。
regs:指向pt_regs结构体的指针。当系统发生系统调用,即用户进程从用户态切换到内核态时,该结构体保存通用寄存器中的值,并被存放于内核态的堆栈中。
stack_size:未被使用,通常被赋值为0。
parent_tidptr:父进程在用户态下pid的地址,该参数在CLONE_PARENT_SETTID标志被设定时有意义。
child_tidptr:子进程在用户态下pid的地址,该参数在CLONE_CHILD_SETTID标志被设定时有意义。
do_fork函数在./linux/kernel/fork.c中,主要工作就是复制原来的进程成为另一个新的进程,它完成了整个进程创建中的大部分工作。代码如下:
long do_fork(unsigned long clone_flags, unsigned long stack_start, struct pt_regs *regs, unsigned long stack_size, int __user *parent_tidptr, int __user *child_tidptr) { struct task_struct *p; int trace = 0; long nr; /* * 做一些预先的参数和权限检查 */ if (clone_flags & CLONE_NEWUSER) { if (clone_flags & CLONE_THREAD) return -EINVAL; /* 希望当用户名称被支持时,这里的检查可去掉 */ if (!capable(CAP_SYS_ADMIN) || !capable(CAP_SETUID) || !capable(CAP_SETGID)) return -EPERM; } /* * 希望在2.6.26之后这些标志能实现循环 */ if (unlikely(clone_flags & CLONE_STOPPED)) { static int __read_mostly count = 100; if (count > 0 && printk_ratelimit()) { char comm[TASK_COMM_LEN]; count--; printk(KERN_INFO "fork(): process `%s' used deprecated " "clone flags 0x%lx ", get_task_comm(comm, current), clone_flags & CLONE_STOPPED); } } /* * 当从kernel_thread调用本do_fork时,不使用跟踪 */ if (likely(user_mode(regs))) /* 如果从用户态进入本调用,则使用跟踪 */ trace = tracehook_prepare_clone(clone_flags); p = copy_process(clone_flags, stack_start, regs, stack_size, child_tidptr, NULL, trace); /* * 在唤醒新线程之前做下面的工作,因为新线程唤醒后本线程指针会变成无效(如果退出很快的话) */ if (!IS_ERR(p)) { struct completion vfork; trace_sched_process_fork(current, p); nr = task_pid_vnr(p); if (clone_flags & CLONE_PARENT_SETTID) put_user(nr, parent_tidptr); if (clone_flags & CLONE_VFORK) { p->vfork_done = &vfork; init_completion(&vfork); } audit_finish_fork(p); tracehook_report_clone(regs, clone_flags, nr, p); /* * 我们在创建时设置PF_STARTING,以防止跟踪进程想使用这个标志来区分一个完全活着的进程 * 和一个还没有获得trackhook_report_clone()的进程。现在我们清除它并且设置子进程运行 */ p->flags &= ~PF_STARTING; if (unlikely(clone_flags & CLONE_STOPPED)) { /* * 我们将立刻启动一个即时的SIGSTOP */ sigaddset(&p->pending.signal, SIGSTOP); set_tsk_thread_flag(p, TIF_SIGPENDING); __set_task_state(p, TASK_STOPPED); } else { wake_up_new_task(p, clone_flags); } tracehook_report_clone_complete(trace, regs, clone_flags, nr, p); if (clone_flags & CLONE_VFORK) { freezer_do_not_count(); wait_for_completion(&vfork); freezer_count(); tracehook_report_vfork_done(p, nr); } } else { nr = PTR_ERR(p); } return nr; }
(1)在一开始,该函数定义了一个task_struct类型的指针p,用来接收即将为新进程(子进程)所分配的进程描述符。trace表示跟踪状态,nr表示新进程的pid。接着做一些预先的参数和权限检查。
(2)接下来检查clone_flags是否设置了CLONE_STOPPED标志。如果设置了,则做相应处理,打印消息说明进程已过时。通常这样的情况很少发生,因此在判断时使用了unlikely修饰符。使用该修饰符的判断语句执行结果与普通判断语句相同,只不过在执行效率上有所不同。正如该单词的含义所表示的那样,当前进程很少为停止状态。因此,编译器尽量不会把if内的语句与当前语句之前的代码编译在一起,以增加cache的命中率。与此相反,likely修饰符则表示所修饰的代码很可能发生。tracehook_prepare_clone用于设置子进程是否被跟踪。所谓跟踪,最常见的例子就是处于调试状态下的进程被debugger进程所跟踪。进程的ptrace字段非0说明debugger程序正在跟踪它。如果调用是从用户态进来的(而不从kernel_thread进来的),且当前进程(父进程)被另外一个进程所跟踪,那么子进程也要设置为被跟踪,并且将跟踪标志CLONE_PTRACE加入标志变量clone_flags中。如果父进程不被跟踪,则子进程也不会被跟踪,设置好后返回trace。
(3)接下来的这条语句要做的是整个创建过程中最核心的工作:通过copy_process()创建子进程的描述符,分配pid,并创建子进程执行时所需的其他数据结构,最终则会返回这个创建好的进程描述符p。该函数中的参数意义与do_fork函数相同。注意原来内核中为子进程分配pid的工作是在do_fork中完成,现在新的内核已经移到copy_process中了。
(4)如果copy_process函数执行成功,那么将继续执行if(!IS_ERR(p))部分。首先定义了一个完成量vfork,用task_pid_vnr(p)从p中获取新进程的pid。如果clone_flags包含CLONE_VFORK标志,那么将进程描述符中的vfork_done字段指向这个完成量,之后再对vfork完成量进行初始化。完成量的作用是,直到任务A发出信号通知任务B发生了某个特定事件时,任务B才会开始执行,否则任务B一直等待。我们知道,如果使用vfork系统调用来创建子进程,那么必然是子进程先执行。究其原因就是此处vfork完成量所起到的作用。当子进程调用exec函数或退出时就向父进程发出信号,此时父进程才会被唤醒,否则一直等待。此处的代码只是对完成量进行初始化,具体的阻塞语句则在后面的代码中有所体现。
(5)如果子进程被跟踪或者设置了CLONE_STOPPED标志,那么通过sigaddset函数为子进程增加挂起信号,并将子进程的状态设置为TASK_STOPPED。signal对应一个unsignedlong类型的变量,该变量的每个位分别对应一种信号。具体的操作是将SIGSTOP信号所对应的那一位置1。如果子进程并未设置CLONE_STOPPED标志,那么通过wake_up_new_task将进程放到运行队列上,从而让调度器进行调度运行。wake_up_new_task()在./linux/kernel/sched.c中,用于唤醒第一次新创建的进程,它将为新进程做一些初始的必须的调度器统计操作,然后把进程放到运行队列中。一旦当然正在运行的进程时间片用完(通过时钟tick中断来控制),就会调用schedule(),从而进行进程调度(下一章节文章中进行详细讲解)。代码如下:
void wake_up_new_task(struct task_struct *p, unsigned long clone_flags) { unsigned long flags; struct rq *rq; int cpu = get_cpu(); #ifdef CONFIG_SMP rq = task_rq_lock(p, &flags); p->state = TASK_WAKING; /* * Fork balancing, do it here and not earlier because: * - cpus_allowed can change in the fork path * - any previously selected cpu might disappear through hotplug * * We set TASK_WAKING so that select_task_rq() can drop rq->lock * without people poking at ->cpus_allowed. */ cpu = select_task_rq(rq, p, SD_BALANCE_FORK, 0); set_task_cpu(p, cpu); p->state = TASK_RUNNING; task_rq_unlock(rq, &flags); #endif rq = task_rq_lock(p, &flags); update_rq_clock(rq); activate_task(rq, p, 0); trace_sched_wakeup_new(rq, p, 1); check_preempt_curr(rq, p, WF_FORK); #ifdef CONFIG_SMP if (p->sched_class->task_woken) p->sched_class->task_woken(rq, p); #endif task_rq_unlock(rq, &flags); put_cpu(); }
这里先用get_cpu()获取CPU,如果是对称多处理系统(SMP),先设置我为TASK_WAKING状态,由于有多个CPU(每个CPU上都有一个运行队列),需要进行负载均衡,选择一个最佳CPU并设置我使用这个CPU,然后设置我为TASK_RUNNING状态。这段操作是互斥的,因此需要加锁。注意TASK_RUNNING并不表示进程一定正在运行,无论进程是否正在占用CPU,只要具备运行条件,都处于该状态。 Linux把处于该状态的所有PCB组织成一个可运行队列run_queue,调度程序从这个队列中选择进程运行。事实上,Linux是将就绪态和运行态合并为了一种状态。
然后用./linux/kernel/sched.c:activate_task()把当前进程插入到对应CPU的runqueue上,最终完成入队的函数是active_task()—>enqueue_task(),其中核心代码行为:
p->sched_class->enqueue_task(rq, p,wakeup, head);
sched_class在./linux/include/linux/sched.h中,是调度器一系列操作的面向对象抽象,这个类包括进程入队、出队、进程运行、进程切换等接口,用于完成对进程的调度运行。
(6)tracehook_report_clone_complete函数用于在进程复制快要完成时报告跟踪情况。如果父进程被跟踪,则将子进程的pid赋值给父进程的进程描述符的pstrace_message字段,并向父进程的父进程发送SIGCHLD信号。
(7)如果CLONE_VFORK标志被设置,则通过wait操作将父进程阻塞,直至子进程调用exec函数或者退出。
(8)如果copy_process()在执行的时候发生错误,则先释放已分配的pid,再根据PTR_ERR()的返回值得到错误代码,保存于nr中。
4. copy_process: 进程描述符的处理
copy_process函数也在./linux/kernel/fork.c中。它会用当前进程的一个副本来创建新进程并分配pid,但不会实际启动这个新进程。它会复制寄存器中的值、所有与进程环境相关的部分,每个clone标志。新进程的实际启动由调用者来完成。
对于每一个进程而言,内核为其单独分配了一个内存区域,这个区域存储的是内核栈和该进程所对应的一个小型进程描述符thread_info结构。在./linux/arch/x86/include/asm/thread_info.h中,如下:
struct thread_info { struct task_struct *task; /* 主进程描述符 */ struct exec_domain *exec_domain; /* 执行域 */ __u32 flags; /* 低级别标志 */ __u32 status; /* 线程同步标志 */ __u32 cpu; /* 当前CPU */ int preempt_count; /* 0 => 可抢占, <0 => BUG */ mm_segment_t addr_limit; struct restart_block restart_block; void __user *sysenter_return; #ifdef CONFIG_X86_32 unsigned long previous_esp; /* 先前栈的ESP,以防嵌入的(IRQ)栈 */ __u8 supervisor_stack[0]; #endif int uaccess_err; }; /* ... */ /* 怎样从C获取当前栈指针 */ register unsigned long current_stack_pointer asm("esp") __used; /* 怎样从C获取当前线程信息结构 */ static inline struct thread_info *current_thread_info(void) { return (struct thread_info *) (current_stack_pointer & ~(THREAD_SIZE - 1)); }
之所以将线程信息结构称之为小型的进程描述符,是因为在这个结构中并没有直接包含与进程相关的字段,而是通过task字段指向具体某个进程描述符。通常这块内存区域的大小是8KB,也就是两个页的大小(有时候也使用一个页来存储,即4KB)。一个进程的内核栈和thread_info结构之间的逻辑关系如下图所示:

图 进程内核栈和thread_info结构的存储
从上图可知,内核栈是从该内存区域的顶层向下(从高地址到低地址)增长的,而thread_info结构则是从该区域的开始处向上(从低地址到高地址)增长。内核栈的栈顶地址存储在esp寄存器中。所以,当进程从用户态切换到内核态后,esp寄存器指向这个区域的末端。从代码的角度来看,内核栈和thread_info结构是被定义在./linux/include/linux/sched.h中的一个联合体当中的:
union thread_union { struct thread_info thread_info; unsigned long stack[THREAD_SIZE/sizeof(long)]; };
其中,THREAD_SIZE的值取8192时,stack数组的大小为2048;THREAD_SIZE的值取4096时,stack数组的大小为1024。
现在我们应该思考,为何要将内核栈和thread_info(其实也就相当于task_struct,只不过使用thread_info结构更节省空间)紧密的放在一起?最主要的原因就是内核可以很容易的通过esp寄存器的值获得当前正在运行进程的thread_info结构的地址,进而获得当前进程描述符的地址。在上面的current_thread_info函数中,定义current_stack_pointer的这条内联汇编语句会从esp寄存器中获取内核栈顶地址,和~(THREAD_SIZE - 1)做与操作将屏蔽掉低13位(或12位,当THREAD_SIZE为4096时),此时所指的地址就是这片内存区域的起始地址,也就刚好是thread_info结构的地址。但是,thread_info结构的地址并不会对我们直接有用。我们通常可以轻松的通过 current宏获得当前进程的task_struct结构,前面已经列出过get_current()函数的代码。current宏返回的是thread_info结构task字段,而task正好指向与thread_info结构关联的那个进程描述符。得到 current后,我们就可以获得当前正在运行进程的描述符中任何一个字段了,比如我们通常所做的current->pid。
下面看copy_process的实现。
static struct task_struct *copy_process(unsigned long clone_flags, unsigned long stack_start, struct pt_regs *regs, unsigned long stack_size, int __user *child_tidptr, struct pid *pid, int trace) { int retval; struct task_struct *p; int cgroup_callbacks_done = 0; if ((clone_flags & (CLONE_NEWNS|CLONE_FS)) == (CLONE_NEWNS|CLONE_FS)) return ERR_PTR(-EINVAL); /* * Thread groups must share signals as well, and detached threads * can only be started up within the thread group. */ if ((clone_flags & CLONE_THREAD) && !(clone_flags & CLONE_SIGHAND)) return ERR_PTR(-EINVAL); /* * Shared signal handlers imply shared VM. By way of the above, * thread groups also imply shared VM. Blocking this case allows * for various simplifications in other code. */ if ((clone_flags & CLONE_SIGHAND) && !(clone_flags & CLONE_VM)) return ERR_PTR(-EINVAL); /* * Siblings of global init remain as zombies on exit since they are * not reaped by their parent (swapper). To solve this and to avoid * multi-rooted process trees, prevent global and container-inits * from creating siblings. */ if ((clone_flags & CLONE_PARENT) && current->signal->flags & SIGNAL_UNKILLABLE) return ERR_PTR(-EINVAL); retval = security_task_create(clone_flags); if (retval) goto fork_out; retval = -ENOMEM; p = dup_task_struct(current); if (!p) goto fork_out; ftrace_graph_init_task(p); rt_mutex_init_task(p); #ifdef CONFIG_PROVE_LOCKING DEBUG_LOCKS_WARN_ON(!p->hardirqs_enabled); DEBUG_LOCKS_WARN_ON(!p->softirqs_enabled); #endif retval = -EAGAIN; if (atomic_read(&p->real_cred->user->processes) >= p->signal->rlim[RLIMIT_NPROC].rlim_cur) { if (!capable(CAP_SYS_ADMIN) && !capable(CAP_SYS_RESOURCE) && p->real_cred->user != INIT_USER) goto bad_fork_free; } retval = copy_creds(p, clone_flags); if (retval < 0) goto bad_fork_free; /* * If multiple threads are within copy_process(), then this check * triggers too late. This doesn't hurt, the check is only there * to stop root fork bombs. */ retval = -EAGAIN; if (nr_threads >= max_threads) goto bad_fork_cleanup_count; if (!try_module_get(task_thread_info(p)->exec_domain->module)) goto bad_fork_cleanup_count; p->did_exec = 0; delayacct_tsk_init(p); /* Must remain after dup_task_struct() */ copy_flags(clone_flags, p); INIT_LIST_HEAD(&p->children); INIT_LIST_HEAD(&p->sibling); rcu_copy_process(p); p->vfork_done = NULL; spin_lock_init(&p->alloc_lock); init_sigpending(&p->pending); p->utime = cputime_zero; p->stime = cputime_zero; p->gtime = cputime_zero; p->utimescaled = cputime_zero; p->stimescaled = cputime_zero; p->prev_utime = cputime_zero; p->prev_stime = cputime_zero; p->default_timer_slack_ns = current->timer_slack_ns; task_io_accounting_init(&p->ioac); acct_clear_integrals(p); posix_cpu_timers_init(p); p->lock_depth = -1; /* -1 = no lock */ do_posix_clock_monotonic_gettime(&p->start_time); p->real_start_time = p->start_time; monotonic_to_bootbased(&p->real_start_time); p->io_context = NULL; p->audit_context = NULL; cgroup_fork(p); #ifdef CONFIG_NUMA p->mempolicy = mpol_dup(p->mempolicy); if (IS_ERR(p->mempolicy)) { retval = PTR_ERR(p->mempolicy); p->mempolicy = NULL; goto bad_fork_cleanup_cgroup; } mpol_fix_fork_child_flag(p); #endif #ifdef CONFIG_TRACE_IRQFLAGS p->irq_events = 0; #ifdef __ARCH_WANT_INTERRUPTS_ON_CTXSW p->hardirqs_enabled = 1; #else p->hardirqs_enabled = 0; #endif p->hardirq_enable_ip = 0; p->hardirq_enable_event = 0; p->hardirq_disable_ip = _THIS_IP_; p->hardirq_disable_event = 0; p->softirqs_enabled = 1; p->softirq_enable_ip = _THIS_IP_; p->softirq_enable_event = 0; p->softirq_disable_ip = 0; p->softirq_disable_event = 0; p->hardirq_context = 0; p->softirq_context = 0; #endif #ifdef CONFIG_LOCKDEP p->lockdep_depth = 0; /* no locks held yet */ p->curr_chain_key = 0; p->lockdep_recursion = 0; #endif #ifdef CONFIG_DEBUG_MUTEXES p->blocked_on = NULL; /* not blocked yet */ #endif p->bts = NULL; /* Perform scheduler related setup. Assign this task to a CPU. */ sched_fork(p, clone_flags); retval = perf_event_init_task(p); if (retval) goto bad_fork_cleanup_policy; if ((retval = audit_alloc(p))) goto bad_fork_cleanup_policy; /* copy all the process information */ if ((retval = copy_semundo(clone_flags, p))) goto bad_fork_cleanup_audit; if ((retval = copy_files(clone_flags, p))) goto bad_fork_cleanup_semundo; if ((retval = copy_fs(clone_flags, p))) goto bad_fork_cleanup_files; if ((retval = copy_sighand(clone_flags, p))) goto bad_fork_cleanup_fs; if ((retval = copy_signal(clone_flags, p))) goto bad_fork_cleanup_sighand; if ((retval = copy_mm(clone_flags, p))) goto bad_fork_cleanup_signal; if ((retval = copy_namespaces(clone_flags, p))) goto bad_fork_cleanup_mm; if ((retval = copy_io(clone_flags, p))) goto bad_fork_cleanup_namespaces; retval = copy_thread(clone_flags, stack_start, stack_size, p, regs); if (retval) goto bad_fork_cleanup_io; if (pid != &init_struct_pid) { retval = -ENOMEM; pid = alloc_pid(p->nsproxy->pid_ns); if (!pid) goto bad_fork_cleanup_io; if (clone_flags & CLONE_NEWPID) { retval = pid_ns_prepare_proc(p->nsproxy->pid_ns); if (retval < 0) goto bad_fork_free_pid; } } p->pid = pid_nr(pid); p->tgid = p->pid; if (clone_flags & CLONE_THREAD) p->tgid = current->tgid; if (current->nsproxy != p->nsproxy) { retval = ns_cgroup_clone(p, pid); if (retval) goto bad_fork_free_pid; } p->set_child_tid = (clone_flags & CLONE_CHILD_SETTID) ? child_tidptr : NULL; /* * Clear TID on mm_release()? */ p->clear_child_tid = (clone_flags & CLONE_CHILD_CLEARTID) ? child_tidptr: NULL; #ifdef CONFIG_FUTEX p->robust_list = NULL; #ifdef CONFIG_COMPAT p->compat_robust_list = NULL; #endif INIT_LIST_HEAD(&p->pi_state_list); p->pi_state_cache = NULL; #endif /* * sigaltstack should be cleared when sharing the same VM */ if ((clone_flags & (CLONE_VM|CLONE_VFORK)) == CLONE_VM) p->sas_ss_sp = p->sas_ss_size = 0; /* * Syscall tracing should be turned off in the child regardless * of CLONE_PTRACE. */ clear_tsk_thread_flag(p, TIF_SYSCALL_TRACE); #ifdef TIF_SYSCALL_EMU clear_tsk_thread_flag(p, TIF_SYSCALL_EMU); #endif clear_all_latency_tracing(p); /* ok, now we should be set up.. */ p->exit_signal = (clone_flags & CLONE_THREAD) ? -1 : (clone_flags & CSIGNAL); p->pdeath_signal = 0; p->exit_state = 0; /* * Ok, make it visible to the rest of the system. * We dont wake it up yet. */ p->group_leader = p; INIT_LIST_HEAD(&p->thread_group); /* Now that the task is set up, run cgroup callbacks if * necessary. We need to run them before the task is visible * on the tasklist. */ cgroup_fork_callbacks(p); cgroup_callbacks_done = 1; /* Need tasklist lock for parent etc handling! */ write_lock_irq(&tasklist_lock); /* CLONE_PARENT re-uses the old parent */ if (clone_flags & (CLONE_PARENT|CLONE_THREAD)) { p->real_parent = current->real_parent; p->parent_exec_id = current->parent_exec_id; } else { p->real_parent = current; p->parent_exec_id = current->self_exec_id; } spin_lock(¤t->sighand->siglock); /* * Process group and session signals need to be delivered to just the * parent before the fork or both the parent and the child after the * fork. Restart if a signal comes in before we add the new process to * it's process group. * A fatal signal pending means that current will exit, so the new * thread can't slip out of an OOM kill (or normal SIGKILL). */ recalc_sigpending(); if (signal_pending(current)) { spin_unlock(¤t->sighand->siglock); write_unlock_irq(&tasklist_lock); retval = -ERESTARTNOINTR; goto bad_fork_free_pid; } if (clone_flags & CLONE_THREAD) { atomic_inc(¤t->signal->count); atomic_inc(¤t->signal->live); p->group_leader = current->group_leader; list_add_tail_rcu(&p->thread_group, &p->group_leader->thread_group); } if (likely(p->pid)) { list_add_tail(&p->sibling, &p->real_parent->children); tracehook_finish_clone(p, clone_flags, trace); if (thread_group_leader(p)) { if (clone_flags & CLONE_NEWPID) p->nsproxy->pid_ns->child_reaper = p; p->signal->leader_pid = pid; tty_kref_put(p->signal->tty); p->signal->tty = tty_kref_get(current->signal->tty); attach_pid(p, PIDTYPE_PGID, task_pgrp(current)); attach_pid(p, PIDTYPE_SID, task_session(current)); list_add_tail_rcu(&p->tasks, &init_task.tasks); __get_cpu_var(process_counts)++; } attach_pid(p, PIDTYPE_PID, pid); nr_threads++; } total_forks++; spin_unlock(¤t->sighand->siglock); write_unlock_irq(&tasklist_lock); proc_fork_connector(p); cgroup_post_fork(p); perf_event_fork(p); return p; bad_fork_free_pid: if (pid != &init_struct_pid) free_pid(pid); bad_fork_cleanup_io: put_io_context(p->io_context); bad_fork_cleanup_namespaces: exit_task_namespaces(p); bad_fork_cleanup_mm: if (p->mm) mmput(p->mm); bad_fork_cleanup_signal: if (!(clone_flags & CLONE_THREAD)) __cleanup_signal(p->signal); bad_fork_cleanup_sighand: __cleanup_sighand(p->sighand); bad_fork_cleanup_fs: exit_fs(p); /* blocking */ bad_fork_cleanup_files: exit_files(p); /* blocking */ bad_fork_cleanup_semundo: exit_sem(p); bad_fork_cleanup_audit: audit_free(p); bad_fork_cleanup_policy: perf_event_free_task(p); #ifdef CONFIG_NUMA mpol_put(p->mempolicy); bad_fork_cleanup_cgroup: #endif cgroup_exit(p, cgroup_callbacks_done); delayacct_tsk_free(p); module_put(task_thread_info(p)->exec_domain->module); bad_fork_cleanup_count: atomic_dec(&p->cred->user->processes); exit_creds(p); bad_fork_free: free_task(p); fork_out: return ERR_PTR(retval); }
(1)定义返回值亦是retval和新的进程描述符task_struct结构p。
(2)标志合法性检查。对clone_flags所传递的标志组合进行合法性检查。当出现以下三种情况时,返回出错代号:
1)CLONE_NEWNS和CLONE_FS同时被设置。前者标志表示子进程需要自己的命名空间,而后者标志则代表子进程共享父进程的根目录和当前工作目录,两者不可兼容。在传统的Unix系统中,整个系统只有一个已经安装的文件系统树。每个进程从系统的根文件系统开始,通过合法的路径可以访问任何文件。在2.6版本中的内核中,每个进程都可以拥有属于自己的已安装文件系统树,也被称为命名空间。通常大多数进程都共享init进程所使用的已安装文件系统树,只有在clone_flags中设置了CLONE_NEWNS标志时,才会为此新进程开辟一个新的命名空间。
2)CLONE_THREAD被设置,但CLONE_SIGHAND未被设置。如果子进程和父进程属于同一个线程组(CLONE_THREAD被设置),那么子进程必须共享父进程的信号(CLONE_SIGHAND被设置)。
3)CLONE_SIGHAND被设置,但CLONE_VM未被设置。如果子进程共享父进程的信号,那么必须同时共享父进程的内存描述符和所有的页表(CLONE_VM被设置)。
(3)安全性检查。通过调用security_task_create()和后面的security_task_alloc()执行所有附加的安全性检查。询问 Linux Security Module (LSM) 看当前任务是否可以创建一个新任务。LSM是SELinux的核心。
(4)复制进程描述符。通过dup_task_struct()为子进程分配一个内核栈、thread_info结构和task_struct结构。注意,这里将当前进程描述符指针作为参数传递到此函数中。函数代码如下:
int __attribute__((weak)) arch_dup_task_struct(struct task_struct *dst, struct task_struct *src) { *dst = *src; return 0; } static struct task_struct *dup_task_struct(struct task_struct *orig) { struct task_struct *tsk; struct thread_info *ti; unsigned long *stackend; int err; prepare_to_copy(orig); tsk = alloc_task_struct(); if (!tsk) return NULL; ti = alloc_thread_info(tsk); if (!ti) { free_task_struct(tsk); return NULL; } err = arch_dup_task_struct(tsk, orig); if (err) goto out; tsk->stack = ti; err = prop_local_init_single(&tsk->dirties); if (err) goto out; setup_thread_stack(tsk, orig); stackend = end_of_stack(tsk); *stackend = STACK_END_MAGIC; /* 用于溢出检测 */ #ifdef CONFIG_CC_STACKPROTECTOR tsk->stack_canary = get_random_int(); #endif /* One for us, one for whoever does the "release_task()" (usually parent) */ atomic_set(&tsk->usage,2); atomic_set(&tsk->fs_excl, 0); #ifdef CONFIG_BLK_DEV_IO_TRACE tsk->btrace_seq = 0; #endif tsk->splice_pipe = NULL; account_kernel_stack(ti, 1); return tsk; out: free_thread_info(ti); free_task_struct(tsk); return NULL; }
首先,该函数分别定义了指向task_struct和thread_info结构体的指针。接着,prepare_to_copy为正式的分配进程描述符做一些准备工作。主要是将一些必要的寄存器的值保存到父进程的thread_info结构中。这些值会在稍后被复制到子进程的thread_info结构中。执行alloc_task_struct宏,该宏负责为子进程的进程描述符分配空间,将该片内存的首地址赋值给tsk,随后检查这片内存是否分配正确。执行alloc_thread_info宏,为子进程获取一块空闲的内存区,用来存放子进程的内核栈和thread_info结构,并将此会内存区的首地址赋值给ti变量,随后检查是否分配正确。
上面已经说明过orig是传进来的current宏,指向当前进程描述符的指针。arch_dup_task_struct直接将orig指向的当前进程描述符内容复制到当前里程描述符tsk。接着,用atomic_set将子进程描述符的使用计数器设置为2,表示该进程描述符正在被使用并且处于活动状态。最后返回指向刚刚创建的子进程描述符内存区的指针。
通过dup_task_struct可以看到,当这个函数成功操作之后,子进程和父进程的描述符中的内容是完全相同的。在稍后的copy_process代码中,我们将会看到子进程逐步与父进程区分开来。
(5)一些初始化。通过诸如ftrace_graph_init_task,rt_mutex_init_task完成某些数据结构的初始化。调用copy_creds()复制证书(应该是复制权限及身份信息)。
(6)检测系统中进程的总数量是否超过了max_threads所规定的进程最大数。
(7)复制标志。通过copy_flags,将从do_fork()传递来的的clone_flags和pid分别赋值给子进程描述符中的对应字段。
(8)初始化子进程描述符。初始化其中的各个字段,使得子进程和父进程逐渐区别出来。这部分工作包含初始化子进程中的children和sibling等队列头、初始化自旋锁和信号处理、初始化进程统计信息、初始化POSIX时钟、初始化调度相关的统计信息、初始化审计信息。它在copy_process函数中占据了相当长的一段的代码,不过考虑到task_struct结构本身的复杂性,也就不足为奇了。
(9)调度器设置。调用sched_fork函数执行调度器相关的设置,为这个新进程分配CPU,使得子进程的进程状态为TASK_RUNNING。并禁止内核抢占。并且,为了不对其他进程的调度产生影响,此时子进程共享父进程的时间片。
(10)复制进程的所有信息。根据clone_flags的具体取值来为子进程拷贝或共享父进程的某些数据结构。比如copy_semundo()、复制开放文件描述符(copy_files)、复制符号信息(copy_sighand 和copy_signal)、复制进程内存(copy_mm)以及最终复制线程(copy_thread)。
(11)复制线程。通过copy_threads()函数更新子进程的内核栈和寄存器中的值。在之前的dup_task_struct()中只是为子进程创建一个内核栈,至此才是真正的赋予它有意义的值。
当父进程发出clone系统调用时,内核会将那个时候CPU中寄存器的值保存在父进程的内核栈中。这里就是使用父进程内核栈中的值来更新子进程寄存器中的值。特别的,内核将子进程eax寄存器中的值强制赋值为0,这也就是为什么使用fork()时子进程返回值是0。而在do_fork函数中则返回的是子进程的pid,这一点在上述内容中我们已经有所分析。另外,子进程的对应的thread_info结构中的esp字段会被初始化为子进程内核栈的基址。
(12)分配pid。用alloc_pid函数为这个新进程分配一个pid,Linux系统内的pid是循环使用的,采用位图方式来管理。简单的说,就是用每一位(bit)来标示该位所对应的pid是否被使用。分配完毕后,判断pid是否分配成功。成功则赋给p->pid。
(13)更新属性和进程数量。根据clone_flags的值继续更新子进程的某些属性。将 nr_threads加一,表明新进程已经被加入到进程集合中。将total_forks加一,以记录被创建进程数量。
(14)如果上述过程中某一步出现了错误,则通过goto语句跳到相应的错误代码处;如果成功执行完毕,则返回子进程的描述符p。
至此,copy_process()的大致执行过程分析完毕。
copy_process()执行完后返回do_fork(),do_fork()执行完毕后,虽然子进程处于可运行状态,但是它并没有立刻运行。至于子进程何时执行这完全取决于调度程序,也就是schedule()的事了。
5. 进程调度
创建好的进程最后被插入到运行队列中,它会通过 Linux 调度程序来调度。Linux调度程序维护了针对每个优先级别的一组列表,其中保存了 task_struct 引用。当正在运行的进程时间片用完时,时钟tick产生中断,调用kernel/sched.c:scheduler_tick()进程调度器的中断处理,中断返回后就会调用schedule()。运行队列中的任务通过 schedule 函数(在./linux/kernel/sched.c 内)来调用,它根据加载及进程执行历史决定最佳进程。这里并不涉及此函数的分析。
6. 进程销毁
进程销毁可以通过几个事件驱动、通过正常的进程结束(当一个C程序从main函数返回时startuproutine调用exit)、通过信号或是通过显式地对 exit 函数的调用。不管进程如何退出,进程的结束都要借助对内核函数 do_exit(在./linux/kernel/exit.c 内)的调用。函数的层次结构如下图: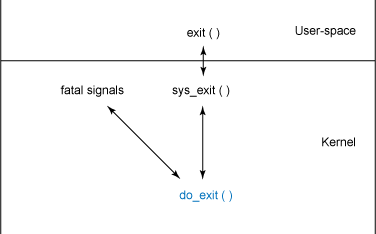
图 进程销毁的函数层次结构
exit()调用通过0x80中断跳到sys_exit内核例程处,这个例程名称可以在./linux/include/linux/syscalls.h中找到(syscalls.h中导出所有平台无关的系统调用名称),定义为asmlinkage long sys_exit(int error_code); 它会直接调用do_exit。代码如下:
NORET_TYPE void do_exit(long code) { struct task_struct *tsk = current; int group_dead; profile_task_exit(tsk); WARN_ON(atomic_read(&tsk->fs_excl)); if (unlikely(in_interrupt())) panic("Aiee, killing interrupt handler!"); if (unlikely(!tsk->pid)) panic("Attempted to kill the idle task!"); /* * If do_exit is called because this processes oopsed, it's possible * that get_fs() was left as KERNEL_DS, so reset it to USER_DS before * continuing. Amongst other possible reasons, this is to prevent * mm_release()->clear_child_tid() from writing to a user-controlled * kernel address. */ set_fs(USER_DS); tracehook_report_exit(&code); validate_creds_for_do_exit(tsk); /* * We're taking recursive faults here in do_exit. Safest is to just * leave this task alone and wait for reboot. */ if (unlikely(tsk->flags & PF_EXITING)) { printk(KERN_ALERT "Fixing recursive fault but reboot is needed! "); /* * We can do this unlocked here. The futex code uses * this flag just to verify whether the pi state * cleanup has been done or not. In the worst case it * loops once more. We pretend that the cleanup was * done as there is no way to return. Either the * OWNER_DIED bit is set by now or we push the blocked * task into the wait for ever nirwana as well. */ tsk->flags |= PF_EXITPIDONE; set_current_state(TASK_UNINTERRUPTIBLE); schedule(); } exit_irq_thread(); exit_signals(tsk); /* sets PF_EXITING */ /* * tsk->flags are checked in the futex code to protect against * an exiting task cleaning up the robust pi futexes. */ smp_mb(); spin_unlock_wait(&tsk->pi_lock); if (unlikely(in_atomic())) printk(KERN_INFO "note: %s[%d] exited with preempt_count %d ", current->comm, task_pid_nr(current), preempt_count()); acct_update_integrals(tsk); group_dead = atomic_dec_and_test(&tsk->signal->live); if (group_dead) { hrtimer_cancel(&tsk->signal->real_timer); exit_itimers(tsk->signal); if (tsk->mm) setmax_mm_hiwater_rss(&tsk->signal->maxrss, tsk->mm); } acct_collect(code, group_dead); if (group_dead) tty_audit_exit(); if (unlikely(tsk->audit_context)) audit_free(tsk); tsk->exit_code = code; taskstats_exit(tsk, group_dead); exit_mm(tsk); if (group_dead) acct_process(); trace_sched_process_exit(tsk); exit_sem(tsk); exit_files(tsk); exit_fs(tsk); check_stack_usage(); exit_thread(); cgroup_exit(tsk, 1); if (group_dead && tsk->signal->leader) disassociate_ctty(1); module_put(task_thread_info(tsk)->exec_domain->module); proc_exit_connector(tsk); /* * Flush inherited counters to the parent - before the parent * gets woken up by child-exit notifications. */ perf_event_exit_task(tsk); exit_notify(tsk, group_dead); #ifdef CONFIG_NUMA mpol_put(tsk->mempolicy); tsk->mempolicy = NULL; #endif #ifdef CONFIG_FUTEX if (unlikely(current->pi_state_cache)) kfree(current->pi_state_cache); #endif /* * Make sure we are holding no locks: */ debug_check_no_locks_held(tsk); /* * We can do this unlocked here. The futex code uses this flag * just to verify whether the pi state cleanup has been done * or not. In the worst case it loops once more. */ tsk->flags |= PF_EXITPIDONE; if (tsk->io_context) exit_io_context(); if (tsk->splice_pipe) __free_pipe_info(tsk->splice_pipe); validate_creds_for_do_exit(tsk); preempt_disable(); exit_rcu(); /* causes final put_task_struct in finish_task_switch(). */ tsk->state = TASK_DEAD; schedule(); BUG(); /* Avoid "noreturn function does return". */ for (;;) cpu_relax(); /* For when BUG is null */ } EXPORT_SYMBOL_GPL(do_exit);
(1)为进程销毁做一系列准备。用set_fs设置USER_DS。注意如果do_exit是因为当前进程出现不可预知的错误而被调用,这时get_fs()有可能得到的仍然是KERNEL_DS状态,因此我们要重置它为USER_DS状态。还有一个可能原因是这可以防止mm_release()->clear_child_tid()写一个被用户控制的内核地址。
(2)清除所有信号处理函数。exit_signals函数会设置PF_EXITING标志来表明进程正在退出,并清除所有信息处理函数。内核的其他方面会利用PF_EXITING来防止在进程被删除时还试图处理此进程。
(3)清除一系列的进程资源。比如比如 exit_mm删除内存页、exit_files关闭所有打开的文件描述符,这会清理I/O缓存,如果缓存中有数据,就会将它们写入相应的文件,以防止文件数据的丢失。exit_fs清除当前目录关联的inode、exit_thread清除线程信息、等等。
(4)发出退出通知。调用exit_notify执行一系列通知。例如通知父进程我正在退出。如下:
static void exit_notify(struct task_struct *tsk, int group_dead) { int signal; void *cookie; /* * This does two things: * * A. Make init inherit all the child processes * B. Check to see if any process groups have become orphaned * as a result of our exiting, and if they have any stopped * jobs, send them a SIGHUP and then a SIGCONT. (POSIX 3.2.2.2) */ forget_original_parent(tsk); exit_task_namespaces(tsk); write_lock_irq(&tasklist_lock); if (group_dead) kill_orphaned_pgrp(tsk->group_leader, NULL); /* Let father know we died * * Thread signals are configurable, but you aren't going to use * that to send signals to arbitary processes. * That stops right now. * * If the parent exec id doesn't match the exec id we saved * when we started then we know the parent has changed security * domain. * * If our self_exec id doesn't match our parent_exec_id then * we have changed execution domain as these two values started * the same after a fork. */ if (tsk->exit_signal != SIGCHLD && !task_detached(tsk) && (tsk->parent_exec_id != tsk->real_parent->self_exec_id || tsk->self_exec_id != tsk->parent_exec_id)) tsk->exit_signal = SIGCHLD; signal = tracehook_notify_death(tsk, &cookie, group_dead); if (signal >= 0) signal = do_notify_parent(tsk, signal); tsk->exit_state = signal == DEATH_REAP ? EXIT_DEAD : EXIT_ZOMBIE; /* mt-exec, de_thread() is waiting for us */ if (thread_group_leader(tsk) && tsk->signal->group_exit_task && tsk->signal->notify_count < 0) wake_up_process(tsk->signal->group_exit_task); write_unlock_irq(&tasklist_lock); tracehook_report_death(tsk, signal, cookie, group_dead); /* If the process is dead, release it - nobody will wait for it */ if (signal == DEATH_REAP) release_task(tsk); }
exit_notify将当前进程的所有子进程的父进程ID设置为1(init),让init接管所有这些子进程。如果当前进程是某个进程组的组长,其销毁导致进程组变为“无领导状态“,则向每个组内进程发送挂起信号SIGHUP,然后发送SIGCONT。这是遵循POSIX3.2.2.2标准。接着向自己的父进程发送SIGCHLD信号,然后调用do_notify_parent通知父进程。若返回DEATH_REAP(这个意思是不管是否有其他进程关心本进程的退出信息,自动完成进程退出和PCB销毁),就直接进入EXIT_DEAD状态,如果不是,则就需要变为EXIT_ZOMBIE状态。
注意在最初父进程创建子进程时,如果调用了waitpid()等待子进程结束(表示它关心子进程的状态),子进程结束时父进程会处理它发来的SIGCHILD信号。如果不调用wait(表示它不关心子进程的死活状态),则不会处理子进程的SIGCHILD信号。参看./linux/kernel/signal.c:do_notify_parent(),代码如下:
int do_notify_parent(struct task_struct *tsk, int sig) { struct siginfo info; unsigned long flags; struct sighand_struct *psig; int ret = sig; BUG_ON(sig == -1); /* do_notify_parent_cldstop should have been called instead. */ BUG_ON(task_is_stopped_or_traced(tsk)); BUG_ON(!task_ptrace(tsk) && (tsk->group_leader != tsk || !thread_group_empty(tsk))); info.si_signo = sig; info.si_errno = 0; /* * we are under tasklist_lock here so our parent is tied to * us and cannot exit and release its namespace. * * the only it can is to switch its nsproxy with sys_unshare, * bu uncharing pid namespaces is not allowed, so we'll always * see relevant namespace * * write_lock() currently calls preempt_disable() which is the * same as rcu_read_lock(), but according to Oleg, this is not * correct to rely on this */ rcu_read_lock(); info.si_pid = task_pid_nr_ns(tsk, tsk->parent->nsproxy->pid_ns); info.si_uid = __task_cred(tsk)->uid; rcu_read_unlock(); info.si_utime = cputime_to_clock_t(cputime_add(tsk->utime, tsk->signal->utime)); info.si_stime = cputime_to_clock_t(cputime_add(tsk->stime, tsk->signal->stime)); info.si_status = tsk->exit_code & 0x7f; if (tsk->exit_code & 0x80) info.si_code = CLD_DUMPED; else if (tsk->exit_code & 0x7f) info.si_code = CLD_KILLED; else { info.si_code = CLD_EXITED; info.si_status = tsk->exit_code >> 8; } psig = tsk->parent->sighand; spin_lock_irqsave(&psig->siglock, flags); if (!task_ptrace(tsk) && sig == SIGCHLD && (psig->action[SIGCHLD-1].sa.sa_handler == SIG_IGN || (psig->action[SIGCHLD-1].sa.sa_flags & SA_NOCLDWAIT))) { /* * We are exiting and our parent doesn't care. POSIX.1 * defines special semantics for setting SIGCHLD to SIG_IGN * or setting the SA_NOCLDWAIT flag: we should be reaped * automatically and not left for our parent's wait4 call. * Rather than having the parent do it as a magic kind of * signal handler, we just set this to tell do_exit that we * can be cleaned up without becoming a zombie. Note that * we still call __wake_up_parent in this case, because a * blocked sys_wait4 might now return -ECHILD. * * Whether we send SIGCHLD or not for SA_NOCLDWAIT * is implementation-defined: we do (if you don't want * it, just use SIG_IGN instead). */ ret = tsk->exit_signal = -1; if (psig->action[SIGCHLD-1].sa.sa_handler == SIG_IGN) sig = -1; } if (valid_signal(sig) && sig > 0) __group_send_sig_info(sig, &info, tsk->parent); __wake_up_parent(tsk, tsk->parent); spin_unlock_irqrestore(&psig->siglock, flags); return ret; }
我们可以看到,如果父进程显示指定对子进程的SIGCHLD信号处理为SIG_IGN,或者标志为SA_NOCLDWAIT,则返回的是ret=-1,即DEATH_REAP(这个宏在./linux/include/tracehook.h中定义为-1),这时在exit_notify中子进程马上变为EXIT_DEAD,表示我已退出并且死亡,最后被后面的release_task回收,将不会再有进程等待我。否则返回值与传入的信号值相同,子进程变成EXIT_ZOMBIE,表示已退出但还没死。不管有没有处理SIGCHLD,do_notify_parent最后都会用__wake_up_parent来唤醒正在等待的父进程。
可见子进程在结束前不一定都需要经过一个EXIT_ZOMBIE过程。如果父进程调用了waitpid等待子进程,则会显示处理它发来的SIGCHILD信号,子进程结束时会自我清理(在do_exit中自己用release_task清理);如果父进程没有调用waitpid等待子进程,则不会处理SIGCHLD信号,子进程不会马上被清理,而是变成EXIT_ZOMBIE状态,成为著名的僵尸进程。还有一种特殊情形,如果子进程退出时父进程恰好正在睡眠(sleep),导致没来得急处理SIGCHLD,子进程也会成为僵尸,只要父进程在醒来后能调用waitpid,也能清理僵尸子进程,因为wait系统调用内部有清理僵尸子进程的代码。因此,如果父进程一直没有调用waitpid,那么僵尸子进程就只能等到父进程退出时被init接管了。init进程会负责清理这些僵尸进程(init肯定会调用wait)。
我们可以写个简单的程序来验证,父进程创建10个子进程,子进程sleep一段时间后退出。第一种情况,父进程只对1~9号子进程调用waitpid(),1~9号子进程都正常结束,而在父进程结束前,pids[0]为EXIT_ZOMBIE。第二种情况,父进程创建10个子进程后,sleep()一段时间,在这段时间内_exit()的子进程都成为EXIT_ZOMBIE。父进程sleep()结束后,依次调用waitpid(),子进程马上变为EXIT_DEAD被清理。
为了更好地理解怎么清理僵尸进程,我们简要地分析一下wait系统调用。wait族的系统调用如waitpid,wait4等,最后都会进入./linux/kernel/exit.c:do_wait()内核例程,而后函数链为do_wait()—>do_wait_thread()—>wait_consider_task(),在这里,如果子进程在exit_notify中设置的tsk->exit_state为EXIT_DEAD,就返回0,即wait系统调用返回,说明子进程不是僵尸进程,会自己用release_task进行回收。如果它的exit_state是EXIT_ZOMBIE,进入wait_task_zombie()。在这里使用xchg尝试把它的exit_state设置为EXIT_DEAD,可见父进程的wait4调用会把子进程由EXIT_ZOMBIE设置为EXIT_DEAD。最后wait_task_zombie()在末尾调用release_task()清理这个僵尸进程。
(5)设置销毁标志并调度新的进程。在do_exit的最后,用exit_io_context清除IO上下文、preempt_disable禁用抢占,设置进程状态为TASK_DEAD,然后调用./linux/kernel/sched.c:schedule()来选择一个将要执行的新进程。注意进程在退出并回收之后,其位于调度器的进程列表中的进程描述符(PCB)并没有立即释放,必须在设置task_struct的state为TASK_DEAD之后,由schedule()中的finish_task_switch()—>put_task_struct()把它的PCB重新放回到freelist(可用列表)中,这时PCB才算释放,然后切换到新的进程。
7. exit与_exit的差异
为了理解这两个系统调用的差异,先来讨论文件内存缓存区的问题。 在linux中,标准输入输出(I/O)函数都是作为文件来处理。对应于打开的每个文件,在内存中都有对应的缓存,每次读取文件时,会多读一些记录到缓存中,这样在下次读文件时,就在缓存中读取;同样,在写文件时也是写在文件对应的缓存中,并不是直接写入硬盘的文件中,等满足了一定条件(如达到一定数量,遇到换行符
或文件结束标志EOF)才将数据真正的写入文件。这样做的好处就是加快了文件读写的速度。但这样也带来了一些问题,比如有一些数据,我们认为已经写入了文件,但实际上没有满足一定条件而任然驻留在内存的缓存中,这样,如果我们直接用_exit()函数直接终止进程,将导致数据丢失。如果改成exit,就不会有数据丢失的问题出现了,这就是它们之间的区别了.要解释这个问题,就要涉及它们的工作步骤了。
exit():通过前面源代码分析可知,在执行该函数时,进程会检查文件打开情况,清理I/O缓存,如果缓存中有数据,就会将它们写入相应的文件,这样就防止了文件数据的丢失,然后终止进程。
_exit():在执行该函数时,并不清理标准输入输出缓存,而是直接清除内存空间,当然也就把文件缓存中尚未写入文件的数据给销毁了。由此可见,使用exit()函数更加安全。
此外,对于它们两者的区别还有各自的头文件不同。exit()在stdlib.h中,_exit()在unistd.h中。一般情况下exit(0)表示正常退出,exit(1),exit(-1)为异常退出,0、1、-1是返回值,具体含义可以自定。还要注意return是返回函数调用,如果返回的是main函数,则为退出程序 。exit是在调用处强行退出程序,运行一次程序就结束。
下面是完整的Linux进程运行流程:
下面是基本的执行流程图:
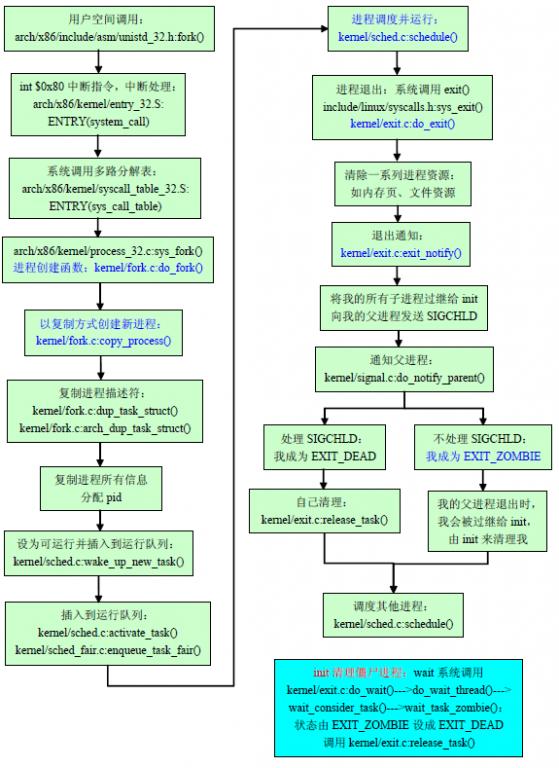
图 Linux进程管理的执行流程